Pandas模块-数据读取和数据类型
Pandas 是一个 Python 类库,用于数据分析、数据处理、数据可视化,它具有高性能的数据结构和数据分析工具,经常与 numpy(数学计算)、scikit-learn(机器学习) 结合使用。
1. Pandas 数据读取
Pandas 需要先读取表格类型的数据,然后进行分析。
| 数据类型 | 说明 | Pandas 读取方法 |
|---|---|---|
| csv、tsv、txt | 用逗号、tab分隔的纯文本文件 | pd.read_csv |
| Excel | 微软xls、xlsx文件 | pd.read_excel |
| mysql | 关系型数据库表 | pd.read_sql |
1.1 读取 csv 文件
读取 csv 文件,使用 pd.read_csv 方法,使用默认的标题行、逗号分隔符。
import pandas as pd
fpath = "文件路径.csv"
# 读取数据,并赋给一个变量
ratings = pd.read_csv(fpath)
# 在控制台打印数据
print(ratings)
'''查看csv文件特定内容的方法'''
# 查看前几行数据
ratings.head()
# 返回数据的行、列数
ratings.shape
# 查看列名列表
ratings.columns
# 查看索引列表
ratings.index
# 查看每列的数据类型
ratings.dtypes
1.2 读取 txt 文件
读取 txt 文件,使用 pd.read_csv 方法,自定义分隔符、列名,查看方法同 csv 文件。
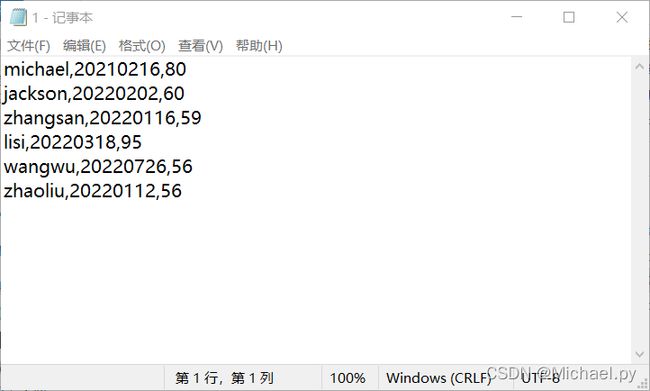
创建一个 1.txt 文件(为了方便,可以使用相对路径),为这个 txt 文件写入三列数据,未定义标题行及列名,每列数据由逗号隔开,文件示意如下。
# 导入pandas库
import pandas as pd
# 导入txt文件,使用相对路径
fpath = "1.txt"
# 读取数据
pvuv = pd.read_csv(
fpath,
# sep=“ ” 自定义分隔符,若默认为逗号,可以省略
# 无标题行
header=None,
# 自定义列名
names=["name", "card number", "mark"],
)
# 在控制台打印数据
print(pvuv)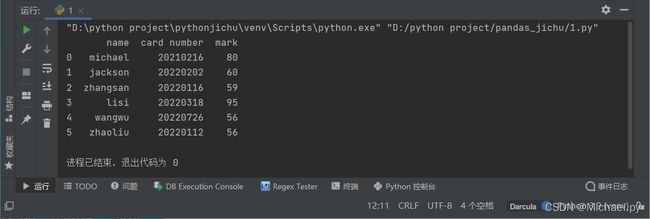
1.3 读取 Excel 文件
读取 Excel 文件,使用 pd.read_excel 方法。
创建一个 Excel1.xlsx 文件(为了方便,可以使用相对路径),为这个文件写入三列数据,第一行为列名,并默认读取第一个表单,文件示意如下。

# 导入库
import pandas as pd
import xlrd
# 导入Excel文件
fpath = "Excel1.xlsx"
# 读取数据,默认第一个表单
p = pd.read_excel(fpath, sheet_name="1")
# 在控制台打印数据,数据结构与读取的txt文件类似
print(p)
''' 使用pycharm运行这段代码时,可能会报错,
根据提示安装openpyxl库即可'''
读取 Excel 文件特定内容的方法:
'''---读取指定行的数据---'''
# 默认读取前5行数据
print(p.head())
# 默认读取前2行数据
print(p.head(2))
#返回指定的行的ndarray结果
print(p.ix[[0,2,3]].values)
#返回指定的行的DataFrame结果
print(p.ix[[0,2,3]])
#返回指定的index结果
print(p.index[0:5:2])
#根据index返回指定的行的ndarray结果
print(p.ix[df.index[0:5:2]].values)
#根据index返回指定的行的DataFrame结果
print(p.ix[df.index[0:5:2]])
'''---读取指定列的数据---'''
#只能获取单列值
print(p['name'].values)
#返回指定的列的DataFrame结果
print(p.ix[:,["name","address"]])
#返回columns结果
print(list(p.columns[0:3:1]))
#根据index返回指定的列的ndarray结果
print(p.ix[:,list(p.columns[1:3:1])].values)
#根据index返回指定的列的DataFrame结果
print(p.ix[:,list(p.columns[1:3:1])])
'''---读取指定行和列的数据---'''
#3,4行,1,2列,起始行列都为0
d = df.ix[list(p.index[3:5:1]),list(p.columns[1:3:1])]1.4 读取 mysql 数据
读取 mysql 文件,使用 pd.read_sql 方法。
import pymysql
conn = pymysql.connect(
host="127.0.0.1",
user="root",
password="12345678",
database="test",
charset="utf8",
)
mysql_page = pd.read_sql("select * from 表名", con=conn)
print(mysql_page)2. Pandas 数据结构
当从一个文件中读取一块数据后,此时这个数据还是二维数据(DataFrame),并不方便我们操作,从二维数据中查找一维数据,一行或一列(Series),将二维数据降至一维数据,这样可以使我们更好地操作数据。
DataFrame:二维数据,整个列表,多行多列。
Series:一维数据,一行或一列。

2.1 Series
Series:一种类似于一维数组的对象,它由一组数据(不同数据类型)以及一组与之相关的数据标签(索引)组成。
利用列表创建 Series:
import pandas as pd
s1 = pd.Series([1, "michael", 2.5, 77])
# 左侧为索引,右侧为数据
print(s1)
# 获取索引
print(s1.index)
# 获取数据
print(s1.values)
# 输出结果
0 1
1 michael
2 2.5
3 77
dtype: object
RangeIndex(start=0, stop=4, step=1)
[1 'michael' 2.5 77]创建一个具有标签索引的 Series:
s2 = pd.Series([1, "michael", 2.5, 77], index=["a", "b", "c", "d"])
print(s2)
print(s2.index)
# 输出结果
a 1
b michael
c 2.5
d 77
dtype: object
Index(['a', 'b', 'c', 'd'], dtype='object')使用字典创建 Series:
dict1 = {"a": 1, "b": "michael", "c": 2.5, "d": 77}
s3 = pd.Series(dict1)
print(s3)
# 输出结果
a 1
b michael
c 2.5
d 77
dtype: object根据索引查询数据,类似于字典:
dict1 = {"a": 1, "b": "michael", "c": 2.5, "d": 77}
s3 = pd.Series(dict1)
print(s3["a"])
print(type(s3["b"]))
print(s3[["c", "d"]])
print(type(s3[["c", "d"]]))
# 输出结果
1
c 2.5
d 77
dtype: object
2.2 DataFrame
DataFrame 是一个表格型数据结构,创建方法也就是读取文件,其有三个特点:
1)每列可以是不同的值类型;
2)既有行索引 index,又有列索引 columns;
3)可以看做由 Series 组成的字典。
根据多个字典创建 DataFrame:
data = {
"state": [1, 24, 56, 100],
"year": [2008, 2012, 2021, 2022],
"name": ["li", "wang", "chen", "qin"]
}
df = pd.DataFrame(data)
print(df)
print(df.dtypes)
print(df.index)
print(df.columns)
# 输出结果
state year name
0 1 2008 li
1 24 2012 wang
2 56 2021 chen
3 100 2022 qin
state int64
year int64
name object
dtype: object
RangeIndex(start=0, stop=4, step=1)
Index(['state', 'year', 'name'], dtype='object')
2.3 从 DataFrame 中查询出 Series
如果只查询一行或一列,返回 pd.Series;
如果查询多行或多列,返回 pd.DataFrame。
查询一列或一行:
data = {
"state": [1, 24, 56, 100],
"year": [2008, 2012, 2021, 2022],
"name": ["li", "wang", "chen", "qin"]
}
df = pd.DataFrame(data)
# 查询一列
print(df["year"])
print(type(df["year"]))
# 查询一行
print(df.loc[1])
print(type(df.loc[1]))
# 输出结果
0 2008
1 2012
2 2021
3 2022
Name: year, dtype: int64
state 24
year 2012
name wang
Name: 1, dtype: object
查询多行或多列:
data = {
"state": [1, 24, 56, 100],
"year": [2008, 2012, 2021, 2022],
"name": ["li", "wang", "chen", "qin"]
}
df = pd.DataFrame(data)
# 查询多列
print(df[["year", "name"]])
print(type(df[["year", "name"]]))
# 查询多行
print(df.loc[1:3])
print(type(df.loc[1:3]))
# 输出结果
year name
0 2008 li
1 2012 wang
2 2021 chen
3 2022 qin
state year name
1 24 2012 wang
2 56 2021 chen
3 100 2022 qin