牛客刷题——题型总结
文章目录
- (一)表连接
-
- 1、多表连接
-
- (1)join-on和多个where等价
- (2)通过多表连接解决A成立B不成立的问题
- (3)自连接
- (4)from相同表但是where不同
- 2、表连接函数
-
- (1)union、union all
- (2)left join、right join、join的区别
- 3、行对应性表连接
- 4、嵌套查询
- (二)筛选:where、having、in
-
- 1、where和having的区别
- 2、where in与join等价的情况
- (三)聚合信息:groupby与窗口函数
-
- 1、要显示所有信息因此不能直接使用group by后的结果
- 2、窗口函数+groupby
- 3、根据两个变量分组
- 4、聚合函数不一定要和groupby一起用
- 5、groupby最易错点:select 分组变量/聚合函数
- 6、根据不同字段group by
- (四)排序
-
- 1、第n多
- 2、前n多:窗口函数
- (五)执行顺序
- (六)统计不同——去重
- (七)行列转换
- (八)时间函数
- (九)字符串函数
-
- 1、内置函数
- 2、正则表达式
- (十)类型转换
- (十一)随机抽样
- (十二)空值null
-
- null和空值得区别
(一)表连接
1、多表连接
(1)join-on和多个where等价
涉及多个表,要么join用on来筛选,要么多表查询限制很多个where条件
-- 1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数
01-多表join,用on筛选
(1)a连b连c,不要a连(b连c),这样会把过程写复杂
(2)中间的筛选放在on里写,where只能在最后(查询前)写,不能在join的过程中
select a.* ,b.s_score as 01_score,c.s_score as 02_score
from student a
join score b on a.s_id=b.s_id and b.c_id='01' #01一定要有成绩,所以用了join
left join score c on b.s_id=c.s_id and c.c_id='02' #02成绩可有可无,所以用left join
where b.s_score>c.s_score;
02-不连接,直接一个where筛选出所有的结果,要哪些信息就直接选择
select a.*,b.s_score as 01_score,c.s_score as 02_score from student a,score b,score c
where a.s_id=b.s_id
and a.s_id=c.s_id
and b.c_id='01'
and c.c_id='02'
and b.s_score>c.s_score
-- 9、查询学过编号为"01"并且也学过编号为"02"的课程的同学的信息
(1)join 方法
select student.*
from student
join score a on a.s_id=student.s_id and a.c_id='01'
join score b on b.s_id=student.s_id and b.c_id='02'
(2)where方法,注意要from所有表,筛选所有条件都具备的情况
select student.*
from student,score a ,score b
where student.s_id=a.s_id and student.s_id=b.s_id and a.c_id='01' and b.c_id='02'
【例】SQL19、查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
- 思路:因为要包括暂时没有分配部门的员工,所以要把employees放在最左边,且用两次left join
# 两次LEFT JOIN连接
SELECT last_name, first_name, dept_name
FROM employees
LEFT JOIN dept_emp ON employees.emp_no=dept_emp.emp_no
LEFT JOIN departments ON dept_emp.dept_no=departments.dept_no
【例】SQL22 统计各个部门的工资记录数
SELECT d.dept_no, dept_name,count(*) as sum
FROM salaries s
JOIN dept_emp de ON de.emp_no = s.emp_no
JOIN departments d ON d.dept_no = de.dept_no
GROUP BY dept_no -- 从groupby可以开始用select中的别名
ORDER BY dept_no
(2)通过多表连接解决A成立B不成立的问题
【例】SQL25 满足条件的用户的试卷完成数和题目练习数
请你找到高难度SQL试卷得分平均值大于80并且是7级的红名大佬,统计他们的2021年试卷完成数和题目练习数,只保留2021年有试卷完成记录的用户。结果按试卷完成数升序,按题目练习数降序。
- 题目的意思是说,试卷一定要有完成记录,但是题目不一定要有,这种情况下应该把试卷完成情况作为左表,题目完成情况作为右表,其他情况再做筛选。
select
uid,
exam_cnt,
(case when question_cnt is null then 0 else question_cnt end)
#if(question_cnt is null, 0, question_cnt)
from
(select uid,count(score) as exam_cnt
from exam_record
where YEAR(submit_time) = 2021
group by uid) t -- 试卷有成绩
left join
(select uid,count(submit_time) as question_cnt
from practice_record
where YEAR(submit_time) = 2021
group by uid) t2 using(uid) -- 题目不一定做了
where uid in
(
select
uid
from exam_record
join examination_info using(exam_id)
join user_info using(uid)
where tag = 'SQL' and difficulty = 'hard' and `level` = 7
group by uid
having avg(score) >= 80
)
order by exam_cnt asc, question_cnt desc
(3)自连接
【例】SQL70 牛客每个人最近的登录日期(五)
- 法一:sum(case when 1 else 0 end)分组计算
- 法二:自连接:join on user_id相等并且datediff(nextday,today)=1
- 法三:lead窗口函数
要在group by之后还能得到所有日期的结果,可以把原表和现表左边界,
select distinct date from login或者select date from login group by date(原表的date也要唯一)
# 法一
select date,
ifnull(
round(
sum(case when (user_id,date) in
(select user_id,date_add(date,interval -1 day) from login)
and (user_id,date) in
(select user_id,min(date) from login group by user_id)
then 1 else 0 end)/
sum(case when (user_id,date) in
(select user_id,min(date) from login group by user_id)
then 1 else 0 end),3),0) as p
from login
group by date
order by date
# 法二
# a最早登录的日期左连接第二天的日期:on用户和时间差
# b所有的日期连接a:所有天的最早和第二天情况
# 对b计数
select t0.date,
ifnull(round(count(t2.user_id)/count(t1.user_id),3),0)
from
(select distinct date from login)t0
left join
(select user_id,min(date)as min_date from login group by user_id)t1
on t0.date=min_date
left join
login t2 on t1.user_id=t2.user_id and datediff(t2.date,min_date)=1
group by t0.date
# 法三
select date,
ifnull(round(sum(case when date=min_date and datediff(next_date,date)=1 then 1 else 0 end) / sum(case when date=min_date then 1 else 0 end),3),0) as p
from(
select user_id, date, min(date) over (partition by user_id) as min_date, lead(date,1) over(partition by user_id order by date) as next_date
from login
) a
group by date
order by date;
【例】SQL46 大小写混乱时的筛选统计
#自连接得到符合大小写要求的exam_id
#on的妙用
select a.tag,b.answer_cnt
from
(select tag,count(start_time) as answer_cnt
from examination_info join exam_record using(exam_id)
group by tag)a
join
(select tag,count(start_time) as answer_cnt
from examination_info join exam_record using(exam_id)
group by tag)b
on a.tag!=b.tag and upper(a.tag)=b.tag
group by tag
order by answer_cnt desc
(4)from相同表但是where不同
with temp as (
select x from table
where x1 in ('a','b','c')
)
select x from temp wehre x1='a'
2、表连接函数
(1)union、union all
行合并,要求列是同数量且有相似的数据类型,每条 SELECT 语句中的列的顺序必须相同。union会去重并降低效率,union all允许重复的值。UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名。
# union
SELECT column_name(s) FROM table_name1
UNION
SELECT column_name(s) FROM table_name2
# union all
SELECT column_name(s) FROM table_name1
UNION ALL
SELECT column_name(s) FROM table_name2
orderby只能在最后使用一次,所以这边只能放进子表中才能使用两次
【例】SQL23 每个题目和每份试卷被作答的人数和次数
select * from
(select exam_id as tid,
count(distinct uid) as uv,
count(*) as pv
from exam_record
group by tid
order by uv desc,pv desc)a -- orderby只能在最后使用一次,所以这边只能放进子表中才能使用两次
union all
select * from
(select question_id as tid,
count(distinct uid) as uv,
count(*) as pv
from practice_record
group by tid
order by uv desc,pv desc)b
【例】SQL24 分别满足两个活动的人
输出2021年里,所有每次试卷得分都能到85分的人以及至少有一次用了一半时间就完成高难度试卷且分数大于80的人的id和活动号,按用户ID排序输出。输出形式:

所有每次试卷得分都能到85分的人:
(1)思路1:找到存在分数小于85分的用户,筛选的时候用not in排除
(2)思路2:根据用户分组,最小分数>=85的用户,就是符合条件的用户
- 难点:分别’activity1’ as activity和’activity2’ as activity之后union all
# 思路1
with a as (select uid from exam_record
where score<85
and year(submit_time) = 2021) -- 存在分数<85的用户,不符合activity1
select distinct uid,
(case when uid not in (select * from a) then 'activity1' else null end) as activity
from exam_record
where (case when uid not in (select * from a) then 'activity1' else null end) is not null
union all
select distinct uid,'activity2' as activity
from exam_record e_r left join examination_info e_i using(exam_id)
where year(submit_time) = 2021
and difficulty = 'hard'
and score > 80
and timestampdiff(minute, start_time, submit_time) * 2 < e_i.duration
order by uid
# 思路2
select uid,'activity1' as activity
from exam_record
where year(submit_time) = 2021
group by uid
having min(score) >= 85
union all
select distinct uid,'activity2' as activity
from exam_record e_r left join examination_info e_i using(exam_id)
where year(submit_time) = 2021
and difficulty = 'hard'
and score > 80
and timestampdiff(minute, start_time, submit_time) * 2 < e_i.duration
order by uid
(2)left join、right join、join的区别
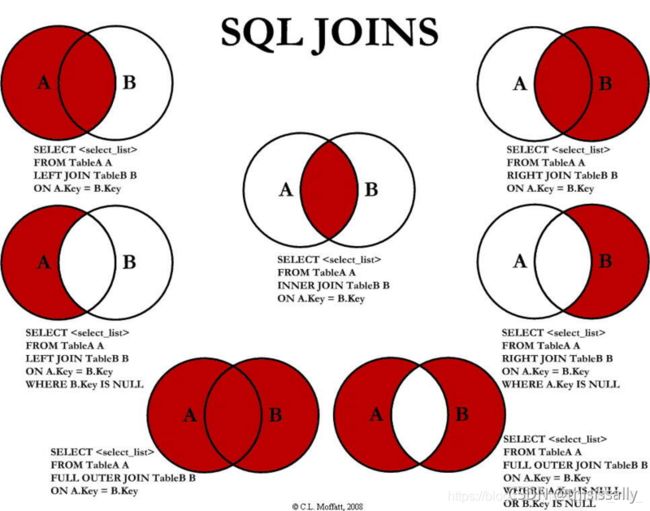
- left join:查出来的结果显示左边的所有数据,然后右边显示的是和左边有交集部分的数据。
- right join:查出表2所有数据,以及表1和表2有交集的数据。
- join(inner join):查出两个表有交集的部分,其余没有关联就不额外显示出来。
3、行对应性表连接
SQL86 实习广场投递简历分析(三)
- 代码注意点:(1)select一定要写清哪些,这里写*会报错;(2)RIGHT(s,n) 返回字符串 s 的后 n 个字符;(3)用right(first_year_mon,2)=right(second_year_mon,2)控制每行上时间的对应性;(4)顺序最后一定要调整
select t1.job,first_year_mon,first_year_cnt,second_year_mon,second_year_cnt
from
(select job,DATE_FORMAT(date,'%Y-%m') as first_year_mon,sum(num)as first_year_cnt
from resume_info
where date like '2025%'
group by job,first_year_mon)t1
JOIN
(select job,DATE_FORMAT(date,'%Y-%m') as second_year_mon,sum(num)as second_year_cnt
from resume_info
where date like '2026%'
group by job,second_year_mon)t2
on t1.job=t2.job AND right(first_year_mon,2)=right(second_year_mon,2)
order by first_year_mon desc,job desc
希望用到两张表的信息——表连接+条件筛选
SQL76 考试分数(五)
- 代码注意点:所有语句中,如果变量名是唯一的,就不需要写表名,写表名是在易混淆的情况下才这么做。
-- 查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序
select id,t1.job,score,t_rank
from
(select id,job,score,
row_number() over (partition by job order by score desc) as t_rank
from grade)t1
JOIN
(select job,
(case when count(id)%2=0 then count(id)/2 else ceiling(count(id)/2) end) as start,
(case when count(id)%2=0 then count(id)/2+1 else ceiling(count(id)/2) end) as end
from grade
group by job )t2
on t1.job=t2.job
where t_rank=start or t_rank=end
order by id
4、嵌套查询
当下一层计算结果是基于上一层时,需要用到层层嵌套的方法
【例】SQL28 第二快/慢用时之差大于试卷时长一半的试卷
-- 先用窗口函数找出每门考试的正数和倒数的排名
-- 然后根据每门课分组,计算正数和倒数对应时间的时间差
-- 最后筛选出时间差符合要求的情况
-- 涉及的知识点:并列计数窗口、分组条件计算、嵌套查询
select distinct exam_id, duration, release_time
from
(select exam_id, duration, release_time,
#sum(case when rank1 = 2 then costtime when rank2 = 2 then -costtime else 0 end) as sub
max(case when rank1=2 then costtime else null end)-max(case when rank2=2 then costtime else null end) as sub
from (
select e_i.exam_id, duration, release_time,
timestampdiff(minute, start_time, submit_time) as costtime,
row_number() over(partition by e_r.exam_id order by timestampdiff(minute, start_time, submit_time) desc) rank1,
row_number() over(partition by e_r.exam_id order by timestampdiff(minute, start_time, submit_time) asc) rank2
from exam_record e_r join examination_info e_i
on e_r.exam_id = e_i.exam_id
) table1
group by exam_id
) table2
where sub*2 >= duration
order by exam_id desc
【例】SQL29 连续两次作答试卷的最大时间窗
时间函数:
datediff(end_time,start_time)
date(start_time)
-- 细节点:(1)作答过只需要有start_time就可以了;(2)根据题意算时间差都需要在公式的基础上+1
-- 需要的数据:每个人的前后期开始作答时间(窗口),
-- groupby:每个人的最大窗口时间,对窗口时间筛选,每个人的最先时间,最后时间,作答次数
-- 在上面的基础上计算count,max,min
-- 一层基于一层来计算,用层层嵌套来做
select uid,days_window,
round(counts/sub_day*days_window,2) as avg_exam_cnt
from
(select uid,
max(datediff(next_time,start_time))+1 as days_window,
datediff(max(date(start_time)),min(date(start_time)))+1 as sub_day,
count(start_time) as counts
from
(select uid,start_time,
lead(start_time,1)over(partition by uid order by start_time) as next_time
from exam_record
where year(start_time)=2021)a
group by uid
having count(distinct date(start_time))>=2
)b
order by days_window desc,avg_exam_cnt desc;
【例】SQL30 近三个月未完成试卷数为0的用户完成情况
# 每个人的试卷作答(start)记录的月份:窗口函数,序号
# 做筛选:序号前三,没有未完成
# 筛选出用户,得到该用户的试卷完成数(近三个月)
# 按试卷完成数和用户ID降序排名
select uid,count(submit_time) as exam_complete_cnt from
(select uid,date_format(start_time,'%Y%m') as ans_month,start_time,submit_time,
dense_rank()over(partition by uid order by date_format(start_time,'%Y%m') desc) as recent_months
from exam_record)a
where recent_months between 1 and 3 -- <=3
group by uid
having count(start_time)=count(submit_time)
order by exam_complete_cnt desc,uid desc
【例】SQL31 未完成率较高的50%用户近三个月答卷情况
- 代码注意点:(1)三表嵌套join很复杂,用where in代替反而简化问题;(2)count()在只有一类的情况下可以不和groupby连用,但是只能显示一行结果。count()over()可以在每一行都显示结果;(3)判断前50%(中位数及之后):rank<=ceiling(总数/2),则是前50%,否则不是
【法一】count(distinct uid) over ()把总人数连接到表上
【法二】只join不on,可以把总人数连接到表上
【法三】(select count(distinct uid) from)表示总人数 - 思路:先把步骤和对应的方法按照先后顺序写出来,再写代码
# 数所有行数用count(1)或者count任意一个非空变量都可以
with a as (
select uid
from
(select *,row_number()over(order by incomplete_rate desc) incomplete_order,count(1)over() as numbers
from
(select uid,(count(1)-count(submit_time))/count(1) as incomplete_rate
from exam_record
where exam_id in (select exam_id from examination_info where tag='SQL')
group by uid)t1)t2 join (select count(distinct uid) as total_user from exam_record join examination_info using(exam_id) where tag='SQL') t_u
# where incomplete_order<=ceiling(numbers*0.5) -- 法一
# where incomplete_order<=ceiling(total_user*0.5) -- 法二
where incomplete_order<=ceiling((select count(distinct uid) as total_user from exam_record join examination_info using(exam_id) where tag='SQL')*0.5) -- 法三
and uid in (select uid from user_info where level in (6,7))
)
select uid,start_month,count(start_time) as total_cnt,count(submit_time) as complete_cnt
from
(select uid,date_format(start_time,'%Y%m') as start_month,start_time,submit_time,
dense_rank()over(partition by uid order by date_format(start_time,'%Y%m') desc) as recent_months
from exam_record)recent_table
where recent_months<=3
and uid in (select uid from a)
group by uid,start_month -- 每个人每个月的登录情况
order by uid,start_month
(二)筛选:where、having、in
1、where和having的区别
(1)作用位置:都是筛选功能,where指定分组之前数据行的条件,having子句用来指定分组之后条件
(2)使用限制:where是对聚合前的信息进行筛选,having是对聚合后的信息进行筛选
(3)联系:where-groupby-having的使用顺序,where和having的区别在于筛选对象是分组前还是分组后
【易错点】涉及groupby的时候注意select的要么是聚合函数,要么是groupby的对象
-- 15、查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩
select a.s_id,a.s_name,avg(b.s_score) as avg_score
from student a join score b
on a.s_id=b.s_id
where s_score<60
group by a.s_id,a.s_name
having count(c_id)>=2
SQL78 牛客的课程订单分析(二)
select user_id
from order_info
where status='completed'
and product_name in ('C++','Java','Python')
and date>'2025-10-15'
group by user_id
having count(id)>=2
order by user_id
SQL88 最差是第几名(二)
- 涉及变量比较一定是在同一行上的数据
- where的逻辑在from之后,select之前,所以这里的where筛选可以用到from表中有但是select中没有的变量
-- 中位数:正序和逆序的累积和都大于总和的一半,就是中位数
select grade FROM
(select
grade,(select sum(number) from class_grade) as total,
sum(number) over (order by grade) as up,
sum(number) over (order by grade desc) as down
from class_grade
)a
where up>=total/2 -- 涉及变量比较一定是在同一行上的,where在from之后,select之前
and down>=total/2
order by grade
2、where in与join等价的情况
当一次groupby,需要筛选条件时,where in和join时等价的
当多次groupby,需要筛选条件时,用where in () (注意不是where in ()a,不用标记表名)
等价:【例】SQL22 作答试卷得分大于过80的人的用户等级分布
# where in
select level,count(uid) as level_cnt
from user_info
where (uid,level) in # 字段数需要统一
(select ui.uid,level
from exam_record er
left join user_info ui using(uid)
left join examination_info ei using(exam_id)
where tag='SQL'
and score>80)
group by level
order by level_cnt DESC
# join
select level,count(distinct u_i.uid) as level_cnt
from exam_record e_r
left join examination_info e_i on e_r.exam_id = e_i.exam_id
left join user_info u_i on e_r.uid = u_i.uid
where tag = 'SQL'
and score > 80
group by level
order by level_cnt desc, level desc
不等价【例】月均完成试卷数不小于3的用户爱作答的类别
SELECT tag,count(tag) as tag_cnt
from exam_record join examination_info using(exam_id)
where uid in
(
select uid from exam_record
where submit_time is not null
group by uid
having count(submit_time)/count(distinct date_format(submit_time,'%Y%m'))>=3
)
group by tag
order by tag_cnt desc
【例】SQL70 牛客每个人最近的登录日期(五)
查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序
- 代码注意点:(1)iffull(value,0)表示如果是null就输出0;(2)(a,b) in (select A,B from…)列数一定要对等
- 明确问题:12号的新用户次留是指在12号是第一次登录,并且在13号也登录了。分母:当前日期新用户的特征是 当前日期=该用户所有登录日期的最小值。分子:当前日期作为前一天有该用户的登录记录,并且是第一次登录。(12号作为前一天登陆了并且是第一次登录,13号要登录了)
-- 通过in来筛选
-- 分子:今天在,昨天也在,且昨天是第一天登录
-- 分母:每天的新用户数
-- 易错点:分母为0,ifnull
select date,
ifnull(round(sum(case when
(user_id,date) in (select user_id,date_add(date,interval -1 day) from login)
and
(user_id,date) in (select user_id,min(date) from login group by user_id)
then 1 else 0 end)/
sum(case when
(user_id,date) in (select user_id,min(date) from login group by user_id)
then 1 else 0 end),3)
,0) as p
from login
group by date
order by date
(三)聚合信息:groupby与窗口函数
1、要显示所有信息因此不能直接使用group by后的结果
SQL79 牛客的课程订单分析(三)
【法一】内表找出user_id,外表找出该user_id符合的记录
-- 要显示所有信息因此不能直接使用group by后的结果
-- 先找到符合条件的人
with temp1 as (select user_id from order_info
where date>'2025-10-15'
and status='completed'
and product_name in ('C++','Java','Python')
group by user_id
having count(id)>=2)
-- 再找到符合条件的所有信息
select * from order_info
where user_id in (select * from temp1) -- 注意不能直接写成temp1
and date>'2025-10-15'
and status='completed'
and product_name in ('C++','Java','Python')
order by id
同理也可以不用临时表来写
select * from order_info
where user_id in (select user_id from order_info
where date>'2025-10-15'
and status='completed'
and product_name in ('C++','Java','Python')
group by user_id
having count(id)>=2) -- 注意不能直接写成temp1
and date>'2025-10-15'
and status='completed'
and product_name in ('C++','Java','Python')
order by id
注:
临时表的写法:
with a as (),
b as (),
c as ()
【法二】窗口函数
groupby会把结果聚合成一行,所以如果需要所有信息,就要先内表后外表。但是窗口函数生成结果的行数不变,因此可以直接基于窗口函数做筛选,但是如果where筛选涉及窗口,还是要作为内表的,因为where的逻辑再select之前,但是可以少写很多筛选条件。
select id,user_id,product_name,status,client_id,date
from
(select *,
count(id) over (partition by user_id) as counts
from order_info
where date>'2025-10-15'
and status ="completed"
and product_name in ("C++","Java","Python")
) a
where counts>=2
order by id
2、窗口函数+groupby
SQL80 牛客的课程订单分析(四)
- 思路:最后需要最小日期所以肯定做聚合,做聚合就需要全部信息,所以前一步的计数肯定用到窗口函数
-- 首先在有次数的内表上做筛选,然后基于筛选结果做聚合函数求最小日期
-- 窗口函数+groupby
select user_id,min(date) as first_buy_date,cnt
from
(select *,
count(id) over (partition by user_id) as cnt
from order_info
where date>'2025-10-15'
and status ="completed"
and product_name in ("C++","Java","Python")
) a
where cnt>=2
group by user_id
order by user_id
SQL27 每类试卷得分前3名
select * from
(select tag,er.uid,
row_number() over (partition by tag order by max(score) desc,min(score) desc,uid desc)as ranking
from examination_info ei join exam_record er using(exam_id)
group by uid,tag
) a
where ranking<=3
3、根据两个变量分组
SQL85 实习广场投递简历分析(二)
select job,date_format(date,'%Y-%m') as mon,sum(num) as cnt
from resume_info
where date like '2025%' -- 符合最左前缀匹配原则,也走索引
group by job,mon
order by mon desc,cnt desc;
4、聚合函数不一定要和groupby一起用
当只有一类的情况下,聚合函数不一定要和groupby一起用
【例】SQL14 SQL类别高难度试卷得分的截断平均值
-- 法一:嵌套子函数,因为只有一类,所以不需要groupby直接就可以算出min和max
select tag,difficulty,round(avg(score),1) as clip_avg_score
from exam_record er join examination_info ei on er.exam_id=ei.exam_id
where tag='SQL'
and difficulty='hard'
and score != (select max(score) from exam_record where tag='SQL' and difficulty='hard')
and score != (select min(score) from exam_record where tag='SQL' and difficulty='hard')
-- 法二:窗口函数,正序和倒序两次row_number来找到最大和最小
select tag,difficulty,round(avg(score),1) as clip_avg_score from
(
select tag,difficulty,score,
row_number() over (partition by tag order by score) as rank1,
row_number() over (partition by tag order by score desc) as rank2
from exam_record er join examination_info ei on er.exam_id=ei.exam_id
where tag='SQL' and difficulty='hard' and score is not null
) a
where rank1!=1 and rank2!=1
【例】SQL31 未完成率较高的50%用户近三个月答卷情况
select count(distinct uid) as total_user from exam_record
5、groupby最易错点:select 分组变量/聚合函数
SQL18 月总刷题数和日均刷题数
这里也可以用ifnull,ifnull和coalesce的区别:
ifnull只有两个参数,coalesce有多个参数,返回第一个非空的值
group by with rollup具有汇总加和的功能,但是列名那里自动为null,如果希望有列名,则需要辅助ifnull/coalesce函数
Hive中with rollup和with cude都可以用于group by的汇总,但是当分组依据是三组的情况下,二者呈现出的汇总效果不一样。cube是3222211111,而rollup是321321321。
这里最易错的点在于每月天数的计算
(1)计算每个月的天数可以用函数:day(last_day(time))
(2)也可以自己写:case when month(time) in (1,3,5,7,8,10,12) then 31 else 30 end
(3)最易错的点在于这里用到了groupby month,需要用max(day_of_month)或者min、first、last汇总出唯一结果,这样才不会报错
select coalesce(date_format(submit_time,'%Y%m'),'2021汇总') as submit_month,
count(score) as month_q_cnt,
round(count(score)/max(case when month(submit_time) in (1,3,5,7,8,10,12) then 31 else 30 end),3) as avg_day_q_cnt
FROM practice_record
where year(submit_time)=2021
group by DATE_FORMAT(submit_time, "%Y%m") with rollup
6、根据不同字段group by
问题:
(1)涉及两种不同的groupby:每个人购买每个商品的次数至少两次的人数(筛选)+每种商品的购买人数
(2)因为涉及对其中一个groupby的筛选,因此如果直接在两个groupby的基础上直接再groupby会导致范围不对
-- 法一:在两个字段groupby的表上套一个字段groupby,用if来筛选
SELECT product_id,
ROUND(SUM(repurchase) / COUNT(1), 3) as repurchase_rate
FROM (
SELECT uid, product_id, IF(COUNT(1)>1, 1, 0) as repurchase
FROM tb_order_detail
JOIN tb_order_overall USING(order_id)
JOIN tb_product_info USING(product_id)
WHERE tag="零食" AND event_time >= (
SELECT DATE_SUB(MAX(event_time), INTERVAL 89 DAY)
FROM tb_order_overall)
GROUP BY uid, product_id
) as t_uid_product_info
GROUP BY product_id
ORDER BY repurchase_rate DESC, product_id
LIMIT 3;
-- 法二:直接表连接计算字段
select a.product_id,
ifnull(round(cnt_2/cnt_total,3),0.000) repurchase_rate
from tb_product_info a
left join (select product_id,
count(distinct uid) cnt_total -- 该产品被几个人购买过
from tb_order_detail t1
left join tb_order_overall t2
on t1.order_id = t2.order_id
GROUP BY product_id) b
on a.product_id = b.product_id
left join (select product_id,count(distinct uid) as cnt_2 -- count(1)也可以
from
(select product_id,uid,count(1) as cnt
from tb_order_detail join tb_order_overall using(order_id)
where (DATEDIFF((select max(event_time) from tb_order_overall),date(event_time)) < 90)
group by product_id,uid
having cnt>=2)c
group by product_id)d
on a.product_id = d.product_id
where tag='零食'
order by repurchase_rate desc,product_id
limit 3
(四)排序
1、第n多
用orderby之后limit个数
limit y --读取 y 条数据
limit x, y --跳过 x 条数据,读取 y 条数据
limit y offset x --跳过 x 条数据,读取 y 条数据
2、前n多:窗口函数
【例】leetcode–185. 部门工资前三高的所有员工
select Department,Employee,Salary
from
(select
b.name as Department,
a.Name as Employee,
a.Salary,
dense_rank() over (partition by a.DepartmentId order by a.Salary desc) as salary_rank
from Employee a join Department b
on a.DepartmentId=b.Id) c
where salary_rank<=3
(五)执行顺序
where在join on后
SQL73 考试分数(二)
查询用户分数大于其所在工作(job)分数的平均分的所有grade的属性
- 代码注意点:表连接中如果是唯一字段可以不加表名
select id,grade.job,score from grade
left join (select job,avg(score) as avg_score from grade group by job) a
on grade.job=a.job
where score>avg_score
order by id
(六)统计不同——去重
distinct 会对结果集去重,对全部选择字段进行去重,并不能针对其中部分字段进行去重。使用count distinct进行去重统计会将reducer数量强制限定为1,而影响效率,因此适合改写为子查询。
-- 统计不同的id的个数
select count(distinct id) from table_1
-- 优化版本的count distinct
select count(*) from
(select distinct id from table_1) tb
SQL15 统计作答次数
数行数用count(*)
count(var) 如果var有空值会自动忽略
count(distinct var)在计数时去重
如果是限制var2不要有空值,数var1有多少种,要用到case when
select
count(*) as total_pv,
count(score) as complete_pv, -- 聚合函数计算时会忽略空值
count(distinct case when score is not null then exam_id else null end) as complete_exam_cnt
from exam_record ;
(七)行列转换
tmp_column
select A,B,C from table
lateral view explode(split(column_C,',')) tmp_table as C
-- A,B,column_C 都是原表的列(字段),tmp_table:explode形成的新虚拟表,可以不写;
![]()
select * from table LATERAL VIEW EXPLODE(SPLIT(ab_version, ',')) vidtb AS vid_explode
where vid_explode in ("1262091")
(八)时间函数
# 提取时间
DATE_FORMAT(NOW(),'%Y')
DATE_FORMAT(NOW(),'%m%d')
year()/month()/day()/hour()/minute()/second()/date()
# 转换类型
convert(log_time,date)
# 时间差day
datediff(string enddate, string startdate)
-- datediff函数只能处理'yyyy-MM-dd'这种格式的日期,如果日期形式是'yyyyMMdd'的话,需要进行格式转换
TIMESTAMPDIFF(interval, time_start, time_end)
-- 可计算time_start-time_end的时间差,单位以指定的interval为准:second,minute,hour,day,month,year
# 时间加
date_add(string startdate, int days)
A.T_DATE = B.T_DATE+ interval 1 hour
'2021-09-01 22:11:12'+interval 50 minute
# 时间减
date_sub (string startdate, int days)
A.T_DATE = B.T_DATE+ interval -1 hour
-- 日期(2020-03-21 17:13:39)和unix时间戳(1584782175)之间相互转换
## 日期转化为时间戳 ##
select unix_timestamp('2020-03-21 17:13:39'):得到 1584782019
select unix_timestamp('20200321 13:01:03','yyyyMMdd HH:mm:ss') 得到 1584766863
select unix_timestamp('20200321','yyyyMMdd') 得到 1584720000
## 时间戳转化为日期 ##
select from_unixtime (1584782175) 得到 2020-03-21 17:16:15
select from_unixtime (1584782175,'yyyyMMdd') 得到 20200321
select from_unixtime (1584782175,'yyyy-MM-dd')得到 2020-03-21
## 日期和日期之间,也可以通过时间戳来进行转换 ##
select from_unixtime(unix_timestamp('20200321','yyyymmdd'),'yyyy-mm-dd') 得到 2020-03-21
select from_unixtime(unix_timestamp('2020-03-21','yyyy-mm-dd'),'yyyymmdd')得到 20200321
(九)字符串函数
1、内置函数
-- 1、拼接
-- (1)concat( A, B...)返回将A和B按顺序连接在一起的字符串
select concat('abc', 'def','gh') 得到abcdefgh
concat(round(num,1),'%') # 得到百分数
-- (2)concat_ws(string X, stringA, string B) 返回字符串A和B由X拼接的结果
select concat_ws(',', 'abc', 'def', 'gh') 得到 abc,def,gh
-- (3)根据分组情况连接字段
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
# DISTINCT用来给字段去重
# 默认用逗号分隔
# 等同于先用窗口函数排序再用collect_set去重组合
-- rk根据窗口函数得到
-- 把rankd的name组合在一起方便排序:['001张','002李']
SORT_ARRAY(COLLECT_SET(CONCAT(LPAD(CAST(rk AS STRING), 3, '0'),feature_name)))
-- 把['001张','002李']中的数字去掉:先把列表组合成字符串,然后替换,再根据逗号拆分成数组
split(REGEXP_REPLACE(CONCAT_WS(',', rank), '[0-9]\{3\}', ''),',')
-- 2、分割
substring_index(str,delim,count)
str=www.wikidm.cn
substring_index(str,'.',1) 结果是:www(从左向右数)
substring_index(str,'.',2) 结果是:www.wikidm
substring_index(str,'.',-2) 结果为:wikidm.cn(从右向左数)
substring_index(substring_index(str,'.',-2),'.',1) 结果是:wikidm(中间的数)
-- 3、切片
-- substr/substring(str,start,len) 截取字符串从0位开始的长度为len个字符。如果不加len,默认从start到end。
select substr('abcde',3,2) from iteblog;
-- 得到cd
-- 4、其他
select char_length('abcedfg') # 字符长度为7
## 使用trim(string A) 去除字符串两边的空格
select trim(' abc ') 得到 'abc'
## 使用lower(string A)/ lcase(string A)返回字符串的小写形式,常用于不确定原始字段是否统一为大小写
select lower('abSEd') 得到 absed
## 使用upper(string A)/ ucase(string A)返回字符串的大写形式,常用于不确定原始字段是否统一为大小写
select upper('abSEd') 得到 ABSED
【例】用户行为分析
用户行为表tracking_log

统计用户行为序列为A-B-D的用户数,其中:A-B之间可以有任何其他浏览记录(如C,E等),B-D之间除了C记录可以有任何其他浏览记录(如A,E等)
select count(*)
from(
select user_id,group_concat(opr_id) ubp
from tracking_log
group by user_id
) a
where ubp like '%A%B%D%' and ubp not like '%A%B%C%D%'
# 先提取子表后where筛选
【例】SQL19 未完成试卷数大于1的有效用户
![]()
- 拼接思路:首先字段拼接成新字段,然后是分组后的新字段拼接,要求分组时拼接的字段是不重复的,因此用distinct去重
select uid
, sum(case when submit_time is null then 1 else 0 end) as incomplete_cnt
, sum(case when submit_time is not null then 1 else 0 end) as complete_cnt
, group_concat(distinct CONCAT(DATE_FORMAT(start_time, '%Y-%m-%d'),':',tag) separator ';') as detail
from exam_record er join examination_info ei using(exam_id)
where YEAR(start_time) = 2021
group by uid
having incomplete_cnt>1
and incomplete_cnt<5
and complete_cnt >= 1
order by incomplete_cnt desc
2、正则表达式
regexp_extract 提取
regexp_replace 替换
## regexp_extract(string subject, string pattern, int index)
## 将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符
select regexp_extract('foothebar', 'foo(.*?)(bar)', 1) 得到 the
## regexp_replace(string A, string B, string C)
## 将字符串A中的符合java正则表达式B的部分替换为C
select regexp_replace('foobar', 'oo|ar', '') 得到 fb
get_json_object(string json_string, string path)
第一个参数填写json对象变量,第二个参数使用$表示json变量标识,然后用 . 或 [] 读取对象或数组;
json对象相当于sql中的字典
data =
{
"store":
{
"fruit":[{"weight":8,"type":"apple"}, {"weight":9,"type":"pear"}],
"bicycle":{"price":19.95,"color":"red"}
},
"email":"amy@only_for_json_udf_test.net",
"owner":"amy"
}
hive> select get_json_object(data, '$.owner') from test;
结果:amy
hive> select get_json_object(data, '$.store.bicycle.price') from test;
结果:19.95
hive> select get_json_object(data, '$.store.fruit[0]') from test;
结果:{"weight":8,"type":"apple"}
【例】SQL39 筛选昵称规则和试卷规则的作答记录
select ui.uid,ei.exam_id,round(avg(score)) as avg_score
from exam_record
join user_info ui using(uid)
join examination_info ei using(exam_id)
where (nick_name rlike '^牛客[0-9]+号$' -- ^开头,[0-9]任意一个字符,+一个或多个匹配
or nick_name rlike '^[0-9]+$') -- $结尾
and tag rlike '(c|C).*' -- c或C,.任意字符,*0或多个匹配
and score is not null -- 这一行要加,因为如果哪一行只有一个结果就是空值,就没办法通过avg的计算把null抵消掉
group by uid,exam_id
order by uid,avg_score
(十)类型转换
CAST (expression AS data_type)
可以转换的数据类型:
二进制,同带binary前缀的效果 : BINARY
字符型,可带参数 : CHAR()
日期 : DATE
时间: TIME
日期时间型 : DATETIME
浮点数 : DECIMAL
整数 : SIGNED
无符号整数 : UNSIGNED
SELECT CAST('9.0' AS decimal) 结果:9
SELECT CAST('9.5' AS decimal(10,2)) 结果:9.50
SELECT CAST(NOW() AS DATE) 结果:2017-11-27
cast(exam_cnt_rank_21 as signed) -- 字符串转化为数字
【例】收入区间分组
select id,
(case when CAST(salary as float)<50000 Then '0-5万'
when CAST(salary as float)>=50000 and CAST(salary as float)<100000 then '5-10万'
when CAST(salary as float) >=100000 and CAST(salary as float)<200000 then '10-20万'
when CAST(salary as float)>200000 then '20万以上'
else NULL end
from table_1;
(十一)随机抽样
rand(),rand(int seed)
## 从数据表中随机取两条数据,设定了rand(1)之后,每次跑出来的都是一样的两条数据
select * from dm_growth_da.xdl_test_20200328 order by rand(1) limit 2
(十二)空值null
什么时候需要标记is not null?
(1)当设计窗口函数排序row_number,需要where is not null
(2)count,avg,sum会自动排除null
(3)限制其他变量非空,对该变量计数,则需要写成类似count(distinct case when score is not null then exam_id else null end) as complete_exam_cnt 的形式
【例】SQL15 统计作答次数
- 注意点:count中的casewhen在一般情况下也可以用where来替代,书写上会更加好读,(见下一个例子)但是因为这边要count(*)所以不能用where做统一筛选。
select
count(*) as total_pv,
count(score) as complete_pv, -- 聚合函数计算时会忽略空值
count(distinct case when score is not null then exam_id else null end) as complete_exam_cnt
from exam_record ;
【例】SQL17 平均活跃天数和月活人数
- 思路:因为平均活跃天数的分子是所有用户的活跃天数之和,需要用count来做,所以是根据用户和天来去重(每个用户一天如果登录多次,就记录一次)
select date_format(submit_time, '%Y%m') as month,
round((count(distinct uid, date_format(submit_time, '%y%m%d'))) / count(distinct uid), 2) as avg_active_days, -- 每个人的登录天数count,要对人和天去重distinct
count(distinct uid) as mau
from exam_record
where submit_time is not null # 很关键的非空
and year(submit_time) = 2021
group by month
【例】SQL19 未完成试卷数大于1的有效用户
- count(非空字段)可以等价于sum(case is not null then end)
# 等价于sum(case when submit_time is null then 1 else null end)
select uid
, sum(if(submit_time is null,1,null)) as incomplete_cnt
, sum(if(submit_time is not null,1,null)) as complete_cnt
, group_concat(distinct CONCAT(DATE_FORMAT(start_time, '%Y-%m-%d'),':',tag) separator ';') as detail
from exam_record er join examination_info ei using(exam_id)
where YEAR(start_time) = 2021
group by uid
having incomplete_cnt>1
and incomplete_cnt<5
and complete_cnt >= 1
order by incomplete_cnt desc
# count
SELECT uid,
(count(*)-count(submit_time)) as incomplete_cnt,
count(submit_time) as complete_cnt,
group_concat(distinct concat_ws(':', date(start_time), tag) SEPARATOR ';') as detail
from exam_record left join examination_info using(exam_id)
where year(start_time)=2021
group by uid
having complete_cnt >= 1 and incomplete_cnt BETWEEN 2 and 4
order by incomplete_cnt DESC
null和空值得区别
1、空值不占空间,NULL值占空间。当字段不为NULL时,也可以插入空值。
2、当使用 IS NOT NULL 或者 IS NULL 时,只能查出字段中没有不为NULL的或者为 NULL 的,不能查出空值。
3、判断NULL 用IS NULL 或者 is not null,SQL 语句函数中可以使用IFNULL()函数来进行处理,判断空字符用 =’‘或者<>’'来进行处理。
4、在进行count()统计某列的记录数的时候,如果采用的NULL值,会别系统自动忽略掉,但是空值是会进行统计到其中的。
5、MySql中如果某一列中含有NULL,那么包含该列的索引就无效了。这一句不是很准确。
6、实际到底是使用NULL值还是空值(’’),根据实际业务来进行区分。个人建议在实际开发中如果没有特殊的业务场景,可以直接使用空值。
题目参考:https://blog.csdn.net/fashion2014/article/details/78826299?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522163132590216780269843900%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=163132590216780269843900&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-78826299.pc_search_result_hbase_insert&utm_term=sql&spm=1018.2226.3001.4187