认识k8s中资源申请和探针
在定义pod的部署文件时,还会对所需的资源量进行设置,保证pod的高可用。例如对于一些很重要的pod,不希望这个pod因为集群资源紧张而被驱逐,那么pod的资源设置最好设置成request和limit的值相同。如果按Pod的QoS(Quality of Service)进行分类,那么可以分为三类。
第一类:Guaranteed:pod的每个容器设置的资源需求(CPU/内存)的limits和request的值完全一样。
第二类:Burstable:只要一个容器指定了CPU或者内存的request,requests的limits的值不一样。
第三类:BestEffort:Pod中所有容器都未指定CPU或内存资源需求的requests。
当计算节点检测到内存压力时,Kubernetes会按BestEffort>Burstable>Guaranteed的顺序依次进行驱逐。在实际项目中对于重要的Pod,建议定义Guaranteed来保护重要的pod,对于大多数应用建议采用Burstable的类型,合理评估Pod所需资源后来设置Limit和request的值。下面是pod的yaml文件中定义requests和limits的例子。

对于启动后的pod也可以通过查看yaml文件获取Qos的类型,kubectl get pod podName -oyaml
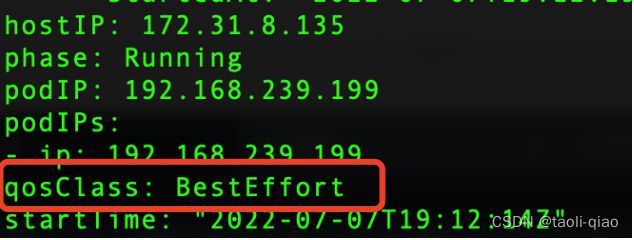
在Pod部署定义的yaml文件中,除了对资源需求进行定义外,还会定义各种类型的探测器,例如存活探测器用来对启动的pod进行持续的健康检查,接下来就看看具体的探针类型和使用。探测器分为活跃(Liveness)、就绪(Readiness)和启动(Startup)探测器。kubelet使用存活探测器来确定什么时候要重启容器,例如,存活探测器可以探测到应用死锁(应用程序在运行,但是无法继续执行后面的步骤)情况。 重启这种状态下的容器有助于提高应用的可用性。kubelet 使用就绪探测器可以知道容器何时准备好接受请求流量,当一个 Pod 内的所有容器都就绪时,才能认为该 Pod 就绪。 这种信号的一个用途就是控制哪个 Pod 作为 Service 的后端。 若 Pod 尚未就绪,会被从 Service 的负载均衡器中剔除。kubelet 使用启动探测器来了解应用容器何时启动。 如果配置了这类探测器,你就可以控制容器在启动成功后再进行存活性和就绪态检查, 确保这些存活、就绪探测器不会影响应用的启动。 启动探测器可以用于对慢启动容器进行存活性检测,避免它们在启动运行之前就被杀掉。
接下来就定义一个存活探测器,具体yaml文件内容如下所示,可以看到pod启动一段时间后会重启,通过describe命令查看,可以看到是因为存活探测器失败,所以会启动kill pod的动作。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -f /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
除了通过shell命令设置liveness prob外,还可以定义httpget的liveness prob,yaml文件内容如下所示,这个liveness prob是访问pod的8080/healthz接口来检测pod的健康状态。
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3除了HttpGet方式,还有TCP方式和gRPC方式,详细信息可以查看官网的文档。
除了定义livenessProbe外,对于有些启动比较耗时的pod,还可以定义startupProbe,防止pod在启动过程中被kill掉,具体yaml例子如下所示,在pod启动过程中,会通过startupProbe探测pod何时真正成功启动了,如果startupProbe成功一次,那么探测活动会被LivenessProbe接管,如果startupProbe一直不成功,那么会在30*10=300s=5minutes时间后kill掉pod里面的容器,然后根据restartPolicy来做下一步操作。
ports:
- name: liveness-port
containerPort: 8080
hostPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 1
periodSeconds: 10
startupProbe:
httpGet:
path: /healthz
port: liveness-port
failureThreshold: 30
periodSeconds: 10上面介绍了探测器,接下来再看看pod的优雅启动和优雅终止。你可能会遇到需要Kubernetes 仅在满足条件时启动 Pod 的情况,例如依赖项正在运行或sidecar 容器已准备就绪。同样,你可能希望在 Kubernetes 终止 pod 之前执行命令,以释放正在使用的资源并优雅地终止应用程序。kubernetes主要通过post-start和pre-stop两类hook来完成优雅启动和终止。下图是post-start和pre-stop两类hook的主要特性。

下面这个例子定义了post-start和pre-stop,创建该pod后,进入pod,查看/bin/sh目录,可以看到打印了具体的信息。
apiVersion: v1
kind: Pod
metadata:
name: lifecycle-demo
spec:
containers:
- name: lifecycle-demo-container
image: nginx
lifecycle:
postStart:
exec:
command: ["/bin/sh", "-c", "echo Hello from the postStart handler > /usr/share/message"]
preStop:
exec:
command: ["/bin/sh","-c","nginx -s quit; while killall -0 nginx; do sleep 1; done"]
下来来看看容器终止的详细过程,通过了解容器终止过程来看看什么情况下应用是无法实现优雅终止的。容器终止的流程如下所示:
- Pod 被删除,状态置为 Terminating。
- kube-proxy 更新转发规则,将 Pod 从 service 的 endpoint 列表中摘除掉,新的流量不再转发到该 Pod。
- 如果 Pod 配置了 preStop Hook,将会执行。
- kubelet对Pod中各个container发送SIGTERM信号以通知容器进程开始优雅停止。
- 等待容器进程完全停止,如果在terminationGracePeriodSeconds内(默认 30s)还未完全停止,就发送SIGKILL 信号强制杀死进程。
- 所有容器进程终止,清理 Pod 资源。
9 - SIGKILL 强制终端
15 - SIGTEM 请求中断
如果容器启动入口使用了 shell,比如使用了类似 /bin/sh -c my-app 或 /docker-entrypoint.sh 这样的 ENTRYPOINT 或 CMD,这就可能会导致容器内的业务进程收不到 SIGTERM 信号,原因是:
- 容器主进程是 shell,业务进程是在 shell 中启动的,成为了 shell 进程的子进程。
- shell 进程默认不会处理 SIGTERM 信号,自己不会退出,也不会将信号传递给子进程,导致业务进程不会触发停止逻辑。
- 当等到 K8S 优雅停止超时时间 (terminationGracePeriodSeconds,默认 30s),发送 SIGKILL 强制杀死 shell 及其子进程。
前面介绍了资源设置、探测器设置、postStart或者preStop hook设置来保证pod的高可用,那么在具体项目中,遇到某些生产事件后,具体的解决策略是什么呢?可能发生的生产事件和对应的建议解决策略如下所示:
