美团一面面经及详细答案

文章目录
-
1.自我介绍
-
2.Spring AOP底层原理
-
3.HashMap的底层数据结构,如何进行扩容的?
-
4.ConcurrentHashMap如何实现线程安全?size()方法是加锁的吗?如何实现的?
-
5.线程池参数
-
6.线程池大小如何设置
-
7.IO密集=Ncpu*2是怎么计算出来
-
8.synchronized的锁优化
-
锁的升级
-
偏向锁
-
轻量级锁
-
自旋锁
-
-
9.常用垃圾回收器
-
10.G1有哪些特点
-
11.MySQL事务隔离级别
-
12.可重复读解决了哪些问题
-
13.脏读 不可重复读 幻读
-
14.聚集索引 非聚集索引
-
15.慢查询优化,会考虑哪些优化
-
16.缓存穿透 缓存击穿 缓存雪崩 以及解决办法
-
17.二叉搜索树中第K小的元素
-
18.反问
推荐阅读:
-
系统设计题面试八股文背诵版
-
面试手册更新,V2.0上线
-
并发编程面试八股文背诵版
-
字节最爱问的智力题,你会几道?(二)
-
MySQL八股文背诵版
-
Java八股文
1.自我介绍
大家好,我是路人zhang,微信号lurenzhang888,经常分享一些面试相关的内容,收藏量已经高达几千,希望大家看的同时帮忙点个在看。
2.Spring AOP底层原理
作为Spring两大核心思想之一的AOP也是一个面试的高频问题
AOP:Aspect Oriented Programming(面向切面编程),和AOP比较像的一个词是OOP,OOP是面向对象编程,而AOP则是建立在OOP基础之上的一种设计思想。而SpringAOP则是实现AOP思想的主流框架
**应用场景:**SpringAOP主要用于处理各个模块的横切关注点,比如日志、权限控制等。
**SpringAOP的思想:**SpringAOP的底层实现原理主要就是代理模式,对原来目标对象创建代理对象,并且在不改变原来对象代码的情况下,通过代理对象,调用增强功能的方法,对原有的业务进行增强。
AOP的代理分为动态代理和静态代理,SpringAOP中是使用动态代理实现的AOP,AspectJ则是使用静态代理实现的AOP。
SpringAOP中的动态代理分为JDK动态代理和CGLIB动态代理。
-
JDK动态代理
**JDK动态代理原理:**基于Java的反射机制实现,必须有接口才能使用该方法生成代理对象。
JDK动态代理主要涉及到了两个类
java.lang.reflect.Proxy和java.lang.reflect.InvocationHandler。这两个类的主要方法如下:java.lang.reflect.Proxy:java.lang.reflect.InvocationHandler:篇幅有限,就不展开介绍了,大致流程如下:
-
实现
InvocationHandler接口创建方法调用器 -
通过为 Proxy 类指定
ClassLoader对象和一组interface创建动态代理 -
通过反射获取动态代理类的构造函数,参数类型就是调用处理器接口类型
-
通过构造函数创建动态代理类实例,构造时调用处理器对象作为参数传入
-
Object invoke(Object proxy, Method method, Object[] args)该方法主要定义了代理对象调用方法时所执行的代码。 -
static InvocationHandler getInvocationHandler(Object proxy),该方法用于获取指定代理对象所关联的调用处理器 -
static Class getProxyClass(ClassLoader loader, Class... interfaces),该方法主要用于返回指定接口的代理类 -
static boolean isProxyClass(Class cl),该方法主要用于返回 cl 是否为一个代理类 -
static Object newProxyInstance(ClassLoader loader, Class[] interfaces, InvocationHandler h)该方法主要用于构造实现指定接口的代理类的实例,所有的方法都会调用给定处理器对象的invoke()方法
-
-
CGLib 动态代理原理:利用ASM开源包,对代理对象类的class文件加载进来,通过修改其字节码生成子类来处理。
SpringAOP何时使用JDK动态代理,何时使用CGLiB动态代理?
-
当Bean实现接口时,使用JDK动态代理。
-
当Bean没有实现接口时,使用CGlib动态代理
3.HashMap的底层数据结构,如何进行扩容的?
非常高频的面试题
底层数据结构:
-
JDK1.7的底层数据结构(数组+链表)
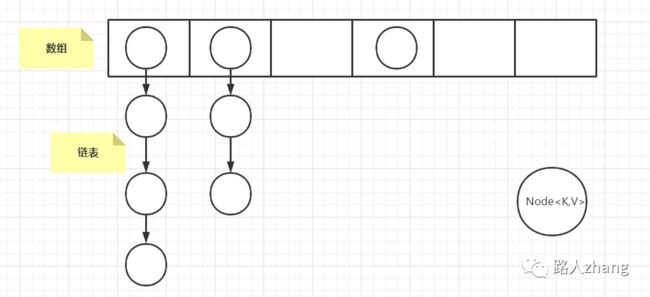
-
JDK1.8的底层数据结构(数组+链表)

扩容机制:
-
初始值为16,负载因子为0.75,阈值为负载因子*容量
-
resize()方法是在hashmap中的键值对大于阀值时或者初始化时,就调用resize()方法进行扩容。 -
每次扩容,容量都是之前的两倍
-
扩容时有个判断
e.hash & oldCap是否为零,也就是相当于hash值对数组长度的取余操作,若等于0,则位置不变,若等于1,位置变为原位置加旧容量。源码如下:
final Node
4.ConcurrentHashMap如何实现线程安全?size()方法是加锁的吗?如何实现的?
如何实现线程安全?
JDK1.7和JDK1.8在实现线程安全上略有不同
-
JDK1.7采用了分段锁的机制,当一个线程占用锁时,会锁住一个Segment对象,不会影响其他Segment对象。
-
JDK1.8则是采用了CAS和
synchronize的方式来保证线程安全。
size()方法是加锁的吗?如何实现的?
这个问题本质是ConcurrentHashMap是并发操作的,所在在计算size时,可能还会进行并发地插入数据,ConcurrentHashMap是如何解决这个问题的?
在JDK1.7会先统计两次,如果两次结果一致表示值就是当前ConcurrentHashMap的大小,如果两次不一样,则会对所有的segment都进行加锁,统计一个准确的值。代码如下:
/**
* Returns the number of key-value mappings in this map. If the
* map contains more than Integer.MAX_VALUE elements, returns
* Integer.MAX_VALUE.
*
* @return the number of key-value mappings in this map
*/
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment[] segments = this.segments; //map数据从segments中拿取
int size;
boolean overflow; // 判断size是否过大会溢出
long sum; //
long last = 0L; //最近的一个sum值
int retries = -1; // 重试的次数
try {
for (;;) { //一直循环统计size直到segment结构没有发生变化
if (retries++ == RETRIES_BEFORE_LOCK) { //如果已经重试2次,到达第三次
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); //对segment加上锁
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock(); //对segment解锁
}
}
return overflow ? Integer.MAX_VALUE : size;
}
在JDK1.8中是这样实现的:
public int size() {
long n = sumCount();
return ((n < 0L) ? 0 :
(n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n);
}
ConcurrentHashMap的容量大小可能会大于int的最大值,所以JDK建议使用mappingCount()方法,而不是size()方法:
public long mappingCount() {
long n = sumCount();
return (n < 0L) ? 0L : n;
}
不过这两个方法的关键点都是sumCount(),其代码如下:
final long sumCount() {
CounterCell[] as = counterCells; CounterCell a;
long sum = baseCount;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
从上面代码可以看出 sumCount()方法就是统计sum的过程,通过使用baseCount和遍历counterCells统计sum
其中counterCells的定义如下:
/**
* Table of counter cells. When non-null, size is a power of 2.
*/
private transient volatile CounterCell[] counterCells;
baseCount的定义如下:
/**
* Base counter value, used mainly when there is no contention,
* but also as a fallback during table initialization
* races. Updated via CAS.
*/
private transient volatile long baseCount;
当容器大小改变时就会通过addCount()改变baseCount
/**
* Adds to count, and if table is too small and not already
* resizing, initiates transfer. If already resizing, helps
* perform transfer if work is available. Rechecks occupancy
* after a transfer to see if another resize is already needed
* because resizings are lagging additions.
*
* @param x the count to add
* @param check if <0, don't check resize, if <= 1 only check if uncontended
*/
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if ((as = counterCells) != null ||
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { //cas操作使得 baseCount加1
CounterCell a; long v; int m;
boolean uncontended = true;
if (as == null || (m = as.length - 1) < 0 ||
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
!(uncontended =
U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) {
fullAddCount(x, uncontended); //高并发导致CAS失败时执行
return;
}
if (check <= 1)
return;
s = sumCount();
}
if (check >= 0) {
Node[] tab, nt; int n, sc;
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
从上述代码可以看出,首先会CAS地更新baseCount的值,如果存在并发,CAS失败的线程则会进行方法中,后面会执行到fullAddCount()方法,该方法就是在初始化counterCells, 这也解释了为什么在 sumCount()中通过baseCount和遍历counterCells统计sum,所以在JDK1,8中size()是不加锁的
....博主太懒了字数太多了,不想写了....文章已经做成PDF,有需要的朋友可以私信我免费获取!