2.2 Apache Hadoop、HDFS - Apache Hadoop集群搭建
文章目录
- Apache Hadoop集群搭建
-
- 一、Hadoop集群简介
-
- Hadoop集群整体概述
- 思考
- Hadoop集群简介
- 二、Hadoop集群模式安装(Cluster mode)
-
- 思路
- Hadoop源码编译
- Step1:集群角色规划
- Step2:服务器基础环境准备
- Step3:上传安装包、解压安装包
- Step4:Hadoop安装包目录结构
- Step5:编辑Hadoop配置文件(0)
- Step5:编辑Hadoop配置文件(1)
- Step5:编辑Hadoop配置文件(2)
- Step5:编辑Hadoop配置文件(3)
- Step5:编辑Hadoop配置文件(4)
- Step5:编辑Hadoop配置文件(5)
- Step5:编辑Hadoop配置文件(6)
- Step6:分发同步安装包
- Step7:配置Hadoop环境变量
- 总结
- Step8:NameNode format(格式化操作)
- 总结
- 三、Hadoop集群启停命令、Web UI
-
- 手动逐个进程启停
- shell脚本一键启停
- 进程状态、日志查看
- HDFS集群
- YARN集群
- 四、Hadoop初体验
-
- HDFS 初体验
- 思考
- MapReduce+YARN 初体验
- 思考
Apache Hadoop集群搭建
一、Hadoop集群简介
Hadoop集群整体概述
- Hadoop集群包括两个集群:HDFS集群、YARN集群
- 两个集群逻辑上分离、通常物理上在一起
- 两个集群都是标准的主从架构集群

HDFS集群:NN,DN,SNN
YARN集群:RM,NM
思考
- 如何理解两个集群逻辑上分离?
- 如何理解两个集群物理上在一起?
- 为什么没有MapReduce集群?有这样的说法吗?
Hadoop集群简介
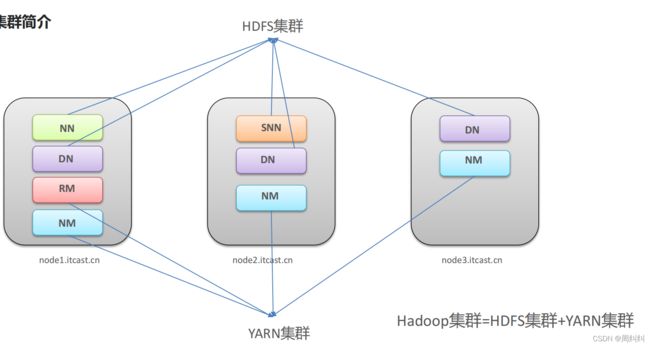
例中所配置的HDFS集群:一个主角色NN,一个辅助SNN,三个从角色DN
YARN集群:一个主角色RM,三个从角色NM
两个组件共同构成Hadoop集群
- 逻辑上分离
两个集群互相之间没有依赖、互不影响(启动互不影响) - 物理上在一起
某些角色进程往往部署在同一台物理服务器上 - MapReduce集群呢?
MapReduce是计算框架、代码层面的组件没有集群之说
二、Hadoop集群模式安装(Cluster mode)
思路
- 可以根据课程一步一步自己动手搭建Hadoop集群。
- 也可以直接使用虚拟机快照切换至搭建好的环境。
Hadoop源码编译

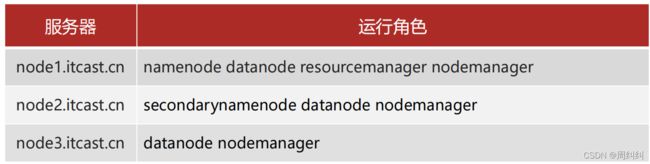
Step1:集群角色规划
- 角色规划的准则
根据软件工作特性和服务器硬件资源情况合理分配
比如依赖内存工作的NameNode是不是部署在大内存机器上? - 角色规划注意事项
资源上有抢夺冲突的,尽量不要部署在一起
工作上需要互相配合的。尽量部署在一起
Step2:服务器基础环境准备
打开软件 FinalShell
- 都发送 点击下面命令,输入命令,设置发送至全部会话
- 1、主机名(3台机器都验证一下)
vim /etc/hostname
[root@node3 ~]# cat /etc/hostname
node3.itcast.cn
您在 /var/spool/mail/root 中有新邮件
- 2、Hosts映射(3台机器验证)
cat /etc/hosts
[root@node3 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.88.151 node1 node1.itcast.cn
192.168.88.152 node2 node2.itcast.cn
192.168.88.153 node3 node3.itcast.cn
- 3、防火墙关闭(3台机器)
systemctl stop firewalld.service #关闭防火墙(当前)
systemctl disable firewalld.service #禁止防火墙开启自启(永久)
systemctl status firewalld.service #验证
[root@node3 ~]# systemctl stop firewalld.service
您在 /var/spool/mail/root 中有新邮件
[root@node3 ~]# systemctl disable firewalld.service
[root@node3 ~]# systemctl status firewalld.service #验证
● firewalld.service - firewalld - dynamic firewall daemon
Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
Docs: man:firewalld(1)
- 4、ssh免密登录(node1执行->node1|node2|node3) 从一台机器访问另一台机器免密登录
ssh-keygen #4个回车 生成公钥、私钥
ssh-copy-id node1、ssh-copy-id node2、ssh-copy-id node3 #
验证:
ssh node1
exit
ssh node2
- 5、集群时间同步(3台机器)
yum -y install ntpdate
ntpdate ntp4.aliyun.com
ntpdate ntp5.aliyun.com
[root@node1 ~]# ntpdate ntp5.aliyun.com
7 May 21:25:29 ntpdate[11515]: adjust time server 203.107.6.88 offset -0.134916 sec
[root@node1 ~]# date
2022年 05月 07日 星期六 21:26:21 CST
您在 /var/spool/mail/root 中有新邮件
- 6、创建统一工作目录(3台机器)
mkdir -p /export/server/ #软件安装路径
mkdir -p /export/data/ #数据存储路径
mkdir -p /export/software/ #安装包存放路径
验证
[root@node1 ~]# ls /export/
data server software
Step3:上传安装包、解压安装包
- 上传、解压jdk安装包(node1)上传安装包到/export/server 解压
上传:打开下方目录,点击export/server,将课程资料“jdk-8u241-linux-x64.tar.gz”拖拉进去
查看:cd /export/server
[root@node1 ~]# cd /export/server
您在 /var/spool/mail/root 中有新邮件
[root@node1 server]# ll
总用量 189988
-rw-r--r-- 1 root root 194545143 5月 7 21:31 jdk-8u241-linux-x64.tar.gz
解压
tar -zxvf jdk-8u241-linux-x64.tar.gz
删除安装包
[root@node1 server]# rm -rf jdk-8u241-linux-x64.tar.gz
- 配置环境变量
vim /etc/profile
使用快捷键大G小o跳转到最后一行的下一行进行编辑
将下面的代码复制到最后
export JAVA_HOME=/export/server/jdk1.8.0_241
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
shift +zz 保存退出(esc 命令格式)
重新加载环境变量文件,让其生效
source /etc/profile
- 验证
[root@node1 server]# java -version
java version "1.8.0_241"
Java(TM) SE Runtime Environment (build 1.8.0_241-b07)
Java HotSpot(TM) 64-Bit Server VM (build 25.241-b07, mixed mode)
您在 /var/spool/mail/root 中有新邮件
- 远程拷贝给其它两台机器
scp -r /export/server/jdk1.8.0_241/ root@node2:/export/server/
scp -r /export/server/jdk1.8.0_241/ root@node3:/export/server/
拷贝环境变量
scp /etc/profile root@node1:/etc/
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
三台机器重新加载配置环境
source /etc/profile
验证
java -version
Step4:Hadoop安装包目录结构
上传安装包‘’hadoop-3.3.0-Centos7-64-with-snappy.tar.gz‘’ 到/export/server
- 上传:打开下方目录,点击export/server,将课程资料“hadoop-3.3.0-Centos7-64-with-snappy.tar.gz”拖拉进去
- 进入路径:
cd /export/server - 查看:
ll - 解压到当前路径下:
tar -zxvf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
- 查看:
ll - 删除安装包
rm -rf hadoop-3.3.0-Centos7-64-with-snappy.tar.gz
- 查看文件:
[root@node1 server]# cd hadoop-3.3.0/
[root@node1 hadoop-3.3.0]# ll
总用量 84
drwxr-xr-x 2 root root 203 7月 15 2021 bin
drwxr-xr-x 3 root root 20 7月 15 2021 etc
drwxr-xr-x 2 root root 106 7月 15 2021 include
drwxr-xr-x 3 root root 20 7月 15 2021 lib
drwxr-xr-x 4 root root 288 7月 15 2021 libexec
-rw-rw-r-- 1 root root 22976 7月 5 2020 LICENSE-binary
drwxr-xr-x 2 root root 4096 7月 15 2021 licenses-binary
-rw-rw-r-- 1 root users 15697 3月 25 2020 LICENSE.txt
-rw-rw-r-- 1 root users 27570 3月 25 2020 NOTICE-binary
-rw-rw-r-- 1 root users 1541 3月 25 2020 NOTICE.txt
-rw-rw-r-- 1 root users 175 3月 25 2020 README.txt
drwxr-xr-x 3 root root 4096 7月 15 2021 sbin
drwxr-xr-x 3 root root 20 7月 15 2021 share

Step5:编辑Hadoop配置文件(0)
配置文件概述
- 官网文档:https://hadoop.apache.org/docs/r3.3.0/
- 第一类1个:hadoop-env.sh
- 第二类4个:xxxx-site.xml ,site表示的是用户定义的配置,会覆盖default中的默认配置。
core-site.xml 核心模块配置
hdfs-site.xml hdfs文件系统模块配置
mapred-site.xml MapReduce模块配置
yarn-site.xml yarn模块配置 - 第三类1个:workers
所有的配置文件目录:/export/server/hadoop-3.3.0/etc/hadoop
修改配置文件
- 配置文件路径 hadoop-3.3.0/etc/hadoop
查看是否在安装包目录下
[root@node1 hadoop-3.3.0]# pwd
/export/server/hadoop-3.3.0
进入etc/
[root@node1 hadoop-3.3.0]# cd etc/
进入hadoop
[root@node1 etc]# ll
总用量 4
drwxr-xr-x 3 root root 4096 7月 15 2021 hadoop
[root@node1 etc]# cd hadoop/
[root@node1 hadoop]# pwd
/export/server/hadoop-3.3.0/etc/hadoop
Step5:编辑Hadoop配置文件(1)
- hadoop-env.sh
vim hadoop-env.sh
大G小o跳转到文件最后一行的下一行
复制粘贴一下代码到最后一行
export JAVA_HOME=/export/server/jdk1.8.0_241
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
shift+zz 保存退出
Step5:编辑Hadoop配置文件(2)
- core-site.xml
vim core-site.xml
在两个中间,按下小o,插入一行,复制下面代码
<configuration>
<!-- 设置默认使用的文件系统 Hadoop支持file、HDFS、GFS、ali|Amazon云等文件系统 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 设置Hadoop本地保存数据路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/export/data/hadoop-3.3.0</value>
</property>
<!-- 设置HDFS web UI用户身份 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 整合hive 用户代理设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 文件系统垃圾桶保存时间 -->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
</configuration>
shift zz 保存退出
Step5:编辑Hadoop配置文件(3)
- hdfs-site.xml
vim hdfs-site.xml
在两个在两个中间,按下 i 插入复制的下面代码
<!-- 设置SNN进程运行机器位置信息 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node2:9868</value>
</property>
shift zz 保存退出
Step5:编辑Hadoop配置文件(4)
- mapred-site.xml
vim mapred-site.xml
在两个中间,按下 i 插入复制的下面代码
<!-- 设置MR程序默认运行模式: yarn集群模式 local本地模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>node1:10020</value>
</property>
<!-- MR程序历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node1:19888</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
shift zz 保存退出
Step5:编辑Hadoop配置文件(5)
- yarn-site.xml
vim yarn-site.xml
删除注释 用dd命令
<configuration>
<!-- Site specific YARN configuration properties --> ##dd删除
</configuration>
在两个中间,按下 i 插入复制的下面代码
<!-- 设置YARN集群主角色运行机器位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 是否将对容器实施物理内存限制 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!-- 是否将对容器实施虚拟内存限制。 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 开启日志聚集 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 历史日志保存的时间 7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
shift zz 保存退出
Step5:编辑Hadoop配置文件(6)
- workers
vim workers
dd命令删除默认的localhost
按 i 插入下面代码
node1.itcast.cn
node2.itcast.cn
node3.itcast.cn
shift zz 保存退出
Step6:分发同步安装包
- 在node1机器上将Hadoop安装包scp同步到其他机器
cd /export/server
scp -r hadoop-3.3.0 root@node2:$PWD
scp -r hadoop-3.3.0 root@node3:$PWD
Step7:配置Hadoop环境变量
- 在node1上配置Hadoop环境变量
vim /etc/profile
快捷键大G小o,来到当前文件最后一行的下一行编辑,粘贴下面代码
export HADOOP_HOME=/export/server/hadoop-3.3.0
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
shift zz 保存退出
- 将修改后的环境变量同步其他机器
scp /etc/profile root@node2:/etc/
scp /etc/profile root@node3:/etc/
- 重新加载环境变量 验证是否生效(3台机器)-命令发送至所有会话
source /etc/profile
- 验证环境变量是否生效(3台机器)-命令发送至所有会话
hadoop

总结
- 服务器基础环境
- Hadoop源码编译
- Hadoop配置文件修改
- shell文件、4个xml文件、workers文件
- 配置文件集群同步
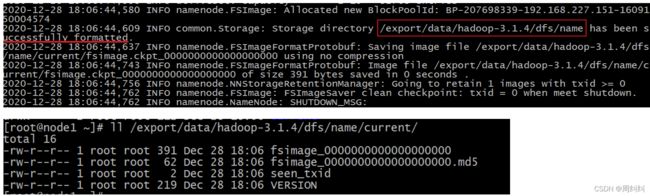
Step8:NameNode format(格式化操作)
格式化-初始化操作
-首次启动HDFS时,必须对其进行格式化操作。- 只能格式化一次
- format本质上是初始化工作,进行HDFS清理和准备工作
ctrl + l 清屏 - 输入命令(node1)
hdfs namenode -format
判断
总结
- 首次启动之前需要format操作;
- format只能进行一次 后续不再需要;
- 如果多次format除了造成数据丢失外,还会导致hdfs集群主从角色之间互不识别。通过删除所有机器hadoop.tmp.dir目录重新format解决
三、Hadoop集群启停命令、Web UI
两种方式:手动逐个进程启停、 shell脚本一键启停
手动逐个进程启停
- 每台机器上每次手动启动关闭一个角色进程,可以精准控制每个进程启停,避免群起群停。
- HDFS集群
#hadoop2.x版本命令
hadoop-daemon.sh start|stop namenode|datanode|secondarynamenode
#hadoop3.x版本命令
hdfs --daemon start|stop namenode|datanode|secondarynamenode
- YARN集群
#hadoop2.x版本命令
yarn-daemon.sh start|stop resourcemanager|nodemanager
#hadoop3.x版本命令
yarn --daemon start|stop resourcemanager|nodemanager
shell脚本一键启停
- 在node1上,使用软件自带的shell脚本一键启动。
- 前提:配置好机器之间的SSH免密登录和workers文件。
- HDFS集群
启动
start-dfs.sh
停止
stop-dfs.sh
- YARN集群
start-yarn.sh
stop-yarn.sh
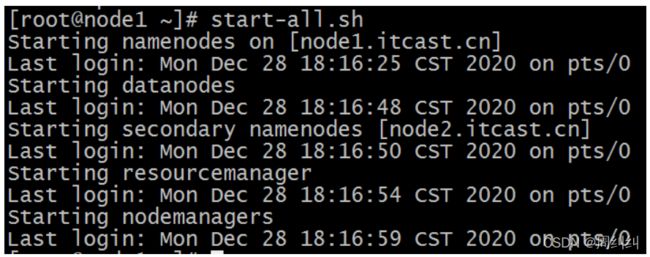
- Hadoop集群
start-all.sh
stop-all.sh
- 查看是否启动成功
jps
第一台机器DN,NN
[root@node1 server]# jps
84502 Jps
83099 DataNode
82906 NameNode
第二台机器DN,SNN
[root@node2 ~]# jps
82529 DataNode
82704 SecondaryNameNode
85662 Jps
第三台机器DN
[root@node3 ~]# jps
82552 DataNode
85151 Jps
进程状态、日志查看
- 启动完毕之后可以使用jps命令查看进程是否启动成功

- Hadoop启动日志路径:/export/server/hadoop-3.3.0/logs/ ,通过日志排查问题出在哪

HDFS集群
- 地址:http://namenode_host:9870
其中namenode_host是namenode运行所在机器的主机名或者ip如果使用主机名访问,别忘了在Windows配置hosts
http://node1:9870

- HDFS文件系统Web页面浏览
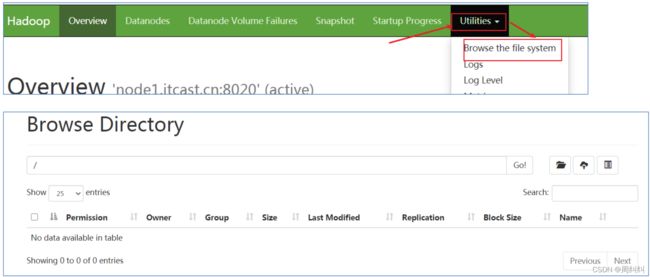
YARN集群
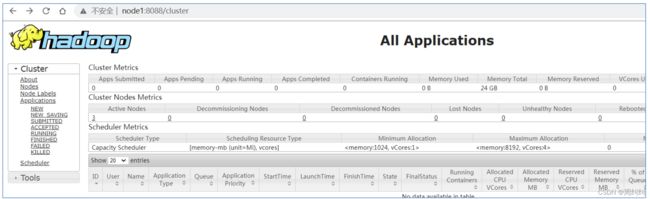
- 地址:http://resourcemanager_host:8088
其中resourcemanager_host是resourcemanager运行所在机器的主机名或者ip
如果使用主机名访问,别忘了在Windows配置hosts
http://node1:8088
四、Hadoop初体验
HDFS 初体验
- shell命令操作 (Finalshell 操作)
hadoop fs -mkdir /itcast
hadoop fs -put zookeeper.out /itcast
hadoop fs -ls /
例子
[root@node1 server]# hadoop fs -ls /
您在 /var/spool/mail/root 中有新邮件
[root@node1 server]# hadoop fs -mkdir /itcast
[root@node1 server]# hadoop fs -ls /
Found 1 items
drwxr-xr-x - root supergroup 0 2022-05-08 15:27 /itcast
[root@node1 server]#
再点击web页面,可以看到新增新增的目录

将本地文件上传到itcast目录下,再点击web页面查看
[root@node1 server]# echo 1 >1.txt
[root@node1 server]# ll
总用量 4
-rw-r--r-- 1 root root 2 5月 8 15:34 1.txt
drwxr-xr-x 11 root root 227 5月 8 11:33 hadoop-3.3.0
drwxr-xr-x 7 10143 10143 245 12月 11 2019 jdk1.8.0_241
[root@node1 server]# hadoop fs -put 1.txt /itcast
- Web UI页面操作

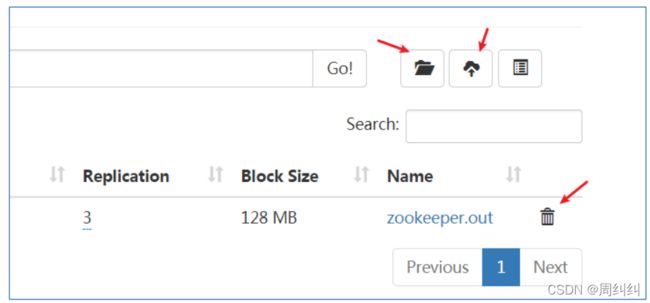
新建路径、上传文件、删除文件
思考
1. HDFS本质就是一个文件系统
2. 有目录树结构 和Linux类似,分文件、文件夹
3. 为什么上传一个小文件也这么慢?
MapReduce+YARN 初体验
- 执行Hadoop官方自带的MapReduce案例,评估圆周率π的值。
cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 4
[root@node1 server]# cd /export/server/hadoop-3.3.0/share/hadoop/mapreduce/
您在 /var/spool/mail/root 中有新邮件
[root@node1 mapreduce]# ll
总用量 5276
-rw-r--r-- 1 root root 589704 7月 15 2021 hadoop-mapreduce-client-app-3.3.0.jar
-rw-r--r-- 1 root root 803842 7月 15 2021 hadoop-mapreduce-client-common-3.3.0.jar
-rw-r--r-- 1 root root 1623803 7月 15 2021 hadoop-mapreduce-client-core-3.3.0.jar
-rw-r--r-- 1 root root 181995 7月 15 2021 hadoop-mapreduce-client-hs-3.3.0.jar
-rw-r--r-- 1 root root 10323 7月 15 2021 hadoop-mapreduce-client-hs-plugins-3.3.0.jar
-rw-r--r-- 1 root root 50701 7月 15 2021 hadoop-mapreduce-client-jobclient-3.3.0.jar
-rw-r--r-- 1 root root 1651503 7月 15 2021 hadoop-mapreduce-client-jobclient-3.3.0-tests.jar
-rw-r--r-- 1 root root 91017 7月 15 2021 hadoop-mapreduce-client-nativetask-3.3.0.jar
-rw-r--r-- 1 root root 62310 7月 15 2021 hadoop-mapreduce-client-shuffle-3.3.0.jar
-rw-r--r-- 1 root root 22637 7月 15 2021 hadoop-mapreduce-client-uploader-3.3.0.jar
-rw-r--r-- 1 root root 281197 7月 15 2021 hadoop-mapreduce-examples-3.3.0.jar
drwxr-xr-x 2 root root 4096 7月 15 2021 jdiff
drwxr-xr-x 2 root root 30 7月 15 2021 lib-examples
drwxr-xr-x 2 root root 4096 7月 15 2021 sources
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.3.0.jar pi 2 4

再返回YARN web页面去查看状态
思考
- 执行MapReduce的时候,为什么首先请求YARN?
- MapReduce看上去好像是两个阶段?先Map,再Reduce?
- 处理小数据的时候,MapReduce速度快吗?
参考
资料来源于《黑马程序员-大数据Hadoop入门》