存算一体 – 智能驾驶AI芯片的下一个战场
交流群 | 进“滑板底盘群”请加微信号:xsh041388
交流群 | 进“域控制器群”请加微信号:ckc1087
备注信息:滑板底盘/域控制器+真实姓名、公司、岗位
引言:
随着AI技术逐渐渗透到各大应用场景,市场对算力的需求呈现爆发式增长。而驱动集成电路产业发展的摩尔定律已逼近极限,在后摩尔时代,依靠传统冯·诺依曼架构的芯片将很难跟得上算力需求不断快速增长的步伐,芯片产业亟需在底层计算架构层面进行创新。存算一体技术可有效突破芯片性能瓶颈,是解决算力提升放缓和算力需求快速增长之间尖锐矛盾的一种关键技术路径。
本文将围绕以下问题进行深入的探讨,包括一些对业内资深人士的访谈。
1) 什么是存算一体?
2) 存算一体的主要玩家有哪些?
3) 为什么说存算一体大算力AI芯片契合智能驾驶应用场景?相比传统架构AI芯片,它在智能驾驶场景下的竞争优势又是什么?
4) 存算一体芯片企业在技术开发和商业化落地过程中将面临哪些挑战?又该如何克服?
正文:
1、 存算一体 - 突破冯·诺依曼架构瓶颈的关键技术
1.1 传统冯·诺依曼架构面临的问题
随着摩尔定律逐渐趋近于极限,基于冯·诺依曼架构AI芯片的“存储墙”和“功耗墙”问题日益凸显,芯片算力的增长速度变得越来越慢。
1)“存储墙”
在冯·诺依曼架构中,数据存储与数据处理在物理上是两个相互分离的单元,在数据处理过程中,处理器与存储器之间需要不断地通过数据总线交换数据。处理器性能以每2年3.1倍的速度增长,而内存性能以每2年1.4倍的速度提升,导致存储器的数据访问速度越来越跟不上处理器的数据处理速度。处理器的性能与效率因此受到严重制约,从而出现了“存储墙”。
2)“功耗墙”
在冯·诺依曼架构中,数据在处理过程中需要不断地从存储器单元“读”数据到处理器单元中,处理完之后再将结果“写”回存储器单元。数据在存储器与处理器之间的频繁迁移将带来严重的传输功耗问题。根据英特尔的研究显示,半导体工艺到了7nm时代,数据搬运功耗达到35pJ/bit,占比达63.7%。数据传输所导致的功耗损失越来越成为芯片发展的制约因素,由此形成“功耗墙”问题。
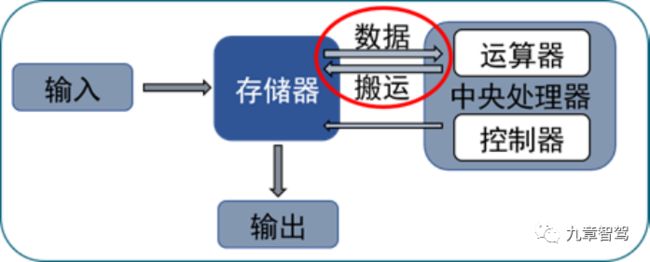
冯·诺依曼架构
(图片来源:https://mp.weixin.qq.com/s/o27-O60-5BeZ_-pyjRh_3g)
在AI计算平台上,面对海量的数据,“存储墙”和“功耗墙”的问题愈发用凸显,成为整个计算平台的掣肘。目前业内正在研究的解决方案有:稀疏化计算、复杂AI算子、推理时延+存储位宽和存算一体等。而存算一体作为“后摩尔时代”的一大技术发展方向,被一些从业人士认为是当前比较有效,且接近商业化落地的解决方案。
1.2 什么是存算一体
存算一体,是指将以计算为中心的架构转变为以数据为中心的架构,存储功能和计算功能有机融合,直接利用存储单元进行数据处理 —— 通过修改“读”电路的存内计算架构,可以在“读”电路中获取运算结果,并将结果直接“写”回存储器的目的地址,不再需要在计算单元和存储单元之间进行频繁的数据转移,消除了数据搬移带来的开销,不仅极大降低了功耗,还大大提升了计算效率。
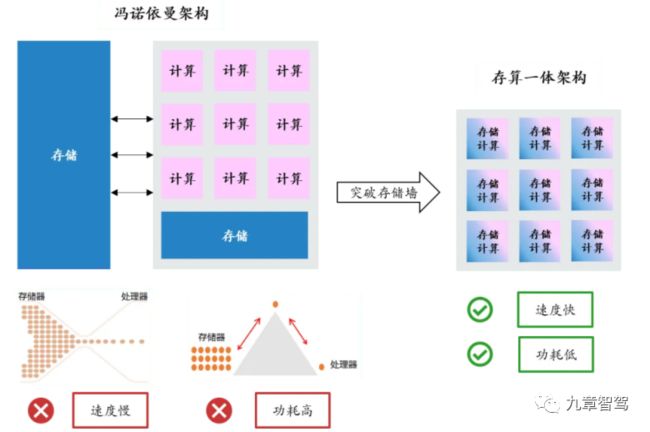 冯·诺依曼架构VS存算一体架构
冯·诺依曼架构VS存算一体架构
(图片来源:https://mp.weixin.qq.com/s/xVIwN1CZ4rAmLzYpXJVD7Q)
达摩院计算技术实验室科学家郑宏忠曾讲过:“存算一体是颠覆性的芯片技术,它天然拥有高性能、高带宽和高能效的优势,可以从底层架构上解决后摩尔定律时代芯片的性能和能耗问题。”
后摩尔时代,芯片如何突破算力瓶颈?
1.3 存算一体的不同实现路径
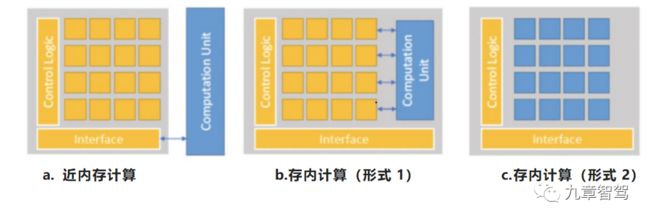
关于存算一体类型的划分,目前在学术界和产业界尚无统一的定义。目前主流的划分方式:依照计算单元与存储单元的关系,存算一体大致可分为近内存计算和存内计算两种技术路线。
近内存计算是指计算操作由位于存储芯片外部的独立计算单元完成。在不改变计算单元和存储单元本身设计功能的前提下,通过采用先进的封装方式以及合理的硬件布局和结构优化,增强二者间通信带宽,增大数据传输速率,进而提高数据处理效率。
存内计算又可分为两种形式,计算都是在存储器内部完成,只是在实现形式上有所不同。一种形式如下图b所示,在物理形式上,存储单元和计算单元还是相互独立存在,计算操作由位于存储芯片内部的独立计算单元完成。另外一种形式如下图c所示,存储单元和计算单元完全融合,没有独立的计算单元,直接通过在存储器颗粒上嵌入算法,由存储器芯片内部的存储单元完成计算操作。
(图片来源:https://blog.csdn.net/m0_37046057/article/details/121172739)
近内存计算架构在本质上还是属于冯·诺依曼架构,只不过通过拉近存储单元和计算单元的距离,对“存储墙”和“功耗墙”的问题进行弱化。在存内计算架构的计算范式中,主处理模块给存储阵列发送请求和输入数据,而存储阵列则直接返回计算结果,这一架构可以从根本上打破冯诺依曼计算架构的瓶颈。
存内计算架构的两种形式中,相比形式1,形式2的存内计算才是一种真正意义上的存算一体。这种形式不再需要单独的计算部件来处理数据,彻底消除了数据在存储和计算部件之间频繁来回传输所带来的延迟和功耗。
后摩智能联合创始人信晓旭认为,形式1的存内计算也是为了充分解决“内存墙”的问题,但毕竟数据存储单元和计算单元是分离的,需要把计算单元分成很多份,数据才方便被传输进去做处理。挑战在于对编译器要求会更高,因为需要把一个模型跑在成千上万个小的计算单元,调度策略会比较复杂,设计难度也会更大。假如说现在这种结构设计可以做到500TOPS,下一代需要提升到1000TOPS,那么计算单元就要切得更碎,调度策略就更加复杂,同时算力越往上提升带来的边际收益也会越低。
而形式2的存内计算相比于形式1的存内计算,对编译器的要求相对要低一些,并且未来可提升的空间也更大。
1.4 存储介质的选择
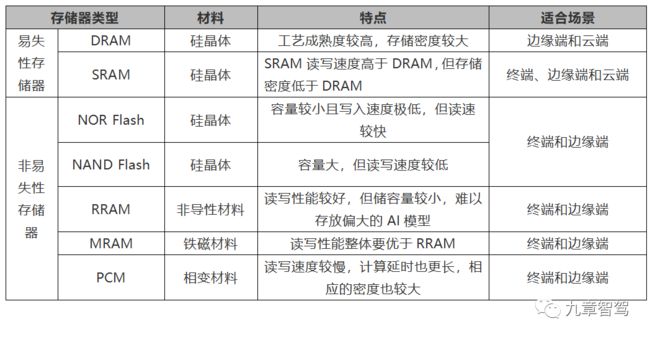
存算一体芯片的存储介质主要可分为两大类:一种是易失性存储器,即在正常关闭系统或者突然性、意外性关闭系统的时候,数据会丢失,如SRAM和DRAM等;另一种是非易失性存储器,在上述情况下数据不会丢失,如传统的闪存NOR Flash 和 NAND Flash,以及新型存储器 - 阻变存储器RRAM(ReRAM)、磁性存储器MRAM、铁变存储器FRAM(FeRAM)、相变存储器PCRAM(PCM)等。
易失性存储器和非易失性存储器
(来源:根据公开资料整理)
1)SRAM和DRAM作为易失性存储器,工艺偏差会大幅度增加模拟计算的设计难度,但工艺成熟度较高,相比新型的非易失性存储器,可以较快地实现技术落地和量产应用 。
2)Flash、RRAM以及MRAM等非易失性存储器可以保证数据掉电不丢失,从而实现即时开机/关机操作,减小静态功耗,延长待机时间,非常适用于功耗受限的边缘和终端设备。
易失性存储器和非易失性存储器各有特点,那么做存算一体芯片的初创企业在选择存储介质的时候究竟需要从哪些维度去考虑呢?
后摩智能创始人兼CEO吴强告诉九章智驾:“选择存储介质需主要看几个方面:一看它的性能 - 读的性能、写的性能、擦写次数等;二要看它的密度和功耗,另外也要看它的工艺成熟度和具体应用场景的实际需求等。
“非易失性存储器,比如NAND Flash和NOR Flash,在工艺上最为成熟,但在“写”的性能上,要比RRAM和MRAM差很远,并且成本也比较高。在非易失性存储器里,RRAM和MRAM的性能是大家公认最好的,同时存储密度也可以做得很大。”
在智能驾驶的车端场景下,非易失性是否是必须的呢?吴强认为,对于智能驾驶场景,直观来看,非易失性的作用不是特别大,因为当智能驾驶车辆在开启的时候,系统需要一直处于运算状态,一旦车不用了就会直接关掉。如果要增加‘哨兵模式’这种应用场景 —— 需要车辆长时间“待命”,比如说要在机场停一个礼拜或者一个月,非易失性就会起较大的作用,因为这种特性可以保证在车辆熄火断电的情况下,控制芯片也能够保持足够长的待机时间。
2、 存算一体芯片主要玩家
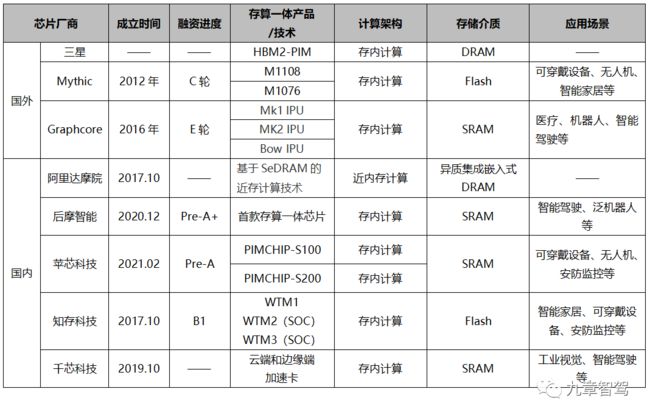
备注:由于国外存算一体公司公开信息相对较少,故重点整理了其中主要三家企业的基本信息
2.1 国外主要玩家
2.1.1 三星
产品名称:HBM2-PIM
发布时间:2021年2月
存储介质:DRAM
实现方案:将4片常规DRAM die和4片具有计算功能的DRAM die通过TSV通孔垂直组合在一起。其中具有计算功能的DRAM die内部集成了计算逻辑单元,即将AI引擎引入每个存储子单元,从而将处理操作转移到HBM。每个存储子单元都有一个嵌入式可编程计算单元(PCU),其运行频率为300 MHz,每个裸片上(PIM-DRAM die)有32个PCU。
主要参数:
算力:1.2 TFLOPS
制程:20nm
计算精度支持:FP16
数据传输速率:2.4Gbps
2.1.2 Mythic
融资进程:2021年5月获得 7000 万美元的 C 轮融资,累计融资金额1.652 亿美元
产品特点:基于区块的AI 计算架构——内存计算、数据流架构和模拟计算
1)第一代产品名称:M1108 AMP
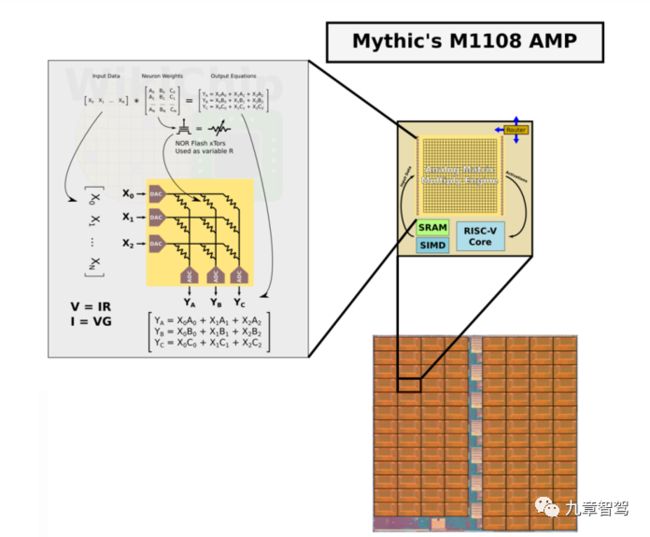
M1108 AMP内部构成
(图片来源:https://mp.weixin.qq.com/s/i-Q2hF9bTdU6Ezyp7w5aeg)
推出时间:2020年11月
存储介质:Flash
实现方案:由108个AMP切片(title)构成,每个切片内部集成一系列闪存单元、ADC阵列、1个32位RISC纳米处理器、1个SIMD矢量引擎、SRAM和1个片上网络(NOC)路由器。
主要参数:
算力:32TOPS
制程:40nm
能效:35/4 TOPS/W
面积:360mm²
带宽:2GB/s
计算精度支持: INT4、INT8 和 INT16
应用场景:无人机、机器人、可穿戴设备等。
2)第二代产品:M1076 AMP
推出时间:2021年6月
存储介质:Flash
实现方案:由72个AMP切片构成,每个切片内部集成一系列闪存单元、ADC阵列、1个32位RISC纳米处理器、1个16位SIMD矢量处理器、 SRAM和1个片上网络(NOC)路由器。
主要参数:
算力:25TOPS
制程:40nm
能效:25/3 TOPS/W
面积:295mm²
带宽:2GB/s
计算精度支持: INT4、INT8 和 INT16
应用场景:智能家居、安防监控、可穿戴设备等。
2.1.3 Graphcore
融资进程:2020年12月完成 E轮2.22亿美元融资
产品特点:IPU同时支持训练和推理。它的基本硬件处理单元是IPU-Core,采用大规模并行MIMD架构,而非GPU的 SIMD/SIMT架构。
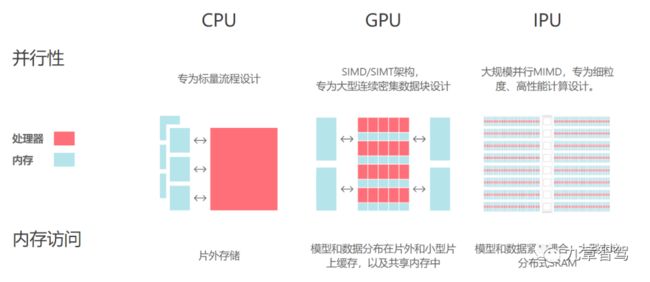
CPU、GPU和IPU三者架构的区别
(图片来源:Graphcore官网)
1)第二代产品:Colossus MK2 IPU
推出时间:2020年7月
存储介质:SRAM
实现方案:内部集成1472个IPU-Core,具有594亿个晶体管,900MB的片内存储,能够处理8832个独立并行程序。
主要参数:
算力:250TFLOPS
制程:7nm
计算精度支持:FP16
面积:823mm²
应用场景:医疗、机器人、智能驾驶等。
2)第三代产品:Bow IPU
推出时间:2022年3月
存储介质:SRAM
实现方案:采用3D Wafer-on-Wafer(WoW)技术封装,把两个晶圆结合在一起产生一个新的3D裸片,其中一个晶圆用于AI处理,另一个晶圆拥有供电裸片。在供电裸片中添加了深沟槽电容器,位于处理内核和存储旁,用于供电。内部集成1472个IPU-Core,具有600亿个晶体管,900MB的片内存储,能够处理8832个独立并行程序。
性能参数:
算力:350TFLOPS
制程:7nm
计算精度支持:FP16
吞吐量:65.4 TB/s
应用场景:医疗、机器人、智能驾驶等。
2.2 国内主要玩家
2.2.1 阿里达摩院
技术名称:基于SeDRAM的近内存计算
发布时间:2021年12月
存储介质:DRAM
实现方案:在基于SeDRAM的存算芯片中,AI电路和外围电路,包括控制、I/O 和 DFT,被布置到一个逻辑计算芯片上,基于“混合键合(Hybrid Bonding)”的3D堆叠技术进行芯片封装,将逻辑计算芯片和存储芯片face-to-face用特定金属材质和工艺互联。
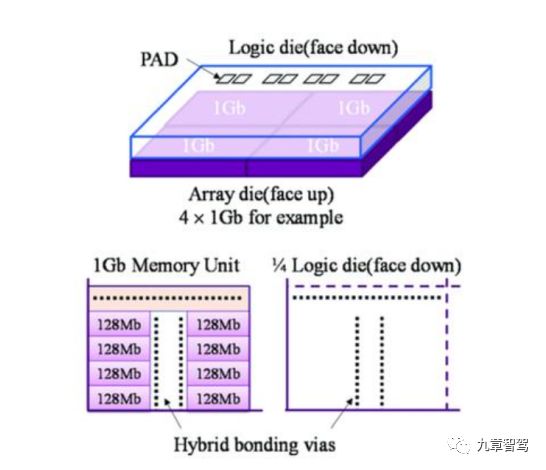
基于SeDRAM的近内存计算技术
(图片来源:https://mp.weixin.qq.com/s/s6F-Npn_CuqM6xd_Ni4mng)
主要参数:
片上内存带宽:37.5GB/s/mm²
吞吐率能效:184QPS/W
存储密度:64Mb/mm²
2.2.2 后摩智能
融资进程:2022年4月,完成数亿元Pre-A+轮融资
存储介质:首款芯片采用SRAM存储介质,以后会使用RRAM/MRAM
项目进展:2022年5月,首款存算一体芯片成功点亮
主要参数(首款存算一体芯片):
制程:22nm
算力:20-200TOPS
能效:20TOPS/W
应用场景:智能驾驶、泛机器人等。
2.2.3 苹芯科技
融资进程:2021年8月完成近千万美元 Pre-A 轮融资
产品名称:PIMCHIP-S100和PIMCHIP-S200
存储介质:SRAM
主要参数:
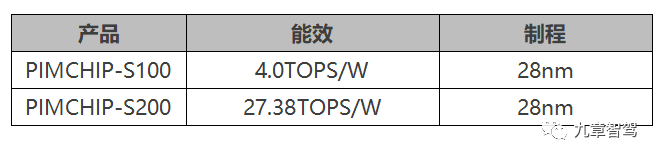
应用场景:可穿戴设备、无人机、安防监控等。
2.2.4 知存科技
融资进展:2022年1月完成完成2亿元B1轮融资
产品名称:WTM1001和WTM2101
存储介质:Flash
封装形式:WTM1001 - QFN48,WTM2101-WLCSP
主要参数:
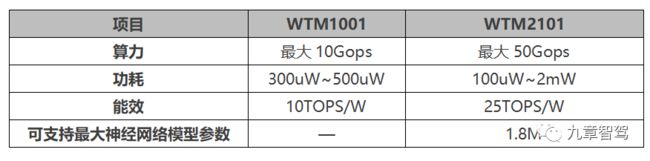
应用场景:智能家居、可穿戴设备、安防监控等
2.2.5 千芯科技
主要产品: AI加速卡和AI计算IP核
存储介质:SRAM
AI加速卡主要参数:
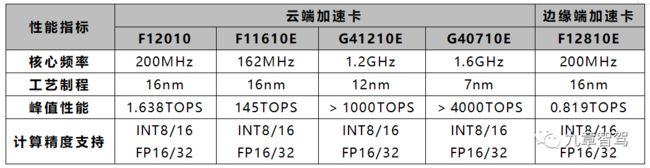
应用场景:工业视觉、医药计算、智能驾驶、商品推荐等。
2.3 市场前景
知存科技CEO王绍迪曾提到:“存内计算的发展类似于存储器的发展路径,随着设计能力不断提升、工艺不断成熟,算力每年可以有5-10倍提升,能效每年会有1-2倍提升,成本每年会有30-50%下降,未来的存算产品可以用在大多数AI应用场景,因为它成本、算力、能效都可以做到最优。”
中早期的存算一体芯片算力较小,更多地应用在对低功耗和高能效有强烈需求的端侧场景,比如智能家居场景下的智能语音和轻量级视觉层面的应用。随着存算一体芯片算力不断提升,其使用范围逐渐扩展到边缘端以及云端的大算力应用领域。
3、存算一体大算力AI芯片与智能驾驶
在智能驾驶技术的迭代升级过程中,传感器配置越来越高 ,所需处理的非结构化数据越来越多,并且算法模型也越来越复杂,驱动算力需求日益增长。大算力AI芯片是解决这些问题的关键,但算力并非AI芯片评价的唯一指标,需要同时兼顾功耗、能效、成本等多重因素。
当前,基于传统架构的大算力AI芯片在智能驾驶的车端场景下还面临功耗、散热以及成本等多方面问题的挑战。因此,智能汽车对在能效和成本上更有优势的大算力存算一体AI芯片的需求更为迫切。
虽然目前国内有不少做存算一体芯片的初创公司,但是重点布局在智能驾驶领域的企业还很少。后摩智能作为国内做存算一体大算力AI芯片的先行者,已经投入大量资源入局智能驾驶领域。带着对存算一体技术的一些疑问,九章智驾对后摩智能的创始人兼CEO吴强以及两位联合创始人项之初和信晓旭进行了专访,以下是访谈中重点内容的整理。
九章智驾:后摩智能为什么选择用存算一体技术去做大算力AI芯片?
吴强:怎样去做大算力AI芯片,特别是在国内如何去做,是我们在创业初期一直思考的问题。基于传统架构的芯片公司,还是偏向于依赖摩尔定律,但不管是从成本问题、功耗问题,还是后续芯片的可扩展性等问题的角度考虑,初创公司都不太适合用传统的方式去做这件事情。
出于这样的考虑,我们当时重点考察了针对后摩尔时代的一些先进芯片技术。最终,我们发现存算一体技术是最有效,也最接近商业落地,因此我们选择了用该项技术去做大算力AI芯片。
九章智驾:从技术本身来讲,存算一体的概念由来已久,之前的存算一体大都是基于NOR Flash、一种纯粹模拟的方法去做,只能做一些小算力芯片,用于智能家居和可穿戴设备等一些AIOT场景。随着大数据和人工智能等应用场景需求的推动,以及新兴半导体工艺和新兴存储技术等各方面技术的发展,是否可以认为在国内做大算力存算一体芯片的时机已经成熟?
吴强:一些技术上的突破,让基于存算一体做大算力芯片成为可能。一方面是从存算电路到存算架构层面的技术都有了较大的进展,尤其是在2018年以后,一些人开始用纯数字或者数字和模拟混合的方法去做存算一体的电路设计,可以把算力做得很大。另一方面是一些新型存储介质的发展,包括 MRAM或者RRAM,促进了大算力存算一体技术的发展。总体来说,大算力存算一体芯片确实是到了可落地的时间点,这是我们的一个判断。我们希望今年就能推出给客户送测的东西,并让其很快就能落地。
九章智驾:大算力AI芯片适用于云端和边缘端的很多场景,为什么后摩智能要选择从智能驾驶这个场景切入?
项之初:其实我们内部是做过一个战略的推演,把云端、安防、AIOT、泛机器人以及智能驾驶等各个赛道都推演了一遍,然后再去审视哪个市场是现在最有机会让我们切进去。所选赛道的下游市场既不能太分散,也不能太集中,同时这个市场至少目前是变动的,如果已经是一成不变的市场,新的芯片厂商要往里切入将会非常困难。对一个AI芯片公司来说,不能只看自己的技术能干什么,还要看市场需要什么,这个市场是不是既有高的天花板,同时也存在一个让后来者进入的机会,而智能驾驶恰好是符合这些条件一个市场。
吴强:用存算一体技术做大算力AI芯片,对先进制程依赖度不是很强,可以用较低的制程实现较大算力,同时可以兼顾成本和能效,因此非常适合智能驾驶应用场景。
第一,相比于传统的冯·诺依曼架构,存算一体技术可以在比较低的成本下把算力做大,因为它对先进工艺的依赖性不是那么强。基于传统架构的AI芯片,如果要做到单芯片1000TOPS,基本上是需要上HBM才有可能达到这个算力。如果用存算一体技术,也许我们不需要HBM,也不需要5nm、7nm这些先进的制程就可以做出单芯片1000TOPS算力。
第二,存算一体芯片能效非常高,数据计算和数据存储深度融合,既避免了大部分数据的无效搬运,同时也能够使芯片可以做更深度的优化,进而使能效有一个数量级的提升。存算一体技术是底层架构层面的创新,是有这个提升空间的。
最后,存算一体芯片避免了大量数据的搬运,大幅缩短了系统响应时间,在节省功耗的同时,时延可以做得更好,车的安全性也能有一个较大程度的提升。
九章智驾:在智能驾驶领域,面对英伟达、高通等传统架构芯片巨头,作为新型计算架构AI芯片领域的初创公司,后摩智能应如何立足?
吴强:首先,我们是选择了一个相对来说壁垒不太深的领域。以传统架构芯片巨头英伟达为例,在云端这个领域,它到现在已经布局了将近快20年,壁垒特别深,在车端,英伟达有壁垒,CUDA壁垒的确也很强 ,但还没有到后来者无法进入的地步。因此,我们的策略是从相对蓝海的边缘端 - 智能驾驶车端领域切入,避开英伟达最深的云端训练软件生态壁垒。
其次,我们需要在硬件上做出一些有竞争力的差异点出来,去解决现有产品不能解决的一些痛点问题。比如在智能驾驶领域,现有一些芯片功耗太高,并且必须用水冷,散热设计更复杂,导致成本更高,而我们的芯片功耗可以做到很低,散热用自然风冷就可以。基于这些优势,客户可能就会去克服用一个新软件上的麻烦而去用我们的芯片了。
九章智驾:存算一体技术本身是一门技术壁垒极高的设计方法学,需要多年的经验积累以及大量的资源投入才有可能将其商业化落地。存算一体作为大算力AI芯片的重要技术实现手段,在实际开发过程中还面临电路设计、架构设计、软件开发以及底层工艺等诸多层面难题。后摩智能作为国内存算一体大算力AI芯片的先行者,又是如何克服开发过程中遇到的一些问题呢?
吴强:首先,从底层工艺上来讲,我们的第一代产品和第二代产品的工艺是分开的。第一代采用的SRAM存储工艺。SRAM是比较成熟的存储介质,没有多少工艺的问题。第二代产品采用MRAM和RRAM,是会存在一些工艺性的问题,我们也在跟一些晶圆厂紧密合作去解决这些问题。
其次,不管是一代还是二代,都有电路设计的问题,架构设计的问题,软件编译器的问题,包括我们怎么做DFT,怎么做后端,这些都是我们必须面对的,我们怎么克服呢?
第一,坚持“小步快跑”的原则,每次我们只往前走一步,技术上是小步快跑,5~10倍的提升足够了,不需要100倍的提升,不需要像学术界那样搞那么大的覆盖度。
第二,需要同时具备较强的学术原创能力和工程实践能力。恰好我们有在学术方面本身就是做存算的架构设计和编译器设计的人,懂得如何去做存算一体的架构和编译器设计、存算相关的量化算法开发等;同时我们还有之前在NVIDIA、TI、AMD、华为海思等公司做过工程开发的人,有很强的场景理解能力以及芯片落地能力,这两拨人有效融合在一起,才有可能把这条路趟出来。现在把芯片做出来已经不是最难的事情了,难的是做出来之后还能够让其规模化落地,这是决定一个芯片企业生死的胜负手。
九章智驾:存算一体芯片产业化尚处于起步阶段,会面临产业链上游支撑不足,下游应用不匹配的诸多困局。在这样的背景下,后摩智能又该如何更好地实现存算一体芯片的工程化落地?
吴强:很多学术背景出身的创业者,他们希望第一步就做得非常的先进,那么很可能就会与现实的情况脱离,甚至出现产品在商业化落地过程中需要的工具都没有。我在工业界已经做了20年,并且我们团队也是工业背景的人做主导。我们的理念是 - 做产品是一个循序渐进的过程,不一定追求学术上这么先进,比如一个产品,好多人觉得如果在学术上没有做到100倍的提升是不值得做的,但是对于我们做产品来说,不一定非得100倍,有5~10倍的提升即可,我们需要先把它做出来,然后再慢慢迭代。
我们刚开始做大算力存算一体芯片,选用了相对成熟的储存介质- SRAM,在计算模式上采用一个纯数字或者数字跟模拟混合的设计。从量产的角度来说,其实它相当于是一个纯定制的SRAM,没有什么商业化层面的挑战,更多的是设计层面的挑战,比如编译器怎么做,量化算法怎么做,架构设计怎么做,而所有的这些技术层面的挑战都已经在内部消化掉了。
项之初:我们最开始的存算一体产品一定是基于现有的工具链,不需要新的EDA工具,是在现有的设计和制造的体系下去做,用一些大家比较熟悉和常规的数字设计工具,在这些工具的基础上需要什么再自己去开发。所有工程化的整个流程与传统AI芯片都是一样的,也不依赖于特殊的工艺,可以在台积电做,也可以在中芯国际做。
九章智驾:存算一体技术要得到大规模落地应用,离不开与芯片厂商、软件工具厂商以及应用集成厂商等产业生态合作伙伴的大力协同研发和推广应用。后摩智能作为整个存算一体AI芯片产业生态的一员,如何去培育自己的软件生态?
吴强:首先,我们得有一个差异化,并且有竞争力的产品,这是一个敲门砖,如果连门都进不来,何谈自己的软件生态; 其次,一定要提供一套方便、可用的软件,让客户迁移进来不是那么的困难。在这些基础上,如果大家觉得工具链和软件好用,再鼓励大家去共享。客户用习惯了,就会有第三方在上面开发工具和库,紧接着又会有第四方又在第三方上面进行开发,慢慢就形成了一个软件生态。
我们坚持两点原则,第一个原则是要兼容现有的软件生态,让客户用起来“无感”。在智能驾驶领域,大算力AI芯片主要是用于做AI推理。我们不会要求客户去改变现阶段训练所用的东西,直接利用现有GPU训练的这一套软件框架。第二个原则是逐渐引导客户去用一些我们新的东西,把我们自己的生态优势慢慢地发挥出来。我们会提供一些工具链,让大家更好地利用存算一体的优势,比如在GPU训练出模型以后,我们要提供一套类似TensorRT这样的一套工具链,可以对大部分模型做适配、压缩或者等量化等。这样的工具要能够把这些训练模型转化到我们的芯片上去跑,并且让系统的性能有一个较大程度地提升。
信晓旭:生态也不是在最开始想去做就能做成的,往往任何一个公司最开始都是在某一个垂直的领域做的特别成功之后,然后把它的技术栈和能力逐渐的外溢,进而逐渐形成了它的生态。可以回看一下历史,X86也是在PC领域获得成功后,技术栈外溢到了其他领域,比如工控机和服务器市场。我们也是一样的,先基于我们存算一体的技术,能够打造出一个产品的长板,先让客户用起来,进而在智能驾驶这个领域站住脚,最后再把它的技术栈外溢到诸如泛机器人和云端等市场。
结语:
1)摩尔定律趋近于极限,芯片性能的提升不仅要面临“存储墙”和“功耗墙”的制约,同时还要应对采用先进制程和高级封装工艺带来的成本压力,业内亟需寻找新的芯片技术方向进行突破。
2)随着智能驾驶技术的迭代升级,智能汽车对算力的需求越来越大;并且,智能汽车作为一个边缘端设备,相比云端,对成本和功耗更为敏感。存算一体技术通过将计算功能和存储功能有机融合,可有效降低甚至消除数据频繁搬运带来的功耗问题,并且能够在不依赖于先进工艺的情况下,做出大算力芯片,能够同时兼顾能效和成本,可破解当前传统架构大算力AI芯片的所面临的一些困局,是智能驾驶场景下被业内人士迫切期待的一种高能效AI芯片架构的技术实现路径。
3)存算一体作为一种新型计算架构,当前正处于从学术界向工业界迁移的关键时期,仍然存在一些技术开发和工程化落地层面的问题,需要相关的芯片厂商、软件工具厂商以及应用集成厂商等产业生态合作伙伴相互协作,共同构建存算一体芯片产业生态。

参考资料:
1. 存算一体技术及其最新发展趋势
https://mp.weixin.qq.com/s/i7PvxpR23ZWMM2t74GEchA
2. 存算一体芯片,人工智能时代的潜力股
https://mp.weixin.qq.com/s/zn6ho1WpLlD41EnfdKyfSQ
3. 清华高滨:基于忆阻器的存算一体单芯片算力可能高达1POPs
https://cj.sina.com.cn/articles/view/2118746300/7e4980bc02000zda0
4. 黄如院士 | 存内计算—突破冯·诺依曼架构瓶颈
https://mp.weixin.qq.com/s/o27-O60-5BeZ_-pyjRh_3g
5. 阿里达摩院最新存算芯片技术解读
https://mp.weixin.qq.com/s/s6F-Npn_CuqM6xd_Ni4mng
6. 知存科技王绍迪:存算一体AI芯片如何打破“内存墙”困局?
https://mp.weixin.qq.com/s/aqn2prJcPTdHV0Xg0Ek_TQ
7. 存内计算,要爆发了?
https://mp.weixin.qq.com/s/PkJDADkQjUhCDrNOyUc8bg
写在最后
与作者交流
如果希望与文章作者直接交流,可以直接扫描右方二维码,添加作者本人微信。

注:加微信时务必备注您的真实姓名、公司、岗位等信息,谢谢!
关于投稿
如果您有兴趣给《九章智驾》投稿(“知识积累整理”类型文章),请扫描右方二维码,添加工作人员微信。

注:加微信时务必备注您的真实姓名、公司、岗位
以及投稿意向等信息,谢谢!
“知识积累”类稿件质量要求:
A:信息密度高于绝大多数券商的绝大多数报告,不低于《九章智驾》的平均水平;
B:信息要高度稀缺,需要80%以上的信息是在其他媒体上看不到的,如果基于公开信息,需要有特别牛逼的独家观点才行。多谢理解与支持。
推荐阅读:
◆九章 - 2021年度文章大合集
◆当候选人说“看好自动驾驶产业的前景”时,我会心存警惕——九章智驾创业一周年回顾(上)
◆数据收集得不够多、算法迭代得不够快,就“没人喜欢我”————九章智驾创业一周年回顾(下)
◆行泊一体 - 打通智能驾驶的“任督二脉”
◆L4自动驾驶公司降维做L2前装量产,前景如何?
◆仅有“模式跑通”是不够的——矿山无人驾驶进入深水区