als算法参数_Pyspark推荐算法实战(一)
作者:丁永兵
作者简介:NLP、推荐算法
1. 前言
由于最近转向商品推荐的工作,因此从本文起,开始介绍一些利用pyspark在推荐算法中的具体应用。
目前最新版本的spark已经出到2.4.5,我们主要使用的还是2.3版本,所以后续涉及代码开发,全部基于2.3.4版本。
首先看下pyspark的算法包内容,pyspark算法包主要有ml和mllib两个库,这 两个库从图一看到,整体内容基本一致,都能满足我们日常的算法需求,不过从2.0开始,mllib主要进行维护状况,不再新增功能,加上ml库与scikit-learn使用非常类似,对于经常使用后者建模的同学来说,ml能够非常快速入手,建议更多时候使用ml算法包。如图所示,ml中提供fpm:频繁项挖掘和recommendation 两个算法包,帮助快速落地推荐算法,下面就这两块内容进行详细介绍,并进行代码开发实现。

图一 pyspark算法工具包内容
2. pyspark中频繁项挖掘算法实现
fpm下主要包含两类算法:FPGrowth和PrefixSpan,PrefixSpan算法主要挖掘序列模式的数据,其记录元素具有时间上的先后关系,与我们常见的购物篮分析数据不是同一个场景,在此就不再赘述。
FPGrowth是韩嘉炜等人于2000年提出的一种关联分析算法,其核心思想是构建一颗频繁模式树。
相比较于Apriori算法,FPGrowth计算速度大大优于前者,前者需要根据项数多次扫描数据库,直到没符合要求的项集存在为止,而FPGrowth仅需扫描两次,计算量大大降低:
第1次扫描获取各个元素的频率,去掉不满足支持度要求的项,并对符合的元素从大到小排序;
第2次扫描建立一颗FP-Tree树。
针对算法具体细节,有兴趣同学可以搜索些文章了解下,比较容易理解,不再说明了,下面就FPGrowth的实际使用进行代码说明。
先看下官网给出的模型操作示例代码
>>> from pyspark.sql.functions import split>>> data = (spark.read... .text("data/mllib/sample_fpgrowth.txt")... .select(split("value", "\s+").alias("items")))>>> data.show(truncate=False)+------------------------+|items |+------------------------+|[r, z, h, k, p] ||[z, y, x, w, v, u, t, s]||[s, x, o, n, r] ||[x, z, y, m, t, s, q, e]||[z] ||[x, z, y, r, q, t, p] |+------------------------+>>> fp = FPGrowth(minSupport=0.2, minConfidence=0.7)模型需要的每行记录要求为一个array,将购物篮所涉及的商品列表组合在一起,因此,需要先按照订单进行汇总整理。
如图所示,下面是一个我们最常见的产品销量统计表:
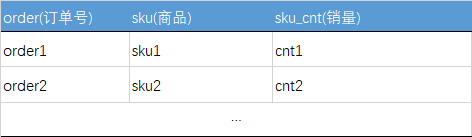
图二 销售样例数据
1. 按订单汇总整理数据
a.先利用spark sql的concat_ws将每个订单下的sku_id汇总拼接成一个字符串。
sql = """ SELECT order_id, concat_ws(',',sku_id) as sku_list, FROM goods_data GROUP BY order_id"""b. 将字段进行切割,并将数据转换为一个array进行存储
sdf = sdf.withColumn("sku_array", split( sdf["sku_list"], ",").cast(ArrayType(StringType())))2. 模型训练使用
模型训练就比较简单了,跟sklearn类似,直接定义好模型参数,指定要分析的字段名称,设置好支持度和置信度的阈值,fit即可,非常简单。
from pyspark.ml.fpm import FPGrowthfpGrowth = FPGrowth(itemsCol="sku_array", minSupport=0.001, minConfidence=0.1)model = fpGrowth.fit(sdf)3.模型结果解读
针对得到的模型,主要使用freqItemsets和associationRules两项内容。
a.freqItemsets 为各频繁项组合的频率结果,打印表结构,可以看到只有两个字段items表示组合列表,freq表示该组合在数据集出现的频数。
freq = model.freqItemsets# 查看结果内容freq.printSchema()root |-- items: array (nullable = false) | |-- element: string (containsNull = true) |-- freq: long (nullable = false)b.associationRules 为各频繁项组合前后项的置信度统计,打印表结构,可以看到antecedent前项商品组合,consequent表示后项商品组合,confidence为置信度,表示前项出现出现的情况下,后项商品出现的概率。
Rules=model.associationRulesRules.printSchema()root |-- antecedent: array (nullable = false) | |-- element: string (containsNull = true) |-- consequent: array (nullable = false) | |-- element: string (containsNull = true) |-- confidence: double (nullable = false)通过对结果的频繁项进行组合筛选,即可得到我们想要的购物篮商品组合结果,下面介绍下协同过滤算法在pyspark中的使用。
3. pyspark中recommendation算法包使用
spark的recommendation算法包更过分,仅且只包含一种算法——ALS算法,简单程度让本人以为是不是没下载安装好。
从协同过滤算法的分类来看,相对于更入门的User CF或Item CF的协同过滤算法,ALS算法属于User-Item CF,算是一种混合协同过滤算法,同时考虑是User和Item两方面,模型一般情况下优于前面两种算法。
对于User-Item矩阵,一般该矩阵非常大,而且元素非常稀疏,所以在推荐系统实践中,常常需要利用矩阵分解的方式来间接使用User-Item矩阵。不同于线性代数中的svd ,在推荐算法实践中,借鉴了svd的思想,最终求得两个矩阵矩阵P,Q,使得其乘积无限接近与原始矩阵R:
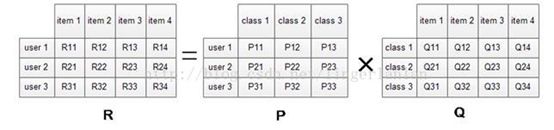
图三 用户商品矩阵分解
此处两个矩阵P可以认为用户对各商品品类的偏好,而Q可以认为是商品都属于哪些商品品类,从而使用P和Q来代替R,更好的实践我们的工程项目中。
算法最核心的思想是构建两个小的稠密矩阵X,Y,通过这两个矩阵来替代原始的R矩阵:
![]()
要讲下面算法的具体实现细节,需要回过头再简单提下,协同过滤涉及用户反馈行为的分类:
显性反馈行为:用户有明确表示物品喜欢的行为,比如电影、音乐评分等
隐性反馈行为:不能明确反映用户喜好的行为,比如电商购物。
显性反馈比较容易理解,隐性反馈比较复杂些,用户购买了某个商品,并不代表他喜欢,他可能是买来送人的,也可能他买了之后发现不喜欢。显性反馈的数值,如评分越高表示越喜欢,而隐性反馈中,用户多次购买一个商品,说明用户喜欢这个商品的置信度较高。
针对我们购物的实际场景,常将购物数量作为权重,所以某些人称该模型为一种“加权的正则化矩阵分解”模型,再加一些正则处理,模型损失函数修正为:
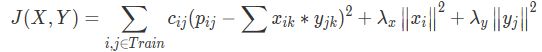
其中:
pij表示用户对商品的偏好,由用户对商品的购买量决定:

cij表示用户对某商品喜欢程度的置信度,一般使用cij=1+arij,此处a表示置信参数,可以根据交叉验证的方式获取
针对上述目标函数,常见的求解方式,一种可以通过梯度下降的方式;另外一种,即通过ALS算法求解,ALS全称交替最小二乘法,做法简单描述如下:
随机初始化X、Y;
固定X(或Y)的情况下,使用最小二乘的方法计算Y(或X),然后反过来,不断迭代,直到符合终止条件为止;
理论的部分已经说完了,下面来看下具体实现:
a.按人统计商品销量数据
sql = """ SELECT user_id, sku_id, sku_cnt FROM goods_data GROUP BY order_id, sku_id"""b.模型训练使用
此处使用ALS模型时,设置implicitPrefs=True表示数据集为隐性反馈,nonnegative=True表示数据集非负。
from pyspark.ml.recommendation import ALSals = ALS( maxIter=20, regParam=0.01, userCol="userId", itemCol="sku_id", implicitPrefs =True, ratingCol="sku_cnt", nonnegative=True)model = als.fit(data)c.模型评估
隐性反馈模型得到的为用户是否购买的概率,所以此处创建一个label字段,后面使用auc值来评判模型的具体效果。
from pyspark.ml.evaluation import BinaryClassificationEvaluatorfrom pyspark.sql.functions import udffrom pyspark.sql.types import IntegerTypedef fun(sku_cnt): return 1 if sku_cnt>0 else 0udf_fun=udf(fun,IntegerType())test = test.withColumn("label",udf_fun(test.sku_cnt))pred = model.transform(test).fillna(0)evaluator = BinaryClassificationEvaluator(rawPredictionCol='prediction',labelCol='label')auc = evaluator.evaluate(pred,{evaluator.metricName: 'areaUnderROC'})d.模型预测
当我们训练调整好我们的模型之后,此时我们即可进行模型预测,此处也比较简单,对于训练好的模型,输入我们指定的用户和商品,然后按照预测用户是否购买的概率从大到小排序即可,之后再加些过滤规则,即可得到我们想要的结果。
user_pred = model.transform(user_data).fillna(0)user_pred.orderBy("prediction",ascending=False).show(20)以上为本次分享的推荐算法工程实践的首篇内容,后续将继续介绍其他常见算法在项目中的工程实践。
参考资料:
[1] https://blog.csdn.net/woniu201411/article/details/85341448
[2] https://zhuanlan.zhihu.com/p/33819712
[3] 《推荐系统算法实践》——黄美灵
[4] 《推荐系统》——陈开江
团队介绍:我们是名创优品信息科技中心的智能应用部,是一支专业的数据科学团队,微信公众号(数据天团)每周日推送一篇原创数据科学文章。我们的作品都由项目经验丰富的工程师精心准备,分享结合实际业务的理论应用和心得体会。欢迎大家关注我们的微信公众号,关注我们的数据科学精品文章。