Python从入门到项目实战————序列
系列文章目录
`

`
文章目录
- 系列文章目录
- 前言
- 一、初步认识序列
-
- 一、列表
-
-
-
-
- 列表基本定义
- 索引的详细使用
- 数据分片
- 成员运算符
- 列表操作函数
- 列表相关操作的详细解释
-
-
-
- 元组
-
-
-
-
- 元组的乘法和加法运算
- 序列统计函数
-
- 字符串
-
- 字符串的分片操作
-
- 字符串拆分过程中出现乱码的原因
- 简单的字符串操作认识
- 字符串格式化
-
- 字符串操作函数
- 字典
-
- 字典的基本使用
- 字典的迭代输出
- 字典操作函数
-
-
- 总结
前言
`前面学习了Python中的程序逻辑结构,在Pytho中又增加了序列的知识,现在,我们将学习Python中较为重要的知识序列,以及更加深化的讲解对字符串的处理。
一、初步认识序列
顾名思义,序列从字面意思就可以得知是一种有序的类容的集合,通过序列不仅可以实现多个数据的的保存,也可以采用相同的方式来访问序列中的数据,最为重要的是,序列可以利用切片的概念获取部分子序列的数据,在Python中,列表,元组,字典,字符串构成了序列的概念。
一、列表
列表(list)是一种常见的序列类型,Python中的列表除了可以保存多个数据外,还可以动态的实现对列表数据的修改。
列表基本定义
在Python中,列表的定义也是采用了赋值的方式,不过形式有点不同于以往变量的赋值。他用了一个[]号。
例如:
infors=["i like you","Python","Hello word"]
#infors就是一个列表,它有三个元素,分别是"i like you" ,"Python","Hello word"。
#如果我们要获取其中某一个元素,那么我们就用索引的方式来获取,和c语言中的数组极为相似。索引的范围为
#0~(列表长度-1)
下面我用一个实例来说明索引:
#关于列表索引的相关的知识点
infors=["I like ","Python ","c++ is better than this","But i think " ] #定义了一个列表
#通过简单的索引达到对上面的话排序
item=infors[0]+infors[1]+infors[3]+infors[2] #在c++和python中,字符串可以实现相加
print(item) #输出排序后的语句
#python中的索引和c语言中数组极为相似,但是,索引可以反向索引
del item
item=infors[-4]+infors[-3]+infors[-1]+infors[-2]
print(item)
#看两个语句的运行结果可以发现两者的结果完全一样。
#我们在进行索引的时候,列表的长度又如何获取?如果只是数数,则无疑会增加我们的工作难度,Python提供了一个函数用来计算长度len();
print(len(infors))
print(type(infors)) #获取列表的类型
上面的程序我们用到了很多的库函数,下面先介绍一下这些函数:
| 函数名 | 功能 |
|---|---|
| id() | 获取变量的存储地址,一般为一串数字 |
| ord() | 获取字符的ASCII码值 |
| type() | 获取变量的类型,一般为字符串类型 |
| str() | 非字符串和字符串连用的时候用,将非字符串转换为字符串 |
暂时就只介绍这些函数,后面遇到了再详细介绍。
索引图:
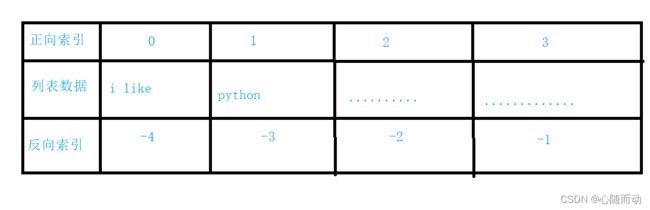
![]()
索引的详细使用
(1).通过索引迭代处理序列
用len()函数得到序列的长度,然后通过for循环,利用range得到序列中的每一个元素。当然,序列中的元素我们也可以通过索引实现数据的更改。和元组不同的是,列表的容量大小可以更改,二元组不可以,但是他们都支持乘法运算。
eg:
# coding:UTF-8
infors=["I like Pthon","and i like c++","我是一名大一学生",20,"喜欢编程"] #注意逗号必须是英文符号的,容易混淆
#索引迭代
for item in range(len(infors)):
print(item,end=",")
#序列的乘法运算
infors*=3 #简洁运算符,后面会细讲
print("扩大三倍后的列表为:",infors)
#将列表中置为空
infor=[None]
print("%s" % type(infor))
数据分片
一个列表中往往有很多的数据类容,除了通过索引的方式来获得数据类容,我们也可以通过某些操作来实现对列表中一段数据的提取,这个就叫做分片。
图解:
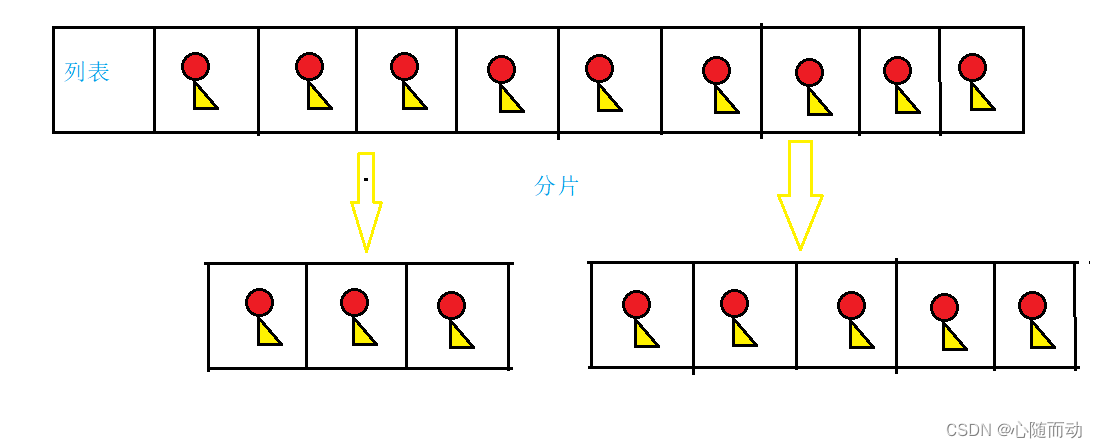
分片索引格式:
对像(列表)[起始位置:终止位置:步长]
或者
对象(列表)[起始位置,终止位置]
程序实例:
infors=["A","B","C","D","E","F","G","H","I","J","K","L"]
number_a=infors[3:7]
print("第一次截取的类容为:",number_a)
number_b=infors[-3:-8]
print("第二次截取的数据类容为:",number_b)
#通过捷径实现列表分片
#获取索引3以后的类容
print(infors[3:])
#获取索引7之前的所有数据
print(infors[:7]) #未设置步长的时候,系统默认步长是1
#设置截取步长
number_size=infors[:7:2]
print("步长为2的索引:",number_size)
当然索引的操作不仅仅是上面所列举的那样,还有很多方式,在实际的开发过程中,根据需要自己操作。
成员运算符
| 运算符 | 描述 |
|---|---|
| in | 判断数据是否在列表中 |
| not in | 判断数据是否不在列表中 |
列表操作函数
| 函数 | 描述 |
|---|---|
| append() | 在列表后面追加新的类容 |
| clear() | 清楚列表数据 |
| copy() | 列表复制 |
| count(data) | 统计某一数据在列表中出现的次数 |
| extend(列表) | 在列表后面追加新的列表 |
| index(data) | 从列表中查找某一数据第一次出现的位置 |
| insert(index,data) | 向列表中指定的位置追加新的数据 |
| pop(index) | 从列表中弹出一个数据并删除 |
| remove(data) | 删除列表中指定的数据 |
| reverse() | 列表数据逆置 |
| sort() | 列表排序 |
| 程序实例: |
infors=[1,2,3,4,5,6,7,8,9,10]
infors.append(11) #追加新的类容
print(infors)
infor=infors.copy() #列表复制
print(infor)
num=infors.count(1) #计算1出现的次数
print(num)
infors.extend(infor) #追加新的列表
print(infors)
index=infors.index(8) #8出现的位置
print(index)
infors.remove(3) #删除3
print(infors)
infors.reverse() #逆置列表
print(infors)
infors.sort() #排序
print(infors)
infors.clear()#列表的清除
del infors
列表相关操作的详细解释
(1).pop函数,clear函数和remove函数的区别,clear函数从字面意思就可以理解到,清除函数,则整个列表中的所有的数据元素都会被删除,pop函数,在数据结构中,弹栈就会用到这个,表示弹出某一个元素,也就是从列表中取出来这个数据,也就是常说的函数返回,remove删除的是列表中所有某一特定的值。
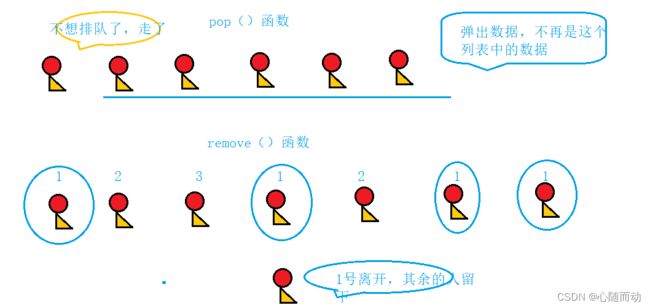
列表也是可以进行大小比较的,如果两者相等,则返回True,否则的话,返回False,如果他们之中的数据都一样,但是顺序不一样的话,也是False。
元组
元组(Tuple)是与列表相似的线性数据结构,与列表不同的是,元组中的定义类容不允许被修改,以及容量大小的动态扩充。元组的定义通过“()”来实现。
# coding:UTF-8
infors=("Pyhton","I like you","i will study you") #定义元组
for item in infors:
print(item,end=",")
'''
记住,元组不能修改内容,否则会报错,但是元组是可以进行乘法和加法运算。如果我们定义的元组只有一个元素的话,就在后面加一个逗号,表示该对象是元组,否则就是一般的变量。
'''
元组的乘法和加法运算
这里单独的讲解元组运算的原因是由于,很多人在这里会产生一种错觉,元组的特点就是内容不能被修改,但是我们用了乘法运算,这是由于乘法运算也好,加法运算也好,从根本上并没有修改元组的内容,只是以一个元组创建了另一个元组。
infors=(1,2,3,4,5,6,7,8)
#使用乘法运算的时候,需要用一个元组来接收,不能在原有的基础上增加,
#如果是直接输出,则系统会将返回后的数据输出
print(infors)
print(infors*3)
序列统计函数
项目开发中会使用列表和元组进行数据存储,而且对列表数据可以进行动态配置。所以序列中往往有很多的数据需要处理,如果每次处理都需要自己写函数来实现的话,无疑会增加程序员的工作量,于是,Python提供了一些常用的序列处理函数。
| 函数 | 描述 |
|---|---|
| len() | 获取序列长度 |
| max() | 获取序列最大的值 |
| min() | 获取序列最小的值 |
| sum() | 获取序列中所有值的和 |
| any() | 序列中有一个True,则为True,否则,为False |
| all() | 序列中所有的内容为True的时候,才为True |
| 代码示例: |
numbers=[1,2,3,4,5,6,5,4,3,2,1] #定义列表
print("元素个数:%d" % (len(numbers))) #统计序列中元素的个数
print("列表中最大的值:%d" % (max(numbers)))
print("列表中最小的值:%d" % (min(numbers)))
print("列表中所有元素的和:%d" % (sum(numbers))) #计算列表中的所有数据的和
print(any((True,1,"Hello"))) #元组中的的数据都不为False,故为True
print(all((True,None))) #元组中存在一个None,判断为False
字符串
前面我们提到了在Python中,字符串为Python的默认数据类型,就像double类型是Java的默认数据类型一样。所以对python中的字符 串数据类型,我们需要花费大量的时间和精力来学习,现在将其作为一个单独的板块来讲解。
字符串的讲解大概分为两个板块:字符串的分片和字符串的数据统计。
字符串的分片操作
问题引进:
title="I like Python and I like c++ too"
str_a=title[:7]
print(str_a)
str_b=title[3:9]
print(str_b)
str_c=title[1:5:2]
print(str_c)
上面的程序我们可以发现,其实对于字符串的分片操作和对序列的分片操作很相似。所以可以联想记忆。在Python中,汉字和字母都作为一个字符来处理,这样就减少了切片的过程中产生乱码的情况。
字符串拆分过程中出现乱码的原因
我们都知道,在程序编译的过程中,我们在对字符进行操作的的时候,一般都是对ASCII码进行操作。按照传统的ASCII码来讲,英文字符占一个字节,中文占两个字节,所以如果字符串中要进行截取,就要考虑到截取的字节数,一旦截取位数不对,就会出现乱码。
在项目开发中:常用的编码就有两种:
(1)。UTF-8编码,一个英文字符占一个字节,一个中文占三个字节,中文标点占三个字节,英文标点占一个字节。
(2).Unicode编码:英文字符占两个字节,中文占两个字节,与之对应的标点也都占两个字节。
简单的字符串操作认识
利用前面的序列操作函数(注意不是列表操作函数)对字符串实现操作。
例如:找出字符串中最大和最小的字符;
# coding:UTF-8
title="i like python"
print("字符串的长度为:%d" % (len(title)))
print("字符串中最大的字符是:%c" % (max(title)))
print("字符串中最小的字符是:%c" % (min(title)))
前面我们在介绍运算符的时候,讲解了成员运算符,在字符串中我们可以使用成员运算符来判断数据是否在字符串中。
# coding:UTF-8
title="study Python now"
if "Python" in title:
print("字符串“Python”在字符串中")
else:
print("no")
字符串格式化
通过前面的学习,我们可以知道,对于Python语言,我们可以选择格式化输出,当然,对于字符串的格式化输出也是可以的。
字符串格式化输出的函数为format()函数,
函数格式:
“…{成员标记!转换格式:格式描述}…”.format(参数类容)
(1).成员标记:用于进行成员或参数序号定义,如果不定义,则参数按照顺序进行。
(2).转换格式:将指定参数的数据类容进行数据格式转换。
(3).格式描述:提供若干配置选项。
转换标记:
| 类型符 | 描述 |
|---|---|
| a | 将字符串按照Unicode编码输出 |
| b | 将整数转换为二进制数 |
| c | 将整数转换为ASCII |
| d | 十进制整数 |
| e | 将十进制数转换为用科学计数法表示 |
| E | 将十进制数转换为用科学技术法表示(大写E) |
| f | 浮点数表示,会将特殊值(nan,inf)转换为小写 |
| F | 浮点数显示,会将特殊值(nan,inf)转换为大写 |
| g | e和f的结合体,若整数部位超过6位用e,否则用f |
| G | E和F的结合体,整数部位超过6位用E表示,否则用F表示 |
| o | 将整数转为八进制数 |
| s | 将数据以字符串类型输出 |
| r | 将数据转为供解释器输出的信息 |
| x | 将十进制整数转换为十六进制数 ,字母部分用小写 |
| X | 将十进制转换为十六进制数,字母部分用大写 |
| % | 将数值格式化位百分之形式 |
格式描述选项
| 选项 | 配置 |
|---|---|
| fill | 空白填充配置,默认使用空格实现空白部分的填充 |
| align | <:左对齐,>:右对齐,^:居中对齐,=:将填充数据放在符号和数据之间,仅对数字有效 |
| sign | +:所有数字均带有符号,-:仅负数带有符号(默认配置选项),空格:正数前面带空格,负数前面带符号 |
| # | 数字进制转换配置,自动在二进制,八进制,十六进制和数值前天添加对应的0b,0o,0x标记 |
| . | 自动在每三个数字之间添加“,”分隔符 |
| width | 定义十进制数字的最小显示宽度,如果未指定,则按照实际的类容来决定宽度 |
| precision | 数据保留的精度位数 |
| type | 数据类型 |
字符串提供的format()函数较为复杂,下面通过几个案例来学习:
name="小明同学"
age=18
score=97.5
message="姓名:{},年龄:{},成绩:{}".format(name,age,score)
print(message)
运行结果:姓名:小明同学,年龄:18,成绩:97.5
上面的程序简单的使用了“{}”进行占位,最终输出的结果就是按照format()函数标记的顺序,行成最终的输出类容。
当然format()函数在格式化字符串的时候,也可以通过数字序号,或者是参数来实现定义,从而达到参数和对象的自动匹配。
例如:
name="小明同学"
age=18
score=97.5
#利用参数的形式来实现。
print("姓名:{name_a},年龄:{age_a},成绩:{score_a}".format(name_a=name,age_a=age,score_a=score))
#利用序号来表示
print("姓名:{0},年龄:{1},成绩:{2}".format(name,age,score)) #注意序号和format()函数中的顺序有关;
运行结果:姓名:小明同学,年龄:18,成绩:97.5
姓名:小明同学,年龄:18,成绩:97.5
通过上面的程序我们可以知道,对于format()函数的使用,不仅可以方便我们对数据的输出,以及减少了代码量。但是,如果每次都需要定义一个变量来使用,则会显得复杂;我们知道,列表可以存储各种类型的数据,则我们可以通过索引来实现字符串的格式化输出:
代码示例:
infors=["Coco",18,98.5,180,60]
print("姓名{list_pragram[0]},年龄:{list_pragram[1]},成绩:{list_pragram[2]},身高:{list_pragram[3]},体重:{list_pragram[4]}".format(list_pragram=infors))
运行结果:姓名Coco,年龄:18,成绩:98.5,身高:180,体重:60
一.数据格式化处理
代码示例:
# coding:UTF-8
print("UNICODE编码:{info!a}".format(info="好好学习"))
print("成绩:{info:6.2f}".format(info=98.5674))
print("收入:{numA:G},收入:{numB:E}".format(numA=92393,numB=92393))
print("二进制数:{num:#b}".format(num=10))
print("八进制数:{num:#o}".format(num=10))
print("十六进制数:{num:#x}".format(num=10))
运行结果:
UNICODE编码:'\u597d\u597d\u5b66\u4e60'
成绩: 98.57
收入:92393,收入:9.239300E+04
二进制数:0b1010
八进制数:0o12
十六进制数:0xa
# coding:UTF-8
msg="I like Python,so i will study hard"
print("数据中显示【{info:^20}】".format(info=msg))
print("数据填充:{info:_^20}".format(info=msg)) #自定义填充符
print("带符号数字填充:{num:^+20.3f}".format(num=12.34578))
print("右对齐:{n:>20.2f}".format(n=25)) #定义对齐方式
print("数字使用“,”分隔:{num:,}".format(num=928239329.99765489090))
print("设置显示精度:{info:.9}".format(info=msg))
运行结果显示:
数据中显示【I like Python,so i will study hard】
数据填充:I like Python,so i will study hard
带符号数字填充: +12.346
右对齐: 25.00
数字使用“,”分隔:928,239,329.9976549
设置显示精度:I like Py
上面的程序带我们学会了字符串中的格式操作,但是对于字符串的操作,Python也提供了相关的操作函数,以此来减轻程序员的工作难度。
字符串操作函数
Python中的字符串的处理函数有很多类型,比如大小写转换,替换,拆分,连接等。
下面我们详细的来认识这些函数。
| 函数 | 描述 |
|---|---|
| center() | 字符串居中显示 |
| find(data) | 字符串数据查找,查找到返回索引值,找不到返回-1 |
| join(data) | 字符串连接 |
| split(data【,limit】) | 字符串拆分 |
| lower() | 字符串转小写 |
| upper() | 字符串转大写 |
| capitalize() | 首字母大写 |
| replace(old,new【,limit】) | 字符串替换 |
| translate(mt) | 使用指定替换规则实现单个字符的替换 |
| maketrans(oc,nc【,d】 ) | 与translate()函数结合使用,定义要替换的字符内容以及删字符内容 |
| strip() | 删除左右空格 |
代码示例:
# coding:UTF-8
#字符串的操作函数的示例
#字符串显示控制
info="I like Python,and i want to get good score in Python"
print(info.center(50)) #数据居中显示,长度为50
print(info.upper()) #将字符串中的字母转为大写
print(info.lower()) #将字符串中的字母转为小写
print(info.capitalize()) #首字母转为大写
del info
#总结,在字符串的转换中,对于非字母字符不做任何处理。
#字符串的内容查找
info="New eternity,if i cahnge the word will change"
print(info.find("change")) #返回查询字符串的位置
#find函数不仅仅能够简单的使用查找,还可以使用索引查找,以此来减少查找时间复杂度
print(info.find("word",10,len(info))) #从索引为10 的位置开始查找,直到字符串的最后。
print(info.find("like",20,30)) #运行结果为-1,所以没有查找到,虽然存在like这个单词,但是没在索引的区间内。
del info
#字符串的连接
url=".".join(["I","like","Python"])
autor="_".join("李华")
print(f"姓名:{autor},爱好:{url}")
#字符串的拆分
ip="192.168.1.105"
print("数据全部拆分为:%s" %(ip.split(".")))
print("数据部分拆分为:%s" %(ip.split(".",1))) #拆分一次
data="2022-7-10 22:51:59"
result=data.split(" ") #此时result相当于列表,用空格将日期和时间分开
print("日期拆分:%s" %(result[0].split("-")))
print("时间拆分为:%s" % (result[1].split(":")))
del ip;del data;del result;
#字符串替换
info="Hello word!Hello Python!Hello c++"
str_a=info.replace("Hello","你好") #全部替换
str_b=info.replace("Hello","你好",2) #部分替换,替换两次,系统会自动替换匹配的字符串;
print("全部替换后的字符串: %s" % (str_a))
print("部分替换后的字符串:%s" % (str_b))
del info
del str_a
del str_b
#字符替换
str_a="Hello Py th on !H e ll o wo r d!"
#利用maketrans()函数创建转换表
mt_a=str_a.maketrans(" "," "," ") #删除空格;
print(str_a.translate(mt_a))
str_b="Hello Pyhton! i like you;i hope get you;"
mt_b=str_b.maketrans(" ",".",";")
print(str_b.translate(mt_b))
del str_a; del str_b;
del mt_a; del mt_b;
#删除左右空格键
"""
我们在输入数据的时候,有时候会出现空格,如果要去掉空格,那么我们就可以使用strip()函数;
"""
login_info=input("请输入登录信息(格式:名字,密码)").strip() #删除左右空格;
if len(login_info)==0 or login_info.find(",")==-1:
print("输入的数据有问题,格式不正确,重新输入;")
else:
result=login_info.split(",")
if result[0] and result[1]:
print("登录成功")
print("恭喜用户%s登录" % (result[0]))
运行结果:
I like Python,and i want to get good score in Python
I LIKE PYTHON,AND I WANT TO GET GOOD SCORE IN PYTHON
i like python,and i want to get good score in python
I like python,and i want to get good score in python
39
29
-1
姓名:李_华,爱好:I.like.Python
数据全部拆分为:['192', '168', '1', '105']
数据部分拆分为:['192', '168.1.105']
日期拆分:['2022', '7', '10']
时间拆分为:['22', '51', '59']
全部替换后的字符串: 你好 word!你好 Python!你好 c++
部分替换后的字符串:你好 word!你好 Python!Hello c++
HelloPython!Helloword!
Hello.Pyhton!.i.like.youi.hope.get.you
登录成功
恭喜用户lihua登录
字典
字典(dict)是一种二元偶对象的数据集合(或称之为Hash表),所有的数据存储结构为key=value形式,开发者只需要通过key就可以获取相应的value类容。
字典的基本使用
字典是由多个key=value的映射向组成的特殊列表结构,可以用“{ }”定义字典数据,考虑到用户使用方便,key的值可以是数字,字符或元组。
info={"python":"I like you",1024:"这一天是程序员节日",None:"空的,啥也没有"}
print("Python对应的值为:%s" % (info["python"]))
print("1024对应的是:%s" % (info[1024]))
print("None对应的值为:%s" % (info[None]))
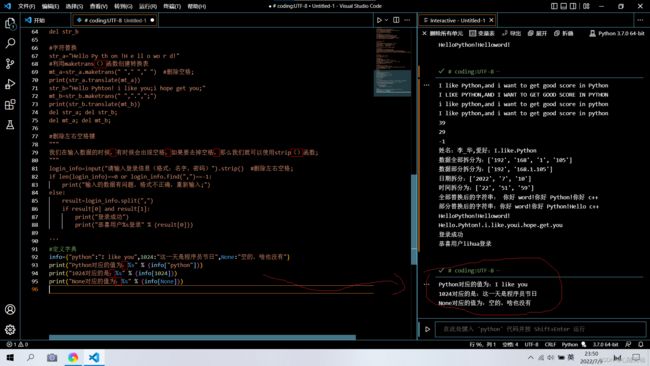
我们发现在Python中的字典的使用中,和数据结构中的哈希表极为相似,所以他和哈希表中的一些特点也很相似,比如key值不允许重复,因为key一旦重复,就会出现新的类容替换旧的类容的情况。
代码示例:使用字典dict()函数定义字典
infos=dict([["Python","I like Python"],["student","we should study hard"]]) #列表转换为字典;
member=dict(name="李华",age=18,score=97.8)
print(infos)
print(member)
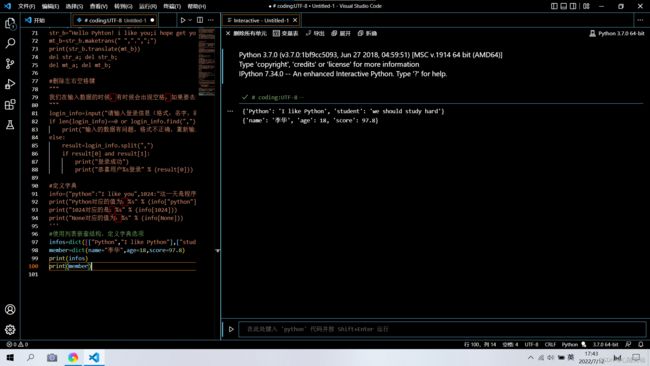
相信很多同学看到这里都会有疑问,既然字典和列表都有多种数据存储的结构,为什么还要实现字典这种结构,这是由于字典结构一般用来进行数据的查询,而列表用来实现数据的输出功能。
字典的迭代输出
字典本质上 是一个由若干映射项形成的列表结构,除了具有数据查询功能,也可以基于for循环是西安全部数据的迭代输出。
字典的迭代输出:
infos=dict([["Python","I like Python"],["student","we should study hard"]]) #列表转换为字典;
member=dict(name="李华",age=18,score=97.8)
print(infos)
print(member)
for key in infos:
print("%s=%s" % (key,infos[key]))
for key in member:
print("%s=%s" % (key,member[key]))
在字典中可以直接使用for循环获取字典中对应的所有key的信息,在每次迭代后再通过key实现value数据的查询。通过迭代的方式获取字典中key的值,然后再获得与之对应的value,这种方法虽然简单,但是,如果存储了大量数据,这种方式就会变得特别的耗费时间。于是在实际的开发中可以用items()的函数直接返回每一组的key和value值。
代码示例:
infos=dict([["Python","I like Python"],["student","we should study hard"]]) #列表转换为字典;
member=dict(name="李华",age=18,score=97.8)
for key,value in infos.items():
print("%s=%s" % (key,value))
for key,value in member.items():
print("%s=%s" % (key,value))
字典操作函数
| 函数 | 描述 |
|---|---|
| clear() | 清空字典数据 |
| update(k=v,…) | 更新字典数据 |
| fromkeys(seq[,value]) | 创建字典,使用列表中的数据作为key,所有的key拥有相同的value |
| get(key[,defaultvalue]) | 根据key获取数据 |
| popitem() | 从字典中弹出一组映射项 |
| keys() | 返回字典中全部key数据 |
| values() | 返回字典中所有的value值 |
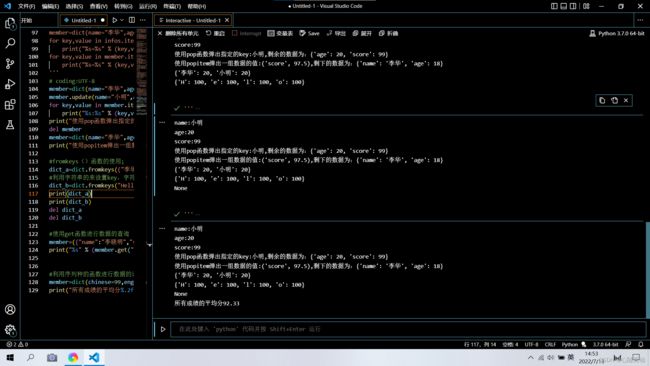
# coding:UTF-8
member=dict(name="李华",age=18,score=97.5)
member.update(name="小明",age=20,score=99) #字典数据的更新
for key,value in member.items():
print("%s:%s" % (key,value))
print("使用pop函数弹出指定的key:%s,剩余的数据为:%s" % (member.pop("name"),member))
del member
member=dict(name="李华",age=18,score=97.5)
print("使用popitem弹出一组数据的值:%s,剩下的数据为:%s" % (member.popitem(),member))
#fromkeys()函数的使用;
dict_a=dict.fromkeys(("李华","小明"),20) #设置一个元组,元组中的值作为key,并且设置的类容相同
#利用字符串的来设置key,字符串中的每一个字符都会作为一个key
dict_b=dict.fromkeys("Hello",100)
print(dict_a)
print(dict_b)
del dict_a
del dict_b
#使用get函数进行数据的查询
member=({"name":"李晓明","score":90,"age":22})
print("%s" % (member.get("num")))
#利用序列种的函数进行数据的运算
member=dict(chinese=99,english=78,math=100)
print("所有成绩的平均分%.2f" % (sum(member.values())/(len(member))))
运行结果:
总结
(1).Python中的序列包括;列表,元组,字符串,字典。
(2).列表是一种可以动态库扩充的数据结构,里面的内容可以依据索引访问,二元组中的类容是不允许被改变的。
(3).序列中的操作函数max(),min(),sum(),len(),all(),any()函数对所有的序列结构都有用。
(4).字符串是一种特殊的序列,有若干的字符所组成,字符串可以利用format()方法实现强大的格式化操作,也可以利用库函数实现字符串的替换,拆分,查找等操作。
(5).字典是一种key=value的二元偶对象集合,主要的功能是依据key实现对应value数据的查询,也可以用update()函数实现对数据的增删查改,或者使用del关键字删除指定key的值。