Java集合——数据结构
Java集合——数据结构
https://blog.csdn.net/bj_chengrong/article/details/108667887
https://binhao.blog.csdn.net/article/details/113279914
https://www.cnblogs.com/paddix/p/5539326.html
1.集合简介
Java中集合类是Java编程中使用最频繁、最方便的类。集合类作为容器类可以存储任何类型的数据,当然也可以结合泛型存储指定的类型(不过泛型仅仅在编译期有效,运行时是会被擦除的)。集合类中存储的仅仅是对象的引用(堆地址,而非实际对象本身),并不存储对象本身。集合类的容量可以在运行期间进行动态扩展,并且还提供很多很方便的方法,如求集合的并集、交集等。
注意:集合中不能添加基本数据类型,只能包含引用类型;部分基恩数据类型在添加过程中会自动装箱包装成类,再添加到集合中。
2.集合类结构
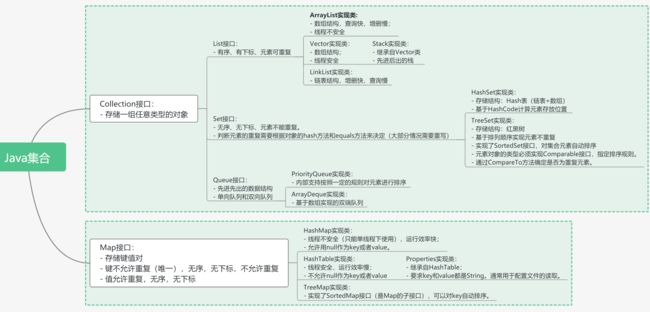
Java中的集合包含多种数据结构,如链表、队列、哈希表等。从类的继承结构来说,可以分为两大类:
-
一类是继承自Collection接口,这类集合包含List、Set和Queue等集合类。
-
一类是继承自Map接口,这主要包含了哈希表相关的集合类。
2.1 Collection接口
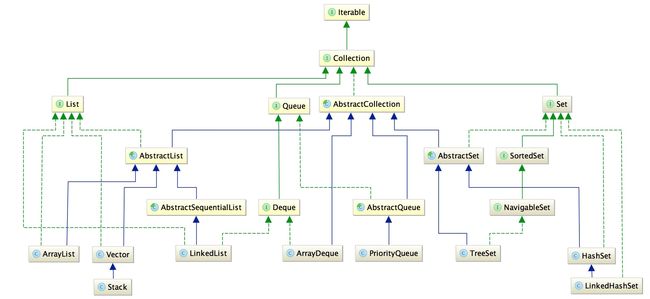
(图中的绿色的虚线代表实现,绿色实线代表接口之间的继承,蓝色实线代表类之间的继承。)
- Collection是根接口(接口要通过具体的类来实现,不能new接口)——代表一组任意类型的对象
- List接口:有序、有下标、元素可重复
- Set接口:无序、无下标、元素不能重复
2.2.1 List接口
List接口继承了Collection,因此其包含Collection中的所有方法。
**特点:**有序、有下标、元素可以重复
方法:
- void add (int index,Object o) //在index位置插入对象o
- boolean addAll (int index, Collection c) //将另一个集合中的所有元素插入到该集合的index位置
- Object get (int index) //返回该集合中指定位置的元素
- List subList (int fromIndex, int toIndex) //返回fromIndex和toIndex之间的集合元素构成的子集合
实现类:
-
ArrayList【重点】
- 数组结构,查询快、增删慢;(底层通过数组实现)
- JDK1.2版本,运行效率快、线程不安全。
-
Vector
- 数组结构,查询快、增删慢;
- JDK1.0版本,运行效率较快、线程安全
- Stack类是继承的Vector类
-
LinkdedList
- 链表结构,增删快、查询慢(底层通过链表实现)
对比:
- ArrayList是最常用的List实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要讲已经有数组的数据复制到新的存储空间中。当从ArrayList的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除。
- Vector与ArrayList一样,也是通过数组实现的,不同的是它支持线程的同步,即某一时刻只有一个线程能够写Vector,避免多线程同时写而引起的不一致性,但实现同步需要很高的花费,因此,访问它比访问ArrayList慢。
- LinkedList是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,他还提供了List接口中没有定义的方法,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。
- Vector是线程(Thread)同步(Synchronized)的,所以它也是线程安全的,而Arraylist是线程异步(ASynchronized)的,是不安全的。如果不考虑到线程的安全因素,一般用Arraylist效率比较高。
- 如果集合中的元素的数目大于目前集合数组的长度时,vector增长率为目前数组长度的100%,而arraylist增长率为目前数组长度
的50%。如过在集合中使用数据量比较大的数据,使用Vector有一定的优势;若集合中数据量不大,使用ArrayList就有利于节约内存空间。
- 注意各类集合的初始大小、载入因子等
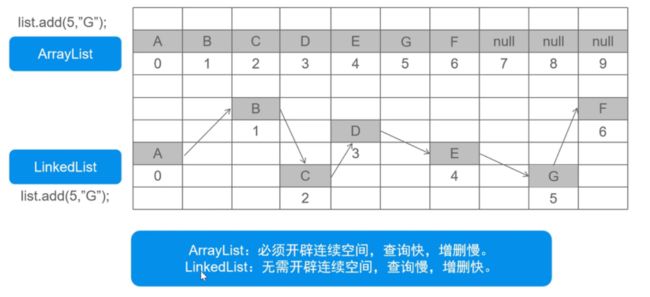
不同结构的实现方式:
- ArrayList:数组结构
- 必须开辟连续的空间
- 查询快,增删慢
- LinkedList:双向链表
- 无需开辟连续的空间
- 查询慢,增删快
(1)ArrayList
ArrayList是List接口最常用的一个实现类,支持List接口的一些列操作。
package com.song.demo02;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.ListIterator;
//ArrayList的使用
//存储结构:数组-->查找遍历速度快,增删慢
public class Demo03 {
public static void main(String[] args) {
//创建集合
/**size=0 初始创建,容量为0;
* 向集合中添加任意一个元素后,容量变为10
* 后续添加的元素超过10,添加第11个元素时会继续扩容,容量变为15
* 每次扩容,都是原来的1.5倍
*/
ArrayList arrayList = new ArrayList<>();
//1.添加元素
Student s1 = new Student("zhangsan", 20);
Student s2 = new Student("lisi", 22);
Student s3 = new Student("wangwu", 18);
arrayList.add(s1);
arrayList.add(s2);
arrayList.add(s3);
arrayList.add(s2);
System.out.println("元素个数:" + arrayList.size());
System.out.println(arrayList.toString());
//2.删除元素
/*arrayList.remove(s1);
arrayList.remove(new Student("wangwu", 18));//正常情况下不能删除,是一个新的对象,实际集合中存储的是对象的地址
//删除过程中会调用到的equals(this==obj)方法,比较的是地址;如果要比较值,则需要重写equals()方法
//重写equals方法后,可以删除
System.out.println("删除之后元素个数:" + arrayList.size());
System.out.println(arrayList.toString());
*/
//3.遍历元素【重点】
//3.1增强for
//3.2使用for
//3.3迭代器
Iterator it = arrayList.iterator();
while (it.hasNext()) {
Student s = (Student) it.next();
System.out.println(s.toString());
}
//3.4使用列表迭代器
System.out.println("------------从前往后------");
ListIterator lit = arrayList.listIterator();
while (lit.hasNext()) {
Student s = (Student) lit.next();
System.out.println(s.toString());
}
System.out.println("------------从后往前------");
while (lit.hasPrevious()) {
Student s = (Student) lit.previous();
System.out.println(s.toString());
}
//4.判断
System.out.println("元素是否存在:" + arrayList.contains(new Student("wangwu", 18)));//equals重写后可以根据对象值判断是否存在
System.out.println("集合是否为空:" + arrayList.isEmpty());
//5.查找元素位置
System.out.println(arrayList.indexOf(new Student("wangwu", 18)));//equals重写后可以根据对象值查找位置
}
}
(2)Vector
package com.song.demo02;
import java.util.Enumeration;
import java.util.Vector;
//Vector的使用
//存储结构:数组
public class Demo04 {
public static void main(String[] args) {
//创建集合
Vector vector = new Vector<>();
//1.添加元素
vector.add("草莓");
vector.add("芒果");
vector.add("西瓜");
System.out.println("元素个数:" + vector.size());
System.out.println(vector.toString());
//2.删除
/*vector.remove(0);//根据下标删除
vector.remove("芒果");
vector.clear();//清空
System.out.println("元素个数:" + vector.size());
System.out.println(vector.toString());
*/
//3.遍历
//3.1for
//3.2增强for
//3.3迭代器
//3.4枚举器
Enumeration en = vector.elements();
while (en.hasMoreElements()) {
String o = (String) en.nextElement();
System.out.println(o);
}
//4.判断
System.out.println("判断是否包含元素:" + vector.contains("西瓜"));
System.out.println("判断是否为空:" + vector.isEmpty());
//其他方法
System.out.println("第一个位置的元素" + vector.firstElement());
System.out.println("最后一个位置的元素" + vector.lastElement());
System.out.println("获取指定位置的元素" + vector.elementAt(1));
}
}
(3)LinkList
LinkedList由一个头节点,一个尾节点和一个默认为0的size构成,可见其是双向链表。
LinkedList中Node源码如下,由当前值item,和指向上一个节点prev和指向下个节点next的指针组成。并且只含有一个构造方法,按照(prev, item, next)这样的参数顺序构造。
package com.song.demo02;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.ListIterator;
//LinkedList的使用
//存储结构:双向链表
public class Demo05 {
public static void main(String[] args) {
//创建集合
LinkedList list = new LinkedList<>();
//1.添加元素
Student s1 = new Student("张三", 21);
Student s2 = new Student("李四", 24);
Student s3 = new Student("王五", 20);
list.add(s1);
list.add(s2);
list.add(s3);
list.add(s2);//可以重复
System.out.println("元素个数:" + list.size());
System.out.println(list.toString());
//2.删除
/*list.remove(0);//根据下标删除
list.remove(new Student("李四", 24));//重写equals()方法后,可以根据对象值删除
list.clear();//清空
System.out.println("删除之后元素个数:" + list.size());
System.out.println(list.toString());
*/
//3.遍历
//3.1for遍历
System.out.println("-----------------for遍历-----------------");
for (int i = 0; i < list.size(); i++) {
Student stu = (Student) list.get(i);
System.out.println(stu.toString());
}
//3.2增强for
System.out.println("-----------------增强for-----------------");
for (Object obj : list) {
Student stu = (Student) obj;
System.out.println(stu.toString());
}
//3.3迭代器Iterator
System.out.println("-----------------迭代器Iterator-----------------");
Iterator it = list.iterator();
while (it.hasNext()) {
Student stu = (Student) it.next();
System.out.println(stu.toString());
}
//3.4列表迭代器ListIterator
System.out.println("-----------------列表迭代器ListIterator-----------------");
ListIterator lit = list.listIterator();
while (lit.hasNext()) {
Student stu = (Student) lit.next();
System.out.println(stu.toString());
}
//4.判断
System.out.println("判断元素是否存在" + list.contains(s1));
System.out.println("判断是否为空" + list.isEmpty());
//5.获取
System.out.println(list.indexOf(s2));//获取元素位置
}
}
(4)Stack

Stack也是List接口的实现类之一,和Vector一样,因为性能原因,更主要在开发过程中很少用到栈这种数据结构,不过栈在计算机底层是一种非常重要的数据结构。
Stack继承于Vector,其也是List接口的实现类。之前提到过Vector是线程安全的,因为其方法都是synchronized修饰的,故此处Stack从父类Vector继承而来的操作也是线程安全的。
栈主要操作为push入栈和pop出栈,而栈最大的特点就是LIFO(Last In First Out,先入后出)。
Stack<String> strings = new Stack<>();
strings.push("aaa");
strings.push("bbb");
strings.push("ccc");
System.err.println(strings.pop());
2.2.2 Set接口
Set与List的主要区别是Set是不允许元素重复的,而List则可以允许元素重复的。判断元素的重复需要根据对象的hash方法和equals方法来决定。这也是我们通常要为集合中的元素类重写hashCode方法和equals方法的原因。
实现类:
-
HashSet【重点】
-
存储结构:Hash表
-
基于HashCode计算元素存放位置
-
当存入元素的哈希码相同时,会调用equals()进行确认,如果认为值true,则拒绝后者存入;如果为false,则形成链表添加到该位置。
-
-
TreeSet
- 存储结构:红黑树
- 基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则。
- 通过CompareTo方法确定是否为重复元素。
(1)HashSet
存储过程:
- 根据hashCode计算保存的位置(数组),如果位置为空,则直接保存,如果不为空则执行第二步
- 再执行equals方法,如果equals方法位true,则认为是重复,无需再次增加;否则形成链表,添加到该位置。
- 既有数组又有链表
实例一:
package com.song.demo04;
import java.util.HashSet;
import java.util.Iterator;
//HashSet的使用
//存储结构:哈希表(数组+链表+红黑树)
public class Demo02 {
public static void main(String[] args) {
//新建集合
HashSet<String> hashSet = new HashSet<String>();
//1.添加元素
hashSet.add("张三");
hashSet.add("李四");
hashSet.add("王五");
hashSet.add("宋六");
System.out.println("元素个数:" + hashSet.size());
System.out.println(hashSet.toString());
//2.删除元素
/*hashSet.remove("王五");
hashSet.clear();//清空
System.out.println("删除后元素个数:" + hashSet.size());
System.out.println(hashSet.toString());
*/
//3.遍历
//3.1增强for
System.out.println("-------------------增强for------------");
for (String str : hashSet) {
System.out.println(str);
}
//3.2迭代器
System.out.println("-------------------迭代器------------");
Iterator it = hashSet.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
//4.判断
System.out.println("判断元素是否存在:" + hashSet.contains("李四"));
System.out.println("判断集合是否为空:" + hashSet.isEmpty());
}
}
实例二:
package com.song.demo04;
import java.util.Objects;
public class Person {
private String name;
private int age;
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Person{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
/*@Override
public boolean equals(Object o) {
if (this == o) {
return true;
}
if (o == null) {
return false;
}
if (o instanceof Person) {
Person person = (Person) o;
if (age == person.age && name.equals(person.getName()))
return true;
}
return false;
}
@Override
public int hashCode() {
//根据名字、年龄来计算hashCode,可以让相同值的的hashCode一致(既数组的同一位置)
int n1 = this.name.hashCode();
int n2 = this.age;//可以直接用年龄的数字,也可以对其做一定的加减等操作
//int n2 = this.age+31;//
//1)31是一个质数,减少散列冲突;2)31提高执行效率
return n1 + n2;
}
*/
//Alt+Insert 中有快速重写equals和hashCode的方法
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
package com.song.demo04;
import java.util.HashSet;
import java.util.Iterator;
//HashSet的使用
//存储结构:哈希表(数组+链表+红黑树)
/**
* 存储过程:
* (1)根据hashCode计算保存的位置(数组),如果位置为空,则直接保存,如果不为空则执行第二步
* (2)再执行equals方法,如果equals方法位true,则认为是重复,否则形成链表
* (3)
*/
public class Demo03 {
public static void main(String[] args) {
//创建集合
HashSet<Person> person = new HashSet<>();
//1.添加元素
Person p1 = new Person("张三", 18);
Person p2 = new Person("李四", 26);
Person p3 = new Person("王五", 28);
Person p4 = new Person("宋六", 20);
person.add(p1);
person.add(p2);
person.add(p3);
person.add(p4);
//person.add(p4);//重复,不能再添加
person.add(new Person("宋六", 20));//可以添加,new了一个新的对象,地址不同,计算出的hashCode不同,可以直接存储
/**想根据值判断,则:
* 1)首先需重写hashCode()方法,让值相同的计算出的hashCode一样(数组的相同位置)---此时用equals判断地址,会形成链表
* 2)再重写equals方法,根据值判断是否一致,而非根据地址判断
*/
System.out.println("元素个数:" + person.size());
System.out.println(person.toString());
//2.删除元素
person.remove(p1);
person.remove(new Person("宋六", 20));//重写hashCode和equals后可以删除
System.out.println("删除之后元素个数:" + person.size());
System.out.println(person.toString());
//3.遍历元素
//3.1增强for
for (Person p : person) {
System.out.println(p.toString());
}
System.out.println("-------------");
//3.2迭代器
Iterator it = person.iterator();
while (it.hasNext()) {
System.out.println(it.next().toString());
}
//4.判断
System.out.println("元素是否存在" + person.contains(p2));
System.out.println("元素是否存在" + person.contains(new Person("李四", 26)));//重写hashCode和equals后可以根据值判断
System.out.println("集合是否为空" + person.isEmpty());
}
}
(2)TreeSet
- 存储结构:红黑树
- 基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则。
- 通过CompareTo方法确定是否为重复元素。
红黑树是一个二叉查找树(每个节点最多只有2个子节点,且左节点小于右节点,涉及到比较)+颜色(保证左右平衡)
实例一:
package com.song.demo04;
//TreeSet的使用
//存储结构:红黑树
import java.util.Iterator;
import java.util.TreeSet;
public class Demo04 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeset = new TreeSet<>();
//1.添加元素
treeset.add("xyz");
treeset.add("abc");
treeset.add("hello");
treeset.add("song");
treeset.add("xyz");//重复,未添加
System.out.println("元素个数:" + treeset.size());
System.out.println(treeset.toString());//打印出的是按照字母表顺序排列的
//2.删除
treeset.remove("xyz");
System.out.println("元素个数:" + treeset.size());
System.out.println(treeset.toString());
//3.遍历
//3.1增强for
for (String str : treeset) {
System.out.println(str);
}
System.out.println("-------------------------");
//3.2迭代器
Iterator it = treeset.iterator();
while (it.hasNext()) {
System.out.println(it.next());
}
//4.判断
System.out.println("元素是否存在:" + treeset.contains("abc"));
System.out.println("集合是否为空:" + treeset.isEmpty());
}
}
实例二:
package com.song.demo04;
import java.util.Iterator;
import java.util.TreeSet;
//TreeSet的使用
//存储结构:红黑树
/**
* 要求:元素必须实现Comparable接口,compareTo()方法返回值为0,被认为是重复元素
*/
public class Demo05 {
public static void main(String[] args) {
//1.创建集合
TreeSet<Person> person = new TreeSet<>();
//1.添加元素
Person p1 = new Person("zhangsan", 18);
Person p2 = new Person("lisi", 26);
Person p3 = new Person("wangwu", 28);
Person p4 = new Person("lisi", 20);
//直接添加不成功,不知道如何把比较(二叉查找树要求左节点<右节点)
//需要实现Comparable接口,重写compareTo方法,告知比较规则
person.add(p1);
person.add(p2);
person.add(p3);
person.add(p4);
System.out.println("元素个数:" + person.size());
System.out.println(person.toString());//按照排序输出,先姓名后年龄,可自定义
//2.删除
/*person.remove(p1);
person.remove(new Person("lisi", 20));//实现Comparable接口之后,比较值,可以删除
System.out.println("删除之后元素个数:" + person.size());
System.out.println(person.toString());//按照排序输出,先姓名后年龄,可自定义
*/
//3.遍历
//3.1使用增强for
for (Person p : person) {
System.out.println(p.toString());
}
System.out.println("---------------------");
//3.2使用迭代器
Iterator it = person.iterator();
while (it.hasNext()) {
System.out.println(it.next().toString());
}
//4.判断
System.out.println(person.contains(p2));
System.out.println(person.contains(new Person("lisi", 20)));//可以判断
}
}
实例三:
package com.song.demo04;
import java.util.Comparator;
import java.util.TreeSet;
//TreeSet集合的使用
//Comparator接口:实现定制比较(比较器)
//Comparable:可比较的
public class Demo06 {
public static void main(String[] args) {
//创建集合,并指定比较规则——采用匿名内部类的方式
TreeSet<Person> person = new TreeSet<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {//拿两个对象定制比较规则
int n1 = o1.getAge() - o2.getAge();
int n2 = o1.getName().compareTo(o2.getName());
return n1 == 0 ? n2 : n1;//先比较年龄再比较性别
}
});
//1.添加元素
Person p1 = new Person("zhangsan", 18);
Person p2 = new Person("lisi", 26);
Person p3 = new Person("wangwu", 28);
Person p4 = new Person("lisi", 20);
person.add(p1);
person.add(p2);
person.add(p3);
person.add(p4);
System.out.println("元素个数:" + person.size());
System.out.println(person.toString());//按照排序输出,先姓名后年龄,可自定义
}
}
实例四:
package com.song.demo04;
import java.util.Comparator;
import java.util.TreeSet;
//要求:使用TreeSet集合实现字符串按照长度进行排序(最短的在前面,长度一样再根据字母顺序比较)
//使用Comparatar接口定制比较
public class Demo07 {
public static void main(String[] args) {
//创建集合
TreeSet<String> treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
int n1 = o1.length() - o2.length();
int n2 = o1.compareTo(o2);
return n1 == 0 ? n2 : n1;
}
});
//1.添加元素
treeSet.add("hello world");
treeSet.add("abc");
treeSet.add("xyz");
treeSet.add("Beijing");
treeSet.add("zhangsang");
treeSet.add("lisi");
System.out.println(treeSet.size());
System.out.println(treeSet.toString());
}
}
2.2.3 Queue接口
Queue接口
正如数据结构中描述,queue是一种先进先出的数据结构,也就是first in first out。可以将queue看作一个只可以从某一段放元素进去的一个容器,取元素只能从另一端取,整个机制如下图所示,不过需要注意的是,队列并没有规定是从哪一端插入,从哪一段取出。

一般可以直接使用LinkedList完成,从上述类图也可以看出,LinkedList继承自Deque,所以LinkedList具有双端队列的功能。PriorityQueue的特点是为每个元素提供一个优先级,优先级高的元素会优先出队列。
注意:Java中的队列明确有从尾部插入,头部取出,所以Java中queue的实现都是从头部取出
Deque接口
Deque英文全称是Double ended queue,也就是俗称的双端队列。就是说对于这个队列容器,既可以从头部插入也可以从尾部插入,既可以从头部获取,也可以从尾部获取,其机制如下图所示。

Queue,Deque的实现类:
Java中关于Queue的实现主要用的是双端队列,毕竟操作更加方便自由,Queue的实现有PriorityQueue,Deque在java.util中主要有ArrayDeque和LinkedList两个实现类,两者一个是基于数组的实现,一个是基于链表的实现。在之前LinkedList文章中也提到过其是一个双向链表,在此基础之上实现了Deque接口。
(1)PriorityQueue
PriorityQueue是Java中唯一一个Queue接口的直接实现,如其名字所示,优先队列,其内部支持按照一定的规则对内部元素进行排序。
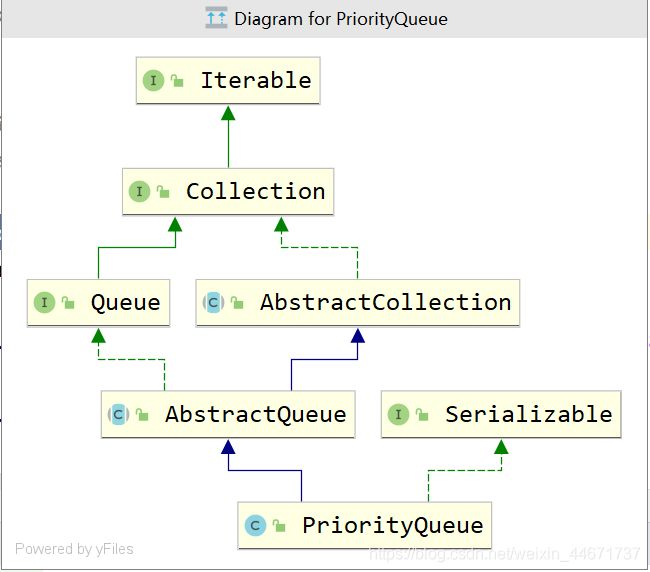
先看下PriorityQueue的继承实现关系,可知其是Queue的实现类,主要使用方式是队列的基本操作,而之前讲到过Queue的基本原理,其核心是FIFO(First In First Out)原理。
Java中的PriorityQueue的实现也是符合队列的方式,不过又略有不同,区别就在于PriorityQueue的priority上,其是一个支持优先级的队列,当使用了其priority的特性的时候,则并非FIFO。
PriorityQueue<Integer> queue = new PriorityQueue<>();
queue.add(20);queue.add(14);queue.add(21);queue.add(8);queue.add(9);
queue.add(11);queue.add(13);queue.add(10);queue.add(12);queue.add(15);
while (queue.size()>0){
Integer poll = queue.poll();
System.err.print(poll+"->");
}
上述代码做的事为往队列中放入10个int值,然后使用Queue的poll()方法依次取出,最后结果为每次取出来都是队列中最小的值,说明了PriorityQueue内部确实是有一定顺序规则的。
PriorityQueue的组成很简单,主要记住一个存放元素的数组,和一个Comparator比较器即可。
(2)ArrayDeque
ArrayDeque是Java中基于数组实现的双端队列.

ArrayDeque<String> deque = new ArrayDeque<>();
deque.offer("aaa");
deque.offer("bbb");
deque.offer("ccc");
deque.offer("ddd");
//peek方法只获取不移除
System.err.println(deque.peekFirst());
System.err.println(deque.peekLast());
ArrayDeque<String> deque = new ArrayDeque<>();
deque.offerFirst("aaa");
deque.offerLast("bbb");
deque.offerFirst("ccc");
deque.offerLast("ddd");
String a;
while((a = deque.pollLast())!=null){
System.err.print(a+"->");
}
2.2 Map接口

**特点:**存储一对数据(Key-Value),无序、无下标,键不可重复,值可以重复。
- 键不允许重复(唯一),无序,无下标,不允许重复
- 值允许重复,无序,无下标
实现类
-
HashMap【重点】
- JDK1.2版本,线程不安全(只能单线程下使用),运行效率快;允许用null作为key或者value。
-
HashTable
- JDK1.0版本,线程安全,运行效率慢;不允许null作为key或者value
-
Properties:
- HashTable的子类,要求key和value都是String。通常用于配置文件的读取。
-
TreeMap
- 实现了SortedMap接口(是Map的子接口),可以对key自动排序。
(1)HashMap
HashSet与HashMap的区别:
HashSet里面本质用的就是HashMap
实例:
package com.song.demo05;
import java.util.Objects;
public class Student {
private String name;
private int stuNo;
public Student() {
}
public Student(String name, int stuNo) {
this.name = name;
this.stuNo = stuNo;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getStuNo() {
return stuNo;
}
public void setStuNo(int stuNo) {
this.stuNo = stuNo;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", stuNo=" + stuNo +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return stuNo == student.stuNo && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, stuNo);
}
}
package com.song.demo05;
import java.util.HashMap;
import java.util.Map;
/**
* HashMap的使用:
* 存储结构:哈希表(数组+链表+红黑树)
*
* 元素增加时重复的判断依据:
* 使用key的hashcode和equals作为重复依据(默认用得是地址比较)
* 要想根据值比较,需要重写hashcode和equals
*/
public class Demo02 {
public static void main(String[] args) {
//创建集合
HashMap<Student, String> hashmap = new HashMap<Student, String>();
//1.增加元素
Student s1 = new Student("张三", 213);
Student s2 = new Student("李四", 104);
Student s3 = new Student("王五", 890);
Student s4 = new Student("六六", 432);
hashmap.put(s1, "北京");
hashmap.put(s2, "上海");
hashmap.put(s3, "南京");
hashmap.put(s4, "青岛");
//hashmap.put(s4, "大同");//不允许key重复,不能添加新的键值对,只会覆盖原来的value
hashmap.put(new Student("李四", 104), "杭州");//可以添加新的键值对,比较的是地址,认为key不同,故新增
//当重写hashcode和equals 方法后,比较的是值认为key重复,不能新增键值对,会覆盖原来的value
System.out.println("元素个数:" + hashmap.size());
System.out.println(hashmap.toString());
//2.删除元素
hashmap.remove(s1);
System.out.println("删除之后元素个数:" + hashmap.size());
System.out.println(hashmap.toString());
//3.遍历
//3.1使用keySet
for (Student stu : hashmap.keySet()) {
System.out.println(stu.toString() + "----->" + hashmap.get(stu));
}
System.out.println("------------------------");
//3.2使用entrySet
for (Map.Entry<Student, String> entry : hashmap.entrySet()) {
System.out.println(entry.getKey() + "------" + entry.getValue());
}
//4.判断
System.out.println("Key是否存在:" + hashmap.containsKey(s2));
System.out.println("value是否存在:" + hashmap.containsValue("杭州"));
}
}
(2)TreeMap
TreeSet与TreeMap的区别:
TreeSet本质就是通过TreeMap实现的。
实例:
package com.song.demo05;
import java.util.Objects;
public class Student implements Comparable<Student> {
private String name;
private int stuNo;
public Student() {
}
public Student(String name, int stuNo) {
this.name = name;
this.stuNo = stuNo;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getStuNo() {
return stuNo;
}
public void setStuNo(int stuNo) {
this.stuNo = stuNo;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", stuNo=" + stuNo +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return stuNo == student.stuNo && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, stuNo);
}
@Override
public int compareTo(Student o) {
int n2 = this.stuNo - o.stuNo;
return n2;//直接比较学号
}
}
1)实现Comparable接口实现比较
package com.song.demo05;
import java.util.Map;
import java.util.TreeMap;
/**
* TreeMap的使用
* 存储结构:红黑树(左节点<右节点)
* 两种比较方式:
* 1)实现Comparable接口
* 2)定制比较Comparator
*/
public class Demo03 {
public static void main(String[] args) {
//新建集合
TreeMap<Student, String> treemap = new TreeMap<>();
//1.增加元素
Student s1 = new Student("张三", 213);
Student s2 = new Student("李四", 104);
Student s3 = new Student("王五", 890);
Student s4 = new Student("六六", 432);
treemap.put(s1, "北京");
treemap.put(s2, "上海");
treemap.put(s3, "南京");
treemap.put(s4, "青岛");
//直接添加出现类型转换异常,不能Comparable,不能比较左右节点
//要求Student实现一个Comparable接口,指定比较规则,实现可比较,才能添加
treemap.put(new Student("六六", 432), "深圳");//不能添加,实现Comparable接口后制定了按照学号比较,此时学号一样,则认为key重复,故value会覆盖原来的值
System.out.println("元素个数:" + treemap.size());
System.out.println(treemap.toString());
//2.删除
treemap.remove(s3);
treemap.remove(new Student("六六", 432));//按照学号比较,可以删除
System.out.println("元素个数:" + treemap.size());
System.out.println(treemap.toString());
//3.遍历
//3.1使用keySet
for (Student stu : treemap.keySet()) {
System.out.println(stu.toString() + "----" + treemap.get(stu));
}
System.out.println("----------------------------------");
//3.2使用entrySet
for (Map.Entry<Student, String> entry : treemap.entrySet()) {
System.out.println(entry.getKey() + "-----" + entry.getKey());
}
//4.判断
System.out.println(treemap.containsKey(s2));
System.out.println(treemap.containsValue(213));
}
}
2)通过Comparator实现定制比较
//新建集合
TreeMap treemap = new TreeMap(new Comparator() {
@Override
public int compare(Student o1, Student o2) {
int n1 = o1.getStuNo() - o2.getStuNo();
return n1;//只根据学号比较
}
});
3.Collections工具类
- 概念:集合工具类,定义除了存取以外的集合常用方法。
- (相比Collection,多了一个s)
- 方法:

实例:
package com.song.demo05;
import java.util.*;
/**
* Collection工具类的使用
*/
public class Demo05 {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(20);
list.add(25);
list.add(39);
list.add(11);
list.add(22);
list.add(40);
list.add(18);
System.out.println("排序之前" + list.toString());
//sort排序方法
Collections.sort(list);//从小到大
System.out.println("排序之后" + list.toString());
//binarySearch二分查找
int i = Collections.binarySearch(list, 39);//返回值是int类型,能找到则返回位置,未找到则返回值小于0
System.out.println(i);
//copy复制
List<Integer> dest = new ArrayList<>();
//Collections.copy(dest, list);//直接copy有问题,要求dest的大小与list相同
for (int i1 = 0; i1 < list.size(); i1++) {
dest.add(0);
}
Collections.copy(dest, list);//可以先给dest赋值0,使两个列表size一致,再赋值
System.out.println(dest.toString());
//reverse反转
Collections.reverse(list);
System.out.println(list.toString());
//shuffle打乱
Collections.shuffle(list);
System.out.println(list.toString());
//补充:list转成数组
System.out.println("list转成数组");
Integer[] array = list.toArray(new Integer[0]);//返回值是数组;构造时new的Interger长度无所谓,只是为了指明一种类型
System.out.println(array.length);
System.out.println(Arrays.toString(array));
//补充:数组转成集合
System.out.println("数组转成集合");
String[] name = {"张三", "李四", "王五", "刘六"};
List<String> list2 = Arrays.asList(name);
//数组转出来的集合是受限集合,不能添加和删除元素,不能add和remove
System.out.println(list2.size());
System.out.println(list2.toString());
//把基本类型的数组转成集合是,需要修改为包装类型(引用类型)
Integer[] nums = {12, 4, 2, 1, 44, 456, 34};
List<Integer> list3 = Arrays.asList(nums);
System.out.println(list3.size());
}
}
4.泛型和工具类
-
Java泛型是JKD1.5中引入的新特性,其本质是参数化类型,把类型作为参数传递。
-
常见形式有:
- 泛型类、
- 泛型接口、
- 泛型方法。
-
语法:
-
好处:
- 提高代码的重用性—一个方法可以传递任何类型的数据
- 防止类型转换异常,提高代码的安全性
4.1泛型类
package com.song.demo03;
public class TestGeneric {
public static void main(String[] args) {
//使用泛型类创建对象---
/* 注意:
1)T只能是引用类型
2)不同的泛型对象之间不能相互复制
*/
//String类型
MyGeneric<String> myGeneric = new MyGeneric<String>();
myGeneric.t = "hello";
myGeneric.show("大家好!");
String str = myGeneric.getT();
System.out.println(str);
//Integer
MyGeneric<Integer> myGeneric1 = new MyGeneric<>();
myGeneric1.t = 108;
myGeneric1.show(200);
Integer integer = myGeneric1.getT();
System.out.println(integer);
}
}
4.2泛型接口
接口:
package com.song.demo03;
//泛型接口
//语法:接口名实现类一(实现接口时确定类型):
package com.song.demo03;
//接口的实现类,指明了泛型的类型
public class MyInterfaceImpl implements MyInterface<String> {
@Override
public String server(String s) {
System.out.println(s);
return s;
}
}
实现类二(实现接口时不确定类型):
package com.song.demo03;
//实现类实现接口时不确定类型,实现类的泛型就是接口的泛型
public class MyInterfaceImpl2<T> implements MyInterface<T> {
@Override
public T server(T t) {
System.out.println(t);
return t;
}
}
测试:
package com.song.demo03;
public class TestGeneric {
public static void main(String[] args) {
//泛型接口的两种实现方式
//1.实现类中指定类型
MyInterfaceImpl myInterface = new MyInterfaceImpl();
myInterface.server("songsong");
//2.把实现类变为泛型类,实例化时指定类型
MyInterfaceImpl2<Integer> myInterfaceImpl2 = new MyInterfaceImpl2<Integer>();
myInterfaceImpl2.server(1000);
}
}
4.3泛型方法
package com.song.demo03;
//泛型方法
//语法: 返回值类型 方法名(){}
public class MyGenericMethod {
//泛型方法,该T只能在此方法中使用
public <T> void show(T t) {
T t2;//可以创建变量,但不能实例化(new)
t2 = t;
System.out.println("泛型方法:" + t);
}
}
package com.song.demo03;
public class TestGeneric {
public static void main(String[] args) {
//泛型方法
MyGenericMethod myGenericMethod = new MyGenericMethod();
myGenericMethod.show("中国加油");//不需要指明类型,直接传递想要的参数,根据参数类型决定
myGenericMethod.show(200);
myGenericMethod.show(3.1415926);
}
}
4.4泛型集合
- 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
- 特点:
- 编译时即可检查,而非运行时抛出异常
- 访问时,不必类型转换(拆箱)
- 不同泛型之间不能相互赋值,泛型不存在多态。
package com.song.demo03;
import com.song.demo02.Student;
import com.sun.org.apache.xerces.internal.impl.xpath.XPath;
import java.util.ArrayList;
import java.util.Iterator;
public class Demo01 {
public static void main(String[] args) {
/*ArrayList arrayList=new ArrayList<>();
arrayList.add("wangwu");
arrayList.add("zhangsan");
arrayList.add(0);
arrayList.add(20);
for (Object obj:arrayList ) {
System.out.println(obj);//没问题
String str=(String)obj;
//System.out.println(str);//有问题,类型转换异常
}*
*/
//使用泛型集合可以避免类型转换异常
ArrayList<String> arrayList = new ArrayList<String>();
arrayList.add("wangwu");
arrayList.add("zhangsan");
//arrayList.add(20);//直接不能添加,报错,避免后面再出问题
for (String str : arrayList) {
System.out.println(str);
}
ArrayList<Student> arrayList1 = new ArrayList<Student>();
Student s1 = new Student("张三", 21);
Student s2 = new Student("李四", 24);
Student s3 = new Student("王五", 20);
arrayList1.add(s1);
arrayList1.add(s2);
arrayList1.add(s3);
//arrayList1.add("zhangsan");//直接不能添加,报错,避免后面再出问题
Iterator<Student> it = arrayList1.iterator();
while (it.hasNext()) {
Student stu = it.next();//少了一步强制类型转换
System.out.println(stu.toString());
}
}
}