Blockchained On-Device Federated Learning学习笔记
Blockchained On-Device Federated Learning学习笔记
- 一、文献翻译
一、文献翻译
知云文献翻译
在区块链的设备上进行联合学习
**摘要:**通过利用区块链,本文提出了一个区块链联邦学习(BlockFL)架构,其中交换和验证本地学习模型的更新。通过使用区块链中的共识机制,可以在没有任何集中训练数据或协调的情况下实现设备上的机器学习。此外,我们分析了BlockFL的端到端延迟模型,并考虑通过通信、计算和共识延迟来表征最优的块生成速率。
一、引言
未来的无线系统无论何时何地,都将确保低延迟和高可靠性。为此,设备上的机器学习是一个引人注目的解决方案,每个设备存储一个高质量的机器学习模型,从而能够做出决策,即使它失去了连通性。训练这样一个设备上的机器学习模型需要比每个设备的本地样本更多的数据样本,并且需要与其他设备进行样本交换[4]-[6]。在这封信中,我们通过与其他设备联合来解决训练每个设备的本地模型的问题。
一个关键的挑战是本地数据样本由每个设备拥有。因此,交易所应该保护原始数据样本不受其他设备的干扰。为此,谷歌的联邦学习(federal learning, FL) [4], [5] (vanilla FL)中提出,每个设备交换其本地模型更新,即学习模型的权值和梯度参数,不能从中导出原始数据。如图1a所示,普通FL的交换是通过一个中央服务器来实现的,该服务器对所有本地模型更新进行聚合并取集合平均值,从而产生一个全局模型更新。然后,每个设备下载全局模型更新,并计算其下一次局部更新,直到全局模型训练完成[5]。由于这些交换,普通FL的训练完成延迟可能是几十分钟或更多,如谷歌的键盘应用程序[7]所示。
普通FL操作的局限性有两个方面。首先,它依赖于一个单一的中央服务器,容易受到服务器故障的影响。这会导致不准确的全局模型更新,扭曲所有本地模型更新。其次,它不奖励本地设备。具有较多数据样本的设备对全局训练的贡献更大。所以在不提供补偿的情况下,这样的设备不太愿意与拥有少量数据样本的其他设备联合。

为了解决这些紧迫的问题,通过利用区块链[8],[9]来代替中央服务器,我们提出了一个区块链FL (BlockFL)架构,区块链网络能够在验证和提供相应奖励的同时交换设备的本地模型更新。BlockFL克服了单点故障问题,并通过对本地训练结果的验证过程,将其联邦的范围扩展到公共网络中不可信的设备。此外,通过提供与训练样本大小成比例的奖励,BlockFL促进了更多设备与更多训练样本的联合。
如图1-b所示,BlockFL的逻辑结构由设备和矿工组成。矿工物理上可以是随机选择的设备,也可以是独立的节点,如网络边缘(即蜂窝网络中的基站),这些节点在挖掘过程中相对不受能量约束。BlockFL的操作总结如下:每个设备计算并上传本地模型更新到区块链网络中其关联的矿工;矿工交换和验证所有本地模型更新,然后运行proof - of- work (PoW) [8];一旦矿机完成了PoW,它就会生成一个块,其中记录了经过验证的本地模型更新;最后,生成的存储聚合本地模型更新的块被添加到区块链,也称为分布式分类账,并由设备下载。每个设备从新块计算全局模型更新。
注意,BlockFL的全局模型更新是在每个设备上本地计算的。矿机或设备故障不影响其他设备的全局模型更新。与普通的FL相比,BlockFL带来了这些好处,但是BlockFL需要考虑区块链网络产生的额外延迟。为了解决这个问题,BlockFL的端到端延迟模型是通过考虑通信、计算和PoW延迟来制定的。通过调整块生成速率,即PoW难度,将产生的延迟最小化。
三、架构和方法
BlockFL中的FL操作:所研究的FL是基于一组设备D ={1,2,···, D N D_N DN}展开的,其中|D| = D N D_N DN。第i台 D i D_i Di拥有一组数据样本 S i S_i Si 并且,| S i S_i Si| = N i N_i Ni,并训练其局部模型。本地模型更新设备 D i D_i Di上传到其关联的矿工 M j M_j Mj,该矿工是从一组矿工M={1,2,···, N M N_M NM}中一致随机选择的。
我们的分布式模型训练侧重于以并行方式解决回归问题,考虑一组整个设备的数据样本
…
目标是最小化全局权值向量的损失函数f(w),选取损失函数f(w)作为均方误差,深度神经网络下的其他损失函数可以很容易地加入,如[10]。
为了解决上述问题,遵循[4]中的vanilla FL设置,通过随机方差降梯度算法[4]对设备 D i D_i Di模型进行局部训练,并使用分布式近似牛顿法对所有设备的局部模型更新进行聚合。对于每个epoch,用迭代次数 N i N_i Ni更新设备的局部模型。在第t次epoch的第t次局部迭代时,得到局部权值 w i w_i wi
…
在[4],[5]的vanilla FL中,设备 D i D_i Di上传它的本地模型更新到中心服务器,模型更新大小 δ m \delta_m δm对于所有的设备都是一样的。全局模型更新数据由服务器计算。在BlockFL中,服务器实体被区块链网络替换,具体如下所述。
BlockFL中的Blockchain操作:在BlockFL中,M中的矿工对区块及其验证进行了设计,以便通过分布式账本真实地交换本地模型更新。分类账中的每个区块被分为主体部分和标题部分。在BlockFL中,主体存储D中设备的本地模型更新,即,对于设备 D i D_i Di在第t个epoch,以及它的局部计算时间T,这将在本小节的末尾讨论。 报头包含指向前一个块的指针信息,块生成速率 λ \lambda λ,以及PoW的输出值.
…
分别,每个矿机都有一个候选块,其中填充了来自其关联设备和/或其他矿机的本地模型更新。填充过程继续进行,直到它达到块大小或等待时间 T w T_w Tw。
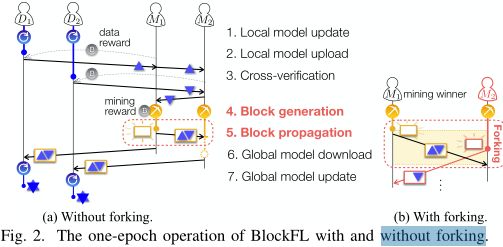
在PoW[8]之后,矿工通过改变其输入数字随机生成一个哈希值,即:nonce,直到生成的散列值小于目标值为止。一旦矿工 M 1 M_1 M1成功找到哈希值,它的候选块将被允许为一个新块,如图2所示。块生成速率 λ \lambda λ可以被PoW的难度所控制,例如:较低的PoW目标散列值,越小的 λ \lambda λ。由于简单和鲁棒性,PoW被应用于无线系统,如[11],[12]。BlockFL还可以使用其他共识算法,如权益证明(PoS)或拜占庭容错(BFT),这可能需要更复杂的操作和初步操作才能在矿工之间达成共识。
生成的区块被传播到所有其他矿工。为此,就像[8]中所做的那样,所有接收到生成区块的矿工都被迫停止他们的PoW操作,并将生成的区块添加到他们的本地账本中。如图2所示,如果另一个矿工 M 2 M_2 M2在第一个生成块的传播延迟内成功生成了自己的块,那么部分矿工可能会错误地将第二次生成的块添加到自己的本地账本中,称为fork。在BlockFL中,fork使得一些设备将错误的全局模型更新应用到下一次本地模型更新中。频繁的fork会增加 λ \lambda λ和块传播延迟。本文将在第三节中详细说明该问题的缓解措施。
区块链网络还为设备的数据样本和挖掘者的验证过程提供奖励,分别称为数据奖励和挖掘奖励。设备 D i D_i Di从其关联矿机接收到的数据奖励,其数量与数据样本大小 N i N_i Ni成正比。当矿机 M j M_j Mj生成一个区块时,它的采矿奖励由区块链网络获得,就像传统的区块链结构[8]所做的那样。挖掘奖励的数量与其所有关联设备的汇总数据样本大小成正比。值得注意的是,BlockFL可以使用奖励机制进一步改进,该机制不仅考虑到影响FL准确性的数据样本的大小,还考虑到数据样本的质量。不真实的设备可能会通过任意本地模型更新来膨胀其样本大小。矿工在存储它们之前,通过比较样本大小 N i N_i Ni与其相应的计算时间T来验证真实的局部更新。这可以通过英特尔的软件保护扩展在实践中得到保证,它允许应用程序在一个受保护的环境中运行,这在区块链技术中得到了利用。
BlockFL 一个epoch的操作:主要是以下的七个步骤。
1.本地模型更新:设备Di经过Ni次迭代
2.本地模型上传:
3.交叉验证:矿工传播得到的本地模型更新,与此同时,矿工从其他设备或者矿工验证接收到的本地模型更新
4.生成块:每一个矿工开始运行工作量证明直至它找到随机数或者得到形成的区块
5.区块传播:记作第一个找到随机数的矿工
6.全局模型下载:设备从它对应的矿工下载形成的区块
7.全局模型更新:设备本地计算全局的模型更新,通过在形成的区块使用聚合的本地模型更新
集中式FL容易受到服务器故障的影响,这将扭曲所有设备的全局模型。然而,在BlockFL中,全局模型更新是在每个设备上本地计算的,这对故障是健壮的,并防止矿工的过度计算开销。
三、端对端延迟分析
一个epoch的BlockFL的延迟模型: …
时延最优区块形成速率: …
四、数值结果与讨论
…
REFERENCES
[1] P . Popovski, J. J. Nielsen, C. Stefanovic, E. de Carvalho, E. G. Ström,K. F. Trillingsgaard, A. Bana, D. Kim, R. Kotaba, J. Park, and R. B.Sørensen, “Wireless Access for Ultra-Reliable Low-Latency Communi-cation (URLLC): Principles and Building Blocks,” IEEE Netw., vol. 32,
pp. 16–23, Mar. 2018.
[2] M. Bennis, M. Debbah, and V . Poor, “Ultra-Reliable and Low-Latency Wireless Communication: Tail, Risk and Scale,” [Online]. Available:https://arxiv.org/abs/1801.01270.
[3] J. Park, D. Kim, P . Popovski, and S.-L. Kim, “Revisiting Frequency Reuse towards Supporting Ultra-Reliable Ubiquitous-Rate Communica-tion,” in Proc. IEEE WiOpt Wksp. SpaSWiN, May 2017.
[4] J. Koneˇ cn´ y, H. B. McMahan, D. Ramage, “Federated Optimization:Distributed Machine Learning for On-Device Intelligence,” [Online].Available: https://arxiv.org/abs/1610.02527.
[5] H. B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A.y Arcas,“Communication-Efficient Learning of Deep Networks from Decentral-ized Data,” in Proc. AISTATS, F ort Lauderdale, FL, USA, Apr. 2017.
[6] J. Park, S. Samarakoon, M. Bennis, and M. Debbah, “Wireless network intelligence at the edge,” submitted to Proc. IEEE [Online]. ArXiv preprint: https://arxiv.org/abs/1812.02858.
[7] H. B. McMahan, and D. Ramage, “Federated Learning: Collabo-rative Machine Learning without Centralized Training Data,” [On-line] Available at: https://ai.googleblog.com/2017/04/federated-learning-
collaborative.html, 2017.
[8] S. Nakamoto, “Bitcoin: A Peer-to-Peer Electronic Cash System,” [On-line]. Available: https://bitcoin.org/bitcoin.pdf.
[9] C. Decker, and R. Wattenhofer, “Information Propagation in the Bitcoin Network,” in Proc. IEEE P2P , Torento, Italy, Sep. 2013.
[10] S. Samarakoon, M. Bennis, W. Saad, and M. Debbah, “Distributed Federated Learning for Ultra-Reliable Low-Latency V ehicular Commu-nications,” [Online]. Available: https://arxiv.org/abs/1807.08127.
[11] P . Danzi, A. E. Kalør, C. Stefanovi´ c, and P . Popovski, “Analysis of the Communication Traffic for Blockchain Synchronization of IoT Devices,” Proc. IEEE Int. Conf. on Commun. (ICC), 2018.
[12] N. C. Luong, D. Niyato, P . Wang, and Z. Xiong, “Optimal Auction for Edge Computing Resource Management in Mobile Blockchain Networks: A Deep Learning Approach,” Proc. IEEE Int. Conf. on
Commun. (ICC), 2018.
[13] L. Chen, L. Xu, N. Shah, Z. Gao, Y . Lu, and W. Shi, “On Security Analysis of Proof-of-Elapsed-Time,” in Proc. SSS, Boston, MA, USA,Nov. 2017.