目标检测篇之---RCNN, Fast RCNN, Faster RCNN
RCNN, Fast RCNN, Faster RCNN
刚涉足目标检测,向通过写博客来记录一下自己的学习过程,也希望可以给大家的学习带来一些帮助,今天的2021年的最后一天,希望看到我文章的朋友们,在新的一年里都能学有所成,学有所获!

R-CNN算法最早在2013年被提出,它的出现打开了运用深度学习进行目标检测的大门,从此之后,目标检测的精准度与实时性被不断刷新。R-CNN系列算法自提出之际,就非常引人注目,以至于在之后的很多经典算法中,如SSD、YOLO系列、Mask R-CNN中都能看到它的影子。
R-CNN、Fast R-CNN采用的还是传统的SS算法(selective search)生成推荐区域,计算非常耗时,达不到实时检测的效果。直到Faster R-CNN才使用RPN代替了原来的SS算法,才使得目标检测的时间大大缩短,达到实时性的效果。
本篇博客先会对R-CNN、Fast R-CNN、Faster R-CNN进行一个简明扼要地讲解,之后,会写博客着重讲解R-CNN 系列的灵魂之作——Faster R-CNN,而这部分才是大家需要着重了解的。
一、RCNN(Region with CNN feature)
论文:
RCNN可以说是利用深度学习进行目标检测的开山之作。作者Ross Girshick多次在PASCAL VOC目标检测竞赛中折桂,这种算法的平均精确度比之前在VOC2012数据集上的最好测试效果还要高30%。并且,由该算法提出的论文《Rich feature hierarchies for accurate object detection and semantic segmentation》获得了世界计算机视觉顶会CVPR2014的最佳论文奖。
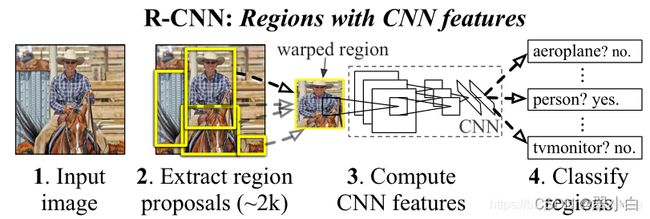
RCNN算法流程,可分为4步:
1.一张图片生成1K~2K个候选区域(SS算法)
利用SS算法通过图像分割的方法得到一些原始区域,然后使用一些合并策略将这些区域合并,得到一个层次化的区域结构,而这些结构就包含着可能需要的物体。

2.对每一个候选区域,都使用深度神经网络(AlexNet)提取特征,得到1*4096的特征向量。
将2000个候选区域缩放到227×227pixel,接着将候选区域输入事先训练好的AlexNet CNN网络中获取4096维的特征得到2000×4096维矩阵。
3.将每一个特征向量送入每一类的SVM分类器,判断是否属于该类
SVM是一个二分类器,所以它针对每一个类别都有一个专门的分类器,针对PASCAL VOC来说,它有20个类别,所以就有20个分类器。将2000×4096的特征矩阵与20个SVM组成的权值矩阵4096×20相乘,获得2000×20的概率矩阵,每一行代表一个建议框归于每个目标类别的概率。分别对上述2000×20维矩阵中每一列即每一类进行非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
非极大值抑制
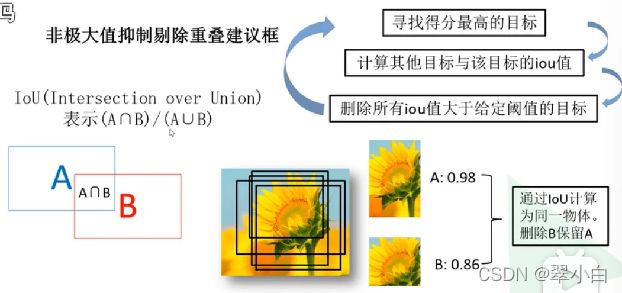
4.对已分类的推荐框进行线性回归,对这些框进行精细地调整,得到更加准确的边界框坐标。
对非极大值抑制(NMS)处理后剩余的建议框进一步筛选。接着分别对20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
R-CNN算法的检测效果很好,但是检测速度很慢,因此总体效率不高。其主要原因在于:
提取特征操作非常冗余。检测时,需要将每个推荐区域都送入训练好的模型(AlexNet)进行前向传播,因此每张图片大约要进行1000~2000次前向传播。
训练速度慢,过程繁琐。要单独分别训练三个不同的模型:CNN用来提取图像特征、SVM分类器用来预测类别、回归器精细修正建议框的位置。分开训练,耗时耗力。
使用Selective Search算法生成推荐区域,这个过程大约耗时2s,也是它不能达到实时性检测的一个重要原因。
通过以上讲解,我们可以发现RCNN的基本框架
| Region proposal(Selective Search) |
| Feature extraction(CNN)|
| Classification(SVM) | Bounding-box regression(regression)
二、Fast RCNN
2015年,Ross Girshick等人在R-CNN的基础上进行了改进,解决了上述影响R-CNN效率的前两个问题。与R-CNN相比,训练速度快了9倍;测试速度快了213倍;在Pascal VOC数据集上,准确率从62%提升到了66%。
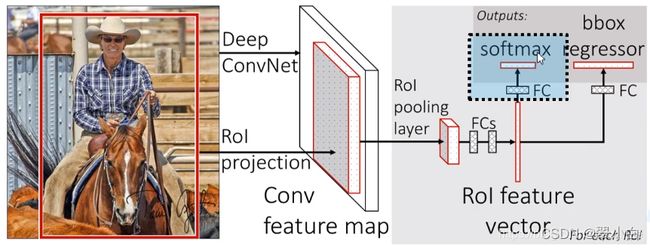
如上图所示,Fast R-CNN算法的流程主要分为下面三个步骤:
1.依然先使用SS(Selective Search)方法,使一张图片生成1000~2000个候选区域。
2.将图像输入到一个CNN(VGG-16)得到相应的特征图,然后将已经生成的候选框投影到特征图上获得相应的特征矩阵。
3.将每个特征矩阵通过ROI Pooling层缩放到7*7大小,然后将特征图展平,在通过一系列全连接层得到预测的类别信息和目标边界框信息。(ROI:Region of Interest)
Fast R-CNN基本框架:
| Region proposal(Selective Search) |
| Feature extraction(CNN)|
| Classification(SVM) |
| Bounding-box regression(regression)|
Fast R-CNN的改进点:
ROI Pooling层。这个方法是针对R-CNN的第一个问题提出来的,用来解决提取特征操作冗余的问题,避免每个推荐区域都要送入CNN进行前向计算。核心思路是:将图像只输入CNN提取特征,只进行一次前向计算。得到的特征图由全部推荐区域共享。然后再将推荐区域(SS算法得到)投影到特征图上,获得每个推荐区域对应的特征图区域。最后使用ROI Pooling层将每个特征图区域下采样到7*7大小。
将原来三个模型整合到一个网络,易与训练。R-CNN算法使用三个不同的模型,需要分别训练,训练过程非常复杂。在Fast R-CNN中,直接将CNN、分类器、边界框回归器整合到一个网络,便于训练,极大地提高了训练的速度。
三、Faster RCNN
Faster R-CNN算法将Region Proposal Networks与Fast R-CNN进一步合并为一个单个网络,是作者Ross Girshick继Fast RCNN后的又一力作,同样使用VGG16作为网络的backbone,推理速度在GPU上达到5fps,准确率也有进一步的提升。在2015年的ILSVRC以及COCO竞赛中获得多个项目的第一名。
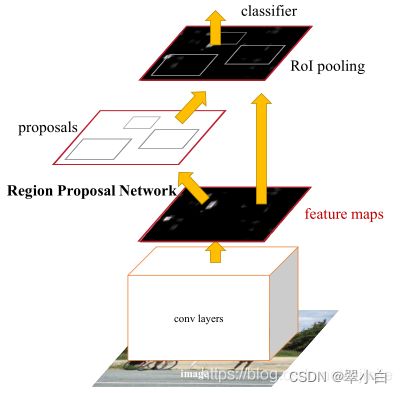
如上图所示,Faster R-CNN算法流程主要有以下4个步骤:
Conv layers。首先将图像输入到CNN(VGG-16)提取图像特征,得到的feature maps 将被共享用于后面的RPN和ROI Pooling。
Region Proposal Networks。RPN用于生成推荐区域。该网络通过softmax判断anchors属于positive还是negative,再利用边界框回归修正anchors获得精确的推荐框proposals。
ROI Pooling。该层以feature maps和proposals同时作为输入,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Classifer。将proposal feature maps输入全连接层与预测proposals的类别;同时再次进行边界框回归,获得检测框最终的精确位置。
相比Fast-RCNN,改进后的Faster R-CNN算法不仅速度上很很大提升,基本可以达到实时的检测帧率;检测精度也有所提高。
接下来会详细的学一下Faster RCNN,学完之后会更新博客,谢谢大家~
参考资料:https://blog.csdn.net/wjinjie/article/details/105930512