5.15 vs2019 静态编译_浅析同一段C++代码在Win X64, X86,MAC,Android ARM64平台编译器优化之美...
背景:定位一些Crash崩溃时,由于缺少更多信息,可能需要从反汇编的静态代码段推测对应的C++代码,并结合寄存器值分析出具体原因。对于Release发布版,由于编译器的强行函数内联和生成指令优化,会出现反汇编代码和C++源码区别较大,加大我们从汇编代码反推C++难度,一但我们分析清楚优化点,可以很欣赏编译器优化之美。
本文是从ARM64平台的一次crash反汇编分析经历出发,发现编译器能在我们根本没写判断的情况下,自动增加条件判断,启用128位寄存器的NENO指令进行加速,这是我以前在PC平台从未见过的优化,惊叹之佘,忍不住在我手上仅有的多平台做进一步分析,写一段简单C++代码,同样的代码在Windows下用VS2019选X64,X86,MAC家的XCode C++ 64位 ,Android Studio的ARM64,这四个平台都用Release版本生成,然后用IDA进行静态分析对比,体验一下编译器的强大之处。
我简单写了一个测试样例,C++字符串,加上测试,全部只有60行。为了简化,没有专门的内存分配器,也没有引入一些迭代器,萃取机制,为了简化也有直接用strlen()取长度等不符合模板泛型编程等,但这些不影响分析。无论在那个平台下,都用同样的代码,都会重点分析TestMyString()函数和生成以及差别最大的TCopy()函数。
template
T* TCopy(const T* pStart, const T* pFinish, T* pDst)
{
for (; pStart != pFinish; ++pDst, ++pStart)
{
*pDst = *pStart;
}
return pDst;
};
template
struct TString
{
~TString()
{
if (_StartPtr) delete _StartPtr;
}
TString(const T* pcStr)
{
Assign(pcStr, pcStr + strlen(pcStr));
}
TString& operator = (const TString& rkRight)
{
if (&rkRight != this)
{
Assign(rkRight._StartPtr, rkRight._FinishPtr);
}
return *this;
}
void Assign(const T* pStart, const T* pFinish)
{
if (pStart == pFinish || nullptr == pStart)
{
_FinishPtr = _StartPtr;
return;
}
int iLen = pFinish - pStart;
int iSelfSize = _FinishPtr - _StartPtr;
if (iSelfSize < iLen)
{
if (_StartPtr) delete _StartPtr;
_StartPtr = new char[iLen + 1];
_EndOfStrore = _StartPtr + iLen;
}
_FinishPtr = TCopy(pStart, pFinish, _StartPtr);
*((char*)_FinishPtr) = '0';
}
T* _StartPtr = nullptr;
T* _FinishPtr = nullptr;
T* _EndOfStrore = nullptr;
};
using MyString = TString;
void TestMyString()
{
MyString s1("HelloWrold");
MyString s2("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ");
s1 = s2;
} windows X64平台:
我们先用VS2019在main函数调用TestMyString(),然后生成windows的X64平台可执行文件,选Release,VS默认速度最快优化,,用IDA反编译工具打开生成的exe,跳到main代码段。好家伙,TestMyString()不见了,直接优化内联展开,省去call,ret开销,且TestMyString里面子函数调用,也全部优化掉,比如
TString& operator = (const TString& rkRight);
void Assign(const T* pStart, const T* pFinish);
T* TCopy(const T* pStart, const T* pFinish, T* pDst); 变成内联,一股脑的全放到main里面了,这也是最常见的优化。

我们重点分析一下:全部汇编代码较长,我们选取部分,也是优化有差别的部分,C++中s1 = s2;这句的反汇编。这本应该调用TString的赋值构造函数,只是优化后全部放在一起了,为了对汇编更好的理解,我对每行都进行注释解析,你只要一行一行看看注释就可以了。如果想深入,可以边看C++代码,边看注释,体验对应关系,感受编译器的优化。
.text:X64总结:非常强的调用优化,除了new,delete系统函数,减少全部子函数的call,ret开销,其中内联TCopy(const T* pStart, const T* pFinish, T* pDst)代码区块,三个参数中pFinish算是略去(利用很早rbx就保存了),没有照本宣科。也能知道T是POD类型,没有单独的赋值构造,也是比较巧秒的。
windows X86平台:
操作同X64,,用IDA反编译工具打开生成的exe,一看哦呵,这优化有点弱啊,虽然代码比较简单,但不像x64代码,所有函数一股脑优化到main中,win32函数跳转都没有省去。我又仔细对比了VS工程C++优化选项卡,发现win64对于omit-frame-pointer是空的,查所有参数也没有标明“/Oy-”或者“Oy”;x86默认是否的,我手动打开吧,不然更比不过x64了。
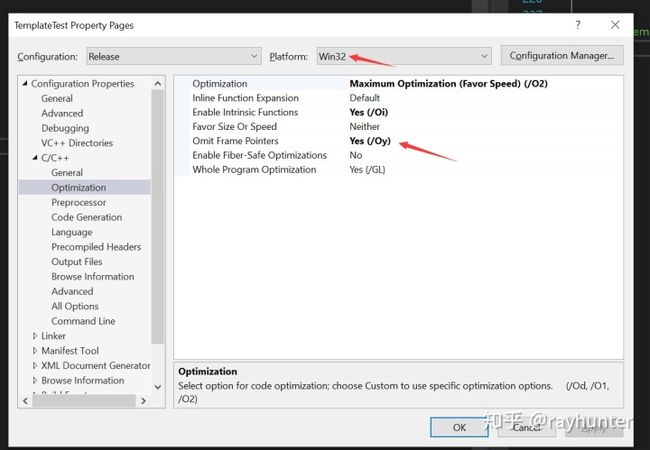
启用omit-frame-pointe,重新编译生成。用IDA打开,首先发现x86代码虽然大部分也直接优化到main中,但一些函数调用还是没有优化掉,比如TString

受限于篇幅,加上和X64代码非常的像,我们只分析最核心的,和后面ARM平台差别比较大的一部分汇编,下面汇编代码对应TString
.text:X86总结:调用优化还算可以,除了new,delete系统函数,只有TString
MAC平台:
MAC平台用XCode生成64位的Release可执行程序,工程全部默认值,没有开单独的优化。发现和X86差不多的水平,函数调用开销没有怎么省,该call还是call,而且有更多的栈保护与平衡,甚至弱于x86,虽是64位,但一点也没有像X64那么激进。

由于MAC下生成执行程序的反汇编和x86差不多代码,再注释也是重复的,我们就不一行一行的分析了,有兴趣的可以看IDA。不过发现这里有个亮点,就是MAC启用SSE指令集,使用XMM的128位寄存器,属于SIMD,还是可以的。摘录一下这段代码,并注释,来自TestMyString()函数。
__text:总结:函数调用方面比X86还保守点,没有太多亮点,但居然自己动使用了SSE指令集,128位的XMM0直接清零两个指针,SIMD操作,也是不单手动开其它可选优化时的亮点。
Android的ARM64平台:
采用Android Studio,选择Native C++工程,将前面的C++代码放到cpp,选择Release版本,Arm64平台,编译生成.so运行库二进制代码。为了这个我专门IDA动态反调试一把Release的APK,两个字,舒服。不过我也是刚接触IDA和Android开发,也不太熟悉,所以才惊叹它的优化,可能后面就会麻木。

这边我就静态分析了,总的看起来非常强的调用优化,除了new,delete系统函数,减少全部子函数的调用开销全部优化掉,也是一股脑全部放到一起,加大反推C++难度,和X64差不多水平,但细节没有x64秒。
下面说这里面有个非常强的优化,那就是启用NENO指令,由于有前面三个平台那么多分析,特别通用的地方就不再赘述,下面对部分汇编代码进行分析,实际是T* TCopy(const T* pStart, const T* pFinish, T* pDst)的代码,这个优化在拷大字符串,还是真香,尤其真机Release调试一下,妙。我也用Android Studio生成Deubg版本,实机也调试过,发现没有这段NENO优化。
NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为ARMv5 性能的3倍,为 ARMv6 SIMD性能的2倍。本文是用了128位的Q0,Q1,由于有前面三个平台那么多分析,特别通用的地方就不再赘述,下面对部分汇编代码进行分析。
.text:总结:和X64差不多一样的优化水平,还引用NENO指令加速,一次处理256bit数据,自动增加和32条件判断,第一次见,太强了,秒秒秒!
综述:这个简单的测试C++样本,ARM64编译表现最强,优化综合也是最强的,启用NENO指令,自动增加条件语句,一次处理32个字符,完全吊打的级别。如果没有NENO指令,Windnows下X64可以说优化最美最强的。剩下MAC和X86都差不多,不过MAC还是用了一点点SSE,采用SIMD,至少128bit操作吧,还算亮点吧。两者基本都是照C++一行一行翻译,中规中矩。
注:本文原创,不足之处,欢迎点评。编译器优化和开发软件相关也和目标平台有关,同样代码,不同版本的开发软件生成代码也不同,同一平台,同一软件,编译选项也有非常大的关系,本文均是采用Release版的默认设置,除了X86默认下太拉跨,手动开了omit-frame-pointer。这里不是说那个编译器好那个差,只是从汇编层面对比一下不同平台C++生成二进制代码的美妙之处。