Spark入门到精通-番外篇(Standaone集群的运维和简单操作)
安装包下载
Index of /dist/spark

spark集群的master和work单独启动
要单独启动那么必须先启动master,然后在启动work
tar -zxvf spark-3.0.0-bin-hadoop2.7.tgz配置环境变量
sudo vi /etc/profile.d/my_en.sh#SPARK_HOME
export SPARK_HOME=/home/atguigu/spark-3.0.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_en.sh先在一台机器上面启动master
cd sbin./start-master.sh启动脚本可选参数
-h HOST,--host HOST 在哪台机器上启动,默认都是本机
-p PORT,--port PORT 在机器上启动后,使用哪个端口对外提供服务,master默认是7077,worker默认是随机的
--webui-port PORT web ui的端口,master默认是8080,worker默认是8081
-c CORES,--cores CORES 仅限于worker,总共能让spark application使用多少个cpu core,.默认是当前机器上所有的cpu core
-m MEM,--memory MEM 仅限于worker,总共能让spark application使用多少内存,是100M或者1G这样的格式
-d DIR,--work-dir DIR 仅限于worker,工作目录,默认是SPARK_HOME/work目录
--properties-file FILE master和worker加载配置文件的地址,默认是SPARK_HOME/conf/spark-default.conf启动以后查看日志的地方(根据自己的机器来)就是在logs目录里面
/home/atguigu/spark-3.0.0-bin-hadoop2.7/logs/spark-atguigu-org.apache.spark.deploy.master.Master-1-hadoop102.out
根据日志知道返回http:hadoop102:8081进入web界面
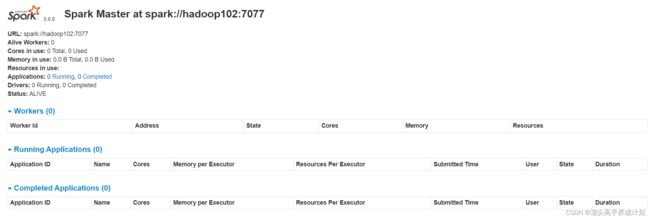
如果想关闭则使用
./stop-master.sh
然后启动加入master的slave
./start-slave.sh spark://hadoop102:7077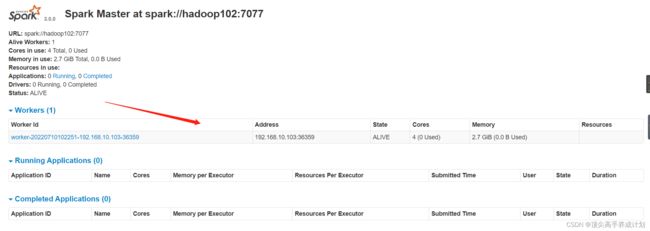
可以看到加入成功
如果先退出master
./stop-slave.sh对于work机器限定内存
./start-slave.sh spark://hadoop102:7077 --memory 500M
可以看到设置成功
集群配置
| hadoop102 | hadoop103 | hadoop104 |
| master,work | work | work |
| historyserver |
环境准备
前提有java环境
然后集群的机器都配置了spark的环境变量
配置环境变量
sudo vi /etc/profile.d/my_en.sh#SPARK_HOME
export SPARK_HOME=/home/atguigu/spark-3.0.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/binsource /etc/profile.d/my_en.sh开始配置和安装
进入配置目录, 并复制一份新的配置文件spark-env.sh, 以供在此基础之上进行修改
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
vi spark-env.shexport JAVA_HOME=/opt/module/jdk/jdk1.8.0_161
# 指定 Spark Master 地址
export SPARK_MASTER_HOST=hadoop102
export SPARK_MASTER_PORT=7077修改配置文件 slaves, 以指定从节点为止, 从在使用 sbin/start-all.sh 启动集群的时候, 可以一键启动整个集群所有的 Worker
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp slaves.template slaves
vi slaveshadoop102
hadoop103
hadoop104配置 HistoryServer
默认情况下, Spark 程序运行完毕后, 就无法再查看运行记录的 Web UI 了, 通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程
复制 spark-defaults.conf, 以供修改
cd /home/atguigu/spark-3.0.0-bin-hadoop2.7/conf
cp spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.confspark.eventLog.enabled true
spark.eventLog.dir hdfs://node01:8020/spark_log
#spark.eventLog.dir (先在每一台机器上面创建对应的目录) /home/atguigu/spark-3.0.0-bin-hadoop2.7/historywork
spark.eventLog.compress true将以下内容复制到`spark-env.sh`的末尾, 配置 HistoryServer 启动参数, 使得 HistoryServer 在启动的时候读取 HDFS 中写入的 Spark 日志
# 指定 Spark History 运行参数
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://node01:8020/spark_log"
#下面是不使用hdfs
#export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=4000 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=/home/atguigu/spark-3.0.0-bin-hadoop2.7/historywork"为 Spark 创建 HDFS 中的日志目录(保存到本地就不用)
hdfs dfs -mkdir -p /spark_log将 Spark 安装包分发给集群中其它机器
然后
启动 Spark Master 和 Slaves, 以及 HistoryServer
sbin/start-all.sh
sbin/start-history-server.sh结果
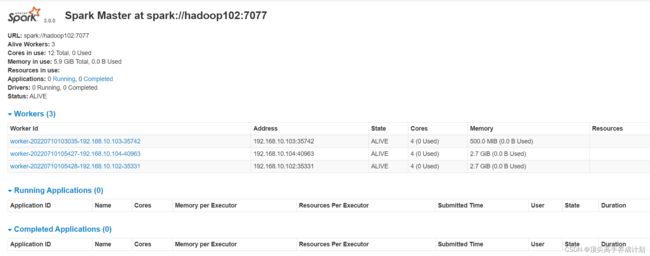
执行测试
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/examples/jars/spark-examples_2.12-3.0.0.jar \
100集群提交作业
pom.xml
org.apache.spark
spark-core_2.12
3.0.0
org.apache.spark
spark-sql_2.12
3.0.0
org.apache.spark
spark-streaming_2.12
3.0.0
org.apache.spark
spark-streaming-kafka-0-10_2.12
3.0.0
com.fasterxml.jackson.core
jackson-core
2.10.1
org.apache.spark
spark-hive_2.12
3.0.0
provided
redis.clients
jedis
3.1.0
org.apache.maven.plugins
maven-compiler-plugin
3.1
1.8
1.8
org.apache.maven.plugins
maven-shade-plugin
2.4.3
shade-my-jar
package
shade
*:*
META-INF/*.SF
META-INF/*.DSA
META-INF/*.RSA
com.zhang.one.JavaWordCount
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
-dependencyfile
${project.build.directory}/.scala_dependencies
测试的程序
object ScalaJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("ScalaJoin")
.setMaster("local")
val stuInfo: Array[(Int, String)] = Array(
(1, "zhangsan"),
(2, "lisi"),
(3, "wanwu")
)
val soreInfo= Array(
(1,90),
(1,80),
(2,90),
(3,90)
)
val sc = new SparkContext(conf)
val stuRDD: RDD[(Int, String)] = sc.parallelize(stuInfo)
val scoreRDD: RDD[(Int, Int)] = sc.parallelize(soreInfo)
stuRDD.join(scoreRDD)
.foreach(println)
sc.stop()
}
}然后打包
client模式提交(这个是默认的提交模式它和cluster的区别就是driver启动的位置不同)
bin/spark-submit \
--class com.zhang.one.scala.ScalaJoin \
--master spark://hadoop102:7077 \
--deploy-mode client \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jarcluster提交
bin/spark-submit \
--class com.zhang.one.scala.ScalaJoin \
--master spark://hadoop102:7077 \
--deploy-mode cluster \
--executor-memory 1G \
--total-executor-cores 2 \
/home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jar集群提交的 时候有时候会出现(这是由于集群环境下Driver是随机的在一台机器上面启动,如果启动的时候不在有jar包的机器上面那么就会说找不到文件,我们可以把它分发到集群的所有work机器就不会出现了,yarn模式就没有这个问题)
java.nio.file.NoSuchFileException: /home/atguigu/spark-3.0.0-bin-hadoop2.7/original-sparkstart-1.0-SNAPSHOT.jar
at sun.nio.fs.UnixException.translateToIOException(UnixException.java:86)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:102)
at sun.nio.fs.UnixException.rethrowAsIOException(UnixException.java:107)
at sun.nio.fs.UnixCopyFile.copy(UnixCopyFile.java:526)
at sun.nio.fs.UnixFileSystemProvider.copy(UnixFileSystemProvider.java:253)
at java.nio.file.Files.copy(Files.java:1274)
at org.apache.spark.util.Utils$.copyRecursive(Utils.scala:690)
at org.apache.spark.util.Utils$.copyFile(Utils.scala:661)
at org.apache.spark.util.Utils$.doFetchFile(Utils.scala:735)
at org.apache.spark.util.Utils$.fetchFile(Utils.scala:535)
at org.apache.spark.deploy.worker.DriverRunner.downloadUserJar(DriverRunner.scala:166)
at org.apache.spark.deploy.worker.DriverRunner.prepareAndRunDriver(DriverRunner.scala:177)
at org.apache.spark.deploy.worker.DriverRunner$$anon$2.run(DriverRunner.scala:96)
22/07/10 11:34:23 INFO ShutdownHookManager: Shutdown hook called
22/07/10 11:34:23 INFO ShutdownHookManager: Deleting directory /tmp/spark-b30b0542-0048-4784-989a-626bdb582bd8