Spark总结(SparkCore,SparkSQL,SparkStreaming)
SparkCore
1.一句话介绍Hadoop 和 Spark
spark是基于内存的分布式计算框架。
hadoop是一个分布式计算开源框架,包含分布式文件系统HDFS、 MapReduce分布式计算的软件架构和Yarn资源管理调度系统。
2.Spark和MR的区别
1.MR是基于磁盘迭代处理数据,Spark是基于内存处理数据
2.Spark有DAG有向无环图做优化
3.MR是细粒度资源申请,application执行慢,spark是粗粒度资源申请,application执行快
4.MR没有SQL,流处理功能,Spark有SQL功能以及流处理功能
5.MR没有高级算子的封装,Spark提供了各种高级算子(函数)
3.Spark的运行模式
1)Local:运行在一台机器上。 测试用。
2)Standalone:是Spark自身的一个调度系统。 对集群性能要求非常高时用。国内很少使用。
3)Yarn:采用Hadoop的资源调度器。 国内大量使用。
4)Mesos:国内很少使用。
4.常用端口号总结
Hadoop
NameNode WebUI 2.x 50070 3.x 9870
访问MR执行情况端口(yarn) 8088
历史服务器 19888
客户端访问集群端口(内部通信) 2.x 9000 3.x 8020
Spark
spark-shell任务端口 4040
内部通讯端口 7077
standalone,master web 8080
历史服务器 18080
其他
zookeeper 2181
redis 6379
mysql 3306
kafka 9092
hbase master WebUI 60010
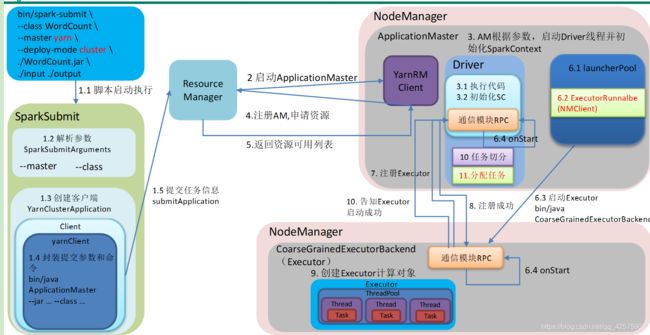
5.简述Spark的架构与作业提交流程
6.RDD的五大特性
RDD是由一系列Partition组成
算子是作用在partition上的
RDD之间有依赖关系
分区器是作用在KV格式的RDD上的
partition对外提供了最佳的计算位置(移动数据不如移动计算)
7.Transformation算子
单value
map
mapPartitions
mapPartitionsWithIndex
flatMap
groupBy
filter
sample(true,0.3) 放回抽样,抽样比例0.3
distinct去重,原理reduceByKey 有shuffle
coalesce 减少分区用coalesce(num,false) 不shuffle
repartition 增加分区用repartition(num) =coalesce(num,true) 有shuffle
sortBy
双value
intersection 它是去二个rdd的交集 有shuffle
union 取两个RDD的并集,不去重,会增加partition的数量,同时并行度也会增加
K-V
reduceByKey
groupByKey
sortByKey
aggregateByKey
join
8.action算子
collect
count
first take(1)
take
foreach
foreachPartitons
top
takeOrdered(n) 取出前n个元素,按升序列
9.Spark提交作业参数
./spark-submit --master yarn --deploy-mode cluster --class …jar …
1)在提交任务时的几个重要参数
executor-cores 4
num-executors 10
executor-memory 8g
driver-cores 2
driver-memory 8g
2)边给一个提交任务的样式
spark-submit \
–master yarn \
–deploy-mode cluster \
–driver-cores 2 \
–driver-memory 8g \
–executor-cores 4\
–num-executors 10 \
–executor-memory 8g \
–class PackageName.ClassName XXXX.jar \
–name “Spark Job Name” \
InputPath \
OutputPath
10.Spark宽窄依赖
窄依赖:父rdd与子rdd是一对一或多对一的关系
宽依赖:父rdd与子rdd是一对多或多对多的关系 有shuffle shuffle会落地到磁盘
比如,coalesce(num,false) 减少分区时,就不会产生shuffle
11.粗细粒度资源申请
粗粒度资源申请-Spark
Application执行之前首先将所有的资源申请完毕,Application中的每个job执行时不需要自己申请资源,自己释放资源,当application中最后一个job执行完成之后,所有的资源才会被释放,job执行快,application执行快,集群的资源不能充分利用。
细粒度资源申请-MR
Application启动之后,每个job自己申请资源自己释放资源,每个job执行完成之后,资源立即释放,集群资源可以充分利用, application执行相对慢。
12. Spark任务的划分
(1)Application:初始化一个SparkContext即生成一个Application;
(2)Job:一个Action算子就会生成一个Job;
(3)Stage:Stage等于宽依赖的个数加1;
(4)Task:一个Stage阶段中,最后一个RDD的分区个数就是Task的个数。
13.cache缓存级别
DataFrame的cache默认采用 MEMORY_AND_DISK
RDD 的cache默认方式采用MEMORY_ONLY
其他缓存级别
DISK_ONLY
MEMORY_AND_DISK_SER
MEMORY_AND_DISK_SER_2 数据存两份
MEMORY_AND_DISK_2
cache() = persist(StorageLevel.MEMORY_ONLY)
14.缓存和检查点
1)Checkpoint 需要手动指定磁盘目录,当Spark的application执行完成之后数据不会被清空,由于这个特点,checkpoint在Spark中常用于状态管理
2)Cache缓存只是将数据保存起来,不切断血缘依赖,当Spark的application执行完成之后数据会被清空。Checkpoint检查点切断血缘依赖。
3)建议对checkpoint()的RDD使用Cache缓存,这样checkpoint的job只需从Cache缓存中读取数据即可,否则需要再从头计算一次RDD。
15.Saprk二次排序
将数据封装到一个对象中,使用SortByKey对对象排序,对象需要实现可排序 Comparable 接口
16.Spark分组取TopN
1.GroupByKey后分组的数据放到集合中进行排序。取出前n个 数据量大会OOM
2.GroupByKey后分组的数据进行迭代,使用定长数组的方式拿到前n个,迭代器本身不储存数据。
17.Saprk广播变量
1)当Executor端使用到Driver端的变量时,如果不使用广播变量,每个Executor有多少task就有多少变量的副本。使用广播变量后,每个Executor只有一份Driver端变量的副本。
2)广播变量不能对RDD进行广播,可以将RDD回收到Driver端进行广播
3)广播变量只能在Driver端定义,在Executor端不能修改广播变量的值
4)广播变量的声明和使用
val broadcast :Broadcast[String] = sc.broadcast(str)
rdd.filter{
log=>log.contains(broadcast.value)
}
…
18.Spark累加器
累加器只能在Driver端定义初始化,在Executor累加
val sum:LongAccumulator = sc.longAccumulator(“sum”);
rdd.foreach{
sum.add(1)
}
19.会引起shuffle的Spark算子
reduceBykey:map端预聚合
groupByKey:没有map端预聚合
repartition: 重分区,一般用于增加分区
aggregateByKey
SortByKey:
SparkSQL
1.Hive on Spark 与Spark On Hive
hive on spark : hive映射HDFS上的表,解析优化SQL,底层转化为Spark执行
spark on hive : hive映射HDFS上的表,Spark解析优化SQL,Spark执行,写的是Spark代码
2.RDD & Dataset & DataFrame
1)RDD 是Spark Core底层操作的对象
2)Dataset是SparkSQL底层操作的对象,Dataset底层hash,filter,sort时不需要反序列化数据成对象,性能比RDD高
3)DataFrame = Dataset[Row] ,DataFrame中有数据和Schema信息,在Java api 没有DataFrame对象,就是Dataset
3.Spark配置对象和上下文对象
SparkConf : Spark 配置
SparkContext : Spark上下文,SparkCore编程需要创建SparkContext
SQLContext : 在SparkSQL编程中需要创建的对象,创建SQLContext,需要创建SparkConf,SparkContext()
HiveContext : SparkSQL读取Hive中的数据需要创建的对象,HiveContext就是SQLContext的子类
SparkSession :Spark2.0+ 版本之后推出对象,兼容了SparkConf,SparkContext,SQLContext,HiveContext对象,方便编程。
4.RDD如何转换为DataFrame
1)通过反射方式(推荐)
(1)把数据切分组装到bean类中,用map算子返回
(2)导入隐式转换函数 import session.implicits._
(3)rdd.toDF
2)通过动态创建Schema
(1)把数据切分组装到Row中,用map算子返回
(2)构建StructType
val scheme: StructType = StructType(List[StructField](
StructField("id", DataTypes.IntegerType, true),
StructField("name", DataTypes.StringType, true),
StructField("age", DataTypes.IntegerType, true),
StructField("score", DataTypes.IntegerType, true)
))
(3) session.createDataFrame(rdd,scheme)
5.UDF
一对一
(1)导入隐式转换函数 import session.implicits._
(2) 向sparkSessionj注册udf函数 val addName: UserDefinedFunction = session.udf.register(“addName”, (x: String) => “Name=” + x)
(3) 在session.sql(“”)使用
SparkStreaming
1.MR & Spark &Storm
MR只能处理批数据,MR只有map和reduce,有原生api,没有高级算子的封装
Storm 处理实时流数据的框架,处理数据是一条条的,有原生api,不支持sql api
Spark 可以处理批数据,也可以处理流数据 可以使用Sql,有高级算子封装
SparkStreaming 是微批处理,吞吐量高,数据延迟较高,可以保证数据的一致性
2.SparkStreaming编程
val ssc = new StreamingContext(SparkConf,Durations.second(xx))
…
ssc.start()之后业务逻辑不能改变
3.SparkStreaming 处理数据过程
1.SparkStreaming读取socket数据首先 会启动一个job,接收数据
2.将batchInterval 接收过来的数据封装到一个batch中,batch又被封装到RDD中,RDD又被封装到DStream中
3.DStream有Transformation类算子可以转换数据,懒执行的,需要DStream的outputOperator类算子触发执行
4.reduceByKeyAndWindow 滑动窗口
每隔一段时间处理最近一段时间内数据 可以使用窗口操作
-
窗口长度:window length - wl ,必须是batchInterval整数倍
-
滑动间隔:sliding interval -si ,必须是batchInterval整数倍
-
reduceByKeyAndWindow(fun,窗口长度,滑动间隔) : 普通机制,每次计算都是将当前窗口内的批次全部重新计算
-
reduceByKeyAndWindow(fun1,fun2,窗口长度,滑动间隔) :优化机制,需要设置checkpoint 保存状态,每次计算根据上次结果统计得到
object SparkStreamingWindowFun {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setMaster("local[2]")
conf.setAppName("test")
val ssc = new StreamingContext(conf,Durations.seconds(5))
ssc.checkpoint("./data/ck1")
ssc.sparkContext.setLogLevel("Error")
val lines: ReceiverInputDStream[String] = ssc.socketTextStream("node5",9999)
val ds: DStream[String] = lines.window(Durations.seconds(15),Durations.seconds(5))
val words: DStream[String] = lines.flatMap(_.split(" "))
val pairWords: DStream[(String, Int)] = words.map(word=>{(word,1)})
val result: DStream[(String, Int)] = pairWords.reduceByKeyAndWindow(
(v1: Int, v2: Int) => {v1 + v2},
(v1: Int, v2: Int) => {v1 - v2},
Durations.seconds(15),
Durations.seconds(5))
// val result: DStream[(String, Int)] = pairWords.reduceByKeyAndWindow((v1: Int, v2: Int) => {
// v1 + v2
// },
// Durations.seconds(15),
// Durations.seconds(5))
result.print()
ssc.start()
ssc.awaitTermination()
}
5.foreachRDD
1).foreachRDD可以获取DStream中的RDD,对RDD使用RDD的算子操作,但是一定要对转换之后的RDD使用RDD的action算子触发
2).foreachRDD 算子内获取的RDD算子外的代码是在Driver端执行的。可以利用这个特点做到动态的改变广播变量
6.transform
1).可以获取DStream中的RDD,对RDD 可以使用RDD的算子操作,需要返回一个RDD
2).在transform算子内获取的RDD的算子外,代码是在Driver端执行的,可以做到动态改变广播变量
7.Driver HA
1.需要提交任务时指定 --supervise
- val ssc: StreamingContext = StreamingContext.getOrCreate(ckdir,myFun)
- myFun为返回StreamingContext的方法,里面是保存的状态和逻辑
/**
* Driver HA
* 实现 : 1. 需要提交任务时指定 --supervise 2.在代码中恢复数据
*/
object SparkStreamingDriverHA {
val ckdir = "./data/ck"
def main(args: Array[String]): Unit = {
//从checkpoint中恢复数据
val ssc: StreamingContext = StreamingContext.getOrCreate(ckdir,myFun)
ssc.start()
ssc.awaitTermination()
}
def myFun():StreamingContext = {
//SparkStreaming 配置
val conf = new SparkConf()
conf.setMaster("local")
conf.setAppName("test")
val ssc = new StreamingContext(conf,Durations.seconds(5))
//设置checkpoint
/**
* checkpoint中保存数据:
* 1.SparkStreaming 配置信息
* 2.当前SparkStreaming 处理的逻辑
* 3.保存当前SparkStreaming 处理数据状态(处理job的进度,每次处理数据的批次信息)
*/
ssc.checkpoint(ckdir)
//DStream处理逻辑
val lines: DStream[String] = ssc.textFileStream("./data/monitorFile")
lines.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.foreachRDD(rdd=>{
rdd.map(tp=>{
println("xxxxx"+tp)
tp._1+"_"+tp._2
}).foreach(println)
})
// .print()
ssc
}
}
8.SparkStreaming+kafka
receiver模式
receiver模式理解:
在SparkStreaming程序运行起来后,Executor中会有receiver tasks接收kafka推送过来的数据。数据会被持久化,默认级别为MEMORY_AND_DISK_SER_2,这个级别也可以修改。receiver task对接收过来的数据进行存储和备份,这个过程会有节点之间的数据传输。备份完成后去zookeeper中更新消费偏移量,然后向Driver中的receiver tracker汇报数据的位置。最后Driver根据数据本地化将task分发到不同节点上执行。
receiver模式中存在的问题
当Driver进程挂掉后,Driver下的Executor都会被杀掉,当更新完zookeeper消费偏移量的时候,Driver如果挂掉了,就会存在找不到数据的问题,相当于丢失数据。使用的是kafka的高级api,不能手动维护offset
如何解决这个问题?
开启WAL(write ahead log)预写日志机制,在接受过来数据备份到其他节点的时候,同时备份到HDFS上一份(我们需要将接收来的数据的持久化级别降级到MEMORY_AND_DISK),这样就能保证数据的安全性。不过,因为写HDFS比较消耗性能,要在备份完数据之后才能进行更新zookeeper以及汇报位置等,这样会增加job的执行时间,这样对于任务的执行提高了延迟度。
Driect模式
Direct模式理解
SparkStreaming+kafka 的Driect模式就是将kafka看成存数据的一方,不是被动接收数据,而是主动去取数据。消费者偏移量也不是用zookeeper来管理,而是SparkStreaming内部对消费者偏移量自动来维护,默认消费偏移量是在内存中,当然如果设置了checkpoint目录,那么消费偏移量也会保存在checkpoint中。当然也可以实现用zookeeper来管理。使用的是kafka的低级api,能手动维护offset,可以实现精准消费一条数据,偏移量的保存,是保存在zookeeper,Redis,MySQL中的。
Direct模式并行度设置
Direct模式的并行度是由读取的kafka中topic的partition数决定的。