kafka专题:kafka的Topic主题、Partition分区、消费组偏移量offset等基本概念详解
文章目录
- 1. kafka集群整体架构
- 2. kafka相关元素的基本概念
-
- 2.1 主题Topic和分区Partition
- 2.2 kafka消息存储在哪里?
- 2.3 分区副本
- 2.4 消费组和偏移量
- 2.5 单播消费和多播消费
- 3. kafka的顺序消费
1. kafka集群整体架构

kafka集群整体运作如上图所示,来看一下kafka的相关术语
| 名称 | 解释 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群Topic |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topicProducer |
| Producer | 消息生产者,向Broker发送消息的客户端Consumer |
| Consumer | 消息消费者,从Broker读取消息的客户端ConsumerGroup |
| ConsumerGroup | 消费者组,每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息Partition |
| Partition | 分区,物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
服务端(brokers)和客户端(producer、consumer)之间通信通过TCP协议来完成。
2. kafka相关元素的基本概念
2.1 主题Topic和分区Partition
Topic是一个逻辑概念,可以看做是一个消息类别的名称,同类消息发送到同一个Topic下面,比如订单消息,就只发送到订单Topic下面。Topic下面还可以划分很多Partition分区,不设置的话只有一个分区,所以从严格上来讲,消息其实是发送到Topic下的Partition分区中的!

Partition是一个有序的消息队列,这些message按顺序添加到一个叫做commit log的文件中。每个partition都对应一个commit log文件。partition中的消息都有一个唯一的编号,称之为offset,用来唯一标示某个分区中的message。 一个partition中的message的offset都是唯一的,但是不同的partition 中的message的offset可能是相同的。
kafka一般不会删除消息,不管这些消息有没有被消费。只会根据配置的日志保留时间(log.retention.hours)确认消息多 久被删除,默认保留最近一周的日志消息。kafka的性能与保留的消息数据量大小没有关系,因为数据是保存在磁盘上的,因此保存大量的数据消息日 志信息)不会有什么影响。
问题一:为什么kafka的Topic下要设置Partition分区的概念呢?
kafka的分区主要有以下两点作用:
- 消息日志文件会受到所在机器的文件系统大小的限制,分区之后,理论上一个topic可以处理任意数量的消息数据。
- 为了提高并行度。
kafka作为海量数据的应用场景选择,因为kafka的broker不会因消费而删除数据的特性(默认7天),如果持续有海量消息(订单)发送到kafka的topic下一个分区中,这个分区(队列)将变得非常之大,这台机器将消耗非常大的内存,由于单个分区只能有消费者组中的一个消费者进行消费,大数据下消费效率明显不理想。
针对这种大数据场景,kafka应用了分布式存储的思想,把订单Topic下划分很多Partition分区,不同的分区可以存在不同的集群机器节点上。在下订单场景中,海量的订单消息不在向同一个分区中发送,而是被分散到Topic下不同的分区中,达到了一个分布式存储的效果,有效的降低了单台机器压力,不同分区也可以有不同的消费者消费,同时也增加了消息消费能力
创建多个分区的主题
# 为test1主体创建2个分区
bin/kafka‐topics.sh ‐‐create ‐‐zookeeper 192.168.65.60:2181 ‐‐replication‐factor 1 ‐‐partitions 2 ‐‐topic test1
查看下topic的分区情况
# 查看test1主题的分区情况
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 192.168.65.60:2181 ‐‐topic test1

第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
- leader节点负责给定partition的所有读写请求。多个分区副本中的leader
- replicas表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
- isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
当然我们也可以通过如下命令增加topic的分区数量(目前kafka不支持减少分区):
# 把test主题的分区修改为3个
bin/kafka‐topics.sh ‐alter ‐‐partitions 3 ‐‐zookeeper 192.168.65.60:2181 ‐‐topic test
问题二:Topic,Partition和Broker 的关系是什么?
一个topic,代表逻辑上的一个业务数据集,比如按数据库里不同表的数据操作消息区分放入不同topic,订单相关操作消息放入订单topic,用户相关操作消息放入用户topic,对于大型网站来说,后端数据都是海量的,订单消息很可能是非常巨量的,比如有几百个G甚至达到TB级别,如果把这么多数据都放在一台机器上可定会有容量限制问题,那么就可以在topic内部划分多个partition来分片存储数据,不同的partition可以位于不同的机器上,每台机器上都运行一个Kafka的进程Broker
2.2 kafka消息存储在哪里?
生产者向kafka的topic发送消息,消息都存储在topic下的分区partition中。可以配置server.properties中的log.dir属性来决定消息的存储位置!
进入log.dir对应的目录,可以看到kafka的消息存储目录
其中,test-0、test-1代表当前test1主题下的两个分区,随便进入一个,即可看到消息日志文件。消息日志文件主要存放在分区文件夹里的以log结尾的日志文件里,如下是test1主题对应的分区0的消息日志:

kafka消息的分段存储
Kafka 一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名(例如:00000000000000000000.log),消息在分区内是分段(segment)存储,每个段的消息都存储在不一样的log文件里,这种特性方便old segment file快速被删除,kafka规定了一个段位的 log 文件最大为 1G,做这个限制目的是为了方便把 log 文件加载到内存去操作:
# 部分消息的offset索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的offset到index文件,
# 如果要定位消息的offset会先在这个文件里快速定位,再去log文件里找具体消息
00000000000000000000.index
# 消息存储文件,主要存offset和消息体
00000000000000000000.log
# 消息的发送时间索引文件,kafka每次往分区发4K(可配置)消息就会记录一条当前消息的发送时间戳与对应的offset到timeindex文件,
# 如果需要按照时间来定位消息的offset,会先在这个文件里查找
00000000000000000000.timeindex
# 分段存储-1
00000000000005367851.index
00000000000005367851.log
00000000000005367851.timeindex
# 分段存储-2
00000000000009936472.index
00000000000009936472.log
00000000000009936472.timeindex
这个 9936472 之类的数字,就是代表了这个日志段文件里包含的起始 Offset,也就说明这个分区里至少都写入了接近 1000 万条数据了。Kafka Broker 可以通过参数log.segment.bytes设置日志段的大小,最大就是 1GB 。一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做 log rolling,正在被写入的那个日志段文件,叫做 active log segment。
2.3 分区副本
分区副本是kafka集群中的一个概念,kafka集群更像是对partition分区的集群。在kafka集群架构中,可以对某一个topic的partition分区设置几个副本,使partition分区中的消息和消息副本落在不同的集群节点上,增加系统的容灾能力。
例如:创建一个名为my‐replicated‐topic的toipc,并设置分区数为2个,副本数为3个。
bin/kafka‐topics.sh ‐‐create ‐‐zookeeper 192.168.65.60:2181 ‐‐replication‐factor 3 ‐‐partitions 2 ‐‐topic my‐replica ted‐topic
查看my‐replicated‐topic主题的情况如下
bin/kafka‐topics.sh ‐‐describe ‐‐zookeeper 192.168.65.60:2181 ‐‐topic my‐replicated‐topic
![]()
以下是输出内容的解释,第一行是所有分区的概要信息,之后的每一行表示每一个partition的信息。
- leader节点负责给定partition的所有读写请求,同一个主题不同分区leader副本一般不一样(为了容灾)
- replicas表示某个partition在哪几个broker上存在备份。不管这个几点是不是”leader“,甚至这个节点挂了,也会列出。
- isr 是replicas的一个子集,它只列出当前还存活着的,并且已同步备份了该partition的节点。
可以看到my‐replicted‐topic主题的两个分区,每个分区数据都有两个副本,分别落在三台kafka集群节点上。leader节点负责所有的读写请求,其他副本节点负责容灾备份。
分区副本的容错性
如果leader节点挂掉,其他副本节点会站出来成为leader节点。为了测试分区副本的容错性,选择杀掉Leader节点1,再次查看my‐replicated‐topic主题情况如下:
![]()
可以看到,分区0的leader节点已经变成了broker 0。要注意的是,在Isr中,已经没有了1号节点。leader的选举也是从ISR(in-sync replica)中进行的。 此时对消息的消费依然正常,说明容错性得到了保障!集群中某个主题分区的leader信息可以在zookeeper的 /brokers/topics/topic…目录下找到,正因为kafka将很多集群关键信息记录在zookeeper里,保证自己的无状态,从而在水平扩容时非常方便。
2.4 消费组和偏移量
消费者组记录着Topic主题中的某个Partition分区的偏移量,下次消费组中的消费者直接从偏移量处消费
①:查看消费组
# 查看当前节点的消费组
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --list
可以看到我们之前已经创建的两个消费者组
![]()
②:查看testGroup消费组的消费偏移量
bin/kafka-consumer-groups.sh --bootstrap-server 192.168.65.60:9092 --describe --group testGroup
可以看到testGroup消费者组的偏移量为13,代表消费到第13条消息
![]()
偏移量参数详情:
Topic:主题topic,逻辑概念,消息真实存在Partition分区中!
Partition:topic中的分区
current-offset:当前消费组的已消费偏移量,每消费一个消息偏移量增加1
log-end-offset:主题对应分区消息的结束偏移量(HW)
lag:当前消费组未消费的消息数
③:停掉testGroup消费组,并生产两条消息到topic中的默认Partition分区0
④:再次使用命令查看testGroup消费组的消费偏移量
![]()
此时发现,已消费偏移量为13,一共15条消息,2条待消费
⑤:再次启动testGroup消费组中的消费者
![]()
发现已消费的偏移量已更新到15,新增的两条消息已被消费。如果此时启动testGroup-2消费组中的消费者,这两条消息也会被testGroup-2消费组中的消费者消费!
问题一:增加消费者对kafka的性能是否会有影响?
答:不会,因为每个consumer是基于自己在commit log中的消费偏移量(offset)来进行工作的。在kafka中,消费偏移量offset由consumer自己来维护,这也是与传统消息中间件MQ的一个区别,这意味kafka中的consumer对集群的影响是非常小的,添加一个或者减少一个consumer,对于集群或者其他consumer 来说,都是没有影响的,因为每个consumer维护各自的消费offset。一般情况下我们按照顺序逐条消费commit log中的消息,当然我可以通过指定offset来重复消费某些消息, 或者跳过某些消息。
2.5 单播消费和多播消费
生产者生产者的消息其实是发往Topic主题中的Partition(分区)中的
# 创建一个名字为“test”的Topic,这个topic只有一个partition,并且备份因子也设置为1
bin/kafka-topics.sh --create --zookeeper 192.168.65.60:2181 --replication-factor 1 --partitions 1 --topic test
# 查看kafka中目前存在的topic
bin/kafka-topics.sh --list --zookeeper 192.168.65.60:2181
# 删除主题
bin/kafka-topics.sh --delete --topic test --zookeeper 192.168.65.60:2181
# 发送消息 到topic主题test的默认分区中
bin/kafka-console-producer.sh --broker-list 192.168.65.60:9092 --topic test
# 消费消息 消费topic主题test默认分区中的消息
# 如果想要消费之前的消息可以通过--from-beginning参数指定
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --topic test
两个kafka构成集群,某个主题下有四个分区,分散到两台集群节点。下图是不同的消费者组对不同分区的消费情况。C1和C2对于P0分区来说属于单播消费,C1和C3对于P0来说属于多播消费!
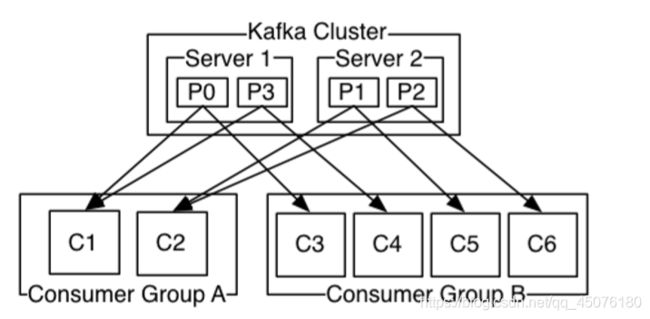
- 单播消费
说明:让所有消费者处在同一个消费组里,消费组中的多个消费者只有一个可以消费到Partition分区中的消息。类似queue模式,一条消息只能被某一个消费者消费。分别在两个客户端执行如下消费命令,两个消费者都处于testGroup消费者组中,然后往主题里发送消息,结果只有一个客户端能收到消息
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --consumer-property group.id=testGroup --topic test
- 多播消费
说明:针对Kafka同一条消息只能被同一个消费组下的某一个消费者消费的特性,要实现多播只要保证这些消费者属于不同的消费组即可。再增加一个消费者,这个消费者处于 testGroup-2 消费者组中,结果是testGroup 和 testGroup-2 消费者组中各有一个消费者成功消费到消息!多播消费其实是一条消息能被多个消费者消费的模式,类似publish-subscribe模式
bin/kafka-console-consumer.sh --bootstrap-server 192.168.65.60:9092 --consumer-property group.id=testGroup-2 --topic test
3. kafka的顺序消费
对于kafka来说,从整体架构上来讲,一般上是不支持顺序消费的。生产者可以选择不同的partition分区发送消息,消费者组可以消费不同partition分区的数据,这样就无法保证顺序性。如果必须要有一定的顺序,可以通过以下两种方式来解决!以订单消息为例
- 订单topic下只设置一个partition分区,在创建一个消费者组,里边一个消费者去消费订单的partition分区,这样只有一个消费者消费一个分区,可以保证顺序性。缺点是效率低下,不符合kafka高效率的初衷。
- 脱离kafka来实现消息顺序。因为kafka不怎么支持顺序消费,我们可以脱离kafka,在外部日志中根据订单的下单时间来做顺序,这也是常用的方式!