分享人 | 叶聪(腾讯云 AI 和大数据中心高级研发工程师)
整 理 | Leo
出 品 | 人工智能头条(公众号ID:AI_Thinker)
刚刚过去的五四青年节,你的朋友圈是否被这样的民国风照片刷屏?用户只需要在 H5 页面上提交自己的头像照片,就可以自动生成诸如此类风格的人脸比对照片,简洁操作的背后离不开计算机视觉技术和腾讯云技术的支持。
那么这个爆款应用的背后用到了哪些计算机视觉技术?掌握这些技术需要通过哪些学习路径?
5 月 17 日,人工智能头条邀请到腾讯云 AI 和大数据中心高级研发工程师叶聪,他以直播公开课的形式为大家解答了这些问题。
(课程回放地址:https://edu.csdn.net/course/detail/8190)
人工智能头条将主要内容整理如下:

▌一、朋友圈爆款活动介绍
大家经常在朋友圈看到一些很有趣的跟图像相关的小游戏,包括以前的军装照以及今年五四青年节的活动。这个活动非常有意思,大家可以选择一张自己觉得拍的最美的照片,然后上传到 H5 的应用里面,我们就会帮你匹配一张近现代比较优秀的青年照片。那张照片是老照片,而大家上传的是新照片,这就产生了一些比较有意思的对比,这个活动今年也是得到了强烈的反响,大家非常喜欢。
所有的这些算法构建完以后,我们把它上传到了腾讯云的 AI 大平台上去。因为我们参照了去年军装照的流量,所以这次活动我们预估了 5 万 QPS,这其实是很高的一个要求。该活动 5 月 4 日上线,截止 5 月 5 日下线,在短短两天内,在线 H5 页面的 PV 达到了 252.6 万,UV 111.3 万,服务调用量 420 万,还是比较惊人的。
▌二、计算机视觉基础知识

首先计算机视觉是什么?计算机视觉研究如何让计算机从图像和视频中获取高级和抽象信息。从工程角度来讲,计算机视觉可以使模仿视觉任务自动化。
一般来说计算机视觉包含以下分支:
物体识别
对象检测
语义分割
运动和跟踪
三维重建
视觉问答
动作识别
这边额外提一下语义分割,为什么要提这个呢?因为语义分割这个词也会在包括 NLP、语音等领域里出现,但是实际上在图像里面分割的意思跟在语音和 NLP 里面都很不一样,它其实是对图像中间的不同的元素进行像素级别的分割。比如最右下角这张图片,我们可以看到行人、车辆、路,还有后面的树,他们都用不同的颜色标注,其实每一种颜色就代表了一种语义。左边和中间的两幅图,可能我不用介绍,大家也应该能猜到了,一个是人脸识别,一个是无人驾驶,都是现在使用非常广泛和热门的应用。

如何让机器可以像人一样读懂图片?人在处理图像的时候,我们是按照生物学的角度,从图像到视网膜然后再存储到大脑。但机器没有这套机制,那机器如何把图片装载到内存里面?这个就牵扯到一个叫 RGB-alpha 的格式。
顾名思义,就是红绿蓝三色,然后,alpha 是什么?如果大家在早期的时候玩过一些电脑硬件,你可能会发现,最早期的显卡是 24 位彩色,后来出现一个叫 32 位真彩色,都是彩色的,有什么不同吗?因为在计算机领域,我们用 8 位的二进制去表示一种颜色,红绿蓝加在一起就是 24 位,基本上我们把所有颜色都表示出来了。
为什么还出现 alpha?alpha 是用来表示一个像素点是不是透明的,但并不是说 alpha 是 1 的时候它就是透明,是 0 的时候就不透明。只是说阿尔法通道相当于也是一个矩阵,这个矩阵会跟 RGB 的其他的矩阵进行一种运算,如果 alpha 的这个点上是 1,它就不会影响 RGB 矩阵上那个点的数值,它就是以前原来的颜色,如果是 0,这个点就变成透明的。这也是我们怎么用 RGB 加 alpha 通道去描述世界上所有的图片的原理。
比如右上角,这张图片是黑白图,中间是彩色图,下面一张是有些透明效果,右下角基本上没有像素点,这就是一个很好的例子,去理解 RGB 是怎么一回事。
除了 RGB-alpha 这种表达方式,我们还有很多不同的颜色表达方式。包括如果我们搞印刷的话,大家可能接触到另外一种色系,叫 CMYK,这个也是一种颜色的表示方式。这边还会有一些其他类型的图片,包括红外线图片,X 光拍摄的图片,红外热成像图,还有显微镜拍摄的细胞图,这些加在一起都是我们计算机可以处理的图像的范围,不仅仅是我们之前看到,用手机、摄像机拍摄的图片。

我们在计算机视觉中经常会提到 stages,为什么叫 stages?
这边我们看到,有 Low level,Mid level,High level,这里澄清一下,并不是说 Low Level 这些应用就比较低级,High level 就比较高端,这个描述的维度其实是从我们看问题的视野上来说的,Low level 代表我们离这个问题非常近,High level 代表比较远。
举一个简单例子,比如 Low Level 上面我们可以做图像的降噪、优化、压缩、包括边缘检测,不管是哪一条,我们都是可以想象一下,我们是离这个图片非常近的去看这个细节。High level 是什么?包括情景理解、人脸识别、自动驾驶,它基本上是从一个比较远的角度来看这个大局。
所以其实大家可以这么想,在解决问题的时候,我们要离图片的视觉大概保持多远的距离,High 代表比较远,Low 代表比较近,并不是说 High 比 Low 要难,或者说要高端。
Mid level 介于 High 跟 Low 之间的,包括分类、分割、对象检测,后面还有情景分割,这边的情境分割跟分割还不太一样,应该说是更深度的分割问题,后面我会详细解释。

这边有一些例子是帮大家去理解 Low level Processing。比如左上那张是我们拍 X 光会看到的图,上面那张图是原始的 X 光的图片,大家可以看到,非常的不清晰,很难去理解到里面的骨骼,血管在什么位置。但通过 Low Level Processing 的降噪和优化,就能非常清晰的看到这个病人的所有的骨骼及内脏的位置。
中间这个是一个 PCB 板,一些工业领域为了检测 PCB 板就会拍摄照片,做图像处理,并用这种方式去找到板上的一些问题,然后去修复它。有的时候也为了质量品控,看到中间这张的 PCB 板原始的图片上面充满了噪音,经过优化、降噪以后就得到一张很清晰的照片。

这个是 Mid level Processing,目前这块的技术比较成熟。这块的应用包括分类、分割、目标检测,也包括情景检测、情景分割,甚至还有意图检测,就是通过看图片里面的一些物体和他们目前在做的一些行为来判断他们的意图。
底下有几张小猫咪和小狗的图,从左到右是一个进阶的方向。首先最容易想到的一个应用,就是怎么能用机器学习的方法读懂一张图片里面的内容,那这个方法如何去实现它呢?其实就是用了一个分类,因为左边那张图片如果给了机器,分类算法会告诉你里面有一只猫,但是仅此而已。
那如果我们想知道,这里面有只猫,但这只猫在哪里呢?这个问题,我们就需要在这个基础上加上定位,也就是第二张图片,那我们就可以定位到,原来这里是猫咪所在的范围,只是在这个方框范围内,并没有精确到像素级别。
再进一步,如果这张图片里面不仅仅有猫,可能会有很多其他的东西,我希望把所有的东西都标识出来,应该怎么办?这个任务叫做叫对象检测,就是把图片里面所有的这些对象全部标注检测出来。
再进一步,我不但想把里面的对象全部标注出来,我还要精确的知道,它们在图像的什么位置,这种情况下我可能想把它们剥离出来,把背景去掉。一般情况下,这种被我们框出来的对象叫做前景,其他的这些部分叫做后景。我们如果想把前景弄出来,那我们就需要这种对象分割的技术,从左到右,我们就完成了分类、定位、检测、对象分割的全部流程,从头到尾也是一个慢慢晋升的过程。因为定位是需要分类的基础的,对象检测是需要有分类基础的,情景分割也需要有检测的基础,它是一个由浅入深的一个过程。
最右边就是一个情景分割的例子,之前我也简单介绍过,现在的技术已经可以精确的把我们这张图片上的几乎所有的元素很精确的给分出来,包括什么是人、车、路、景色、植物、大楼等全部都能分出来,我们的技术目前在 Mid level Processing 这块已经很成熟了。

接下来简单介绍一下 High level Processing,也是目前非常热门和有前景,但是应该说远远还未达到成熟的技术。可能目前,大家做最好的 High level Processing 就是人脸检测。
左下角那张是无人驾驶,也可以叫做高智能的辅助驾驶,不同的车厂,不同的定义,基本上就是对象检测的一个复杂应用,包括检测到路上的所有情况,包括不同的地上标识,周围的建筑,还有在你前面的所有车辆,甚至行人,各种信息,还包括跟他们的距离,它是一个相对来说多维度的,是个复杂的对象检测的应用。
中间的是两个小朋友在打网球,这张图片也是两个人物,跟之前Mid level Processing有什么区别吗?其实从右边那个对象树上,我们就能判断,它是对这个图片理解的深度有了非常本质的区别。前一个那个例子,我们知道图片上有猫有狗,仅此而已。而这张图片上,我们除了判断到,图片上有两个孩子以外,还对他们的各种穿着,都进行了精确的分割和定义,包括他们手上的这些持有的球拍,我们都有个非常详细的描述,所以High level图像的理解并不是简单的说有哪些东西,而是他们之间的联系、细节。High level本身不仅能识别我们的图上有什么东西,它还能识别,应该做什么,他们的关系是什么。
右边那张图片是一个医学的应用,一个心血管的虚拟图。它是英国皇家医学院跟某个大学合作的一个项目,我们通过计算机视觉去模拟一个病人的心血管,帮助医生做判断,是否要做手术,应该怎么去做手术方案,这个应该是计算机视觉在医学上的很好的一个应用的例子。

这里有一些比较常见的计算机视觉的应用,平时我们也会用到,包括多重的人脸识别,现在有些比较流行的照片应用,不知道大家平时会不会用到,包括比如像 Google photos,基本上传一张照片上去,它就会对同样的照片同样的人物进行归类,这个也是目前非常常见的一个应用。
中间那个叫 OCR,就是对文本进行扫描和识别,这个技术目前已经比较成熟了。照片上这张是比较老的技术,当时我记得有公司做这个应用,有个扫描笔,扫描一下就变成文字,现在的话,基本上已经不需要这么近的去扫描了,大家只要拍一张照片,如果这张照片是比较清晰的,经过一两秒钟,一般我们现在算法就可以直接把它转换成文字,而且准确率相当高,所以图片上的这种 OCR 是一个过时的技术。
右下角是车牌检测,开车的时候不小心压到线了,闯红灯了,收到一张罚单,这个怎么做到呢?也是计算机视觉的功劳,它们可以很容易的就去识别这个照片里的车牌,甚至车牌有一定的污损,经过计算机视觉的增强都是可以把它给可以优化回来的,所以这个技术也是比较实用的。

下面聊几个比较有挑战性的计算机视觉的任务。首先是目标跟踪,目标跟踪就是我们在连续的图片或者视频流里面,想要去追踪某一个指定的对象,这个听起来对人来说是一个非常容易的任务,大家只要目不转睛盯着一个东西,没有人能逃脱我们的视野。
实际上对机器来说,这是一个很有挑战性的任务,为什么呢?因为机器在追踪对象的时候,大部分会使用最原始的一些方法,采取一些对目标图片进行形变的匹配,就是比较早期的计算机识别的方法,而这个方法在实际应用中间是非常难以实现的,为什么?因为需要跟踪的对象,它由于角度、光照、遮挡的原因包括运动的时候,它会变得模糊,还有相似背景的干扰,所以我们很难利用模板匹配这种方法去追踪这个对象。一个人他面对你、背对你、侧对你,可能景象完全不一样,这种情况下,同样一个模板是无法匹配的,所以说,很有潜力但也很有挑战性,因为目前对象追踪的算法完全没有达到人脸识别的准确率,还有很多的人在不断的努力去寻找新的方法去提升。
右边也是一个例子,就是简单的一个对我们头部的追踪,也是非常有挑战性的,因为我们头可以旋转,尺度也可能发生变化,用手去遮挡,这都给匹配造成很大的难度。

后面还有一些比较有挑战性的计算机视觉任务,我们归类把它们叫做多模态问题,其中包括 VQA,这是什么意思?这个就是说给定一张图片,我们可以任意的去问它一些问题,一般是比较直接的一些问题,Who、Where、How,类似这些问题,或者这个多模态的模型,要能够根据图片的真实信息去回答我们的问题。
举个例子,比如底下图片中间有两张是小朋友的,计算机视觉看到这张图片的时候它要把其中所有的对象全部分割出来,要了解每个对象是什么,知道它们其中的联系。比如左边的小朋友在喝奶,如果把他的奶瓶分出来以后,它必须要知道这个小朋友在喝奶,这个关系也是很重要的。
屏幕上的问题是“Where is the child sitting?”,这个问题的复杂度就比单纯的只是解析图像要复杂的多。他需要把里面所有信息的全部解析出来,并且能准确的去关联他们的关系,同时这个模型还要能够理解我们问这个问题到底是什么个用意,他要知道问的是位置,而且这个对象是这个小孩,所以这个是包含着计算机视觉加上自然语言识别,两种这种技术的相结合,所以才叫多模态问题,模态指的是像语音,文字,图像,语音,这种几种模态放在一起就叫多模态问题。
右边一个例子是 Caption Generation,现在非常流行的研究的领域,给定一张图片,然后对图片里面的东西进行描述,这个还有一些更有趣的应用,待会我会详细介绍一下。
▌三、曾经的图像处理——传统方法

接下来我们聊一聊,过去了很多年,大家积累的传统的计算机视觉的图像处理的方法。
首先提到几个滤波器,包括空间滤波器,傅里叶、小波滤波器等等,这些都是我们经常对图像进行初期的处理使用的滤波器。一般情况下,经过滤波以后,我们会对图像进行 Feature Design,就是我们要从图片中提取一些我们觉得比较重要的,可以用来做进一步的处理的一些参照的一个信息,然后利用信息进行分类,或者分割等等,这些应用,其中一些比较经典的一些方法,包括 SIFT、Symmetry、HOG,还有一些就是我们分类会经常用到的一个算法,包括 SVM,AdaBoost,还有 Bayesian 等等。
进一步的分割还有对象检测还有一些经典算法,包括 Water-shed、Level-set、Active shape 等。

首先我们做 Feature Design,提取一个图片中间对象的特点,最简单能想到的方法,就是把这个对象的边缘给分离出来,Edge Detection 也确实是很早期的图像信息提取方法。
举个例子,硬币包括上面的图案,都会经过简单的 Edge Detection 全部提取出来,但实际上Edge Detection 在一些比较复杂的情况上面,包括背景复杂的情况下,它是会损失很多信息的,很多情况下我们看不到边缘。

这样情况下大家还想出另外一个方法叫 Local Symmetry,这种方法是看对象重心点,利用重心点去代表着这个图像的一些特征。

这个叫 Haar Feature,相当于结合了前面边缘特征,还有一些其他的一些特征的信息。Haar Feature 一般分为三类
边缘特征
线性特征
中心对角线特征
通过处理,把图片中所有的边缘信息提取出来以后,就会对图片整理获得一个特征模板,这个特征模板由白色和黑色两种矩形组成,一般情况下定义模板的特征值为白色的矩形像素和减去黑色像素矩形像素和。Haar Feature 其实是反映了图像的一个灰度变化的情况,所以脸部的一些特征,就可以用矩形的模板来进行表述,比如眼睛要比脸颊颜色要深,鼻梁两侧比鼻梁颜色要深,嘴巴比周围颜色深等等。我们利用这些矩形就对图像的一些细节进行了提取。

SIFT 尺度不变特征变换,当对象有角度、特征位置的变化时,我们如何去持续的能够知道它们是同样的一个东西,这个就要利用到 SIFT。SIFT 是一种局部检测的特征算法,这个算法是通过求图片中的一些特征点,对图像进行匹配,这是非常老的一个算法,大概在 2000 年时候就提出来了,目前已经是一个常用的非深度学习的一个图像的一种匹配的算法。

另外一个比较流行的方法叫 HOG 方向梯度直方图,比如像这张图片上显示,在图像中间,局部目标的表象和形状能够对灰度的梯度、还有边缘方向的密度有很好的表示。比如像这张图像,人身上的梯度就是向着上下方向。而对于背景,由于背景光的原因,如果我们做灰度的分析,会发现它的梯度是偏水平方向的,利用这种方式我们就很容易的可以把背景跟前景进行分割。另外如果很多小框里的梯度方向几乎一致的话,我们就可以认为它是一个对象,这个方法是很好的可以塑造一个分割的效果。实际上很早期的目标检测就是 Feature Design,所以说检测是基于分类的,也是这个意思。现在深度学习引入以后,很多理论也发生了一些变化,待会详细介绍一下。

这个也是一个非常经典的分割方法,叫分水岭算法,就是把这个图像想象成一个地理上的地形图,然后我们对其中的各个山谷非常无差别的统一往里面放水,总会有一些山谷先被填满漫出来,那我们为了阻隔他们水流的流动就要建一些这种堤坝,这也是分水岭算法的名字的由来。利用这种方式,我们建坝的地方就是很好的一个图像的分割的这种界线,大家可以想象一下,把左边这张图和右边的边界联系起来,就会理解到这个算法是个非常巧妙的事。
常规的分水岭算法还是有些缺点的,比如由于图像上的一个噪音,经常会造成局部的一些过度分割,也会有一些图像中的部分元素因为颜色相近不会被分割出来,所以经常会出现一些误判,这也是分水岭算法的一些局限性。

ASM,中文名叫可变模板匹配,或者叫主观形状模型。这个翻译听起来都怪怪的,其实很好理解,它是对人脸上的一些特征进行提取,采用的方式是在人脸上寻找一些边角的地方进行绘点,一般绘制大概 68 个关键特征点。然后利用这些特征点,我们去抽取一个原始的模型出来。
原始的模型抽出来之后,是不是能直接用呢?没有那么简单,因为人脸有可能会由于角度变化会发生一些形变,如果只是单纯的对比这 68 个点,是不是在新的图片上面还有同样的位置,大部分情况都是 No。这时我们要对这些特征点进行一些向量的构建,我们把那 68 个点提取出来,把它向量化,同时我们对我们需要比对的点,比对的那个脸部也进行同样的工作,也把它向量化。然后我们对原始图片上的这种向量点和新图片上的点进行简单化匹配,可以通过旋转缩放水平位移,还有垂直位移这种方式,寻找到一个等式,让它们尽量的相等,最后优化的不能再优化的时候,就去比较阈值的大小,如果它小于某个阈值,这样人脸就能匹配上,这个想法还是比较有意思的。
另外,在这里由于 68 个点可能比较多,很久以前我们的这种计算机的性能可能没有那么好,也没有 GPU,我们如果写的时候为了提高匹配的速度,就要想个办法去降低需要比对特征点的量,这个时候引出一个比较著名的算法叫主成分分析,利用这个 PC,我们会做降维,比如一些没有太大意义的点可以去掉,减少数据量,减少运算量,提高效果,当然这并不是必须的,它只是一个提升 ASM 实际效能的加分办法。
▌四、图像处理的爆发——深度学习方法

然后接下来我们就聊一聊现在非常热门,未来也会更加热门的图形学的深度学习方法。下面有两个深度学习的网络,所谓的深度学习实际就是深度神经网络,叫深度神经网络大家更容易理解。左边那个是一个两层的神经网络,这里要解释一下,我们一般说神经网络的层数是不算输入层的,两层就是包括一个输入层,一个隐层,和一个输出层。所以有的时候,如果我们提到了一个单层网络,其实就是只有输入层和输出层,大家知道这种情况下面的浅度神经网络是什么?它就是我们传统的机器学习里非常经典的逻辑回归和支持向量机。
这时候你会发现,深度学习并没有那么遥不可及,它其实跟我们传统的一些方法是有联系的。它只是多重的一种包装,或者组合强化,然后反复利用,最后打包成了一个新的机器学习的方法。
图上有两个神经网络,其中有些共同点,首先他们都有一个输入层,一个输出层。这个就是所有的神经网络必须的,中间的隐层才是真正的不同的地方,不同的网络为了解决不同的问题,它就会有不同的隐层。

这个是对多重人脸识别设计的一个深度神经网络,我们可以看到输入层中间会做一些预处理,包括把图片转换成一些对比度图。第一个隐层是 Face Features,从人脸上提取关键的特征值。第二个隐层就是开始做特征值匹配,最后的输出层就是对结果进行输出,一般就是分类。

除了刚才我们看到的典型神经网络,还会有其他各式各样的网络?有三角形,也有矩形的,矩形中间还有菱形的。神经网络出现了以后,改变了大家的一些工作方式。之前,大部分机器学习的科学家是去选择模型,然后选择模型优化的方式。到了深度学习领域,大家考虑的是我们使用什么网络来实现我们的目的,实际上还是区别比较大的。
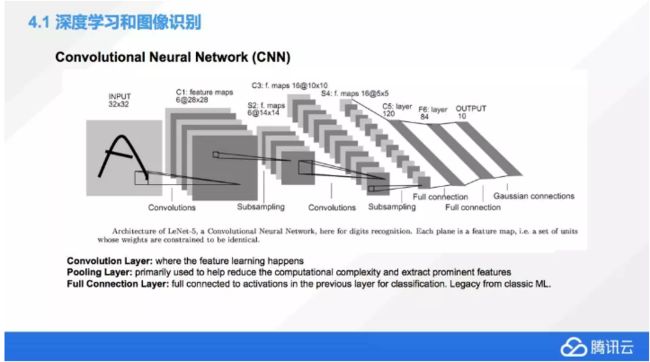
CNN,也就是卷积神经网络,它是目前应用最广泛的图像识别网络,了解 CNN 会对了解其他网络有很大的帮助,所以把这个作为例子。
这个例子中我们做了一个手写识别,这里包含输入层、输出层,还有卷积层、池化层。一般情况下,不仅仅做一次卷积,我们还会多次的做卷积,池化然后再卷积,利用这种方式去多次的降维,池化层其实在这个卷积神经网络中起一个作用,就是降低我们数据的维度。
最后会有一个叫全连接层,它是个历史遗留物,现在大家其实慢慢的也在减少使用全连接层,全连接层一般情况下,它的作用就是对前面的各种池化卷积最后的结果进行一个归类。而实际上现在深度学习比较讲究端对端学习,又讲究效率比较高,这种情况下面,有的时候全连接层的意义就不是那么大,因为这个分类有可能在卷积的时候就把它做了,其实这个里面还是有很多的可以提升的地方。

再举一个例子,目前比较流行的做图像分割的还有很多基于 CNN 的新网络。比如在 CNN 基础上大家又加入了一个叫 Region Proposal Network 的东西,利用它们可以去优化传统 CNN 中间的一些数据的走向。Faster-RCNN 不是一蹴而就的,它是从RCNN中借鉴了 SPPNET 的一些特性,然后发明了 Fast-RCNN,又在 Fast-RCNN 的基础上进一步的优化变成了 Faster-RCNN。
大家能看到,神经网络也不是一成不变的,它也是不断在进化的,而我们最开始想到用神经网络去解决图像问题的时候,是由于什么原因?是由于当时我们在尝试去用 CNN 去做图像检测的时候发现了很大的困难,效果不好,这时就有非常厉害的科学家想了,我们可不可以把一个非常典型的检测问题变为分类问题,因为 CNN 用来解决分类问题是非常有效的,所以就会出现很多的这样的转换应用。我上面写的每一个网络都是一篇非常伟大的论文,所以大家如果有兴趣,我课后可以分享一下。
目前除了 Faster-RCNN,还有一个应用效果非常好的一个网络结构,叫 YOLO,它也是在 Faster-RCNN 上面,已经不仅仅是进行了优化,而是改变了它的思维模式。最开始,我们觉得检测如果转化成分类会效果更好,后来发明 Faster-RCNN 的这个科学家觉得,有的时候可能还是用回归的方式去解决目标检测的问题效果会更好,他最后就搬出了 YOLO 这种新的神经网络框架,从而重新返回到了用回归的方式去解决目标检测问题的方式上来。
有的时候也并不是说解决同样一个问题是有不同方法,也并不是说在一条路上一直走到黑是最好,换个思维方式,在硬件和软件条件达到一个新的层次的时候,有些已经用不了的技术现在就能用了,深度学习就是这么来的。

我们再聊一聊深度学习图像应用的案例,比如说我们提到的这个五四青年节活动,它是怎么样去设计的。首先呢,我们会有一些图片的训练数据,然后在进入模型之前,我们会对数据进行向量化,通过数据向量化,我们就可以得到一个模型,然后得到一个分类,和一个 score,这边的 score 只是模型对这种结果一个相对的分析,一般我们会选择 score 最高的一个分类,然后前端会从这个分类中间选择图片,生成H5的这个结果,大家就可以看到跟哪位历史上的有名的青年相似了。

第二个也是多模态的例子,根据一张图片去讲一个浪漫的故事,当时我们有这个想法的原因是,我们知道现在已经有看图出文字描述的技术,那我们能不能进一步的,让图片可以讲故事。这样的话,这个应用就可以帮助家里有小宝宝的人群。除了图像识别以外,我们还进行了一些意图的分析。

在另一方面,我们会使用一个浪漫小说的数据库,对另外一个模型进行训练。最后,我们根据这个图片里面这些关健词和它的意图去匹配浪漫小说中间的文段,把有关的文段全部拿出来,拿出来这些文段有的是不成文章的,所以要进行下一轮的匹配,把这些文段中间的关键词再去进一步的在小说库里面去匹配,成段的文字,这就实现了一个 storyteller。
这个项目除了最先我们对图像里面的对象识别过程使用的是监督学习,其他的都是非监督学习。这个系统是可以自然的去套用到很多不同的地方,只要换个不同的文章数据库,它就可以讲不同的故事。一些例子就是根据不同的图片,比如左上角这张是我觉得分数最高的:有一个女性在沙滩上面走路,经过我们的模型就输出了一个非常浪漫的故事,基本上符合这个情景。
▌五、解析云端AI能力支撑

我们聊了很多计算机视觉图像处理的一些算法,我们是不是下一步还要考虑怎么样把这个算法落地,变成一个有趣的产品或者活动呢?如果是这样,我们需要一些什么样的能力呢?
我们需要一个这样的架构,比如像这次军装照活动,我们会有非常高的访问量,同时呢,它会有遍布全国的用户,整体上来说,我们首先要保证这个系统能稳定和弹性伸缩,然而由于所有的机器都是有成本的,这里我们就要考虑到一个平衡,如何很好的高效承载服务的同时,又要保证这个系统能够足够的稳定?
在这个活动背后,我们使用了很多的腾讯云的一些服务,包括静态加速、负载均衡、云服务器、对象存储,还有一些 GPU 计算。后来发现 CPU 的性能是能够满足我们的需求的,所以之后我们 GPU 就没有上,因为 CPU 的承载还是比较高的,但实际上这一套流程是完全都是可以这么运行的。一般情况下,我们会先用 SCD,里面的 CDM 去做一个静态的缓存,到离用户最近的节点,这样大家在访问 H5 页面的时候就不会等着图片慢慢加载,因为它会在离你家最近的某一个数据中心里一次性的把它给到手机的客户端上。
然后就到负载均衡器,就是把流量负载到背后海量的虚拟机上面。在不同的区域,比如北京会有,成都会有多个 ELB……这个 ELB 会挂载着很多个不同的 CVM,就是虚拟机,所有这些大家上传的照片,匹配运算都是在每个 CVM 上面去产生结果的,然后有些过程的信息,我们也会存在 COS 上,这个 COS 存储是没有大小限制的,这样多种需求都可以得到满足。
这套机制目前证明是非常有效的,我们将来的很多的活动会继续在架构上面做一些优化。如果你有一个很好的想法或模型要去实现,也是可以尝试使用一下云服务,这样是最经济和高效的。

腾讯云人工智能产品方案矩阵
▌六、技能进阶建议
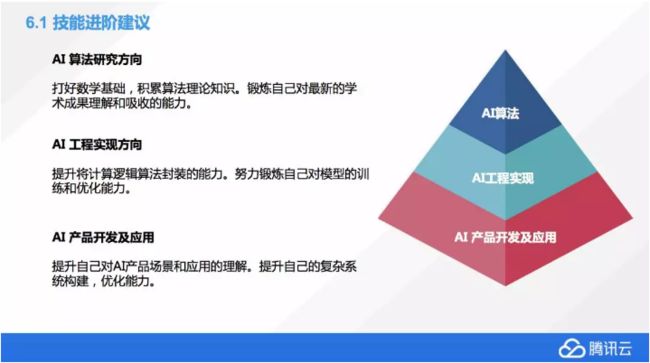
最后我们聊一聊技能进阶的一些建议,如果我们在 AI 这个方向上想有所进步的话,我们应该怎么做?右边有个金字塔,它表示我们要完成一个 AI 的产品,我们需要的人力的数量,AI 算法这块可能是很核心的,但它需要的人数相对来说比较少一点。共同实现是中间的,你需要多一些的底层开发。由于同样一个算法模型,你可能会海量的应用,产品开发应用这个需要的人力的数量是最大的。
算法研究方面我们要做什么?首先是要打好比较强的数学基础。因为机器学习中间大量的用到了比大学高等数学更复杂的数学知识,这些知识需要大家早做研究打好基础,这就需要读很多论文。同时还要锻炼自己对新的学术成果的理解和吸收能力,像刚才提到了一个神经网络图像的分类问题,实际上,短短的十年时间实现了那么多不同网络的进化,每一个新的网络提出了,甚至还没有发表,只是在预发表库里面,大家就要很快的去吸收理解它,想把它转化成可以运行的模型,这个是要反复锻炼的。
第二块是工程实现方面,如果想从事这方面首先要加强自己逻辑算法封装的能力,尽量锻炼自己对模型的训练和优化能力,这块会需要大家把一个设计好的算法给落实到代码上,不断的去调整优化实现最好的结果,这个过程也是需要反复磨炼的。
最后一个方向是产品应用,这个首先大家要有一定的开发能力,不管是移动开发还是 Web 开发,同时要提升自己 AI 产品场景的理解和应用。实际上很多AI产品跟传统的产品是有很大的理解上的区别,大家可能要更新自己的这种想法,多去看一些 AI 产品目前是怎么做的,有没有好的点子,多去试用体会。同时如果我们想把一个 AI 的模型变成百万级、千万级用户使用的流行产品,我们还需要有系统构建能力和优化能力。

计算机视觉学习资源
—【完】—
公开课预告
课程主题:云从科技:详解跨镜追踪(Reid)技术实现及应用场景
时间:6月7日 20:00-21:00
分享嘉宾:袁余锋
云从科技资深算法研究员,2012年浙江大学硕士毕业,专注于计算机视觉的前沿算法研究及应用落地,由其领导的技术团队最近在Reid研究课题上取得重大突破,刷新了三个数据集的世界纪录。
报名地址:https://edu.csdn.net/huiyiCourse/detail/788
扫描下方二维码,添加小助手微信,备注:公开课,加入课程交流群,课程回放以及分享PPT会发到群里
