如何高效系统学习 MySQL?
DevWeekly收集整理每周优质开发者内容,包括开源项目、工具资源、技术文章等方面,每周五首发于DevWeekly,欢迎大家Star并收藏!
MySQL这么简单还用得着学习?
有不少同学估计都有这种想法,“不就是增删改查一些简单操作吗?”
如果仅从使用者的角度做一些简单的查询和聚合,MySQL的确很简单。
但是,你能从头至尾配置一套生产环境的数据库环境吗?你可以设计出具有优秀扩展性的表模型吗?怎么样才可以实现大数据量的快速查询?
我认为,任何一个领域都有相应的专家,也都有一知半解的人,对于MySQL,虽然很多人觉得非常简单,但是要真正成为这个领域的专家同样有很高的难度。
有点扯远了,本文的目标不是面向高阶数据库专家的,本文旨在引导初学者入门、帮助对MySQL感兴趣的同学了解数据库全局链路。
配置SQL环境
现如今云服务使用越来越官方,很多同学在公司直接接触的都是rds(Relational Database Service),开箱即用,作为使用者不需要关注底层使用的到底是Oracle、Postgresql还是SQL Server,也不用关注运维和数据库安全。
但是,我认为亲自动手配置一套SQL环境会更加容易帮助我们对数据库的理解。
要想配置环境,我们首先需要下载MySQL服务客户端。
我们可以根据自己的系统(MACOSX、Linux、Windows)下载对应的MySQL。
下载完之后,双击并安装该文件。需要设置一个密码,一定要记住这个密码,因为以后需要它来连接到MySQL实例。

创建一个名为my.cnf的文件,并将以下内容放入其中,这需要给本地文件读取SQL数据库的权限。
[client]
port= 3306
[mysqld]
port= 3306
secure_file_priv=''
local-infile=1
打开系统偏好->MySQL,转到配置,选择my.cnf文件,然后点击Apply按钮。
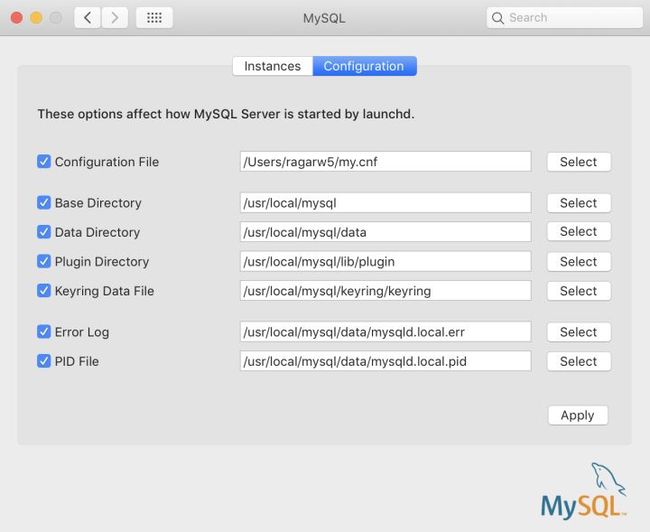
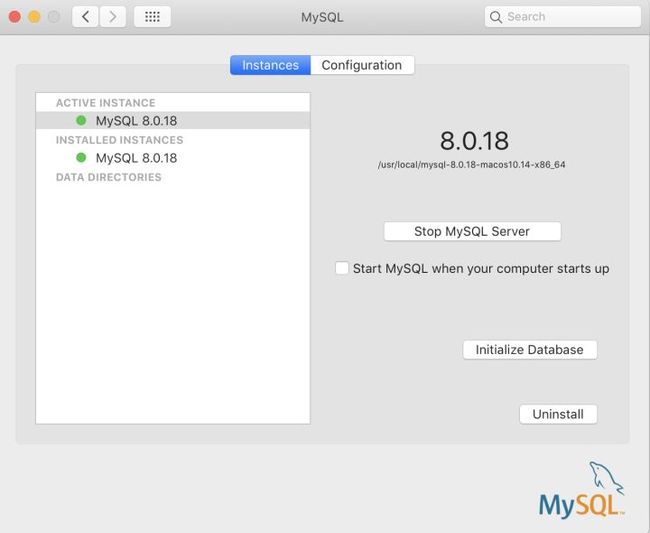
通过点击 在MySQL设置页面,可以 通过点击Start或者Stop来启动或者停止数据库。
如果数据库服务正常运行,接下来就可以下载并安装[MySQL工作台](https://www.zhihu.com/question/MySQL :: Download MySQL Workbench),工作台可以用来编辑和查询数据,并以结构化的方式返回结果。
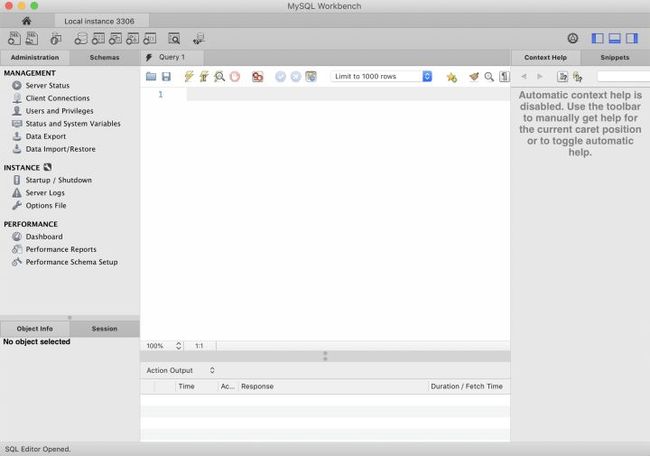
现在打开MySQL工作台,通过它连接到SQL服务,你会看到类似下面的东西:

你可以看到,本地实例连接已经事先为你设置好了。
现在,你只需要点击该连接,并使用我们之前为MySQL服务器设置的密码开始工作。

连接之后,你就会看到是一个编辑界面,在这里你可以输入一些查询语句执行数据的查询。
但是,目前我们还没有建表,也没有数据,所以,首先需要准备一些数据:
手动建表太麻烦了,MySQL官网提供了一些数据样例用于学习,我们可以访问官网,下载Sakila电影数据库,然后解压。
接下来,回到MySQL工作台,依次点击文件>运行SQL脚本>选择位置sakila-db/sakila-schema.sql。
这样,就创建了表结构。
下一步,依次点击文件>运行SQL脚本>选择位置sakila-db/sakila-data.sql。
这样 ,就把数据导入到SQL服务了。
做完这些操作,你会看到侧边栏有一些数据库了:

处理数据
现在,已经配置好环境并有了数据,接下来可以写一些查询。
你可以尝试使用Sakila样本数据库文档来详细了解Sakila数据库的模型,这是设计数据库表时非常重要的环节。
现在,可以看一个基本的SQL语句:
SELECT col1
,SUM(col2) AS col2sum
,AVG(col3) AS col3avg
FROM table_name
WHERE col4 = 'some_value'
GROUP BY col1
ORDER BY col2sum DESC;
在这个查询中,有4个核心要素:。
- SELECT:要查询哪些列?这里我们查询col1,对col2进行SUM聚合,对col3进行AVG聚合。这里还通过使用as关键字给SUM(col2)起了一个别名
- FROM:从哪个表中查询
- WHERE:可以使用WHERE语句过滤数据
- GROUP BY:所有不在聚合中的列都需要在GROUP BY,含义就是以哪些字段分组聚合
- ORDER BY:根据col2sum排序
这个简单的SQL样例就可以在数据库里轻松查到一些有价值的信息。
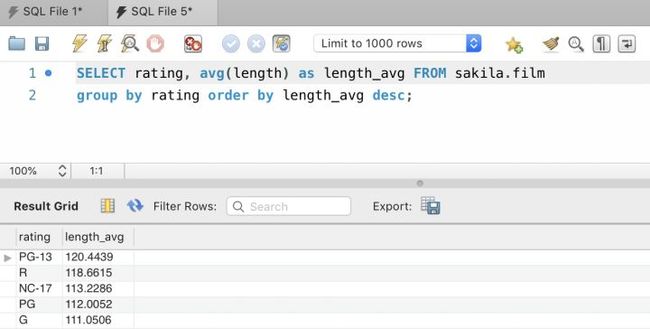
例如,我们可以用以下方法找出不同审查等级的电影在平均时间上的差异:
SELECT rating
,avg(length) AS length_avg
FROM sakila.film
GROUP BY rating
ORDER BY length_avg DESC;
编辑切换为居中
添加图片注释,不超过 140 字(可选)
接下来可以做一个练习,你可以根据自己感兴趣的内容想出一些自己的问题。
例如,你可以试着找出所有在2006年发行的电影、或者尝试找出所有评级为PG且长度大于50分钟的电影。
你可以通过在MySQL Workbench上运行以下程序来完成这个任务:
SELECT *
FROM sakila.film
WHERE release_year = 2006;
SELECT *
FROM sakila.film
WHERE length > 50
AND rating = "PG";
SQL连接
到现在为止,我们已经学会了如何查询单个表。
但在现实中,我们需要与多个表一起工作,需要 用到表的关联。
这时,就会用到SQL中一个非常重要的概念:SQL连接。
下面这张图讲列出了SQL中大多数会用到的连接,使用较多的就是LEFT JOIN和INNER JOIN:
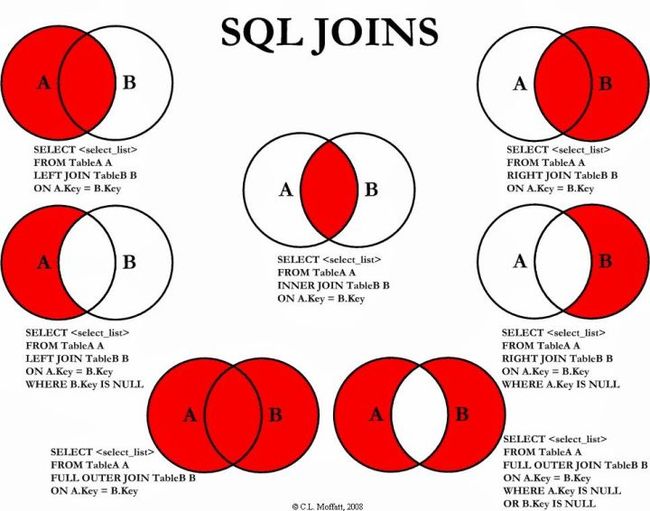
下面,就先来介绍一下LEFT JOIN,先来看一段SQL代码:
SELECT A.col1
,A.col2
,B.col3
,B.col4
FROM A
LEFT JOIN B
ON A.col2 = B.col3;
当你想保留左表(A)中的所有记录并关联B中的匹配记录时,就可以使用LEFT JOIN。在结果表中,B没有被关联到的A表记录被置为NULL。
在上面这段代码中,从表A中选择col1和col2,从表B中选择col3和col4,我们还使用ON语句指定关联字段。
当你想连接A和B并只保留A和B中的交集时,就可以使用INNER JOIN。
回到Sakila数据库,假设我们想知道数据库中每部电影有多少分拷贝,你可以通过以下方式获得:
SELECT film_id
,count(film_id) AS num_copies
FROM sakila.inventory
GROUP BY film_id
ORDER BY num_copies DESC;

你觉得这个结果怎么样?
你会发现你从这里面并不能得到太多有价值的信息,因为ID是一种系统设计过程中方便系统识别的标识符,但是对于用户端并不能很好理解,比如,《霸王别姬》对应的ID是1001,直接返回给你1001,看不到名称我们就很难读懂它里面的信息。
因此,我们就需要电影ID和电影名称的一种关联关系。
但是,在系统模型设计过程中,一个系统流程会被拆分到多个数据表中,film_id和film的映射关系我们就需要去另外一张表中取到。
这时候,就需要用到前面介绍的表连接。
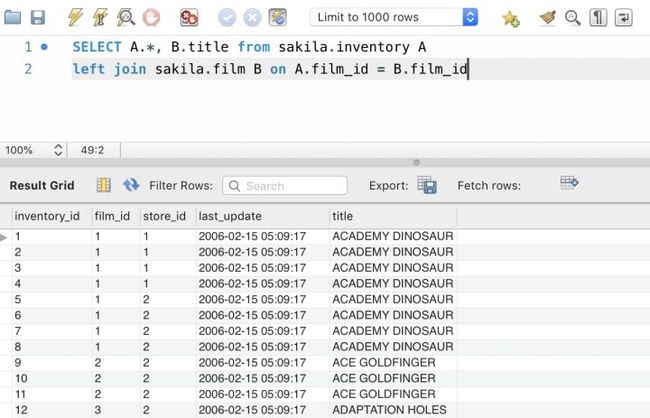
SELECT A.*
,B.title
FROM sakila.inventory A
LEFT JOIN sakila.film B
ON A.film_id = B.film_id;
编辑切换为居中
添加图片注释,不超过 140 字(可选)
在上面SQL中,通过film_id字段将A表与B表关联到一起,并从表B中取出了电影名称title,这样再输出结果就可以带出电影名称,方便理解了。
内部查询
假设现在有一个需求,我们需要基于前面的结果统计每部电影有多少副本。
如果逐步实现的话,需要先把前面的结果写到一张新表里:
CREATE TABLE sakila.temp_table AS
SELECT A.*
,B.title
FROM sakila.inventory A
LEFT JOIN sakila.film B
ON A.film_id = B.film_id;
然后使用一个简单的group by操作:
SELECT title
,count(title) AS num_copies
FROM sakila.temp_table
GROUP BY title
ORDER BY num_copies DESC;

但是这步骤太多、太繁琐了,而且我们必须创建一个临时表,最终会占用系统的空间。
SQL为我们提供了内部查询的概念,就是为了解决这类问题。
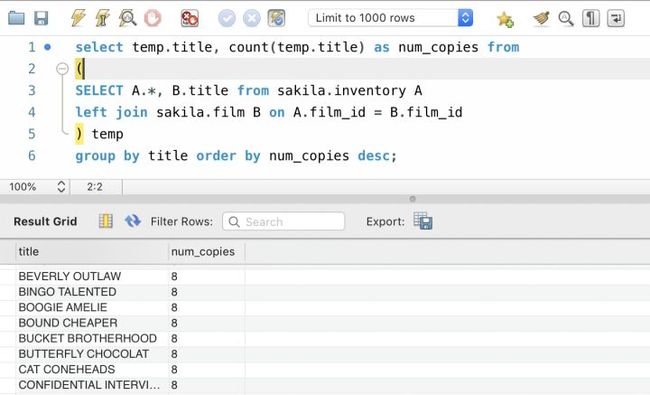
我们可以层层嵌套,把第一个查询结果放在一个括号里,并给这个结果起一个别名temp,然后再在temp的基础上做group by操作。
得益于内部查询的概念,我们可以在某些时候编写比较复杂的SQL查询:
SELECT temp.title
,count(temp.title) AS num_copies
FROM (
SELECT A.*
,B.title
FROM sakila.inventory A
LEFT JOIN sakila.film B
ON A.film_id = B.film_id
) temp
GROUP BY title
ORDER BY num_copies DESC;
HAVING子句
HAVING也是一个需要理解的SQL结构,它很有用。
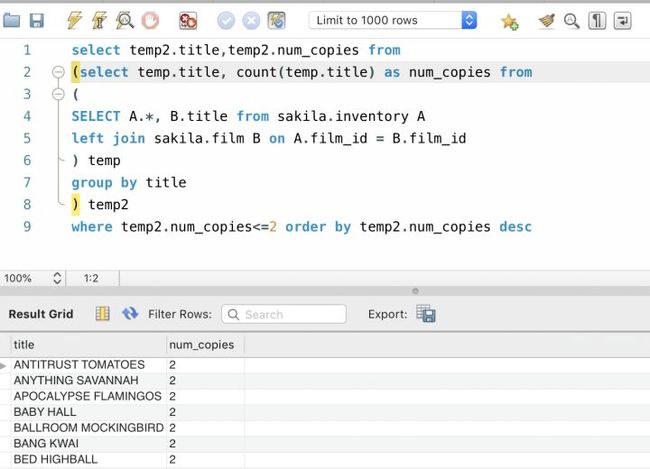
考虑一个问题:根据前面的结果,我们想得到那些拷贝数小于或等于2的影片。
我们可以通过使用内部查询的概念和WHERE子句来实现这个目的,如下所示,这里我们把一个内部查询嵌套在另一个内部查询中:
我们也可以用HAVING子句:
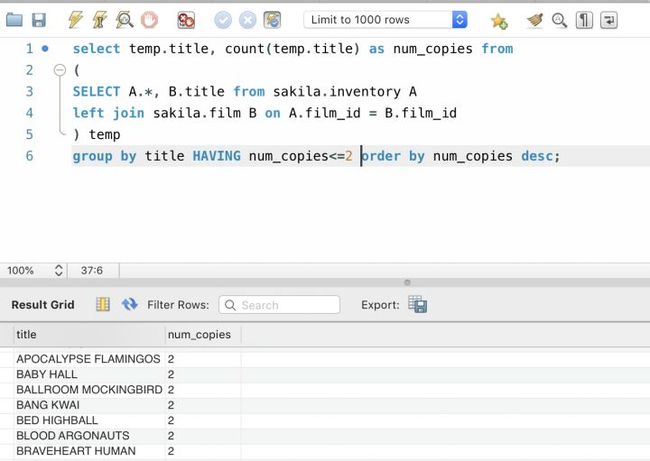
HAVING子句是用来过滤最终的聚合结果的,它与WHERE不同,WHERE是用来过滤FROM语句中使用的表。HAVING过滤的是GROUP BY处理后的最终结果。
正如你在上面的例子中看到的那样,解决一个问题,可以有很多实现方法。我们需要想出最省事的方法,因此HAVING在很多情况下更加简洁省事。
到此为止,已经从数据库服务、到SQL工作台再到基本的数据查询做了全面的了解,想必很多同学对MySQL也有了全局的认识。
接下来要做的就是逐个方面不断练习,我们可以自己寻找一些感兴趣的问题,然后通过SQL的方式找到答案,例如,哪个演员出演了最多的电影?哪个类型的电影被租用的最多?
这篇内容是一个简单的教程,如果想更加深入学习SQL,给大家推荐一门来自加州大学戴维斯分校的SQL数据分析课程:SQL for Data Science | Coursera,目前已经有几十万人报名,评分也非常高,感兴趣的同学可以看一下。