40从传统算法到深度学习:目标检测入门实战 --深度学习在目标检测中的应用:R-CNN
参考视频教程:
**深度学习之目标检测常用算法原理+实践精讲 **
R-CNN
在传统的目标检测方法中,我们使用滑动窗口标记目标的位置、使用人工设计的特征和机器学习算法进行分类,此类方法虽然可以基本达到实时性的要求但是其缺点也比较明显。首先滑动窗口采用穷举的策略来找到目标,这种方法的缺陷是如果步长和窗口尺寸设置太小会导致时间复杂度过高,在检测过程中会出现过多的冗余窗口,如果窗口的尺寸和步长设置过大就会导致检测不到目标,同时人工设计的特征面对复杂的环境和遮挡不能表现较好的鲁棒性。不同于传统的方法,基于深度学习的目标检测提出了一系列的改进方法,本节实验我们将介绍其中的开山之作:R-CNN。
R-CNN(Rich feature hierarchies for accurate object detection and semantic segmentation)是最早将深度学习应用于目标检测领域的方法之一,其使用基于候选区域的方法替代滑动窗口来寻找图像中可能存在目标的区域,使用卷积神经网络替代人工设计的特征用于目标特征的提取,然后使用支持向量机(SVM)判断目标类别并使用边框回归(Bounding-Box Regression)修正候选框(Bounding Box)的位置。相较于传统的方法,R-CNN 提高了检测的准确率和面对复杂环境的鲁棒性。下面让我们来了解下 R-CNN 的基本原理以及如何使用 Keras 实现 R-CNN。
如下图,R-CNN 可以分为以下四个步骤。
使用候选区域方法找出图片中可能存在目标的区域。
将这些区域缩放成相同尺寸输入卷积神经网络,通过网络提取每个区域的特征。
将提取到的特征输入分类器并判别每个特征所属类别。
使用边框回归修正候选框的位置。

image.png
上述步骤和部分概念名词大家一开始可能会不太明白,不过不用担心,在接下来的实验我们将通过代码一步步地构建 R-CNN 检测模型,在这个过程中大家将逐步理解上述内容。与原始的 R-CNN 不同,本次实验我们不会单独使用 SVM 和边框回归对目标进行分类和定位,而是在使用迁移学习的同时将这两种方法嵌入进神经网络。接下来我们将介绍如何实现一个 R-CNN 以及整个项目流程。
项目流程和数据集
本节实验我们将构建一个 R-CNN 检测模型用于检测和标记出图片中的宠物狗。如下图,我们的项目流程可以分为以下几个步骤。
首先需要对数据集进行预处理,我将会对数据集中的图片使用候选区域算法生成正负样本,然后再将正负样本输入网络进行训练(在本节实验中我们将直接提供已经生成好的正负样本)。
数据集预处理后构建我们的 CNN 模型,这个模型的输入是图片中可能存在目标的区域,模型的输出有两个,一个是对输入的分类结果,另一个是用于标记出目标物体在图片中位置的矩形框坐标。
模型训练完成后我们就可以使用模型进行目标检测了,但是我们不会直接将待检测图片作为模型的输入,而是先用候选区域算法找出图片中可能存在目标的区域。
将步骤 3 中生成的区域输入模型,模型将对每个区域进行分类和生成用于标记的矩形框坐标,最后在图片中标记出目标物体。

image.png
接下来要给大家介绍本节实验将用到的数据集,我们将使用一个由不同品种的宠物狗构成的数据集对卷积神经网络进行训练。数据集由 2490 个标注文档和 2490 张宠物狗图片组成,每个标注文档对应一张图片,其中标注文档保存了一些图片信息(图片名,图片宽、高等)以及用于标记图片中宠物狗的矩形框坐标。
如下图,通过标注文档中提供的坐标我们可以在原图中用矩形框标记出宠物狗的头部(图中绿色矩形框),这些矩形框我们称之为 Ground Truth,图中红色矩形框内就是矩形框的坐标值,其中 xmin 和 ymin 表示矩形左上角顶点坐标,即图中绿色矩形框左上角黄色箭头所指顶点,xmax 和 ymax 表示矩形右下角顶点坐标,即图中绿色矩形框右下角黄色箭头所指顶点。我们将使用这些源图片和用于标记宠物狗头部的矩形框坐标来训练我们的神经网络模型,这样对于每张输入图片,我们的模型都可以预测图片中宠物狗头部的坐标位置。

image.png
至此我们已经熟悉了整个项目的流程,现在让我们开始编写相应的代码,首先执行下面一行命令安装 opencv-contrib-python,我们将使用其中的模块生成候选区域。
!pip install opencv-contrib-python
我们可以通过下面的命令下载和解压数据集。然后我们使用 !ls 命令查看解压后的 dataset 文件夹是否在当前目录下。dataset 目录下有两个子目录 images 和 annotations,分别存放 2490 个标注文档和 2490 张宠物狗图片。
!wget https://labfile.oss.aliyuncs.com/courses/3096/dataset.zip
!unzip dataset.zip
!ls
配置基本参数
在开始构建我们自己的 R-CNN 算法前,让我们先设定一些配置参数,这些参数将在后面的代码中用到。首先导入 os 模块用于操作文件路径,然后导入 cv2 模块。我们设置数据集的路径 BASE_PATH,这个路径就是我们前下载并解压的 dataset 目录,然后我们分别设置源图片的路径 ORIG_IMAGES、标注文档的路径 ORIG_ANNOTS。
import os
import cv2
BASE_PATH = "dataset"
ORIG_IMAGES = os.path.sep.join([BASE_PATH, "images"])
ORIG_ANNOTS = os.path.sep.join([BASE_PATH, "annotations"])
我们还需要设置正负样本路径 DOG_PATHS、BACKGROUNDS_PATHS,稍后我们将会用候选区域算法对每张源图片进行裁剪,提取出宠物狗头部的区域以及不包含头部的区域,因为在训练阶段我们不仅要用到源图片也要用这些裁剪后的区域训练,具体原因我们后面会解释。
DOG_PATHS = os.path.sep.join([BASE_PATH, "dog"])
BACKGROUND_PATHS = os.path.sep.join([BASE_PATH, "background"])
路径 BASE_OUTPUT 是用于保存一些输出文件的目录。第 3、4 行表示如果目录 output 不存在则创建一个 output 目录。LB_PATH 是保存标签文件的路径。
BASE_OUTPUT = "output"
if not os.path.exists(BASE_OUTPUT):
os.mkdir(BASE_OUTPUT)
LB_PATH = os.path.sep.join([BASE_OUTPUT, "lb.pickle"])
最后我们设置一些训练模型时需要的参数,INPUT_DIMS 表示训练模型时输入图片的尺寸,INIT_LR 表示训练时的学习率,NUM_EPOCHS 表示数据集将被训练的次数,BS 表示每次训练图片的数量。
INPUT_DIMS = (224, 224)
INIT_LR = 1e-4
NUM_EPOCHS = 15
BS = 1
选择性搜索(Selective Search)
配置完基本参数,下面就需要构建我们的候选区域函数,我们将用这个函数创建我们自己的数据集,以及在检测阶段使用这个函数获取图片中可能存在目标的区域。本节实验我们将要用到的候选区域方法是选择性搜索(Selective Search),选择性搜索算法的原理是先将图片分割成许多小的区域,然后在综合考虑多种特征(颜色、纹理、相似性、形状等)将这些小的区域合并起来以达到找到图片可能存在目标物体的目的。需要注意的是选择性搜索算法并不能判断一个区域肯定存在目标,它只能告诉我们给定区域内可能存在目标,至于有没有目标以及目标是什么还需进一步使用诸如分类器等算法去判断。下图表示选择性搜索综合多种特征给出图片中可能存在的目标区域。

image.png
接下来我们将使用 Opencv 实现选择性搜索算法。首先创建名为 ssearch 的函数,该函数有两个输入值,image 表示输入图片,mode 表示我们将使用哪种模式的选择性搜索算法。在函数内使用 Opencv 中的 cv2.ximgproc.segmentation.createSelectiveSearchSegmentation() 初始化选择性搜索实例并使用 setBaseImage() 设置输入图片。
第 5-8 行表示我们将使用哪种模式寻找可能存在目标的区域,即 switchToSelectiveSearchFast() 和 switchToSelectiveSearchQuality() 模式。其中 switchToSelectiveSearchFast() 模式的效率较高,我们默认设置这种模式。第 10 行我们调用 process() 方法获取每个候选区域,这里 rects 包含了所有候选区域,每个候选区域由四个值构成 x, y, w, h, 其中 x, y 表示候选区域左上角顶点坐标,w, h 表示候选区域的宽和高。
def ssearch(image, mode="fast"):
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
ss.setBaseImage(image)
if mode == "fast":
ss.switchToSelectiveSearchFast()
else:
ss.switchToSelectiveSearchQuality()
rects = ss.process()
return rects
交并比(IOU)
在实验六中我们介绍了交并比(IOU)的基本概念,在本节实验中我们将使用交并比来计算两个矩形框重叠的情况,当创建数据集时我们将使用交并比来挑选出包含宠物狗头部的候选区域。下面让我们来构建一个交并比函数。
首先将交并比函数命名为 compute_iou,该函数的两个输入参数 boxA、boxB 表示将计算交并比的两个矩形,这两个参数都由 4 个值组成,分别是矩形的左上角顶点坐标和右下角顶点坐标。第 2 至 5 行计算 boxA 和 boxB 重叠部分的矩形左上角顶点和右下角顶点坐标。第 7 行计算重叠部分的矩形面积,如果两个矩形不相交则 interArea 值是 0。第 9 至 10 行计算两个矩形的面积。最后计算并返回交并比。
def compute_iou(boxA, boxB):
xA = max(boxA[0], boxB[0])
yA = max(boxA[1], boxB[1])
xB = min(boxA[2], boxB[2])
yB = min(boxA[3], boxB[3])
interArea = max(0, xB - xA + 1) * max(0, yB - yA + 1)
Area_A = (boxA[2] - boxA[0] + 1) * (boxA[3] - boxA[1] + 1)
Area_B = (boxB[2] - boxB[0] + 1) * (boxB[3] - boxB[1] + 1)
iou = interArea / float(Area_A + Area_B - interArea + 1)
return iou
非极大值抑制(Non Maximum Suppression)
在后面的目标检测阶段我们将会用到非极大值抑制的方法,这个方法我们在实验 6 非极大值抑制一节中已经介绍过了,详细讲解可以参考实验 6,这里就不多做赘述,下面是构建该方法的代码。
def NMS(boxes, threshold):
if len(boxes) == 0:
return []
boxes = np.array(boxes).astype("float")
x1 = boxes[:,0]
y1 = boxes[:,1]
x2 = boxes[:,2]
y2 = boxes[:,3]
w1 = x2 - x1
h1 = y2 - y1
area = (w1 + 1) * (h1 + 1)
temp = []
idxs = np.argsort(y2)
while len(idxs) > 0:
last = len(idxs) - 1
i = idxs[last]
temp.append(i)
x1_m = np.maximum(x1[i], x1[idxs[:last]])
y1_m = np.maximum(y1[i], y1[idxs[:last]])
x2_m = np.minimum(x2[i], x2[idxs[:last]])
y2_m = np.minimum(y2[i], y2[idxs[:last]])
w = np.maximum(0, x2_m - x1_m + 1)
h = np.maximum(0, y2_m - y1_m + 1)
over = (w * h) / area[idxs[:last]]
idxs = np.delete(idxs, np.concatenate(([last],
np.where(over > threshold)[0])))
return boxes[temp].astype("int")
构建数据集
至此我们已经编写好所需的函数方法,接下来就是构建我们的数据集了。我们会从标注文档中提取出宠物狗头部坐标信息,然后使用选择性搜索和交并比方法从源图片中分离出正负样本。首先我们导入需要用到的模块,这些模块的作用我们在后面的代码中会介绍。
from bs4 import BeautifulSoup
import numpy as np
from tensorflow.keras.applications import VGG16
from tensorflow.keras.layers import Flatten, Dropout, Dense, Input
from tensorflow.keras.models import Model, model_from_json, load_model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.preprocessing.image import img_to_array, load_img, array_to_img
from tensorflow.keras.utils import to_categorical
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
import tensorflow as tf
import math
import json
import pickle
from sklearn.utils import shuffle
import matplotlib.pyplot as plt
from IPython import display
%matplotlib inline
下面第 1、2 行代码使用导入的 os 模块中的 listdir 方法获取 ORIG_ANNOTS 路径中所有的标注文档名,以及获取 ORIG_IMAGES 路径中所有源图片名。第 3 行使用 os.path.join 方法将 ORIG_ANNOTS 和每个标注文档名连接起来,这样我们就获取了每个标注文档的路径并将这些路径保存在 xmlpaths 中。
xmlpaths = os.listdir(ORIG_ANNOTS)
imagelists = os.listdir(ORIG_IMAGES)
xmlpaths = [os.path.sep.join([ORIG_ANNOTS, path]) for path in xmlpaths]
接下来我们创建列表 bboxes、orig_bboxes、imagepaths 分别用于存储宠物狗头部相对坐标值、宠物狗头部绝对坐标值、每张源图片路径。
bboxes = []
orig_bboxes = []
imagepaths = []
下面我们使用 for 循环遍历 xmlpaths 获取每个标注文档的路径 path。第 3 行代码我们打开标注文档 path 使用从 bs4 中导入的 BeautifulSoup 模块解析标注文档内容。第 4 行代码我们解析 filename 标签获取文件名。 第 6 到 7 行我们需要确认每个标注文档是否有对应的源图片,如果没有则跳过本次循环。第 9 行我们通过连接 ORIG_IMAGES 和 imgname 获取每张源图片的路径。第 11 到 12 行获取图片的宽和高,注意这里需要将宽和高转换为整型。
第 14 行使用 BeautifulSoup 的 find 方法获取 object 标签,这个标签内是可以标记出宠物狗头部的矩形框的 2 个顶点坐标值。第 16 到 19 行解析坐标值并将这些值转换为整型,其中 xMin、yMin、xMax 和 yMax 是矩形两个顶点坐标值。第 21 到 24 行我们分别使用 max 和 min 方法确保这 4 个坐标值大于等于 0,小于等于源图片的宽和高。
第 26 行我们将每张图片的路径都保存在 imagepaths 中,第 27 行将解析的坐标值保存在 bboxes 中,需要注意的是这里我们保存的是经过归一化处理的相对坐标,即横坐标与源图片的宽的比值、纵坐标与源图片的高的比值,这样处理后的坐标即使对图片进行缩放也可以准确定位,同时在模型训练阶段也可以加快梯度收敛。第 28 行我们将坐标值保存在 orig_bboxes 中,即没有经过归一化处理的绝对坐标。
for path in xmlpaths:
soup = BeautifulSoup(open(path)).annotation
imgname = soup.filename.string
if imgname not in imagelists:
continue
imagepath = os.path.sep.join([ORIG_IMAGES, imgname])
w = int(soup.size.width.string)
h = int(soup.size.height.string)
o = soup.find("object")
xMin = int(o.find("xmin").string)
yMin = int(o.find("ymin").string)
xMax = int(o.find("xmax").string)
yMax = int(o.find("ymax").string)
xMin = max(0, xMin)
yMin = max(0, yMin)
xMax = min(w, xMax)
yMax = min(h, yMax)
imagepaths.append(imagepath)
bboxes.append((float(xMin)/w, float(yMin)/h, float(xMax)/w, float(yMax)/h))
orig_bboxes.append((xMin, yMin, xMax, yMax))
正负样本
通过前面的操作我们获得了每张源图片的路径 imagepaths、每张图片对应的矩形框坐标 orig_bboxes,现在我们还需要正负样本。创建正负样本的步骤如下。
使用选择性搜索方法从每张源图片中获得多个候选区域。
计算每个候选区域和 Ground Truth 的交并比。
设定一个阈值T1(可以将这个阈值设定为大于 0.5 的小数),将交并比大于T1的候选区域保存为正样本(这里并不需要保存所有符合条件的正样本,只需要挑选 1 到 3 张作为正样本)。
设定一个阈值T2(可以将这个阈值设定为小于 0.2 的小数),将交并比小于T2的候选区域保存为负样本(这里并不需要保存所有符合条件的负样本,只需要挑选 1 到 3 张作为负样本)。
由于生成正负样本需要花费相当长的时间,本节实验我们将向大家提供已经处理好的正负样本,大家可以自行尝试使用 compute_iou 和 ssearch 函数生成正负样本。使用下面命令下载并解压正样本。这里要确保 dog.zip 文件解压到 dataset 目录下。
!wget https://labfile.oss.aliyuncs.com/courses/3096/dog.zip
!unzip -o -d dataset dog.zip
同样的,通过下面命令下载并解压已经处理好的负样本。这里要确保 background.zip 文件解压到 dataset 目录下。
!wget https://labfile.oss.aliyuncs.com/courses/3096/background.zip
!unzip -o -d dataset background.zip
下图是我们下载的正负样本,正样本就是宠物狗的头部图片,负样本就是不包含宠物狗头部的图片。

image.png
边框回归
现在我们将使用 imagepaths 和 bbox 进行边框回归。简单来说边框回归是寻找一个与 Ground Truth 最相似的矩形框的过程。如下图,绿色矩形框是 Ground Truth,红色矩形框是检测过程中产生的矩形框,我们的目的就是通过边框回归使得红色矩形框逼近 Ground Truth。

image.png
接下来让我们构建边框回归模型,如果我们像上一节实验一样从零开始构建 CNN 将会需要大量的计算时间和计算资源,而且还存在参数不够优化、过拟合、模型泛化能力差等风险,一种常用且非常高效的解决方法是使用预训练网络。预训练网络是已经在大型数据集上训练好的网络。这些网络可以作为有效的通用模型使用。本节实验我们将使用的预训练网络是 VGG16,我们可以使用下面命令下载该网络。
!wget https://labfile.oss.aliyuncs.com/courses/3096/vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5
接下来我们首先进行处理数据集的操作,下面代码第 1 到 4 行使用从 sklearn.model_selection 中导入的 train_test_split 模块将 imagepaths 和 bboxes 分为训练集和测试集。
split = train_test_split(imagepaths, bboxes, test_size=0.20, random_state=42)
(trainPaths, testPaths) = split[:2]
(trainBBoxes, testBBoxes) = split[2:]
下面我们需要计算训练集和测试集完成一整次训练需要生成多少个 Mini Batch(下面代码第 1、2 行),例如,假设 Mini Batch 为 32,我们的训练集有 1000 个样本,测试集有 100 个样本,则训练集完成一整次训练需要生成1000÷32=32 (向上取整)个 Mini Batch,测试集完成一整次训练需要100÷32=4(向上取整)个 Mini Batch。
BS_TR = math.ceil(len(trainPaths)/BS)
BS_TE = math.ceil(len(testPaths)/BS)
现在我们就是正式开始构建我们的 CNN 了,首先使用从 tensorflow.keras.applications 导入的 VGG16 载入我们刚才下载的预训练模型。这个模块需要输入 3 个参数,其参数意义如下所示。
weights 表示加载预训练网络,只需将文件路径赋值给 weights。
include_top 表示是否加载全连接层,本节实验我们只使用卷积层提取特征,所以这里我们将其设置为 False。
input_tensor 表示模型的输入张量,这里我们使用从 tensorflow.keras.layers 中导入的 Input 实例化输入张量为 (224, 224, 3)。
接着我们将 vgg.trainable 设置为 Fasle 表示在训练网络时这些卷积层将不参与训练。
vgg = VGG16(weights="vgg16_weights_tf_dim_ordering_tf_kernels_notop.h5", include_top=False,
input_tensor=Input(shape=(224, 224, 3)))
vgg.trainable = False
下面第 1、2 行代码使用从 tensorflow.keras.layers 中导入的 Flatten() 将 VGG16 卷积层的输出转化为一个向量。第 4 行使用从 tensorflow.keras.layers 中导入的 Dense() 添加全连接层,该层的输入就是前面转化为向量的 flatten,参数 128 表示该层有 128 个节点,activation=“relu” 表示将激活函数设置为 relu,name=“bounding_box1” 表示将该层命名为 “bounding_box1”。第 5、6 行分别再创建两个全连接层。第 7 行代码创建一个只有 4 个节点的全连接层,这四个节点的输出值就是检测矩形框的左上角和右下角坐标,该层我们设置激活函数为 “sigmoid”。
flatten = vgg.output
flatten = Flatten()(flatten)
bboxHead = Dense(128, activation="relu", name="bounding_box1")(flatten)
bboxHead = Dense(64, activation="relu", name="bounding_box2")(bboxHead)
bboxHead = Dense(32, activation="relu", name="bounding_box3")(bboxHead)
bboxHead = Dense(4, activation="sigmoid",
name="bounding_box")(bboxHead)
接下来我们使用从 tensorflow.keras.models 中导入的 Model 实例化模型,这个模型将包含从 vgg.input 到 bboxHead 的所有网络层。然后使用 model.summary() 输出模型概述信息。
model = Model(inputs=vgg.input, outputs=bboxHead)
print(model.summary())
我们的网络已经构成好了,现在我们需要定义损失。下面第 1 行代码我们创建一个 losses 字典表示在 bounding_box 层输出上使用均方误差 mean_squared_error。第 2 行代码创建一个 lossWeights 字典表示在模型输出上用 1.0 来计算总的损失权重。第 3、4 行代码创建 trainTargets 和 testTargets 两个字典表示将训练集 trainBBoxes 和测试集 testBBoxes 作用于输出。
losses = {"bounding_box": "mean_squared_error"}
lossWeights = {"bounding_box": 1.0}
trainTargets = {"bounding_box": trainBBoxes}
testTargets = {"bounding_box": testBBoxes}
接下来我们使用从 tensorflow.keras.optimizers 中导入的 Adam 优化误差函数,下面第 1 行我们初始化 Adam 算法并将学习率设为 INIT_LR。第 2 行使用 compile 配置编译我们的训练模型,参数 loss 表示我们选择的目标函数,这里传入前面创建的 losses 字典。optimizer 是设置优化方法,这里我们将其设置为 Adam 算法。metrics 用于设置模型评估标准,这里我们将其设置为 [“accuracy”]。loss_weights 表示损失权重,这里传入前面创建的 lossWeights 字典。
opt = Adam(lr=INIT_LR)
model.compile(loss=losses, optimizer=opt, metrics=["accuracy"], loss_weights=lossWeights)
生成器(Generator)
完成了上面编译模型的工作我们就可以训练我们的网络了,在训练开始之前我们需要解决一个问题。上一节实验我们将数据集一次性读入内存,然后用这些数据训练,在数据集比较小的情况下,这种做法不会出现什么问题,但是当数据集较大时,就无法将所有的数据都读入内存,这时候就会发生内存耗尽、受限的状况导致训练失败,为了解决这个问题我们将编写一个生成器(Generator)分次的将数据读入内存。
首先我们定义生成器函数名为 batch_generator,该函数需要 3 个参数 x,targets,batch_size。x 表示我们的数据集中源图片的路径,targets 表示网络输出所需数据,这里是 Ground Truth 数据。batch_size 是每次读入多少数据量,即 Mini Batch 的尺寸。
在函数内我们首先获取 x 中数据的数量 num_samples。然后第 4 行我们使用 while 循环让代码一直执行。第 5、6 行使用 for 循环将 x 分成若干个 batches, 每个 batches 内的数据量等于 batch_size。第 8 行创建列表 X_train 用于存储每个 Mini Batch 的图片。第 9 到 12 行创建字典 batch_targets 并将 X_train 所对应的 Ground Truth 数据赋值给它,如果 targets 不仅仅包含 Ground Truth,还包含 x 所对应的标签,那么这个操作同样有效。
第 14 行遍历 batches,第 15 行使用从 tensorflow.keras.preprocessing.imag 中导入的 load_img 模块通过路径 batch_sample 载入图片并将图片的尺寸缩放为 (224, 224)。第 16 行使用从 tensorflow.keras.preprocessing.imag 中导入的 img_to_array 将图片转化为数组并除以 255.0 以达到归一化的目的。第 17 行将每张归一化的图片添加到 X_train 中,第 19 行将 X_train 转化为 NumPy 数组。最后使用 yield 语句生成 Mini Batch:X_train、batch_targets。
def batch_generator(x, targets, batch_size):
num_samples = len(x)
while True:
for offset in range(0, num_samples, batch_size):
batches = x[offset:offset+batch_size]
X_train = []
batch_targets = {}
for i in targets.keys():
batch_targets[i] = np.array(targets[i][offset:offset+batch_size])
for batch_sample in batches:
image = load_img(batch_sample, target_size=(224, 224))
image = img_to_array(image)/255.0
X_train.append(image)
X_train = np.array(X_train)
yield X_train, batch_targets
现在我们已经构建了生成器,接下来我们可以训练网络了,下面第 3 行代码使用 fit 方法训练网络,下面第 4 行代码表示将生成器 batch_generator 作为 fit 的参数,我们将源图片 trainPaths、Ground Truth trainTargets、Mini Batch 的尺寸 BS 作为参数传入生成器,这样生成器就会不停的生成尺寸为 BS 的 Mini Batch。
第 5 行 steps_per_epoch 表示训练集完成一整次训练需要生成 BS_TR 个 Mini Batch,第 6 行 validation_data 表示使用测试集评估模型,同样的这里使用生成器生成测试用的 Mini Batch。第 7 行 validation_steps 表示测试集完成一整次测试需要生成 BS_TE 个 Mini Batch。第 8 行 epochs 表示训练集将被训练 NUM_EPOCHS 次。第 9 行 verbose=1 表示以进度条形式显示训练过程。
第 11 行使用 model.to_json 以 JSON 字符串形式表示模型结构,第 12、13 行保存模型结构。第 15 行保存模型权重。
print("Training model...")
H = model.fit(
batch_generator(trainPaths, trainTargets, BS),
steps_per_epoch=BS_TR,
validation_data=batch_generator(testPaths, testTargets, BS),
validation_steps=BS_TE,
epochs=NUM_EPOCHS,
verbose=1)
model_string = model.to_json()
with open(os.path.sep.join([BASE_OUTPUT, "bboxes_regression_model.json"]), "w") as f:
f.write(model_string)
model.save_weights(os.path.sep.join([BASE_OUTPUT, "bboxes_regression_model_weights.h5"]))
由于在课程环境中训练需要花费较长时间,大家可以通过下面命令下载描述模型结构的 JSON 文件和已经训练好的权重文件。
!wget -O output/bboxes_regression_model.json https://labfile.oss.aliyuncs.com/courses/3096/bboxes_regression_model.json
!wget -O output/bboxes_regression_model_weights.h5 https://labfile.oss.aliyuncs.com/courses/3096/bboxes_regression_model_weights.h5
进行分类训练
因为边框回归训练和分类训练使用了两种不同的数据集,所以训练过程需要分成两个阶段。第一阶段我们已经使用源图片和 Ground Truth 完成了边框回归训练,下面将进行分类阶段的训练。
首先创建需要的列表 imagepaths、bboxes、labels。然后在第 5、6 行我们获取每张正样本图片路径,第 8、9 行我们获取每张负样本路径。
imagepaths = []
bboxes = []
labels = []
dogs = os.listdir(DOG_PATHS)
dogs = [os.path.sep.join([DOG_PATHS, path]) for path in dogs]
backgrounds = os.listdir(BACKGROUND_PATHS)
backgrounds = [os.path.sep.join([BACKGROUND_PATHS, path]) for path in backgrounds]
下面第 1 到 4 行我们将正样本中的每张图片添加到 imagepaths,将每张图片对应的标签 “dog” 添加到 labels,最后是添加对应的矩形框坐标 bboxes。需要注意的是这里添加的坐标并不是真正的 Ground Truth,而是一个假的矩形框坐标。
在接下来的训练阶段我们会在边框回归模型中嵌入分类模型,在训练阶段我们会冻结前面已经训练过的层,然后对网络进行分类训练,但是我们需要为模型提供 Ground Truth,所以在这一步我们为每张图片添加一个假的矩形框坐标,这里我们将其设置为 (0.0, 0.0, 0.0, 0.0)。同样的第 6 到 9 行我们分别将每张负样本的路径添加到 imagepaths,添加对应的标签 “background” 到 labels,添加对应的矩形框坐标。
for dog in dogs:
imagepaths.append(dog)
labels.append("dog")
bboxes.append((0.0, 0.0, 0.0, 0.0))
for background in backgrounds:
imagepaths.append(background)
labels.append("background")
bboxes.append((0.0, 0.0, 0.0, 0.0))
下面我们使用从 sklearn.utils 中导入的 shuffle 方法打乱 labels、imagepaths、bboxes。
labels, imagepaths, bboxes = shuffle(labels, imagepaths, bboxes, random_state=42)
接下来我们使用从 sklearn.preprocessing 模块中导入的 LabelBinarizer 对数据集的标签进行编码,使用 LabelBinarizer 中的 fit_trainsform 方法分别将训练集和测试集的标签二值化(下面代码第 1、2 行)如果我们数据集只有两类样本,则使用从 tensorflow.keras.utils 中导入的 to_categorical 将类别转换为二进制,即只有 0 和 1(下面代码第 4、5 行)。
lb = LabelBinarizer()
labels = lb.fit_transform(labels)
if len(lb.classes_) == 2:
labels = to_categorical(labels)
接下来我们使用 train_test_split 方法将 imagepaths、labels、bboxes 分为训练集和测试集(下面代码第 1 到 5 行)。第 7、8 行我们使用导入的 pickle 模块将标签对象 lb 转换为二进制对象并保存在路径为 LB_PATH 的文件中(下面代码第 7、8 行)。
split = train_test_split(imagepaths, labels, bboxes, test_size=0.20, random_state=42)
(trainPaths, testPaths) = split[:2]
(trainLabels, testLabels) = split[2:4]
(trainBBoxes, testBBoxes) = split[4:]
with open(LB_PATH, "wb") as f:
f.write(pickle.dumps(lb))
下面第 1、2 行代码读取描述模型结构的 JSON 文件,第 4 行代码使用从 tensorflow.keras.models 中导入的 model_from_json 实例化边框回归模型,第 5 行使用 load_weights 载入边框回归模型的权重。
with open(os.path.sep.join([BASE_OUTPUT, "bboxes_regression_model.json"]), 'r') as file:
model_json = file.read()
model = model_from_json(model_json)
model.load_weights(os.path.sep.join([BASE_OUTPUT, "bboxes_regression_model_weights.h5"]))
载入训练好的模型后,我们将在原有的网络基础上添加用于分类的分支网络。首先在第 1 行代码我们获取边框回归模型的最后一层的输出,即该层名称为 bounding_box 的层。代码第 2 行获取模型的 flatten 层的输出,这一层实际上就是将 VGG16 卷积层的输出转化为一个向量。第 4 行添加一个节点数为 512 的全连接层。第 5 行添加 Dropout 层,其随机丢弃部分节点的概率设为 0.25。同理第 6、7 行分别添加全连接层和 Dropout 层。第 8 行添加全连接层,其节点数等于需要分类的类别数,这里是 2 个节点。代码第 10 行使用 Model 将分类和边框回归整合在一起构建了新的网络,这个新网络的输入 input 就是边框回归的输入 model.input,网络的输出 output 分别是 bboxlayer 和 softmaxHead。
bboxlayer = model.layers[-1].output
flatten = model.get_layer("flatten").output
softmaxHead = Dense(512, activation="relu", name="label1")(flatten)
softmaxHead = Dropout(0.25)(softmaxHead)
softmaxHead = Dense(512, activation="relu", name="label2")(softmaxHead)
softmaxHead = Dropout(0.5)(softmaxHead)
softmaxHead = Dense(len(lb.classes_), activation="softmax", name="class_label")(softmaxHead)
model_2 = Model(inputs=model.input, outputs=(bboxlayer, softmaxHead))
整个网络的结构如下图所示,输入图片经过卷积层后分别输入边框回归和分类分支中,最后模型输出预测的边框坐标和类别。
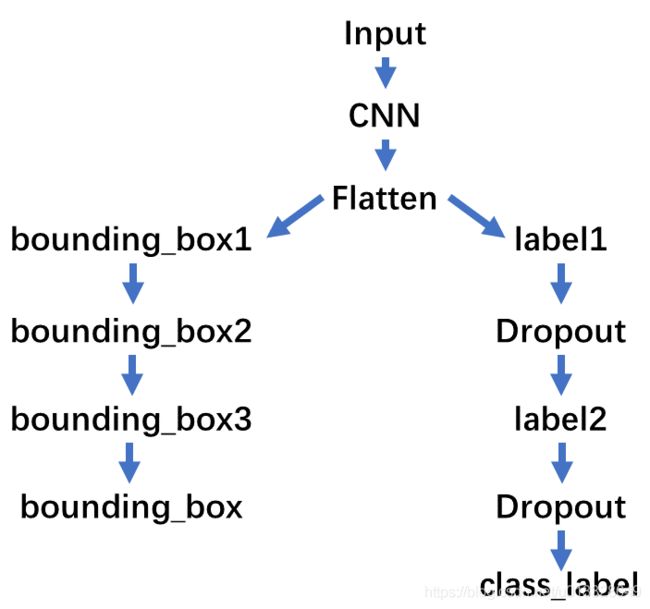
image.png
因为在第一训练网络时,边框回归分支已经训练好了不需要再进行训练了,所以下面第 1 到 5 行代码表示我们将这些不需要训练的层冻结。然后代码第 7 行使用模型的 summary() 输出模型的结构。
bboxes_layers = ["bounding_box1", "bounding_box2", "bounding_box3", "bounding_box"]
for layer in model_2.layers:
if layer.name in bboxes_layers:
layer.trainable = False
print(model_2.summary())
因为新模型添加了分类分支,所以模型的损失函数和损失权重也要做相应的修改。下面第 1 到 4 行我们在原有的 losses 字典中添加了分类损失函数为 “categorical_crossentropy”。第 6 到 9 行在 lossWeights 字典中添加了分类损失权重为 1.0。
losses = {
"class_label": "categorical_crossentropy",
"bounding_box": "mean_squared_error",
}
lossWeights = {
"class_label": 1.0,
"bounding_box": 1.0
}
同理,下面第 1 到 4 行在 trainTargets 字典中添加训练集所对应的标签 trainLabels,在 testTargets 字典中添加测试集所对应的标签 testLabels。
trainTargets = {
"class_label": trainLabels,
"bounding_box": trainBBoxes
}
testTargets = {
"class_label": testLabels,
"bounding_box": testBBoxes
}
最后第 1 到 3 行我们配置训练模型,第 5 到 11 行使用生成器对模型进行训练。第 14 行保存训练好的模型。自此我们已经完成了整个模型的构建和训练。
opt = Adam(lr=5e-4)
model_2.compile(loss=losses, optimizer=opt, metrics=["accuracy"],
loss_weights=lossWeights)
H = model_2.fit_generator(
batch_generator(trainPaths, trainTargets, BS),
steps_per_epoch=BS_TR,
validation_data=batch_generator(testPaths, testTargets, BS),
validation_steps=BS_TE,
epochs=3,
verbose=1)
print("Saving object detector model")
model_2.save(os.path.sep.join([BASE_OUTPUT, "dog_model.h5"]), save_format="h5")
由于在课程环境中训练整个模型需要耗费大量时间,所以大家可以通过下面命令下载已经训练好的模型。
!wget -O output/dog_model.h5 https://labfile.oss.aliyuncs.com/courses/3096/dog_model.h5
实现目标检测
接下来我们将使用前面训练好的模型进行目标检测,我们使用下面命令用于检测的图片。
!wget https://labfile.oss.aliyuncs.com/courses/3096/predict_images.zip
!unzip predict_images.zip
接下来我们使用从 tensorflow.keras.models 中导入的 load_model 载入训练好的模型,使用 pickle.loads 读取保存的标签对象。
print("Loading object detector...")
model = load_model(os.path.sep.join([BASE_OUTPUT, "dog_model.h5"]))
lb = pickle.loads(open(LB_PATH, "rb").read())
然后我们设置待检测图片的路径 imagepath。第 2 到 5 行分别表示导入图片、将图片转换为数组、获取图片的宽 width 和高 height、使用选择性搜索获取候选区域 rects。第 7 行列表 pboxes 将会存储模型输出的检测框。
imagepath = "dogs1.jpeg"
image = load_img(imagepath)
image = img_to_array(image)
height, width = image.shape[:2]
rects = ssearch(image)
pboxes = []
然后我们使用 for 循环遍历 rects 中的前 500 个候选区域。第 2、3 行代码表示如果候选区域的宽和高不满足设定的条件则跳过该循环。第 5 到 8 行首先从原图中裁剪出候选区域,将这些区域的尺寸缩放为 (224, 224),对每个区域进行归一化处理,然后使用 np.expand_dims 扩展区域维度。
第 10 行使用载入模型对每个候选区域进行检测,模型分别输出检测框的坐标 boxPreds 和目标的类别 labelPreds。第 11 行获取检测框的左上角和右下角顶点坐标。第 13 到 16 行表示如果标签的预测结果是 backgournd 则跳出当前循环。第 18、19 表示如果标签的预测值小于 0.6 则跳出当前循环。
第 21 到 24 行计算检测框在候选区域中的绝对坐标,由于模型输出的检测框坐标是相对坐标,所以我们需要用这些值与候选区域 roi 的宽和高相乘获取绝对坐标。第 26、27 行计算检测框的宽 r_w 和高 r_h。第 29 到 32 行计算在原图中检测框的坐标,由于我们获取的检测框坐标是相对于候选区域,而候选区域是从原图中裁剪获取的,所以我们需要将检测框的坐标转换为相对原图的坐标。最后将转换后的坐标添加到 pboxes 中。最后在课程环境下运行这个 for 循环需要花费大概 50 到 90 秒左右的时间,大家需要耐心等待一下。
for (x, y, w, h) in rects[:500]:
if w < 50 or h < 50 or w == 0 or h == 0 or 2*w < h or w > 0.7*width or h > 0.7*height:
continue
roi = image[y:y+h, x:x+w]
roi = cv2.resize(roi, (224, 224), interpolation=cv2.INTER_LINEAR)
roi = roi / 255.0
roi = np.expand_dims(roi, axis=0)
(boxPreds, labelPreds) = model.predict(roi)
(startX, startY, endX, endY) = boxPreds[0]
i = np.argmax(labelPreds, axis=1)
label = lb.classes_[i][0]
if label == "background":
continue
if labelPreds[0][i] < 0.6:
continue
startX = int(startX * w)
startY = int(startY * h)
endX = int(endX * w)
endY = int(endY * h)
r_w = endX - startX
r_h = endY - startY
s_x = x + startX
s_y = y + startY
e_x = s_x + r_w
e_y = s_y + r_h
pboxes.append((s_x, s_y, e_x, e_y))
下面第 1 行我们使用非极大值抑制抑制剔除 pboxes 中的冗余检测框。第 2 行使用 tensorflow.keras.preprocessing.image 中导入的 array_to_img 将数组转换为图像,然后使用 for 循环在原图中画出检测框。第 7、8 行显示检测结果。最后第 10 到 12 行代码保存图片。
picks = NMS(pboxes, threshold=0.3)
image = np.array(array_to_img(image))
for (nms_x, nms_y, end_x, end_y) in picks:
cv2.rectangle(image, (nms_x, nms_y), (end_x, end_y), (0, 255, 0), 2)
plt.figure(figsize = (10,10))
plt.imshow(image)
image = image[:,:,::-1]
results = imagepath.split(".")[0] + "_predict" + ".jpg"
cv2.imwrite(results, image)
大家可以将 imagepath = “dogs1.jpeg” 中的路径修改为需要检测的图片路径。如果没有出现错误的话大家应该会得到下图的检测结果,可以看到我们的模型识别图片中的宠物狗并将其标记出来。

image.png