非深度网络 Non-deep Network:低延迟平行网络 ParNet,仅 12 层媲美 ResNet
Non-deep Network
Ankit Goyal1,2 Alexey Bochkovskiy2 Jia Deng1 Vladlen Koltun2
1Princeton University 2 Intel Labs
[pdf] [github]
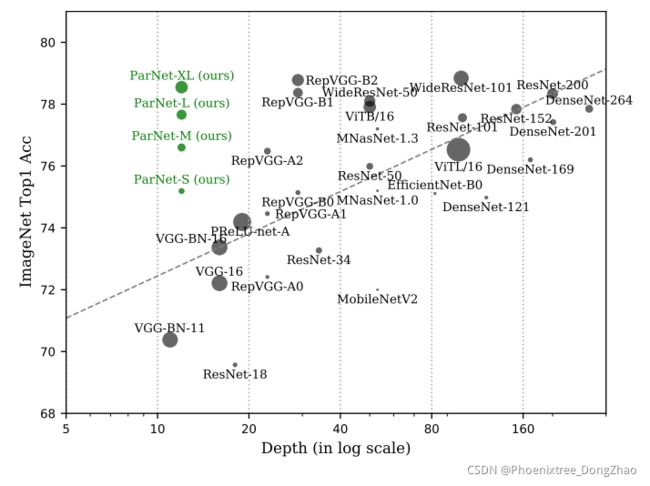
Figure 1: Top-1 accuracy on ImageNet vs. depth (in log scale) of various models.
目录
Non-deep Network
Abstract
1 Introduction
2 Related Work
3 Method
3.1 ParNet Block
3.2 Dwonsamping and Fusion Block
3.3 Network Architecture
3.4 Scaling ParNet
3.5 Practical Advantages of Parallel Architecture
4 Results
Ablation Studies
5 Ddiscussion
Abstract
Depth is the hallmark of deep neural networks. But more depth means more sequential computation and higher latency. This begs the question – is it possible to build high-performing “non-deep” neural networks?
We show that it is. To do so, we use parallel subnetworks instead of stacking one layer after another. This helps effectively reduce depth while maintaining high performance.
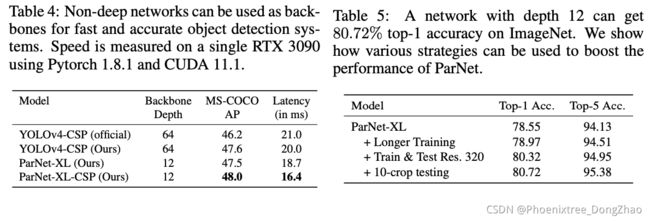
By utilizing parallel substructures, we show, for the first time, that a network with a depth of just 12 can achieve top-1 accuracy over 80% on ImageNet, 96% on CIFAR10, and 81% on CIFAR100. We also show that a network with a low-depth (12) backbone can achieve an AP of 48% on MS-COCO.
We analyze the scaling rules for our design and show how to increase performance without changing the network’s depth.
Finally, we provide a proof of concept for how non-deep networks could be used to build low-latency recognition systems.
研究动机:深度是深度神经网络的标志。但深度越大,意味着顺序计算越多,延迟也越大。这就引出了一个问题——是否有可能构建高性能的 “非深度” 神经网络?
研究方法:本文证明了这一点。为了做到这一点,本文使用并行子网,而不是一层接着一层堆叠。这有助于在保持高性能的同时有效地减少深度。
实验结果:通过利用并行子结构,首次表明,深度仅为 12 的网络可以在 ImageNet 上达到 top-1 的准确率,在 CIFAR10 上达到 96%,在 CIFAR100 上达到 81%。本文还表明,一个具有低深度(12) backbone 的网络可以在 MS-COCO 上实现 48% 的 AP。
研究结论:本文分析了该设计的伸缩规则,并展示了如何在不改变网络深度的情况下提高性能。最后,本文还提供了如何使用非深度网络构建低延迟识别系统的概念证明。
1 Introduction
Deep Neural Networks (DNNs) have revolutionized the fields of machine learning, computer vision, and natural language processing. As their name suggests, a key characteristic of DNNs is that they are deep. That is, they have a large depth, which can be defined as the length of the longest path from an input neuron to an output neuron. Often a neural network can be described as a linear sequence of layers, i.e. groups of neurons with no intra-group connections. In such cases, the depth of a network is its number of layers.
定义深度学习中深度的概念:
深度神经网络 (DNNs) 已经彻底改变了机器学习、计算机视觉和自然语言处理等领域。顾名思义,DNN 的一个关键特征是深度。也就是说,它们有一个很大的深度,可以定义为从一个输入神经元到一个输出神经元的最长路径的长度。通常,神经网络可以被描述为层的线性序列,即没有组内连接的神经元群。在这种情况下,网络的深度就是它的层数。
It has been generally accepted that large depth is an essential component for high-performing networks because depth increases the representational ability of a network and helps learn increasingly abstract features (He et al., 2016a). In fact, one of the primary reasons given for the success of ResNets is that they allow training very deep networks with as many as 1000 layers (He et al., 2016a). As such, state-of-the-art performance is increasingly achieved by training models with large depth, and what qualifies as “deep” has shifted from “2 or more layers” in the early days of deep learning to the “tens or hundreds of layers” routinely used in today’s models. For example, as shown in Figure 1, competitive benchmarks such as ImageNet are dominated by very deep models (He et al., 2016a; Huang et al., 2017; Tan & Le, 2019) with at least 30 layers, whereas models with fewer than 30 layers perform substantially worse. The best-performing model with fewer than 20 layers has a top-1 accuracy of only 75.2, substantially lower than accuracies achievable with 30 or more layers when evaluated with a single image crop (He et al., 2015; Tan & Le, 2019).
描述传统认知,为本文突破性研究成果做铺垫:
普遍认为,大深度(large depth)是高性能网络的重要组成部分,因为深度增加了网络的表征能力,并有助于学习越来越抽象的特征。事实上,ResNets 成功的主要原因之一是,它们允许训练多达 1000 层的深度网络。因此,state-of-the-art 性能越来越多地通过具有大深度的训练模型实现,而所谓的 “深度” 已经从早期深度学习的 “两层或更多层” 转变为今天模型中常规使用的 “数十或数百层”。例如,如图 1 所示,ImageNet 等竞争性基准主要由深度模型,至少有 30 层,而少于 30 层的模型表现明显差。当使用单一图像裁剪进行评估时,表现最好的小于 20 层的模型的 top-1 精度仅为 75.2,远远低于 30 层或更多层所能达到的精度。
But is large depth always necessary? This question is worth asking because large depth is not without drawbacks. A deeper network leads to more sequential processing and higher latency; it is harder to parallelize and less suitable for applications that require fast responses.
深度过深存在的缺点,因为本文动机和研究的巨大意义:
但是大深度总是必要的吗? 这个问题值得一问,因为大深度并非没有缺点。更深层次的网络会导致更多的顺序处理和更高的延迟;它很难并行化,也不太适合需要快速响应的应用程序。
In this paper, we study whether it is possible to achieve high performance with “non-deep” neural networks, especially networks with ∼10 layers. We find that, contrary to conventional wisdom, this is indeed possible. We present a network design that is non-deep and performs competitively against its deep counterparts. We refer to our architecture as ParNet (Parallel Networks). We show, for the first time, that a classification network with a depth of just 12 can achieve accuracy greater than 80% on ImageNet, 96% on CIFAR10, and 81% on CIFAR100. We also show that a detection network with a low-depth (12) backbone can achieve an AP of 48% on MS-COCO. Note that the number of parameters in ParNet is comparable to state-of-the-art models, as illustrated in Figure 1.
本文研究基本思路(平行网络)和研究成果(非深度,亦可行):
本文研究了是否有可能实现高性能的 “非深度” 神经网络,特别是具有 ~ 10 层的网络。研究发现,与传统观点相反,这确实是可能的。本文提出了一种网络设计,它是非深度的,并且在性能上与深度的对手相比具有竞争力。该体系结构称为 ParNet (平行网络)。本文首次证明,深度仅为 12 的分类网络在 ImageNet 上的准确率超过 80%,在 CIFAR10 上的准确率超过 96%,在 CIFAR100 上的准确率超过 81%。研究还表明,一个低深度 (12) backbone 的检测网络可以在 MS-COCO 上实现 48% 的 AP。请注意,ParNet 中的参数数量可以与最先进的模型相媲美,如图 1 所示。
Figure 1
A key design choice in ParNet is the use of parallel subnetworks. Instead of arranging layers sequentially, we arrange layers in parallel subnetworks. This design is “embarrassingly parallel”, in the sense that there are no connections between the subnetworks except at the beginning and the end. This allows us to reduce the depth of the network while maintaining high accuracy. It is worth noting that our parallel structures are distinct from “widening” a network by increasing the number of neurons in a layer.
ParNet not only helps us answer a scientific question about the necessity of large depth, but also offers practical advantages. Due to the parallel substructures, ParNet can be efficiently parallelized across multiple processors. We find that ParNet can be effectively parallelized and outperforms ResNets in terms of both speed and accuracy. Note that this is achieved despite the extra latency introduced by the communication between processing units. This shows that in the future, with possibly specialized hardware to further mitigate communication latency, ParNet-like architectures could be used for creating extremely fast recognition systems.
We also study the scaling rules for ParNet. Specifically, we show that ParNet can be effectively scaled by increasing width, resolution, and number of branches, all while keeping depth constant. We observe that the performance of ParNet does not saturate and increases as we increase computational throughput. This suggests that by increasing compute further, one can achieve even higher performance while maintaining small depth (∼10) and low latency.
三段,给出更多本文在技术上的创意/意义/突破:1. 关键设计;2. 实践优势;3. 模型操作(缩放规则)
ParNet 的一个关键设计选择是使用并行子网。作者不是按顺序排列层,而是在并行的子网络中排列层。这种设计是 “令人尴尬的平行”,从这个意义上说,除了开始和结束,子网之间没有连接。这使得我们可以在保持高精度的同时减少网络的深度。值得注意的是,本文平行结构不同于通过增加一层神经元的数量来 “扩大” 一个网络。
ParNet 不仅回答了关于大深度的必要性的科学问题,而且提供了实践优势。由于具有并行的子结构,ParNet 可以在多个处理器之间有效地并行化。本文发现 ParNet 可以被有效的并行化,并且在速度和准确性上都优于 ResNets。注意,尽管处理单元之间的通信带来了额外的延迟,但还是实现了这一点。这表明,在未来,可能会有专门的硬件来进一步减少通信延迟,类似 ParNet 的体系结构可以用于创建非常快速的识别系统。
本文还研究了 ParNet 的缩放规则。具体来说,本文证明了 ParNet 可以通过增加宽度、分辨率和分支数量来有效缩放,同时保持深度不变。作者观察到 ParNet 的性能并没有饱和,而是随着计算吞吐量的增加而增加。这表明,通过进一步增加计算,可以实现更高的性能,同时保持较小的深度(~ 10) 和低延迟。
To summarize, our contributions are three-fold:
• We show, for the first time, that a neural network with a depth of only 12 can achieve high performance on very competitive benchmarks (80.7% on ImageNet, 96% on CIFAR10, 81% on CIFAR100).
• We show how parallel structures in ParNet can be utilized for fast, low-latency inference.
• We study the scaling rules for ParNet and demonstrate effective scaling with constant low depth.
贡献:
• 首次证明,深度仅为 12 的神经网络可以在非常有竞争力的 benchmarks 上获得高性能。
• 展示了如何利用 ParNet 中的并行结构进行快速、低延迟的推断。
• 研究了 ParNet 的缩放规则,并证明了恒定的低深度下的有效缩放。
2 Related Work
Analyzing importance of depth
There exists a rich literature analyzing the importance of depth in neural networks. The classic work of Cybenko et al. showed that a single-layer neural network with sigmoid activations can approximate any function with arbitrarily small error (Cybenko, 1989). However, one needs to use a network with sufficiently large width, which can drastically increase the parameter count. Subsequent works have shown that, to approximate a function, a deep network with non-linearity needs exponentially fewer parameters than its shallow counterpart (Liang & Srikant, 2017). This is often cited as one of the major advantages of large depth.
Several works have also empirically analyzed the importance of depth and came to the conclusion that under a fixed parameter budget, deeper networks perform better than their shallow counterparts (Eigen et al., 2013; Urban et al., 2017). However, in such analysis, prior works have only studied shallow networks with a linear, sequential structure, and it is unclear whether the conclusion still holds with alternative designs. In this work, we show that, contrary to conventional wisdom, a shallow network can perform surprisingly well, and the key is to have parallel substructures.
分析深度的重要性:
已有大量的文献分析了深度在神经网络中的重要性。Cybenko 等人的经典工作表明,具有 sigmoid 激活的单层神经网络可以以任意小的误差近似任何函数。但是,需要使用具有足够大宽度的网络,这可能会大幅增加参数计数。后续工作表明,要逼近一个函数,具有非线性的深层网络比浅层宽度网络需要更少的参数。这通常被认为是大深度的主要优势之一。
一些研究也对深度的重要性进行了实证分析,并得出结论,在固定的参数预算下,深度网络比浅层网络表现得更好。然而,在这样的分析中,先前的工作只研究了线性顺序结构的浅层网络,不清楚这个结论是否仍然适用于其他设计。在这项工作中表明,与传统的认知相反,浅层网络可以表现得非常好,关键是要有并行的子结构。
Scaling DNNs
There have been many exciting works that have studied the problem of scaling neural networks. Tan & Le (2019) showed that increasing depth, width, and resolution leads to effective scaling of convolutional networks. We also study scaling rules but focus on the low-depth regime. We find that one can increase the number of branches, width, and resolution to effectively scale ParNet while keeping depth constant and low. Zagoruyko & Komodakis (2016) showed that shallower networks with a large width can achieve similar performance to deeper ResNets. We also scale our networks by increasing their width. However, we consider networks that are much shallower – a depth of just 12 compared to 50 considered for ImageNet by Zagoruyko & Komodakis (2016) – and introduce parallel substructures.
DNNs 的伸缩研究:
在神经网络缩放问题上已经有了许多令人兴奋的工作。Tan & Le (2019) 指出,增加深度、宽度和分辨率可以有效地缩放卷积网络。本文也研究了缩放规则,但重点是低深度机制。研究发现,在保持深度不变和较低的情况下,可以通过增加分支数量、宽度和分辨率来有效地扩展 ParNet。Zagoruyko & Komodakis (2016) 研究表明,宽度较大的较浅网络可以获得与较深的 ResNets 相似的性能。本文还通过扩大网络的宽度来扩大网络的规模。然而,本文考虑的网络要浅得多,深度仅为 12,并引入了平行子结构。而 Zagoruyko 和 Komodakis (2016) 的 ImageNet 考虑的深度为 50。
Shallow networks
Shallow networks have attracted attention in theoretical machine learning. With infinite width, a single-layer neural network behaves like a Gaussian Process, and one can understand the training procedure in terms of kernel methods (Jacot et al., 2018). However, such models do not perform competitively when compared to state-of-the-art networks (Li et al., 2019). We provide empirical proof that non-deep networks can be competitive with their deep counterparts.
浅层网络的研究:
浅网络在机器学习理论中引起了广泛的关注。单层神经网络具有无限宽,表现为高斯过程,可以用核方法来理解训练过程。然而,与最先进的网络相比,这些模型并不具有竞争力。本文提供了实证证明,非深度网络可以与深度网络竞争。
Multi-stream networks
Multi-stream neural networks have been used in a variety of computer vision tasks such as segmentation (Chen et al., 2016; 2017), detection (Lin et al., 2017), and video classification (Wu et al., 2016). The HRNet architecture maintains multi-resolution streams throughout the forward pass (Wang et al., 2020); these streams are fused together at regular intervals to exchange information. We also use streams with different resolutions, but our network is much shallower (12 vs. 38 for the smallest HRNet for classification) and the streams are fused only once, at the very end, making parallelization easier.
Multi-stream 网络的研究:
Multi-stream 神经网络已被用于各种计算机视觉任务,如分割、检测、视频分类。HRNet 架构在整个前向通道中保持多分辨率流;这些信息流定期地融合在一起以交换信息。本文也使用不同分辨率的流,但本文的网络更浅 (用于分类的最小 HRNet 是 38 层),stream 只在最后融合一次,使并行化更容易。
3 Method
In this section, we develop and analyze ParNet, a network architecture that is much less deep but still achieves high performance on competitive benchmarks. ParNet consists of parallel substructures that process features at different resolutions. We refer to these parallel substructures as streams. Features from different streams are fused at a later stage in the network, and these fused features are used for the downstream task. Figure 2a provides a schematic representation of ParNet.
本节介绍 ParNet 的开发和分析,它的深度要低得多,但在具有竞争力的 benchmarks 测试中仍然能够实现高性能。ParNet 由并行的子结构组成,以不同的分辨率处理特征。本文把这些平行的子结构称为流(stream)。来自不同流的特征在网络的后期阶段被融合,这些融合的特征用于下游任务。图 2a 提供了 ParNet 的示意图。
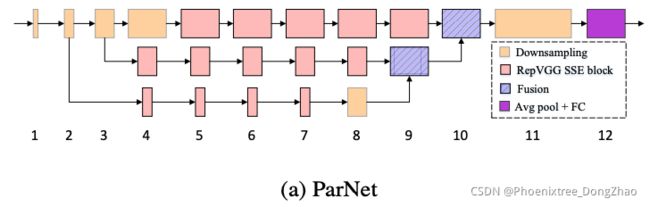
Figure 2: Schematic representation of ParNet and the ParNet block. ParNet has depth 12 and is composed of parallel substructures.
3.1 ParNet Block
该模块设计有几点考虑:
1. 基本模块用 VGG 还是 ResNet?
2. 网络太浅,接受域太小怎么办?
3. 网络太浅,非线性程度不足怎么办?
下面三段一一回答:
In ParNet, we utilize VGG-style blocks (Simonyan & Zisserman, 2015). To see whether non-deep networks can achieve high performance, we empirically find that VGG-style blocks are more suitable than ResNet-style blocks (Table 8). In general, training VGG-style networks is more difficult than their ResNet counterparts (He et al., 2016a). But recent work shows that it is easier to train networks with such blocks if one uses a “structural reparameterization” technique (Ding et al., 2021). During training, one uses multiple branches over the 3×3 convolution blocks. Once trained, the multiple branches can be fused into one 3×3 convolution. Hence, one ends up with a plain network consisting of only 3×3 block and non-linearity. This reparameterization or fusion of blocks helps reduce latency during inference.
在 ParNet 中使用了 VGG 风格的模块。为了了解非深度网络是否能够获得高性能,本文通过经验发现 VGG 风格的模块比 ResNet 风格的块更适合 (表8)。总的来说,VGG 风格的网络比 ResNet 风格的网络更难训练。但最近的研究表明,如果使用 “结构重参数化” 技术,用 VGG 这样的模块训练网络会更容易。在训练期间,在 3×3 卷积块上使用多个分支。经过训练后,多个分支可以融合成一个 3×3 卷积。因此,最终得到的是一个只包含 3×3 模块和非线性的平面网络。这种模块的重新参数化或融合有助于减少推理过程中的延迟。

We borrow our initial block design from Rep-VGG (Ding et al., 2021) and modify it to make it more suitable for our non-deep architecture. One challenge with a non-deep network with only 3×3 convolutions is that the receptive field is rather limited. To address this, we build a SkipSqueeze-Excitation (SSE) layer which is based on the Squeeze-and-Excitation (SE) design (Hu et al., 2018). Vanilla Squeeze-and-Excitation is not suitable for our purpose as it increases the depth of the network. Hence we use a Skip-Squeeze-Excitation design which is applied along-side the skip connection and uses a single fully-connected layer. We find that this design helps increase performance (Table 7). Figure 2b provides a schematic representation of our modified Rep-VGG block with the Skip-Squeeze-Excitation module. We refer to this block as the RepVGG-SSE.
本文借鉴了Rep-VGG 的初始块设计,并对其进行修改,使其更适合本文的非深度架构。一个只有 3×3 卷积的非深度网络的挑战是,接受域相当有限。为了解决这个问题,本文构建了一个基于Squeeze-and-Excitation (SE) 设计的 Skip-Squeeze-Excitation (SSE) 层。传统的 SE 法不适合本文的目的,因为它增加了网络的深度 [这个细节至关重要!!!]。因此,本文使用一个 SSE 设计,这是应用在旁边的跳跃连接和一个单一的全连接层。本文发现这种设计有助于提高性能 (表7)。图 2b 提供了带有 SSE 模块的改进 Rep-VGG 模块的示意图。本文将此模块称为 RepVGG-SSE。
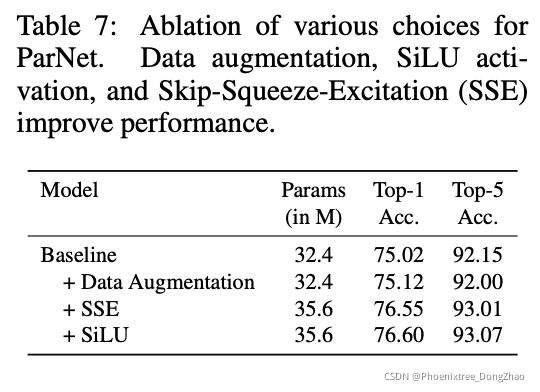
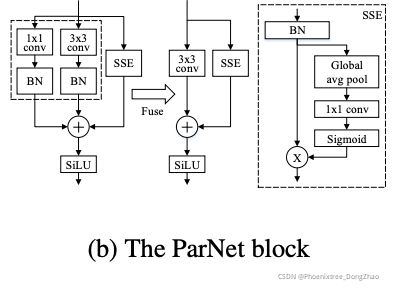
Figure 2: The ParNet block consists of three parallel branches: 1×1 convolution, 3×3 convolution and Skip-Squeeze-and-Excitation (SSE). Once the training is done, the 1×1 and 3×3 convolutions can be fused together for faster inference. The SSE branch increases receptive field while not affecting depth.
One concern, especially with large-scale datasets such as ImageNet, is that a non-deep network may not have sufficient non-linearity, limiting its representational power. Thus we replace the ReLU activation with SiLU (Ramachandran et al., 2017).
一个问题是,特别是像 ImageNet 这样的大规模数据集,非深度网络可能没有足够的非线性,限制了它的表征能力。因此,本文用 SiLU 替代了 ReLU 的激活。
3.2 Dwonsamping and Fusion Block
Apart from the RepVGG-SSE block, whose input and output have the same size, ParNet also contains Downsampling and Fusion blocks. The Downsampling block reduces resolution and increases width to enable multi-scale processing, while the Fusion block combines information from multiple resolutions.
除了输入和输出大小相同的 RepVGG-SSE 模块外,ParNet 还包含 Downsampling 和 Fusion 模块。下行采样块降低分辨率,增加宽度,以实现多尺度处理,而融合块合并来自多个分辨率的信息。
In the Downsampling block, there is no skip connection; instead, we add a single-layered SE module parallel to the convolution layer. Additionally, we add 2D average pooling in the 1×1 convolution branch. The Fusion block is similar to the Downsampling block but contains an extra concatenation layer. Because of concatenation, the input to the Fusion block has twice as many channels as a Downsampling block. Hence, to reduce the parameter count, we use convolution with group 2. Please refer to Figure A1 in the appendix for a schematic representation of the Downsampling and Fusion blocks.
在下采样模块中,没有跳过连接;相反,增加了一个单层的 SE 模块平行于卷积层。此外,在 1×1 卷积分支中添加了 2D 平均池化。
融合模块类似于下采样模块,但包含一个额外的连接层。由于连接,Fusion 模块的输入通道是Downsampling 模块的两倍。因此,为了减少参数计数,使用与组卷积,其中 group=2。请参阅附录中的图 A1,了解下采样和融合模块块的示意图。

3.3 Network Architecture
网络结构介绍:不同数据集采用了不同的网络结构
Figure 2a shows a schematic representation of the ParNet model that is used for the ImageNet dataset. The initial layers consist of a sequence of Downsampling blocks. The outputs of Downsampling blocks 2, 3, and 4 are fed respectively to streams 1, 2, and 3. We empirically find 3 to be the optimal number of streams for a given parameter budget (Table 10). Each stream consists of a series of RepVGG-SSE blocks that process the features at different resolutions. The features from different streams are then fused by Fusion blocks using concatenation. Finally, the output is passed to a Downsampling block at depth 11. Similar to RepVGG (Ding et al., 2021), we use a larger width for the last downsampling layer. Table A1 in the appendix provides a complete specification of the scaled ParNet models that are used in ImageNet experiments.
用于 ImageNet 数据集的 ParNet 模型
如图 2a 所示。初始层由一系列下采样块组成。下采样模块 2、3 和 4 的输出分别被 feed 到 streams 1、2 和 3。根据经验发现,对于给定的参数预算,最优流数选择 3 个流 (表10)。每个流由一系列 RepVGG-SSE 块组成,以不同的分辨率处理特征。来自不同流的特征然后被使用连接的 Fusion 块融合。最后,输出被传递到深度11的下采样块。与RepVGG (Ding et al., 2021)类似,我们对最后的下采样层使用了更大的宽度。附录中的表 A1 提供了ImageNet实验中使用的缩放ParNet模型的完整规范。
Figure 2
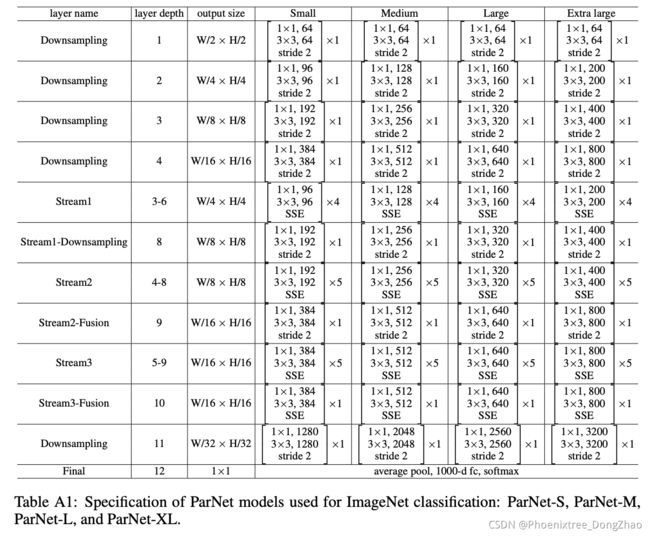
In CIFAR the images are of lower resolution, and the network architecture is slightly different from the one for ImageNet. First, we replace the Downsampling blocks at depths 1 and 2 with RepVGGSSE blocks. To reduce the number of parameters in the last layer, we replace the last Downsampling block, which has a large width, with a narrower 1×1 convolution layer. Also, we reduce the number of parameters by removing one block from each stream and adding a block at depth 3.
用于 CIFAR 数据集的 ParNet 模型
在 CIFAR 中,图像的分辨率较低,网络架构与 ImageNet 略有不同。首先,用 RepVGG-SSE 模块替换深度 1 和 2 的 Downsampling 模块。为了减少最后一层的参数数量,将最后一个宽度较大的Downsampling 模块替换为更窄的 1×1 卷积层。此外,还通过从每个流中删除一个块并添加深度为 3 的模块来减少参数的数量。
3.4 Scaling ParNet
With neural networks, it is observed that one can achieve higher accuracy by scaling up network size. Prior works (Tan & Le, 2019) have scaled width, resolution, and depth. Since our objective is to evaluate whether high performance can be achieved with small depth, we keep the depth constant and instead scale up ParNet by increasing width, resolution, and the number of streams.
For CIFAR10 and CIFAR100, we increase the width of the network while keeping the resolution at 32 and the number of streams at 3. For ImageNet, we conduct experiments by varying all three dimensions (Figure 3).
使用神经网络,可以观察到通过扩大网络规模可以获得更高的精度。之前的作品 (Tan & Le, 2019)已经缩放了宽度、分辨率和深度。由于本文的目标是评估是否可以在较小的深度下实现高性能,因此保持深度不变,而不是通过增加宽度、分辨率和流的数量来扩大 ParNet。
对于 CIFAR10 和 CIFAR100,本文增加了网络的宽度,同时保持分辨率为 32,流的数量为 3。对于 ImageNet,通过改变所有三个维度来进行实验 (图 3)。
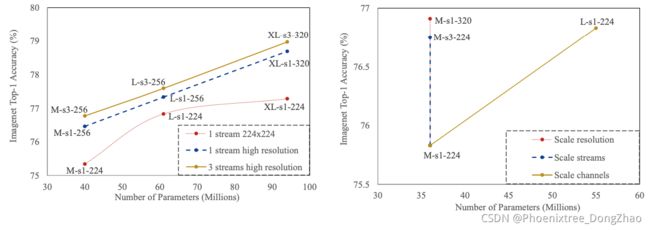
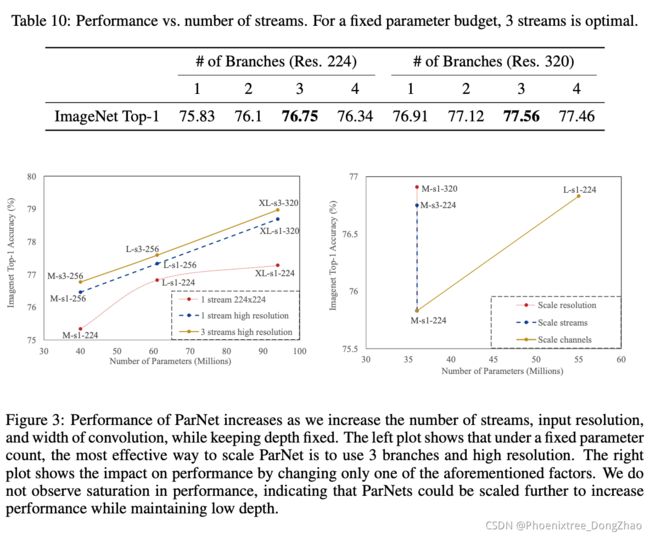
Figure 3:Performance of ParNet increases as we increase the number of streams, input resolution, and width of convolution, while keeping depth fixed. The left plot shows that under a fixed parameter count, the most effective way to scale ParNet is to use 3 branches and high resolution. The right plot shows the impact on performance by changing only one of the aforementioned factors. We do not observe saturation in performance, indicating that ParNets could be scaled further to increase performance while maintaining low depth.
3.5 Practical Advantages of Parallel Architecture
本节从实际的硬件应用角度,分析了本文平行结构的优势。
The current process of 5 nm lithography is approaching the 0.5 nm size of the silicon crystal lattice, and there is limited room to further increase processor frequency. This means that faster inference of neural networks must come from parallelization of computation.
The growth in the performance of single monolithic GPUs is also slowing down (Arunkumar et al., 2017). The maximum die size achievable with conventional photolithography is expected to plateau at ∼800mm^2 (Arunkumar et al., 2017). On the whole, a plateau is expected not only in processor frequency but also in the die size and the number of transistors per processor.
目前的 5 纳米光刻工艺正在接近 0.5 纳米尺寸的硅晶格,进一步增加处理器频率的空间有限。这意味着更快的神经网络推断必须来自并行计算。
单片 GPU 的性能增长也在放缓 (Arunkumar et al., 2017)。传统光刻可实现的最大模具尺寸预计将稳定在 ~ 800mm^2 (Arunkumar et al., 2017)。总的来说,预计不仅在处理器频率上,而且在模具尺寸和每个处理器的晶体管数量上都将达到一个平台。
To solve this problem, there are suggestions for partitioning a GPU into separate basic modules that lie in one package. These basic modules are easier to manufacture than a single monolithic GPU on a large die. Large dies have a large number of manufacturing faults, resulting in low yields (Kannan et al., 2015). Recent work has proposed a Multi-Chip-Module GPU (MCM-GPU) on an interposer, which is faster than the largest implementable monolithic GPU. Replacing large dies with mediumsize dies is expected to result in lower silicon costs, significantly higher silicon yields, and cost advantages (Arunkumar et al., 2017).
为了解决这个问题,有人建议将 GPU 划分为单独的基本模块,这些模块位于一个包中。这些基本模块比在大型模具上制作单个单片 GPU 更容易。大型模具有大量的制造缺陷,导致低产量(Kannan et al., 2015)。最近的工作提出了一种基于插入器的多芯片模块 GPU (MCM-GPU),它比最大的可实现单片 GPU 更快。用中型模具替换大型模具有望降低硅成本,显著提高硅产量和成本优势 (Arunkumar et al., 2017)。
Even if several chips are combined into a single package and are located on one interposer, the data transfer rate between them will be less than the data transfer rate inside one chip, because the lithography size of the chip is smaller than the lithography size of the interposer. Such chip designs thus favor partitioned algorithms with parallel branches that exchange limited data and can be executed independently for as long as possible. All these factors make non-deep parallel structures advantageous in achieving fast inference, especially with tomorrow’s hardware.
即使将多个芯片组合成一个封装,并位于一个插入器上,它们之间的数据传输速率也会小于一个芯片内部的数据传输速率,因为芯片的光刻尺寸小于插入器的光刻尺寸。因此,这种芯片设计倾向于使用并行分支的分区算法,交换有限的数据,并可以尽可能长时间地独立执行。所有这些因素使得非深度并行结构在实现快速推断方面具有优势,特别是在未来的硬件环境中。
4 Results
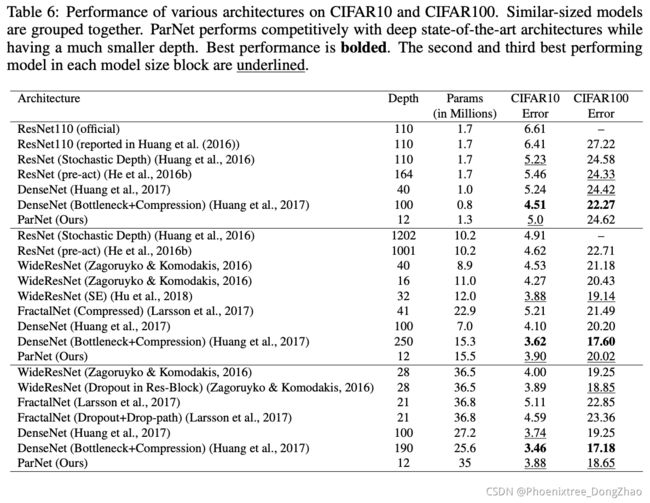
Ablation Studies
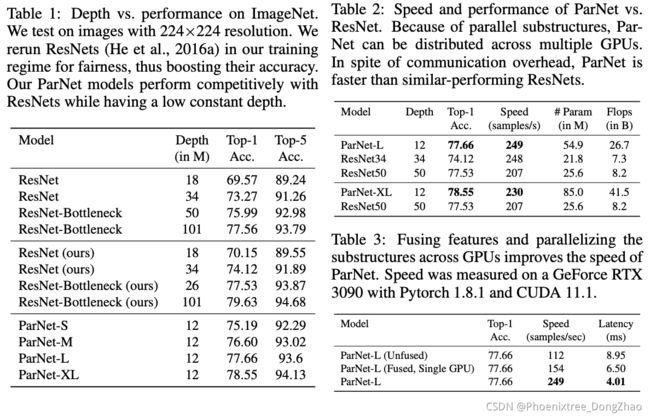
To test if we can trivially reduce the depth of ResNets and make them wide, we test three ResNet variants: ResNet12-Wide, ResNet14-Wide-BN, and ResNet12-Wide-SSE. ResNet12-Wide uses the basic ResNet block and has depth 12, while ResNet14-Wide-BN uses the bottleneck ResNet block and has depth 14. Note that with the bottleneck ResNet block, one cannot achieve a depth lower than 14 while keeping the original ResNet structure as there has to be 1 initial convolution layer, 4 downsampling blocks (3 × 4 = 12 depth), and 1 fully-connected layer.
We find that ResNet12-Wide outperforms ResNet14-Wide-BN with the same parameter count. We additionally add SSE block and SiLU activation to ResNet12-Wide to create ResNet12-Wide-SSE to further control for confounding factors.
We find that ParNet-M outperforms all the ResNet variants which have depth 12 by 2.7 percentage points, suggesting that trivially reducing depth and increasing width is not as effective as our approach.
We show that the model with three branches performs better than a model with a single branch.
We also show that with everything else being equal, using VGGstyle blocks leads to better performance than the corresponding ResNet architecture. Architectural choices in ParNet like parallel substructures and VGG-style blocks are crucial for high performance at lower depths.
为了测试是否可以简单地减小 ResNet 的深度并使其变宽,本文测试了三种 ResNet 变体:ResNet12-Wide、ResNet14-Wide-BN 和 ResNet12-Wide-SSE。ResNet12-Wide 使用基本ResNet block,深度为 12,而 ResNet14-Wide-BN 使用瓶颈 ResNet block,深度为 14。注意,使用瓶颈 ResNet block,在保持原始 ResNet 结构的情况下,不能实现深度低于 14,因为必须有 1 个初始卷积层,4 个下采样 block (3 × 4 = 12 深度),和 1 个全连接层。
本文发现在相同的参数计数下,ResNet12-Wide 的性能优于 ResNet14-Wide-BN。在 ResNet12-Wide 中添加 SSE block 和 SiLU 激活,以创建 ResNet12-Wide-SSE,进一步控制混杂因素。
本文还发现,ParNet-M 比所有深度为 12 的 ResNet 变体的性能高出 2.7 个百分点,这表明简单地减少深度和增加宽度不如本文的方法有效。
本文证明了有三个分支的模型比只有一个分支的模型性能更好。
本文还表明,在其他条件相同的情况下,使用 VGG-style block 会比相应的 ResNet 体系结构带来更好的性能。ParNet 中的结构选择,如并行子结构和 VGG 风格的块,对于较低深度的高性能至关重要。
Table 7 reports ablation studies over various design choices for our network architecture and training protocol. We show that each of the three decisions (rand-augment data augmentation, SiLU activation, SSE block) leads to higher performance. Using all three leads to the best performance.
In Table 10, we evaluate networks with the same total number of parameters but with different numbers of branches: 1, 2, 3, and 4. We show that for a fixed number of parameters, a network with 3 branches has the highest accuracy and is optimal in both cases, with a network resolution of 224x224 and 320x320.
表 7 说明了针对本文的网络架构和训练协议的各种设计选择的消融研究。实验表明,这三种决策(rand-augment data enhancement, SiLU activation, SSE block) 中的每一种都能带来更高的性能。使用这三种方法可以获得最佳性能。
在表 10 中,评估了总参数数相同但分支数不同的网络: 1、2、3 和 4。实验表明,对于固定数量的参数,具有 3 个分支的网络具有最高的精度,并且在这两种情况下都是最佳的,网络分辨率分别为 224x224 和 320x320。

ParNet vs. Ensembles
Another approach to network parallelization is the creation of ensembles consisting of multiple networks. Therefore, we compare ParNet to ensembles. In Table 9, we find that ParNet outperforms ensembles while using fewer parameters.
网络并行化的另一种方法是创建由多个网络组成的集成。因此,将 ParNet 与 Ensemble 进行比较。在表 9 中,发现当使用更少的参数时,ParNet 的性能优于 ensemble。
Scaling ParNet
Neural networks can be scaled by increasing resolution, width, and depth (Tan & Le, 2019). Since we are interested in exploring the performance limits of constant-depth networks, we scale ParNet by varying resolution, width, and the number of streams. Figure 3 shows that each of these factors increases the accuracy of the network.
Also, we find that increasing the number of streams is more cost-effective than increasing the number of channels in terms of accuracy versus parameter count.
Further, we find that the most effective way to scale ParNet is to increase all three factors simultaneously. Because of computation constraints, we could not increase the number of streams beyond 3, but this is not a hard limitation. Based on these charts, we see no saturation in performance while scaling ParNets. This indicates that by increasing compute, one could achieve even higher performance with ParNet while maintaining low depth.
神经网络可以通过增加分辨率、宽度和深度进行缩放。由于本文对探索恒定深度网络的性能限制感兴趣,本文通过改变分辨率、宽度和流的数量来扩展 ParNet。图 3 显示了这些因素中的每一个都提高了网络的准确性。
此外,实验发现,从准确性和参数计数的角度来看,增加流的数量比增加通道的数量更划算。
此外,发现,扩大 ParNet 的最有效的方法是同时增加这三个因素。由于计算限制,不能将流的数量增加到 3 个以上,但这不是硬性限制。根据这些图表,可以看到在扩展 ParNets 时性能没有饱和。这表明,通过增加计算,可以在保持较低深度的情况下使用 ParNet 实现更高的性能。
5 Ddiscussion
We have provided the first empirical proof that non-deep networks can perform competitively with their deep counterparts in large-scale visual recognition benchmarks. We showed that parallel substructures can be used to create non-deep networks that perform surprisingly well. We also demonstrated ways to scale up and improve the performance of such networks without increasing depth.
Our work shows that there exist alternative designs where highly accurate neural networks need not be deep. Such designs can better meet the requirements of future multi-chip processors. We hope that our work can facilitate the development of neural networks that are both highly accurate and extremely fast.
本文提供了第一个经验证明,非深度网络可以在大规模视觉识别基准测试中与深度网络竞争。本文展示了并行子结构可以用来创建性能惊人的非深度网络。本文还演示了如何在不增加深度的情况下扩大和改进此类网络的性能。
本工作表明,在高精确度的神经网络不需要深度的情况下,存在其他的设计方案。这样的设计可以更好地满足未来多芯片处理器的需求。希望本文的工作可以促进神经网络的发展,既高度精确又极其快速。