redis 发布和订阅 持久化 事务 缓存问题
redis的发布订阅 使用数据类型lists
原理
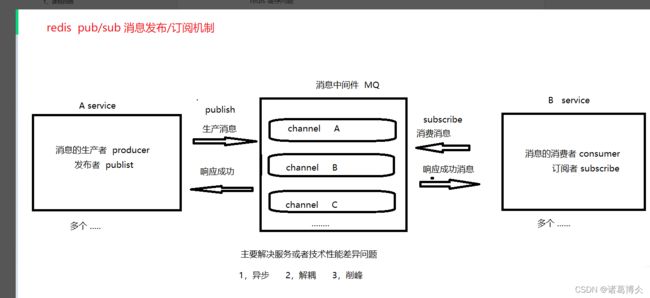
可以有多个消费者和订阅者
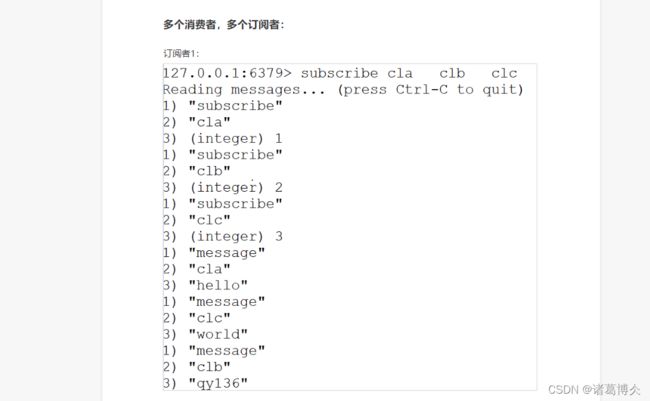
订阅者:subscribe cla 命令
执行成功后
subscribe :表示成功订阅到响应
第二个元素:提供的频道
第三个参数代表订阅频道的数量
message:这是另一个客户端发出来的发布命令的结果
第二个元素:来源频道的名称
第三个参数:实际消息的内容
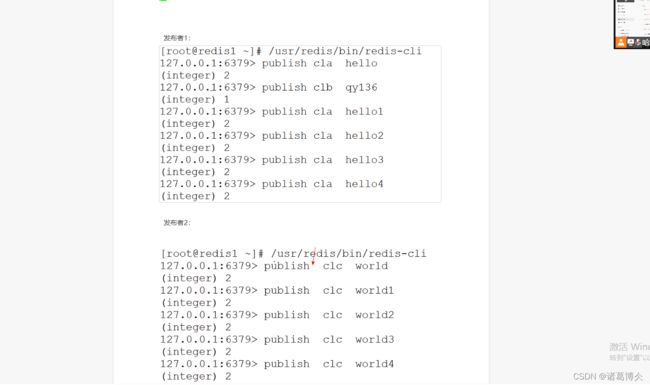
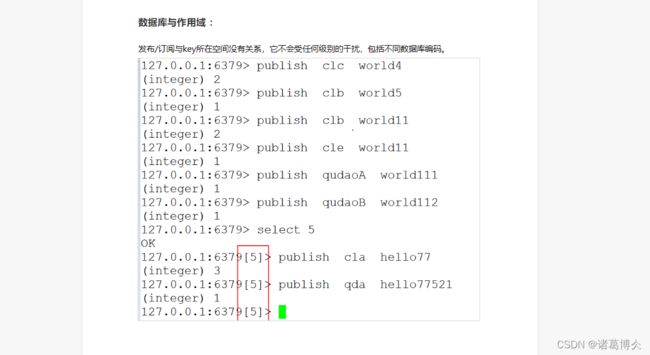
发布者:publish cla ‘hello world’(字符间有空格要加上引号,否则会报错)
对应发布频道的内容打不成功会返回频道有几个数据
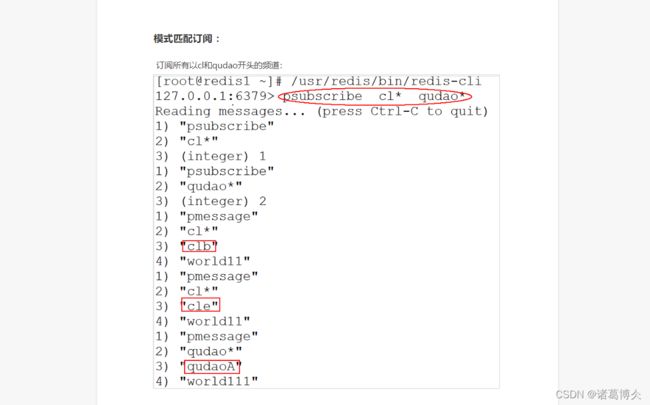
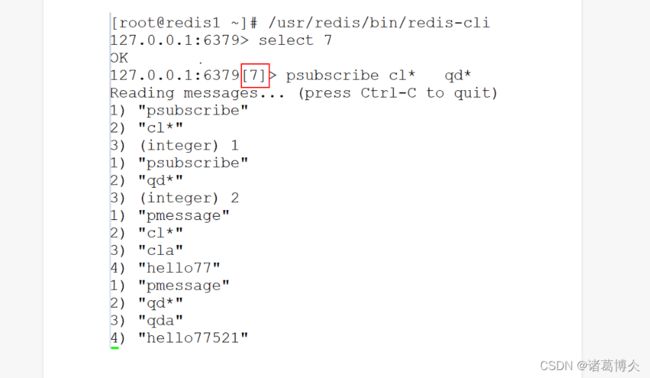
匹配订阅:psubcribe cl* qudao* (模糊匹配查看这两个包含名称的频道的订阅内容)
数据库与作用域:发布或者订阅与key所在的空间没有关系,不会受任何级别的干扰,包括数据库编码
redis的持久化
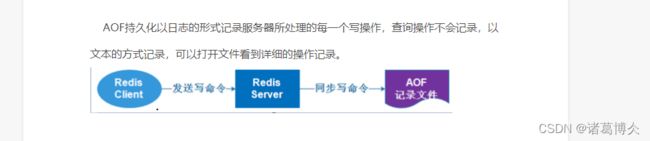
redis提供了两种方式进行持久化,一种是RDB(redis database)持久化(原理是将Redis在内存中的数据记录定时dump到磁盘上的RDB持久化),另一种是AOF持久化(原理是将Redis的写操作日志(“set aaa 111 " " lpush lista 1112”…)一追加的形式写入文件
区别:
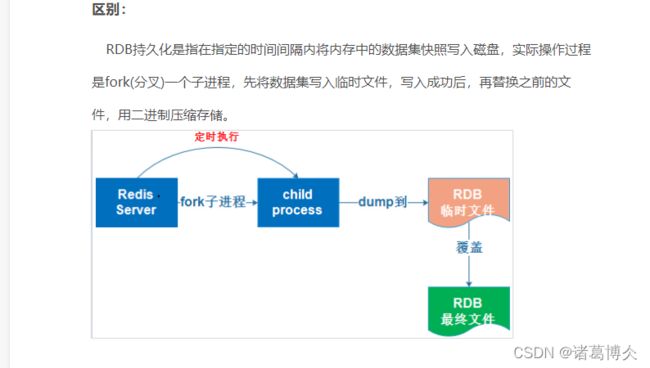
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘,实际操作过程中是fork一个子进程,先将数据集写入临时文件,写入成功后,再替换之前的文件,用二进制进行压缩存储
RDB具体实现:
在这个配置文件中
vim /usr/redis/bin/redis.conf
:196
#after 900 sec (15 min) if at least 1 key changed 在15分钟之内,如果有一个key发生变化都会发生一次RDB save 900 1
#after 300 sec (5 min) if at least 10 keys changed 在5分钟之内,如果有10个key发生变化都会发生一次RDBsave 300 10
#after 60 sec if at least 10000 keys changed 在一分钟之内,如果有10000个key发生变化都会发生一次RDB save 60 10000
每秒中最多执行81000次
生成的快照文件为
The filename where to dump the DB :253 dbfilename dump.rdb 在启动redis服务的位置会生成该文件
AOF具体实现:
vim /usr/redis/bin/redis.conf
:699 appendoly no 如果要开启aof需要修改配置为yes
:703 append only “appendonly.aof” aop写命令存储的文件
:705 aof具体配置
aof redis默认支持三种方式:
no: don’t fsync, just let the OS flush the data when it wants. Faster. 从来不执行aof 速度最快,最不安全(数据丢失时,就找不回来)
always: fsync after every write to the append only log. Slow, Safest. 每一个写命令执行完成后都把命令追加到appendonly.aof 速度最慢,最安全(数据一条都不会丢失)
everysec: fsync only one time every second. Compromise. 系统默认,即不是使用no也不使用always使用协调的方式 每一秒执行一次aof
:729 appendfsync everysec 默认的方式
优缺点:
RDP优点:
1.RDB是一个非常紧凑的文件,他保存了某个时间点的数据集,适合数据集的被备份,可以每小时保存前24小时的数据,同时每天保存过去30天的数据,这样即使出了问题也可以根据需求恢复到不同版本的数据集
2. RDB是一个紧凑单一的文件,方便传送到另一个远端数据中心,或者亚马逊s3,适用于发生灾难恢复
3. RDB在保存RDB文件时父进程要做的就是fork一个子进程,在接下来的工作全部交给子进程来做,父进程不需要再左其它的IO操作,所以RDB持久化方式可以最大化redis的性能,与AOF相比,在恢复大数据集的时候,RDB的方式会更快一些
RDB缺点:
1.由于redis的保存方式,在redis突然停止工作的话,无法做到丢失的数据最少,虽然可以配置不同的save时间点保存,但是redis想要完整保存整个数据是一个比较繁重的工作,通常都是选择5分钟或者更久完整保存一次,但是如果宕机的话这几分钟的数据就会丢失,81000次每秒的写入会损失很大。
2.RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,子进程非常耗时,可能导致redis在毫秒级内不能响应客户端的请求,如果数据集巨大并且CPU性能不是很好的情况下,这种情况会持续一秒,客户端一秒不能响应是非常恐怖的,虽然AOF也需要fork,但是你可以调节重写日志文件的频率来提高数集的耐久度
AOF的优点:
1.使用AOF会让Redis更加耐久:
使用不同的fsync策略:无fync ,每秒fync ,每次写的时候fync,
使用默认fync策略,Redis的性能依然很好(fync是后台进程处理的,主线程会尽力处理客户端请求),一旦故障,最多损失一秒的数据。
2.AOF文件是一个只进行追加的日志文件,所以不需要写入seek,,即使因为某些原因(磁盘空间满了,写的过程宕机了等)未执行完整的写入命令,也可以使用redis-check-aof工具修复这些问题,Redis可以在Aof文件体积变得过大时,自动地在后台对AOF进行重写,重写后新的AOF文件包含了当前数据集所需要的最小的命令的文件的集合。整个重写的操作绝对是安全的,在Redis创建新的AOF文件的过程中,会继续将命令追加到现有的AOF文件中,,即使重写过程中停机,现有的AOF文件也不会丢失,而一旦新AOF文件创建完毕,Reids就会从旧AOF文件切换到新的AOF文件,并且对新的AOF进行追加操作。
3.AOF文件有序地保存了对数据库执行的所有写操作,这些写入操作以Redis协议的格式保存,因此AOF文件非常容易读懂,到处AOF文件也非常简单:举个例子,如果不小心执行了FLUSHALL命令,但是只要AOF文件未被重写,AOF文件未被重写,那么只要停止服务器,移除AOF文件末尾的FLUSHALL命令,并重启Redis,就可以将数据集恢复到FLUSHALL执行状态之前
AOF缺点:
1.对于相同的数据集来说,AOF文件的体积通常要大于RDB文件的体积。
2.根据使用的fsync策略,AOF速度会慢于RDB。一般情况下,每秒fsync的性能依然非常高,而关闭fsync可以让AOF的速度和RDB一样快,即使在高负荷之下也是如此,但是巨大的写处理时,RDB可以提供更有保证的最大延迟时间。
RDB和AOP同时开启时,默认会使用AOF:
你也可以同时开启两种持久化方式, 在这种情况下, 当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整
Redis事务
事务概念:
1.事务是一个单独的隔离操作:事务中的所有命令都会序列化,按顺序的执行。事务在执行过程中,不会被其它客户端打送过来的命令请求打断。
2.事务是一个原子操作:事务中的命令要么全部执行,要么全部不执行。
事务的相关命令:
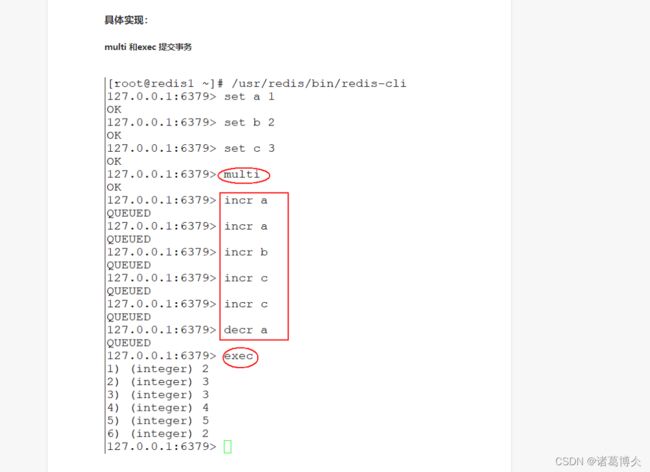
MULTI:命令用于开启一个事务,他总是返回OK。MULTI执行之后,客户端可以继续向服务器发送任意多条命令,但是不会立即被执行,而是被放到一个队列中,当EXEC命令被调用时,所有队列中的命令才会被执行。
EXEC:执行所有事务块内的命令,返回事务块内搜友命令的返回值,按命令执行的先后顺序排列,当操作被打断时,返回控制nil
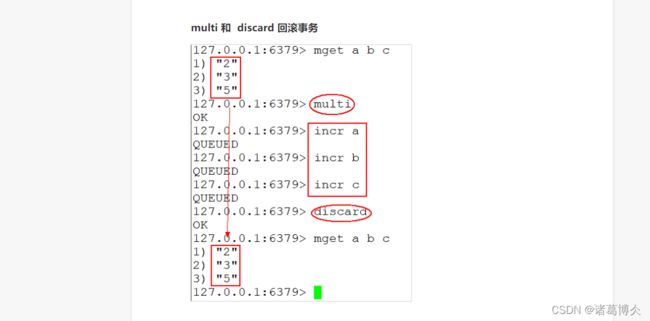
DISCARD:当执行DISCARD命令时,事务会被抛弃,事务队列会被清空,并且客户端会从事务状态中退出
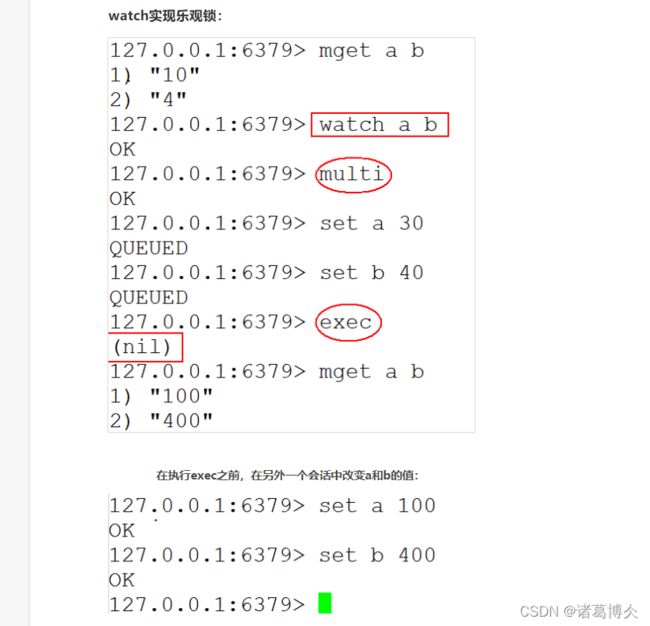
WATCH:命令可以为Redis事务提供check-and-set (CAS)行为,可以监控一个或者多个键,一旦其中有一个键被修改或者删除,之后的事务就不会执行,监控一致持续EXEC命令。

缓存问题:
缓存穿透:
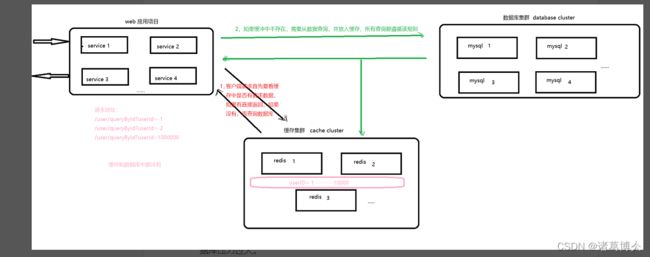
缓存穿透是指缓存区和数据库中都没有的数据,而用户不断发起请求,如发起id为-1的数据或者id为特别大不存在的数据,这是的用户很可能就是攻击者,攻击会导致数据库压力过大。
解决办法:
1.对查询结果为空的情况进行缓存,缓存时间短一点,该key对应的数据新增后进行清理缓存。
2.对一定不存在的key进行过滤,可以把所有的可能存在的key放到一个Bigtmap中(布隆过滤器),查询时通过该bitmap过滤
缓存击穿:
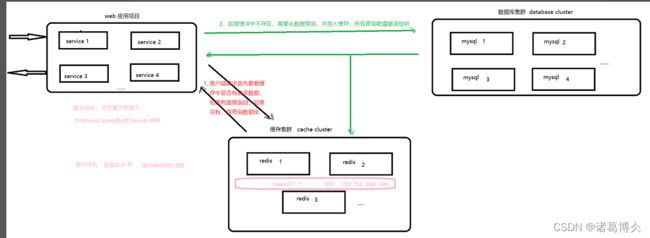
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力
如何避免?
设置热点数据永远不过期。加互斥锁,互斥锁参考思路如下
1)缓存中有数据,直接返回结果了
2)缓存中没有数据,第1个进入的线程,获取锁并从数据库去取数据,没释放锁之前,其他并行进入的线程会等待100ms,再重新去缓存取数据。这样就防止都去数据库重复取数据,重复往缓存中更新数据情况出现。
缓存雪崩:
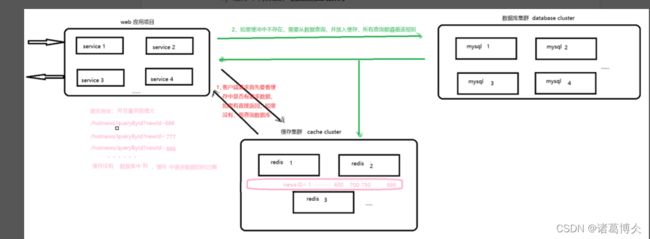
缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至down机。和缓存击穿不同的是, 缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库。
如何避免?
缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中。
设置热点数据永远不过期。