近日举办的 Databricks Data & AI Summit 2022 上,来自 Intel 的陈韦廷和来自 Kyligence 的张智超共同分享了 Intel 和 Kyligence 两家企业自 2021 年合作共建的全新开源项目「Gluten」。这也是 Gluten 首次在全球平台上亮相,今天我们将一起通过本文进一步了解 Gluten。
Gluten 项目旨在为 Apache Spark 注入 Native Vectorized Execution 的能力,极大优化 Spark 的执行效率和成本。目前,Gluten 社区的主要参与方有 Intel、Kyligence 等。
“ Kyligence 企业级产品源自 Apache Kylin,今天,两者在离线数据处理、即时查询分析等方面,都深度集成了 Spark 的能力。通过 Gluten 这一开源项目,Kylin 和 Kyligence 企业级产品将有效提升 OLAP 查询性能和执行效率,尤其是在云原生版本 Kyligence Cloud 中,将更大程度地降低整体拥有成本(TCO),提高云端数据分析的成本效率,加速大型客户从传统数据分析架构转向云原生数据湖架构的进程。”
——Kyligence 联合创始人兼 CTO 李扬
1. 为什么需要 Gluten
近年来,随着 IO 技术的提升,尤其是 SSD 和万兆网卡的普及,大家基于 Apache Spark 的数据负载场景遇到越来越多的 CPU 计算瓶颈,而不是传统认知中的 IO 瓶颈。而众所周知,基于 JVM 进行 CPU 指令的优化比较困难,因为 JVM 提供的 CPU 指令级的优化(例如 SIMD)要远远少于其他 Native 语言(例如 C++)。
同时,大家也发现目前开源社区已经有比较成熟的 Native Engine(例如 ClickHouse、Velox),具备了优秀的向量化执行(Vectorized Execution)能力,并被证明能够带来显著的性能优势,然而它们往往游离于 Spark 生态之外,这对已经严重依赖 Spark 计算框架、无法接受大量运维和迁移成本的用户而言不够友好。Gluten 社区希望能够让 Spark 用户无需迁移,就能享受这些成熟的 Native Engine 带来的性能优势。
无独有偶,前不久 Databricks 在 SIGMOD 2022 发表了一篇关于 Photon 项目的文章“Photon: A Fast Query Engine for Lakehouse Systems”[1],文章详细描述了 Databricks 如何在 Apache Spark 中集成 Photon 这一 Native 子系统,通过向量化执行等方面的优化,为 Apache Spark 带来执行性能的大幅提升。Gluten 项目在 Photon 公开前就已独立地立项和启动,不过我们看到在实现思路和加速效果上两者具有一定的相似性。
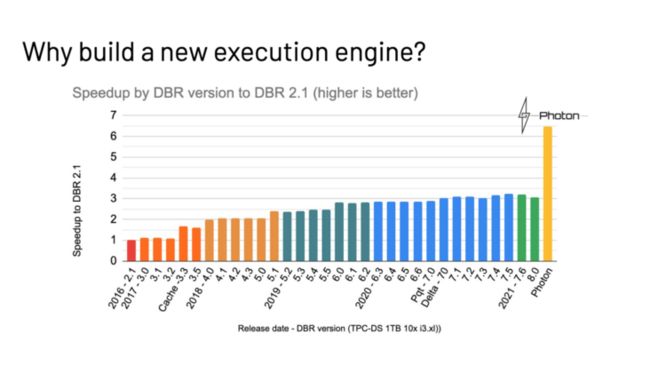
下图来自 Databricks 公开的演讲材料[2],从图中可以看出引入 Native Vectorized 引擎(Photon)的性能收益,胜过过去 5 年来所有性能优化的总和。而性能的提升又可以带来 Spark 使用体验的提升和 IT 成本的下降,这一点在企业用户动辄使用成百上千台服务器用来运行 Spark 作业的今天,是非常诱人的进步。目前 Photon 并不开源,因此 Gluten 项目可以很好地填补行业在这里的空白。
2. Gluten 项目是什么?
Gluten 这个单词在拉丁文中有胶水的意思,Gluten 项目的作用也正像胶水一样,主要用于“粘合” Apache Spark 和作为 Backend 的 Native Vectorized Engine。Backend 的选项有很多,目前在 Gluten 项目中已经明确开始支持的有 Velox[3]、Clickhouse 和 Apache Arrow。
从这个定位出发,我们结合下图可以大致看到 Gluten 项目需要提供哪些能力:

2.1 Plan Conversion & Fallback
这是 Gluten 最核心的能力,简单来讲就是通过 Spark Plugin 的机制,把 Spark 查询计划拦截并下发给 Native Engine 来执行,跳过原生 Spark 不高效的执行路径。整体的执行框架仍沿用 Spark 既有实现,包括消费接口、资源和执行调度、查询计划优化、上下游集成等。
一般来讲,Native Engine 的能力,无法 100% 覆盖 Spark 查询执行计划中的算子,因此 Gluten 必须分析 Spark 查询执行计划中哪些算子是可以下推给 Native Engine 的,并将这些相邻的、可下推的算子封装成一个 Pipeline,序列化并发送给 Native Engine 来执行并返回结果。我们依赖了一个独立的名为 substrait 的开源项目[4],其使用 protobuf 来实现引擎中立的查询计划的序列化。
对于 Native Engine 无法承接的算子,Gluten 安排 fallback 回正常的 Spark 执行路径进行计算。Databricks 的 Photon 目前也只是支持了部分 Spark 算子,应该是采用了类似的做法。
在线程模型的角度,Gluten 使用以 JNI 调用 Library 的形式,在 Spark Executor Task 线程中直接调用 Native 代码,并且严格控制 JNI 调用的次数。因此,Gluten 并不会引入复杂的线程模型,具体示意可参考下图:

2.2 Memory Management
由于 Native 代码和 Spark Java 代码在同一个进程中运行,因此 Gluten 具备了统一管理 Native 空间和 JVM 空间内存的条件。在 Gluten 中,Native 空间的代码在申请内存的时候,会先向本地的 Memory Pool 申请内存,如果内存不足,会进一步向 JVM 中 Task Memory Manager 申请内存配额,得到相应配额后才会在 Native 空间成功申请下内存。通过这种方式,Native 空间的内存申请也受到 Task Memory Manager 的统一管理。当发生内存不足的现象时,Task Memory Manager 会触发 spill,不管是 Native 还是 JVM 中的 operator 在收到 spill 通知时都会释放内存。

2.3 Columnar ShuffleShuffle
本身就是影响性能的重要一环,由于 Native Engine 大多采用列式(Columnar)数据结构暂存数据,如果简单的沿用 Spark 的基于行数据模型的 Shuffle,则会在 Shuffle Write 阶段引入数据列转行的环节,在 Shuffle Read 阶段引入数据行转列的环节,才能使数据可以流畅周转。但是无论行转列,还是列转行的成本都不低。因此,Gluten 必须提供完整的 Columnar Shuffle 机制以避开这里的转化开销。
和原生 Spark 一样,Columnar Shuffle 也需要支持内存不足时的 spill 操作,优先保证查询的健壮性。
2.4 Compatibility
用户出于所在公司技术栈的考虑,可能会偏向使用兼容不同的 Native Engine。因此,Gluten 有必要定义清晰的 JNI 接口,作为 Spark 框架和底层 Backend 通信的桥梁。这些接口用来满足请求传递、数据传输、能力检测等多个方面的需求。开发者只需要实现这些接口,并满足相应的语义保障,就能利用 Gluten 完成 Spark 和 Native Engine 的“粘合”工作。在 Spark 一侧, 目前的架构设计中也预留的 Shim Layer 用来适配支持不同版本的 Spark。
2.5 其他方面的优化除了使用
Native 代码挖掘向量化执行的性能收益,Photon 的性能收益也来源于其他方面的优化(主要是查询优化器),不过这些优化很多并未开源,Gluten 项目也在不断吸纳这部分的开源版本的优化。
3. Status & Roadmap
目前 Gluten 社区已经完成 Velox Backend 和 Clickhouse Backend 在 TPC-H 数据集上的验证工作。两种 backend 在 TPC-H 1000 数据集下的性能表现如下图所示,可以看到无论是哪种 backend,都收获了较为显著的性能提升。对于所有 TPC-H 的所有查询,我们仅通过简单的集成,在并没有对 backend 做深度定制的前提下就能普遍获得大于两倍的性能提升,这是非常令人振奋的。


接下来,我们将围绕以下方面展开 Gluten 社区的工作:
- 完成在 TPC-DS 数据集上的验证和性能测试工作
- 完善数据类型和函数的支持工作
- 完善数据源对接、数据源格式的支持工作
- 完善 CICD 流程和测试覆盖
- 尝试 Remote Shuffle Service 的对接工作
- 尝试其他硬件加速的工作
希望越来越多的同学们关注 Gluten 社区的进展,并使用和贡献到这个项目,我们的项目地址是:https://github.com/oap-projec...,如果你喜欢这个项目,别忘了在 Github 上给我们点个
想了解更多关于 Gluten 的信息,欢迎大家点击链接 预约 报名参加 7月21日举办的 Data & AI Meetup,我们将带来对 Gluten 的首发中文解读,更多精彩内容周四见~
关于Kyligence
上海跬智信息技术有限公司 (Kyligence) 由 Apache Kylin 创始团队于 2016 年创办,致力于打造下一代企业级智能多维数据库,为企业简化数据湖上的多维数据分析(OLAP)。通过 AI 增强的高性能分析引擎、统一 SQL 服务接口、业务语义层等功能,Kyligence 提供成本最优的多维数据分析能力,支撑企业商务智能(BI)分析、灵活查询和互联网级数据服务等多类应用场景,助力企业构建更可靠的指标体系,释放业务自助分析潜力。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售等行业客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、Costa、UBS、MetLife 等全球知名企业,并和微软、亚马逊、华为、Tableau 等技术领导者达成全球合作伙伴关系。目前公司已经在上海、北京、深圳、厦门、武汉及美国的硅谷、纽约、西雅图等开设分公司或办事机构。