在Ubuntu20.04上训练YOLOv4-tiny
在Ubuntu20.04上训练YOLOv4-tiny
文章目录
- 在Ubuntu20.04上训练YOLOv4-tiny
-
- 一、资料下载
-
- 1.yolov4
- 2.yolov4-tiny.weights
- 3.yolov4-tiny.conv.29
- 二、训练
-
- 1.配置Makefile文件
-
- (1)修改Makefile文件
- (2)编译
- 2.数据集训练文件配置
-
- (1)存放数据集
- (2)Main中生成train、trainval、test和val文件
- 3.修改cfg文件
- 4.修改voc.names
- 5.修改voc.data
- 6.训练
- 7.测试
-
- (1)图片测试
- (2)视频测试
- (3)摄像头测试
- 三、参考
一、资料下载
1.yolov4
官方下载:https://github.com/AlexeyAB/darknet
网盘下载:链接:https://pan.baidu.com/s/1HYiCANZZ4NPYFvMJ-cenFA
提取码:2rh0
2.yolov4-tiny.weights
官方下载:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.weights
网盘下载:链接:https://pan.baidu.com/s/1Rui1GNNyXQeEvz-dNdmbQA
提取码:jem4
3.yolov4-tiny.conv.29
官方下载地址:https://github.com/AlexeyAB/darknet/releases/download/darknet_yolo_v4_pre/yolov4-tiny.conv.29
网盘下载:链接:https://pan.baidu.com/s/15jyob_g98I951bbrBRDyIA
提取码:1ey6
二、训练
1.配置Makefile文件
(1)修改Makefile文件
进行如下修改:
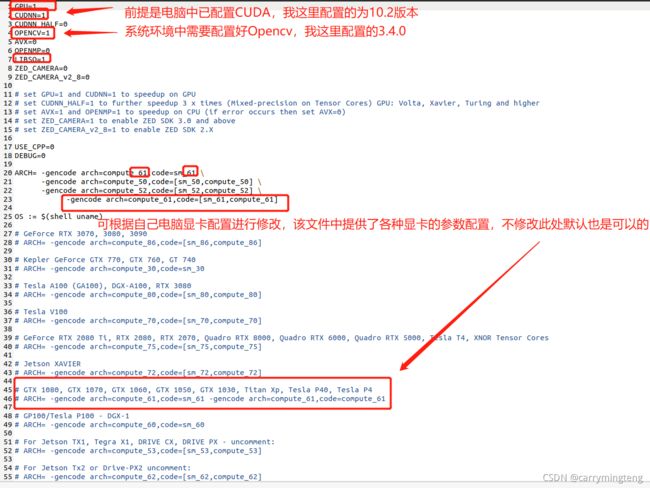
(2)编译
在yolov4目录下,打开终端进行编译
make #电脑CPU为单核
或者
make -j16 #我电脑为多核CPU所以此处我在后面加了参数-j16,当然根据自己电脑配置可以尝试-4 -j8,当然j后面的数值越大编译越快
运行完成后,可在yolov4目录下看到生成的darknet可执行文件
2.数据集训练文件配置
(1)存放数据集
在yolov4目录下新建如下文件夹结构
---VOCdevkit
---VOC2007
---Annotations #自己数据集的xml文件
---ImageSets #新建文件夹,用于存放后续生成的txt文件
---Main
---JPEGImages #自己数据集的图片文件,我是jpg格式
(2)Main中生成train、trainval、test和val文件
在上述新建的Main夹中生成train、trainval、test和val文件,首先要在文件夹VOC2007下创建一个python文件(文件名称无特殊需求),具体代码如下:
import os
import random
trainval_percent = 0.9 #可以自己修改
train_percent = 0.9 #可以自己修改
xmlfilepath = 'Annotations'
txtsavepath = 'ImageSets\Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
然后在VOC2007文件夹下打开终端运行该文件:
python3 label.py #label.py是我自定义的名称
在ImageSets/Main/下即可看见生成的四个train.txt、trainval.txt、test.txt和val.txt文件。
(3)yolov4目录下生成用于训练的txt文件
在yolov4目录下创建voc_label.py的文件(或者在scripts下也可以找到,但是需要修改一下),具体代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] #去掉2012的相关内容
classes = ["person"] #修改为自己类的名称
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
os.system("cat 2007_train.txt 2007_val.txt > train.txt") #去掉2012的相关内容
os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt > train.all.txt") #去掉2012的相关内容
运行该文件:
python3 voc_label.py
在yolov4目录下可看到生成了2007_test.txt、2007_train.txt和2007_val.txt文件。
3.修改cfg文件
在cfg文件夹下找到yolov4-tiny.cfg文件,修改如下:
[net]
# Testing #测试模式,测试时开启
#batch=1
#subdivisions=1
# Training #训练模式,训练时开启,测试时注释
batch=256 # 每批数量,根据配置设置,如果内存小,可改小(1,16,64)
subdivisions=16
width=416
height=416
channels=3 # 输入图像width height channels 长宽设置为32的倍数,因为下采样参数是32,最小320*320 最大608*608
momentum=0.9 # 动量参数,影响梯度下降速度
decay=0.0005 # 权重衰减正则项,防止过拟合
angle=0 # 旋转
saturation = 1.5 # 饱和度扩增
exposure = 1.5 # 曝光度
hue=.1 # 色调
learning_rate=0.00261 # 学习率,权值更新速度,如果为多显卡,learning_rate=0.0013305
burn_in=1000 # 迭代次数小于burn_in,学习率更新;大于burn_in,采用policy更新,如果多显卡,其数值为gpu数量*1000
max_batches = 500200 # 训练达到max_batches停止,具体数值为classes*2000,但是最小数值不能小于自己数据集图片的数量以及最小值不能小于6000
policy=steps # 学习率调整策略policy:constant, steps, exp, poly, step, sig, RANDOM
steps=400000,450000 # 步长 数值为max_batches的80%和90%
scales=.1,.1 # 学习率变化比例
[convolutional]
batch_normalize=1
filters=32
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=2
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1
groups=2
group_id=1
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=32
size=3
stride=1
pad=1
activation=leaky
[route]
layers = -1,-2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -6,-1
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1
groups=2
group_id=1
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=64
size=3
stride=1
pad=1
activation=leaky
[route]
layers = -1,-2
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -6,-1
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[route]
layers=-1
groups=2
group_id=1
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=128
size=3
stride=1
pad=1
activation=leaky
[route]
layers = -1,-2
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -6,-1
[maxpool]
size=2
stride=2
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
##################################
[convolutional]
batch_normalize=1
filters=256
size=1
stride=1
pad=1
activation=leaky
[convolutional]
batch_normalize=1
filters=512
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
filters=24 # 3*(classes+5)
activation=linear
[yolo]
mask = 3,4,5
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319
classes=1 # 类别数,修改为自己的类别数量,我这里就一个类别,所以为1
num=6
jitter=.3
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7
truth_thresh = 1
random=0
resize=1.5
nms_kind=greedynms
beta_nms=0.6
[route]
layers = -4
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
[upsample]
stride=2
[route]
layers = -1, 23
[convolutional]
batch_normalize=1
filters=256
size=3
stride=1
pad=1
activation=leaky
[convolutional]
size=1
stride=1
pad=1
**filters=24** # 3*(5+classes)
activation=linear
[yolo]
mask = 1,2,3
anchors = 10,14, 23,27, 37,58, 81,82, 135,169, 344,319 #预测框的初始宽高,第一个是w,第二个是h,总数量是num*2
classes=1 # 类别数,修改为自己的类别数量
num=6 # 每个grid预测的BoundingBox个数
jitter=.3 # # 利用数据抖动产生更多数据抑制过拟合.YOLOv2中使用的是crop,filp,以及net层的angle,flip是随机的,crop就是jitter的参数,tiny-yolo-voc.cfg中jitter=.2,就是在0~0.2中进行crop
scale_x_y = 1.05
cls_normalizer=1.0
iou_normalizer=0.07
iou_loss=ciou
ignore_thresh = .7 # # 决定是否需要计算IOU误差的参数,大于thresh,IOU误差不会夹在cost function中
truth_thresh = 1
random=0 # 如果为1每次迭代图片大小随机从320到608,步长为32,如果为0,每次训练大小与输入大小一致
resize=1.5
nms_kind=greedynms
beta_nms=0.6
4.修改voc.names
修改data下的voc.names,根据自己实际种类名称填写,我这里只有一个person种类,注意一定要和自己的标签文件中的类别一致!
person
5.修改voc.data
修改cfg下的voc.data。注意:如果后续训练时出现如下文件或文件夹的找不到的情况可以尝试使用根路径。
classes= 1 # 类别数
train = /home/yourselfpath/darknet-master/2007_train.txt # 训练集路径
valid = /home/yourselfpath/darknet-master/2007_test.txt # 测试集路径
names = data/voc.names
backup = backup/ # 模型保存路径
6.训练
在yolov4下打开终端输入:(注意检查如下指令中的文件是否都放到了相应位置!如下的yolov4.conv.29在开始时已提供了下载方式,记得放到yolov4下)
./darknet detector train data/voc.data cfg/yolov4-tiny.cfg yolov4-tiny.conv.29 -map
多GPU训练:
./darknet detector train data/voc.data cfg/yolov4-tiny.cfg yolov4-tiny.conv.29 -map -gpus 0,1
暂停后继续训练:
./darknet detector train data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights -map -gpus 0,1
7.测试
修改cfg文件,将测试模式打开,训练模式关闭,如下
[net]
# Testing #测试模式,测试时开启
batch=1
subdivisions=1
# Training #训练模式,训练时开启,测试时注释
#batch=256 # 每批数量,根据配置设置,如果内存小,可改小(1,16,64)
#subdivisions=16
选择参数最有的权重文件进行测试
(1)图片测试
./darknet detector test data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights data/person.jpg
(2)视频测试
./darknet detector demo data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights data/1.mp4
(3)摄像头测试
./darknet detector demo data/voc.data cfg/yolov4-tiny.cfg backup/yolov4-tiny-custom_last.weights -c 0 #如果有多个摄像头可以通过切换-c后面的参数进行更换
三、参考
1.https://github.com/AlexeyAB/darknet
2.https://blog.csdn.net/u010881576/article/details/107053328