涨姿势!一文了解深度学习中的注意力机制
全文共11413字,预计学习时长33分钟

图源:Unsplash
“每隔一段时间,就会出现一种能改变一切的革命性产品。”
——史蒂夫·乔布斯(SteveJobs)
这句21世纪最知名的言论之一与深度学习有什么关系呢?
想想看。计算能力的提升带来了一系列前所未有的突破。
若要追根溯源,答案将指向注意力机制。简而言之,这一全新概念正在改变我们应用深度学习的方式。

图源:Unsplash
注意力机制是过去十年中,深度学习研究领域最具价值的突破之一。
它催生了包括Transformer架构和Google的BERT在内的自然语言处理(NLP)领域的许多近期突破。如果你目前(或打算)从事NLP相关工作,一定要了解什么是注意力机制及其工作原理。
本文会讨论几种注意力机制的基础、流程及其背后的基本假设和直觉,并会给出一些数学公式来完整表达注意力机制,以及能让你在Python中轻松实现注意力相关架构的代码。
大纲
l 注意力机制改变了我们应用深度学习算法的方式
l 注意力机制彻底改变了自然语言处理(NLP)甚至计算机视觉等领域
l 本文将介绍注意力机制在深度学习中的工作原理,以及如何用Python将其实现
目录
1.什么是注意力?
1. 深度学习是如何引入注意力机制的
2. 了解注意力机制
2.使用Keras在Python中实现简单的注意力模型
3.全局与局部注意力
4.Transformers–只需注意力就足够
5.计算机视觉中的注意力

什么是注意力?
在心理学中,注意力是选择性地专注于一件或几件事物而忽略其他事物的认知过程。
神经网络被认为是为对人脑运作进行简单模仿所做出的努力。注意力机制也是为在深度神经网络中实现选择性地专注于一些事物而忽略其他事物这一相同动作所做出的一种尝试。
对此,我来解释一下。假设你在看小学时期的一张合照。照片上一般会有一群孩子分几排而坐,老师则坐在孩子中间。现在,如果有人问“照片上有多少人?”,你会怎么做呢?
只需数一下人头,对吗?不用考虑照片上其他任何内容。现在,如果有人问“里面哪个是老师?”,你的大脑十分清楚要怎样做,即开始找里面哪个看起来像大人。照片的其他特征将会被忽略。这就是大脑擅用的“注意力”。
深度学习是如何引入注意力机制的
注意力机制是对NLP中基于编码/解码器的神经机器翻译系统的一种改进。后来,该机制或其变体被用于计算机视觉、语音处理等其他方面。
在Bahdanau等人2015年提出首个注意力模型前,神经机器翻译是基于编码—解码器RNN / LSTM的。编码器和解码器都是LSTM/ RNN单元的堆栈。按以下两个步骤工作:
1.编码器LSTM用于处理整个输入句并将其编码为一个上下文向量,这是LSTM / RNN最后的隐藏状态。预期生成输入句的准确摘要。编码器的所有中间状态都将被忽略,最终状态应为解码器的初始隐藏状态
2.解码器LSTM或RNN单元生成句中的各个单词。简单来说,有两个RNN / LSTM。其中一个称为编码器—在生成摘要之前,会先读取输入句并尝试进行理解。它将摘要(上下文向量)传递给解码器,解码器仅通过查看即可翻译输入的句子。
这一方法的主要缺点显而易见。如果编码器的摘要不准确,翻译就会出错。实际上,已出现过这种情况,编码器在理解较长的句子时会生成错误的摘要。这就是RNN / LSTM的远程依赖问题。
由于梯度消失/爆炸问题,RNNs无法记住较长的句子和序列,它只能记住刚刚看到的部分。甚至提出编码器—解码器网络的Cho等人(2014)也证明,编码器—解码器网络的性能会随着输入句长度的增加迅速下降。
尽管LSTM应比RNN能更好捕获远程依赖关系,在特定情况下它往往会变得健忘。在翻译句子时,无法重点关注输入的某些词。

图源:Unsplash
现在,假设要预测某个句子的下一个单词,要从这个词前面的几个单词判断上下文内容。比如,“尽管他来自北方邦(印度某地名),但因成长于孟加拉,他还是更习惯说孟加拉语”。在这一句中,要想预测“孟加拉语”这个词,就要在预测时对“长大”和“孟加拉”这两个词赋予更大的权重。尽管北方邦也是个地名,这里应将其“忽略”。
那么,创建上下文向量时,有没有什么方法可以使输入句中的所有信息保持完整呢?
Bahdanau等人(2015)提出了一个简单但优雅的方法,他们建议在生成上下文向量时不仅可以考虑所有输入词,还应给予每个输入词的相对重要性。
因此,建议使用的模型在生成句子时,都会在编码器隐藏状态下搜寻一组位置,在这些位置上有着相关性最高的信息。这就是“注意力”。
了解注意力机制

这是Bahdanau论文中的注意力模型示意图。此处使用的双向LSTM为每个输入句生成一个注释序列(h1,h2,.....,hTx)。其中用到的所有向量h1,h2…基本上都是编码器中前向和后向隐藏状态的串联。
![]()
也就是说,向量h1,h2,h3....,hTx都是输入句中的Tx个词的代表。在简单的编码器和解码器模型中,仅将编码器LSTM的最后状态(在这种情况下为hTx)用作上下文向量。
但Bahdanau等人在创建上下文向量时着重将所有词嵌入到输入中(由隐藏状态表示)。他们通过简单地对隐藏状态进行加权求和实现这一点。
那么,要如何计算权重呢?其实,权重也可以通过前馈神经网络来学习,下文会提到它们的数学公式。
输出词yi的上下文向量ci是使用注释的加权之和生成的:
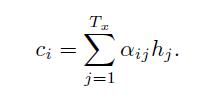
权重αij由以下给出的softmax函数计算得出:

![]()
eij由函数a描述的前馈神经网络的输出得分,该函数试图捕获j处输入与i处输出之间的对齐程度。
一般来说,如果编码器生成Tx个“注释”(隐藏状态向量),每个注释的维数为d,则前馈网络的输入维数为(Tx,2d)(假设解码器的先前状态也具有d维,并且这两个向量是串联的)。此输入乘以(2d,1)维的矩阵Wa(当然要加上偏差项),以获得得分eij(具有维度(Tx,1))。
在这些eij分数上,先应用tanh函数,再加上softmax以获取输出j的归一化比对分数:
E = I [Tx*2d] * Wa [2d * 1] + B[Tx*1]
α = softmax(tanh(E))
C=IT * α
因此,α是(Tx,1)维向量,其元素是与输入句中每个词对应的权重。
令α为[0.2,0.3,0.3,0.2],输入句为“I am doing it”。这里,与其对应的上下文向量是:
C = 0.2 *I” I” + 0.3 * I” am” + 0.3 * I”doing” + 0.3 *I” it” [Ix是与单词x对应的隐藏状态]
使用Keras在Python中实现简单的注意力模型
现在,我们已大致了解这种常被提及的注意力机制是什么。下面来将所学应用于实际吧。没错,要开始编码啦!
本节将讨论如何在Keras中实现简单的注意力模型。这一部分旨在展示如何在python中实现简单的注意力层。
作为例子,我们在加州大学尔湾分校机器学习存储库收集的简单句子层级情感分析数据集上运行这个演示程序。你可以自由选择一个数据集,为查看更加显著结果,还可以实现自定义“注意力”层。
这里只有两种情感类别,“ 0”表示负面情感,“1”表示正面情感。你会注意到,数据集包含三个文件。其中,两个文件涉及句子级别的情感,第三个文件涉及段落级别的情感。
为简单起见,我们使用句子级别的数据文件(amazon_cells_labelled.txt,yelp_labelled.txt)。在读取合并了两个数据文件后,数据如下图所示:

然后使用Keras的Tokenizer()类对数据进行预处理以适应模型:
t=Tokenizer()
t.fit_on_texts(corpus)
text_matrix=t.texts_to_sequences(corpus)
text_to_sequences()方法接收语料库,并将其转换为序列,即每个句子变成一个向量。向量的元素是与词汇表中每个单词一一对应的整数:
len_mat=[]
for i in range(len(text_matrix)):
len_mat.append(len(text_matrix[i]))
由于句子的长度一般不同,必须要确定与句子相对应向量的最大长度。应借助零填充使它们长度相等。这里使用了“后填充”,即在向量末尾添加零:
from keras.preprocessing.sequence import pad_sequences
text_pad = pad_sequences(text_matrix, maxlen=32, padding='post')
接下来,定义基于LSTM的基本模型:
inputs1=Input(shape=(features,))
x1=Embedding(input_dim=vocab_length+1,output_dim=32,\
input_length=features,embeddings_regularizer=keras.regularizers.l2(.001))(inputs1)
x1=LSTM(100,dropout=0.3,recurrent_dropout=0.2)(x1)
outputs1=Dense(1,activation='sigmoid')(x1)
model1=Model(inputs1,outputs1)
这里使用了嵌入层,紧接着是LSTM层。嵌入层采用32维向量,每个向量对应一个句子,然后输出(32,32)维矩阵,也就是说,生成与每个词相对应的32维向量。在模型训练中学习这种嵌入。
然后,添加一个具有100个神经元的LSTM层。由于它是一个简单的编码器/解码器模型,不需要编码器LSTM的每个隐藏状态。只想要编码器LSTM的最后一个隐藏状态,这可以通过在Keras LSTM函数中设置“ return_sequences” =False来实现。
但在Keras中,此参数的默认值为False。因此无需采取任何措施。
现在,输出变为100维向量,即LSTM的隐藏状态为100维。然后被传送到使用‘sigmoid’激活函数的前馈或密集层。使用具有二元交叉熵损失的 Adam优化器对模型进行训练。下文列出了10个周期的训练及模型结构:
model1.summary()

model1.fit(x=train_x,y=train_y,batch_size=100,epochs=10,verbose=1,shuffle=True,validation_split=0.2)
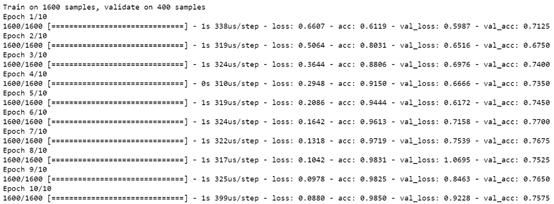
使用基于LSTM的基本模型,验证集的准确率高达77%
不在Keras中实现简单的Bahdanau注意层并将其添加到LSTM层。而是选择在Keras中使用默认的Layer类。定义一个名为Attention的类作为Layer类的派生类。根据Keras自定义layer的生成规则,需定义四个函数,分别为build(),call(),compute_output_shape()和get_config()。
在build()中,会定义权重和偏差,即前面提到的Wa和B. 如果上一个LSTM层的输出尺寸为(None,32,100),输出权重就应为(100,1),偏差应为(100,1)。
ef build(self,input_shape):
self.W=self.add_weight(name="att_weight",shape=(input_shape[-1],1),initializer="normal")
self.b=self.add_weight(name="att_bias",shape=(input_shape[1],1),initializer="zeros")
super(attention, self).build(input_shape)
在call()中,编写注意力的主要逻辑。只需创建一个多层感知器(MLP)即可。因此,会采用权重和输入的点积,然后加上偏差项。之后,会先应用“tanh”,然后再添加softmax层。softmax给出对齐分数。它的维数即LSTM中隐藏状态的数量,这里为32。将其点积与隐藏状态一起使用可生成上下文向量:
def call(self,x):
et=K.squeeze(K.tanh(K.dot(x,self.W)+self.b),axis=-1)
at=K.softmax(et)
at=K.expand_dims(at,axis=-1)
output=x*at
return K.sum(output,axis=1)
以上函数返回上下文向量。完整的自定义注意力类如下所示:
from keras.layers import Layer
import keras.backend as K
class attention(Layer):
def __init__(self,**kwargs):
super(attention,self).__init__(**kwargs)
def build(self,input_shape):
self.W=self.add_weight(name="att_weight",shape=(input_shape[-1],1),initializer="normal")
self.b=self.add_weight(name="att_bias",shape=(input_shape[1],1),initializer="zeros")
super(attention, self).build(input_shape)
def call(self,x):
et=K.squeeze(K.tanh(K.dot(x,self.W)+self.b),axis=-1)
at=K.softmax(et)
at=K.expand_dims(at,axis=-1)
output=x*at
return K.sum(output,axis=1)
def compute_output_shape(self,input_shape):
return (input_shape[0],input_shape[-1])
def get_config(self):
return super(attention,self).get_config()
get_config()方法收集输入尺寸和有关模型的其他信息。
现在,试着将此自定义的注意力层添加到先前定义的模型中。除了自定义注意力层外,其他所有层及其参数均保持不变。记住,这里要在LSTM层中设置return_sequences= True,因为需要LSTM输出所有隐藏状态。
inputs=Input((features,))
x=Embedding(input_dim=vocab_length+1,output_dim=32,input_length=features,\
embeddings_regularizer=keras.regularizers.l2(.001))(inputs)
att_in=LSTM(no_of_neurons,return_sequences=True,dropout=0.3,recurrent_dropout=0.2)(x)
att_out=attention()(att_in)
outputs=Dense(1,activation='sigmoid',trainable=True)(att_out)
model=Model(inputs,outputs)
model.summary()

model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['acc'])
model.fit(x=train_x,y=train_y,batch_size=100,epochs=10,verbose=1,shuffle=True,validation_split=0.2)

与先前模型相比,此模型确实实现了性能的提升。添加自定义注意力层后,验证精度现在可以达到81.25%。 通过进一步的预处理和网格搜索的参数调整,还能对其进一步改进。
研究人员尝试了多种技术来计算分数。根据计算分数以及上下文向量的方式,注意力模型有不同的变体。当然还会有其他变体,下文会有所涉及。
全局注意力与局部注意力
到目前为止,我们已讨论了最基本的注意力机制,即全部输入都被赋予一定的重要性。现在来深入探究一番吧。
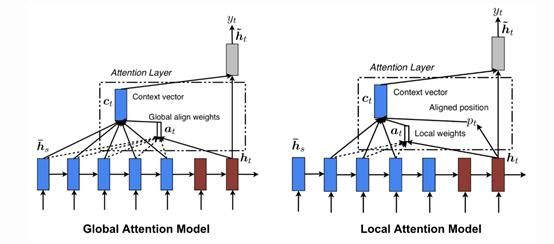
“全局”注意力这一用词十分恰当,因为所有输入都被赋予重要性。最初的全局注意力(由Luong等人于2015年定义)与先前讨论的注意力概念有一些细微差别。
差别在于,它考虑了编码器LSTM和解码器LSTM的所有隐藏状态,以计算“可变长度上下文向量ct”,而Bahdanau等人使用了单向解码器LSTM的先前隐藏状态和编码器LSTM的所有隐藏状态来计算上下文向量。
在编码器—解码器体系结构中,分数通常是编码器和解码器隐藏状态的函数。任何一个函数,只要能捕获输入单词相对于输出单词的重要性,就是有效函数。
在应用“全局”注意层时,会产生大量计算。这是因为必须考虑所有隐藏状态,将它们合并成一个矩阵,然后乘以正确尺寸的权重矩阵,以获得前馈连接的最后一层。
因此,随着输入量的增加,矩阵的大小也会增加。简而言之,前馈连接中的节点数量的增加实际上增加了计算量。
有什么办法能减少这种情况吗? 当然有!局部注意力就可以。

图源:Unsplash
就直觉来讲,我们在试着根据任何给定信息推断某些信息时,大脑倾向于仅分析最相关的输入来智能地一步步缩小搜索空间。
全局和局部注意力的思想受到主要用于计算机视觉任务的软、硬注意力概念的影响。
“软注意力”即全局注意力,其中所有图像斑块都具有一定权重;但注意,在硬注意力中,一次只考虑一个图像块。
但是局部注意力与图说任务中使用的硬注意力不同。它是两个概念的混合,不考虑所有编码输入,只考虑一部分输入,用于上下文向量的生成。这不仅避免了软注意力会引起的耗资巨大的计算,还比硬注意力更容易训练。
首先如何做到这一点?在这里,模型尝试预测输入单词的嵌入顺序中的位置pt。在位置pt周围,它考虑一个固定大小的窗口,如2D。因此,上下文向量将作为位置[pt-D,pt + D]的输入的加权平均值生成,其中D是根据经验选择的。
此外,可以有两种类型的对齐方式:
1,单调对齐,其中pt设置为t,假设在时间t处,仅t附近的信息很重要
2,预测对齐,其中模型按如下方式自行预测对齐位置:
![]()
其中“Vp”和“Wp”是在训练期间学习的模型参数,而“S”是源句的长度。显然,pt ε[0,S]。
下图说明了全局注意力机制和局部注意力机制的区别。全局注意力考虑所有隐藏状态(蓝色部分),而局部注意力仅考虑一个子集:
Transformers–只需注意力就足够
瓦斯瓦尼(Vaswani)等人发表的名为“只需注意力就足够(Attention is All You Need)”的论文是迄今为止对注意力机制最重要的贡献之一。他们在键、查询和值的基础上给出了十分通用、广泛的定义,重新定义了注意力。还引用了多头注意力的概念。简要介绍见下文。
首先定义“自我注意力机制(self-Attention)”。Cheng等人在其名为《用于机器阅读的LSTM网络》(Long Short-Term Memory-Networks for MachineReading)的论文中,将自注意力机制定义为关联单个序列或句子的不同位置以获得更生动表示的机制。
机器阅读器是一种可以自动理解提供给它的文本算法。我们从论文中截取了以下图片。红色单词当前正在被读取或处理,蓝色单词则是记忆单词。不同的阴影表示记忆激活的各种程度。
在逐字阅读或处理句子时,从阴影可以推断出,以前看过的单词得到了强调,这正是机器阅读器中的“自我注意力机制”所做的事情。

以前,要计算句子中某个单词的注意力,计算分数的方法是使用点积或单词的其他函数连同先前看到的单词的隐藏状态表示形式。该论文提出了一个与之基本相同但更通用的概念。
假设要计算“Chasing”一词的注意力。该机制将采用“Chasing”的嵌入与每个先前看到的词(例如“The”,“FBI”和“is”)嵌入的点积。
现在,根据广义定义,单词的每个嵌入应具有与之对应的三个不同向量,即“键”,“查询”和“值”。可以使用矩阵乘法轻松得出这些向量。
在需要针对输入嵌入来计算目标词的注意力时,应使用目标词的查询和输入的键来计算匹配分数,然后这些匹配分数将作为求和期间的值向量的权重。
现在,你可能会问这些键、查询和值向量是什么。他们是不同子空间中嵌入向量的抽象表述。可以这样理解:你提出一个查询;查询对应到输入向量的键。可以将这个键与正在读取的存储位置进行比较,值就是要从存储位置读取的值。还挺简单吧?
如果嵌入的尺寸为(D,1),而我们想要尺寸为(D/ 3,1)的键向量,就必须将嵌入乘以尺寸为(D/ 3,D)的矩阵Wk。因此,键向量变为K= Wk * E。同样,对于查询和值向量,等式将为Q = Wq *E,V = Wv * E(E是任一单词的嵌入向量)。
现在,要计算单词“chasing”的注意力,需要将“chasing”嵌入的查询向量与每个先前单词的键向量计算点积,即对应于“The”,“FBI”和“is”的键向量。然后将这些值除以D(嵌入的尺寸),然后进行softmax运算。运算分别如下:
l softmax(Q”chasing” .K”The” / D)
l softmax(Q”chasing” .K”FBI” / D)
l softmax(Q”chasing” .K”is” / D)
这基本上是目标单词的查询向量和输入嵌入的键向量的函数f(Qtarget,Kinput)。它不一定是Q和K的点积,可以自行选择函数。
接下来,假设由此获得的向量为[0.2,0.5,0.3]。这些值用于计算注意力的“对齐分数”。将这些分数与每个输入嵌入的值向量相乘,然后将这些权值向量相加便获得上下文向量:
C”chasing”=0.2 * VThe + 0.5* V”FBI” + 0.3 * V”is”
实际上,所有嵌入的输入向量都在一个矩阵X中,然后将其与常见的权重矩阵Wk,Wq,Wv相乘,分别得出K、Q和V矩阵。现在,方程可以简化为:
Z =Softmax(Q* KT / D)V
因此,上下文向量是键、查询和值F(K,Q,V)的函数。
Bahdanau 注意力或先前所有关于注意力的文章都是本文中描述的注意力机制的特例,重要特征/关键在于将单个嵌入式向量同时用作键、查询和值向量。
在多头注意力中,矩阵X乘以不同的Wk,Wq和Wv矩阵分别得到不同的K、Q和V矩阵。最终得到不同的Z矩阵,即将每个输入单词的嵌入投影到不同的“表征子空间”中。
例如,与“chasing”一词相对应的三头自我注意会出现3个不同的Z矩阵,这些矩阵也称为“注意力头”。将这些注意力头连接起来并乘以一个权重矩阵,会得到一个注意力头,可捕获来自所有注意力头的信息。
下图展示了多头注意机制。可以看到,不同的V、K、Q向量产生了多个注意力头,它们串联在一起:

实际的transformer结构要复杂一些。
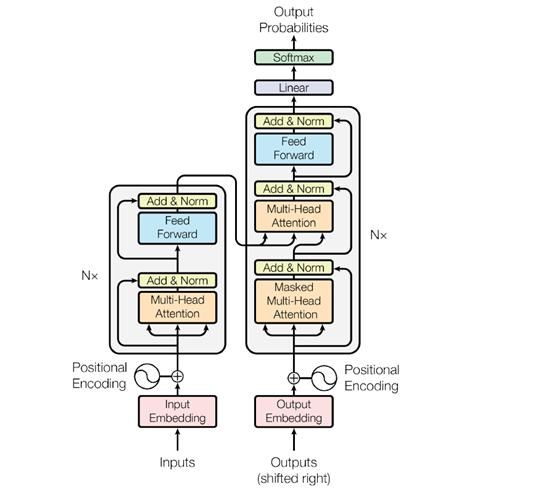
上图为transformer架构。可以看到已使用了“位置编码”,并同输入嵌入一同添加在编码器和解码器中。
到目前为止,我们所描述的模型还无法解决输入单词的顺序问题。它们都试图通过位置编码来捕获这一点。这种机制向每个输入嵌入添加了一个向量,所有向量都遵循一种模式,该模式有助于确定每个单词的位置或输入中不同单词间的距离。
如上图所示,在位置编码(positionalencoding)+输入嵌入(input embedding)层之上,有两个子层:
1. 在第一子层中,有一个多头自我注意层。从位置编码的输出到多头自我注意的输出之间存在附加的残余连接,在它们上面,应用了层归一化层。层归一化是一项技术(Hinton,2016),类似于批处理归一化,该技术在计算中考虑网络同一层中的所有隐藏单元,而不是考虑整个数据的最小批处理来计算归一化统计数据。这克服了在训练样本的小批量上估计对任何神经元总输入统计量的缺点。因此,在RNN/ LSTM中使用很方便
2. 在第二个子层中,有一个前馈层,而非多头自我注意(如图所示),其他连接都相同
在解码器端,除了上述两层,还有另一层在编码器堆栈的顶部应用多头注意力。然后,经过一个子层,一个线性层和一个softmax层,就能从解码器获得输出概率。
计算机视觉中的注意力机制
你可以直观地了解注意力机制在NLP领域中的应用。在这之上,我们还想进行深入探索。因此,本节将讨论计算机视觉中的注意力机制。此处将引用一些重要观点,借助引用的论文,你可以进行进一步的探索。
图像描述:Show, Attend and Tell: Neural Image Caption Generation with VisualAttention (Xu et al, 2015):
在图像描述中,使用卷积神经网络从图像中提取名为注解向量的特征向量。这将产生L个D维特征向量,每个特征向量对应于图像的一部分。
这一过程已从CNN模型的较低卷积层提取了特征,以便确定提取的特征向量和图像部分之间的对应关系。最重要的是,一种注意力机制用于选择性地赋予图像某些位置相对于其他位置更大的重要程度,以生成与图像相对应的描述。
此处采用了进行了细微修改的Bahdanau注意力。不同于对注释向量进行加权求和(类似于先前解释的隐藏状态),其设计了一个函数,可同时获取注释向量和对齐向量集,并输出上下文向量,而非简单地使用点积(相关内容可见上文)。
![]()
图像生成:DRAW – Deep Recurrent Attentive Writer
尽管Google DeepMind的这项工作与“注意力”没有直接关系,但已巧妙应用了这种机制来模仿艺术家的绘画方式,这是通过连续绘制图像的部分实现的。
下面简要介绍一下该论文,看一看如何能将此机制单独或与其他算法结合使用,来更好地完成更多有趣任务。
该工作的主要思想是使用变分自动编码器来生成图像。与简单的自动编码器不同,变分自动编码器不会直接生成数据的潜在表示。而是会生成具有不同均值和标准偏差的多个高斯分布(例如N个高斯分布)。
从这N个高斯分布中,对N个元素的潜在向量进行采样,并将该采样喂给解码器以生成输出图像。注意,基于注意力的LSTM在这里已用于变分自动编码器框架的编码器和解码器。
那又是什么?
这背后的主要直觉是迭代构造图像。在每一时间步长,编码器将一个新的潜在向量传递给解码器,解码器以累积方式改善生成图像,即在特定时间步生成的图像在下一时间步得到增强。就像模仿艺术家一步步地绘制图像一样。
但艺术家不能同时处理整个画面,对吧?他/她是分步绘制的—如果正在画肖像,肯定不能同时画出耳朵、眼睛或其他面部部位,他/她画好了眼睛,然后转到其他部分。
使用简单的LSTM无法在特定时间专注图像的特定部分。这就是这里为什么要用到注意力。
在编码器和解码器LSTM上,都使用了一个“注意力”层(称为“注意门”)。因此,在编码或“读取”图像时,每个时间步长仅聚焦图像的一部分。同样,在写入时,该时间步长仅生成图像的特定部分。
下图取自参考论文,显示了DRAW生成MNIST图像的步骤:

结语
本文为对目前流行的注意力机制及其在深度学习领域应用方式的全面综述。你一定已经明白了为什么该机制在深度学习领域的应用颇为广泛。该机制十分有效,并已渗透到多个领域。
当然,注意力机制的用途不仅限于本文中所提及的范围。如果你在工作或任何项目中应用过该机制,欢迎在下面的评论区留言,方便大家一起讨论哟~


留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)