目标检测算法——YOLOv5结合BotNet(Transformer)
BoTNet:视觉识别的Bottleneck Transformer !!!
论文题目:《Bottleneck Transformers for Visual Recognition》
基于Transformer的新backbone来了!!!在ImageNet上高达84.7%的top-1精度,性能远远优于SENet、EfficientNet等主干。
小海带近期实验将YOLOv5算法与BotNet进行创新性有效结合,发现检测效果俱佳!大大提高了模型的检测精度。
简介:BotNet由谷歌出品,BotNet即将ResNet中的第4个block中的bottleneck替换为MHSA(Multi-Head Self-Attention)模块,形成新的模块,取名叫做Bottleneck Transformer (BoT) 。最终由BoT这样的block组合成的网络结构就叫做BotNet。
Transformer中的MHSA和BoTNet中的MHSA的区别:
1.归一化:Transformer使用 Layer Normalization,而BoTNet使用 Batch Normalization。
2.非线性激活:Transformer仅仅使用一个非线性激活在FPN block模块中,BoTNet使用了3个非线性激活。
3.输出投影:Transformer中的MHSA包含一个输出投影,BoTNet则没有。
4.优化器:Transformer使用Adam优化器训练,BoTNet使用sgd+ momentum
————————————————
1.结构对比图
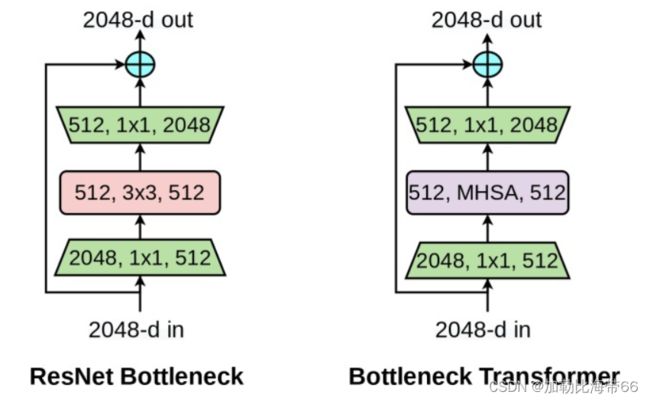
2.MHSA代码段:
class MHSA(nn.Module):
def __init__(self, n_dims, width=14, height=14, heads=4, pos_emb=False):
super(MHSA, self).__init__()
self.heads = heads
self.query = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.key = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.value = nn.Conv2d(n_dims, n_dims, kernel_size=1)
self.pos = pos_emb
if self.pos:
self.rel_h = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, 1, int(height)]), requires_grad=True)
self.rel_w = nn.Parameter(torch.randn([1, heads, (n_dims) // heads, int(width), 1]), requires_grad=True)
self.softmax = nn.Softmax(dim=-1)
def forward(self, x):
n_batch, C, width, height = x.size()
q = self.query(x).view(n_batch, self.heads, C // self.heads, -1)
k = self.key(x).view(n_batch, self.heads, C // self.heads, -1)
v = self.value(x).view(n_batch, self.heads, C // self.heads, -1)
# print('q shape:{},k shape:{},v shape:{}'.format(q.shape,k.shape,v.shape)) #1,4,64,256
content_content = torch.matmul(q.permute(0, 1, 3, 2), k) # 1,C,h*w,h*w
# print("qkT=",content_content.shape)
c1, c2, c3, c4 = content_content.size()
if self.pos:
# print("old content_content shape",content_content.shape) #1,4,256,256
content_position = torch.matmul(content_position, q) # ([1, 4, 1024, 256])
content_position = content_position if (
content_content.shape == content_position.shape) else content_position[:, :, :c3, ]
assert (content_content.shape == content_position.shape)
# print('new pos222-> shape:',content_position.shape)
# print('new content222-> shape:',content_content.shape)
energy = content_content + content_position
else:
energy = content_content
attention = self.softmax(energy)
out = torch.matmul(v, attention.permute(0, 1, 3, 2)) # 1,4,256,64
out = out.view(n_batch, C, width, height)
return outBoTNet是一种简单却功能强大的backbone,该架构将自注意力纳入了多种计算机视觉任务,包括图像分类,目标检测和实例分割。通过仅在ResNet的最后三个bottleneck blocks中用全局自注意力替换空间卷积,并且不进行其他任何更改,该方法在实例分割和目标检测方面显著改善了基线,同时还减少了参数,从而使延迟最小化。
近期较忙,代码咨询的小伙伴请私聊!!!