linux进程管理详解 —— 学习笔记
文章目录
- 进程管理
- 一、概述
- 二、进程与线程
-
- 2.1 进程描述符
- 2.2 进程状态
- 2.3 进程上下文
- 2.4 进程树
- 2.5 进程的创建
-
- 2.5.1 do_fork()
- 2.5.2 copy_process
- 2.5.3 .task_fork = task_fork_fair()
-
- 2.5.3.1 task_fork_fair()->update_curr()
- 2.5.3.2 task_fork_fair()->place_entity()
- 2.5.4 do_fork()->wake_up_new_task()
- 2.5.5 .enqueue_task = enqueue_task_fair()
-
- 2.5.5.1 enqueue_task_fair()->enqueue_entity()
- 2.6 撤销进程
-
- 2.6.1 进程终止
- 2.6.2 do_group_exit()函数
- 2.6.3 do_exit()函数
- 2.7 小结
- 三、调度器
-
- 3.1 调度器类
- 3.2 就绪队列->运行队列
-
- 3.3.1 处理优先级
-
- 3.3.1.1 计算优先级
- 3.3.1.2 负荷权重
- 3.3.2 核心调度器
-
- 3.3.2.1 周期性调度器
- 3.3.3 主调度器
- 3.4 小结
进程管理
一、概述
很多时候说多任务是并发执行的,是一个宏观的说法,在微观看来,多任务并行的错觉是内核在任务切换中所耗费时间极短,由于切换时间极短,以至于用户无法感受到进程切换带来的迟滞,所以感觉到程序是在并行执行。
所以就设计到内核针对进程进行管理的问题,有几个需要内核面对的问题需要理解清楚:
- 应用程序不能彼此干扰,除非有明确的需求;
- CPU时间必须在各种应用程序之间尽可能的公平共享;
有两个执行相对独立的任务,负责进程间的切换:
- 内核必须决定为各个进程分配多长时间,何时切换到下一个进程,哪个进程是下一个进程?;
- 内核从进程A切换到进程B的时候,必须确保进程B的执行环境与上一次撤销其处理器资源时完全相同;
这两个任务被称为调度器的内核子系统的职责,CPU时间如何分配取决于调度器策略,这与用于在各个进程之间切换的任务切换机制完全无关。
二、进程与线程
进程管理是所有操作系统的心脏所在,是Unix操作系统抽象概念中最基本的一种,程序本身并不是进程,它是处于执行期的程序(目标码存放在某种存储介质上),通常进程不局限于一段可执行的程序代码,还会包含其他资源,像打开的文件、挂起的信号、内核内部数据、处理器状态、一个或多个执行线程和数据段等等。Linux内核通常把进程称为任务Task,因此进程控制块(processing control block,PCB)也被命名为struct task_struct。
执行线程简称线程,是在进程中活动的对象,也被称为轻量级进程,是操作系统调度中的最小单元,通常一个进程可以拥有多个线程,**每个线程都拥有一个独立的程序计数器、进程栈和一组进程寄存器。**线程和进程的区别在于进程有自己独立资源空间,而线程智能共享进程的资源空间。
进程在创建它的时刻就开始存活,进程通过fork系统调用创建新的进程,而调用fork的进程就被称为父进程,被创建的进程为子进程,新创建的进程可以通过exec()函数创建新的地址空间,并载入新的程序,进程结束可以自愿也可以被结束;子进程在调用结束后,在返回点这个相同位置上,父进程恢复执行,子进程开始执行,fork()系统调用从内核返回两次,一次回到父进程,第二次回到新产生的子进程。
2.1 进程描述符
内核为了管理进程,就必须对每个进程的大小细节了如指掌,比如进程的优先级、分配的地址空间、允许访问了哪个文件、进程的状态等等,内核通过进程描述符(process descriptor)进行管理——task struct类型结构体,它的字段包含了与一个进程相关的所有信息,该结构体极其复杂,不仅包含了很多进程属性的字段,而且一些字段还包括了指向其他数据结构的指针!
struct task_struct {
volatile long state; /* -1 不可运行, 0 可运行, >0 表示停止 */
void *stack;
atomic_t usage;
unsigned int flags; /* 每个进程标志 */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
unsigned int wakee_flips;
unsigned long wakee_flip_decay_ts;
struct task_struct *last_wakee;
int wake_cpu;
#endif
int on_rq;
...
pid_t pid;
pid_t tgid;
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class; // 调度器类实例
struct sched_entity se; // 调度器实例
struct sched_rt_entity rt;
#ifdef CONFIG_SCHED_INFO
struct sched_info sched_info;
#endif
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
struct rb_node pushable_dl_tasks;
#endif
struct mm_struct *mm, *active_mm;
/* 文件系统信息 */
struct fs_struct *fs;
/* 打开文件信息 */
struct files_struct *files;
/* 命名空间 */
struct nsproxy *nsproxy;
/* 信号处理程序 */
struct signal_struct *signal;
struct sighand_struct *sighand;
...
...
...
}
涉及到mm_struct(指向内存区描述符的指针)、tty_struct(与进程相关的tty)、fs_struct(当前目录)、files_struct(指向文件描述符的指针)、signal_struct(所接收的信号);
另一方面,系统允许用户使用一个叫进程标识符process ID(PID)的数来进行标识进程,PID存放在进程描述符的pid字段中,是被顺序编号的,新创建进程的PID通常是前一个进程的PID+1。PID是有上限的,当内核使用的PID达到这个上限值的时候,系统开始循环使用已经闲置的小PID号。
pid_t pid;
pid_t tgid;
PID的上限为32767,系统管理员可以通过修改 /proc/sys/kernel/pid_max文件去修改写入一个更小的值来减小PID的上限值。
task_struct相对比较大,毕竟进程描述符包含的数据能够完整的描述一个正在执行的程序,它由一个任务队列来链接

2.2 进程状态
进程描述符中的state字段描述了进程当前所处的状态,它由一组标志组成,而且状态间是互斥的,因此,严格意义上来说,每个进程只能设置一种状态,其余的标志会被清除!
理论上一共有5中状态标志,加上一种僵死态(EXIT_ZOMBIE):
-
**TASK_RUNNING(可运行状态):**进程是可执行的,它也许是正在执行、在运行队列中等待执行,该状态也可以应用到内核空间中正在执行的进程;
-
**TASK_INTERRUPTIBLE(可中断的等待状态):**进程被挂起(睡眠态或者说是被阻塞状态),等待某些条件的达成,一旦这些条件达成,内核就会把进程状态设置为运行,处于此状态的进程也会因为接受信号而提前被唤醒(转入TASK_RUNNING态)并随时准备投入运行;
-
**TASK_UNINTERRUPTIBLE(不可中断的等待状态):**与可中断的等待状态相似,但是它即使接收到信号也不会被唤醒,所以很少用到;但是在一些特定的情况下,比如进程必须等待,直到一个不能被中断的事件发生,这种状态还是很有用的;
-
**TASK_STOPPED:**进程的执行被暂停,当进程接收到SIGSTOP、SIGTSTP、SIGTTIN或SIGTTOU等信号的时候,进入暂停状态;
-
**TASK_TRACED:**进程的执行已由debugger程序暂停,当一个进程被另一个进程监控时,任何信号都可以把这个进程置于TASK_TRACED状态,例如通过ptrace对调试程序进行跟踪;
-
**EXIT_DEAD~EXIT_ZOMBIE:**进程在退出的过程中,处于TASK_DEAD状态。在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息(保存在task_struct里)。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。这样的进程可以说已经死亡,但是仍然以某种方式活着,活着指的是进程表中仍然有对应的表项,死亡指的是它的资源(内存、外设连接、等等)已经释放,因此不会再次运行。
父/子进程在退出的时间不同,会有两种异常导致的状态,一种是上述的僵尸态,一种是孤儿进程;孤儿进程是父进程先于子进程退出,还存活的进程就变成了“孤儿”,这个时候孤儿进程要么被下一个RUNNING的进程接管,要么就是被init进程(1号进程)接管。

2.3 进程上下文
可执行程序代码是进程的重要组成成分,可执行文件载入到进程地址空间进行执行,一般程序在用户空间执行,当一个程序执行了系统调用或者处罚了某个异常,它就陷入了内核空间,此时,我们称内核代表进程执行,这个时候处于进程的上下文中,在内核空间退出的时候,程序恢复在用户空间会继续执行,除非在此间隙中出现有更高优先级的进程需要执行并由调度器做出相应调整。
系统调用和异常处理程序是对内核明确定义的接口,进程只有通过这些接口才能进入内核执行,而且对内核的所有访问都必须通过这些接口。
2.4 进程树
正如前文描述的,Linux内核在启动时会有一个init_task进程,它是操作系统中所有进程的“鼻祖”,所有进程都是他的后代;
![]()
除了init进程,系统中的所有进程都必然会有一个父进程,每个进程可以有零到多个子进程,拥有同一个父进程的相互为兄弟进程,进程间的关系都存放在进程描述符中,如下:
struct task_struct __rcu *real_parent; /* 真实的父进程(调试情况下) */
struct task_struct __rcu *parent; /* 父进程 */
/*
* children/sibling链表外加当前调试的进程,构成了当前进程的所有子进程
*/
struct list_head children; /* 子进程链表 */
struct list_head sibling; /* 连接到父进程的子进程链表 */
struct task_struct *group_leader; /* 线程组组长 */
- real_parent:指向了创建了当前进程的进程描述符,如果当前进程的父进程不再存在,就会指向init的描述符;
- parent:指向当前进程的父进程,该值指向通常与前者相同;
- children:链表的头部,链表中所有元素都是当前进程创建的子进程;
- sibling:指向兄弟进程链表中上下元素的指针,它们的父进程相同;
所以我们可以通过内核链表提供的接口,从系统中任何一个进程出发,查找任意指定的其他进程。
2.5 进程的创建
Linux系统中,进程或线程是通过fork、vfork、clone等系统调用来建立的;
目前Linux采取了两段式方法来创建进程,fork()和exec()(这里的exec代指exec()族),fork()负责通过拷贝当前进程创建一个子进程,子进程与父进程的区别仅在于PID、PPID和某些资源和统计量,当父子进程共用同一个elf文件时,可以只调用fork()即可;对于创建的子进程需要加载自己的elf文件时,一般就采用先fork() then exec(),exec()函数主要负责读取可执行文件并将其载入地址空间开始运行;
- fork调用复制完整的父进程资源带来的开销非常的大,对此Linux内核引入了 copy-on-write技术,最后fork的开销降低;
- 为了节省复制页表的开销,Linux内核提供了vfork()的调用,vfork类似于fork,但是不复制父进程数据,而是通过共享数据实现的,这个时候问题出现了,当父子进程共享了同一块内存空间(完全相同的虚拟空间、栈空间)后,为了避免同时运行带来的内存错乱,所以在子进程退出或者开始新程序之前,需要对父进程进行阻塞;
- clone产生线程,可以对父子进程之间的共享、复制进行精准控制,这个接口提供了更多的灵活性,可以让用户指定父进程和子进程(也就是创建的进程)共享的内容。其实通过传递不同的参数,clone接口可以实现fork和vfork的功能。
以上三个系统调用都是通过一个函数来实现的,即do_fork()函数。
2.5.1 do_fork()
long _do_fork(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *parent_tidptr,
int __user *child_tidptr,
unsigned long tls)
{
struct task_struct *p;
int trace = 0;
long nr;
if (!(clone_flags & CLONE_UNTRACED)) {
if (clone_flags & CLONE_VFORK)
trace = PTRACE_EVENT_VFORK;
else if ((clone_flags & CSIGNAL) != SIGCHLD)
trace = PTRACE_EVENT_CLONE;
else
trace = PTRACE_EVENT_FORK;
if (likely(!ptrace_event_enabled(current, trace)))
trace = 0;
}
p = copy_process(clone_flags, stack_start, stack_size,
child_tidptr, NULL, trace, tls);
if (!IS_ERR(p)) {
struct completion vfork;
struct pid *pid;
trace_sched_process_fork(current, p);
pid = get_task_pid(p, PIDTYPE_PID);
nr = pid_vnr(pid);
if (clone_flags & CLONE_PARENT_SETTID)
put_user(nr, parent_tidptr);
if (clone_flags & CLONE_VFORK) {
p->vfork_done = &vfork;
init_completion(&vfork);
get_task_struct(p);
}
wake_up_new_task(p);
/* forking complete and child started to run, tell ptracer */
if (unlikely(trace))
ptrace_event_pid(trace, pid);
if (clone_flags & CLONE_VFORK) {
if (!wait_for_vfork_done(p, &vfork))
ptrace_event_pid(PTRACE_EVENT_VFORK_DONE, pid);
}
put_pid(pid);
} else {
nr = PTR_ERR(p);
}
return nr;
}

/*
* cloning flags:
*/
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */
#define CLONE_VM 0x00000100 /* set if VM shared between processes */
#define CLONE_FS 0x00000200 /* set if fs info shared between processes */
#define CLONE_FILES 0x00000400 /* set if open files shared between processes */
#define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */
#define CLONE_PTRACE 0x00002000 /* set if we want to let tracing continue on the child too */
#define CLONE_VFORK 0x00004000 /* set if the parent wants the child to wake it up on mm_release */
#define CLONE_PARENT 0x00008000 /* set if we want to have the same parent as the cloner */
#define CLONE_THREAD 0x00010000 /* Same thread group? */
#define CLONE_NEWNS 0x00020000 /* New mount namespace group */
#define CLONE_SYSVSEM 0x00040000 /* share system V SEM_UNDO semantics */
#define CLONE_SETTLS 0x00080000 /* create a new TLS for the child */
#define CLONE_PARENT_SETTID 0x00100000 /* set the TID in the parent */
#define CLONE_CHILD_CLEARTID 0x00200000 /* clear the TID in the child */
#define CLONE_DETACHED 0x00400000 /* Unused, ignored */
#define CLONE_UNTRACED 0x00800000 /* set if the tracing process can't force CLONE_PTRACE on this clone */
#define CLONE_CHILD_SETTID 0x01000000 /* set the TID in the child */
/* 0x02000000 was previously the unused CLONE_STOPPED (Start in stopped state)
and is now available for re-use. */
#define CLONE_NEWUTS 0x04000000 /* New utsname namespace */
#define CLONE_NEWIPC 0x08000000 /* New ipc namespace */
#define CLONE_NEWUSER 0x10000000 /* New user namespace */
#define CLONE_NEWPID 0x20000000 /* New pid namespace */
#define CLONE_NEWNET 0x40000000 /* New network namespace */
#define CLONE_IO 0x80000000 /* Clone io context */
- CSIGNAL:在出口处发送的信号掩码;
- CLONE_VM:父进程和子进程运行在同一个虚拟地址空间,一个进程对全局变量改动,另一个进程也可以看到;
- CLONE_FS:父进程和子进程共享文件系统信息,其中一个进程对文件系统信息进行改变,将会影响到另外一个进程;
- CLONE_FILES:父进程和子进程共享文件描述符表;
- CLONE_SIGHAND:父进程和子进程共享信号处理函数表;
- CLONE_PTRACE:父进程被跟踪,子进程也会被跟踪;
- CLONE_VFORK:调用vfork(),在创建子进程时,父进程准备睡眠等待子进程将其唤醒
fork实现:
do_fork(SIGCHLD, 0, 0, NULL, NULL);
vfork实现:
do_fork(CLONE_VFORK | CLONE_VM |SIGCHLD , 0, 0, NULL, NULL);
clone实现:
do_fork(cloning_flags , newsp, 0, parent_tidptr, child_tidptr);
2.5.2 copy_process
在do_fork中大多数工作是由copy_process函数完成的;
static struct task_struct *copy_process(unsigned long clone_flags,
unsigned long stack_start,
unsigned long stack_size,
int __user *child_tidptr,
struct pid *pid,
int trace,
unsigned long tls)
创建一个新的进程,并返回进程描述符的具体过程如下:
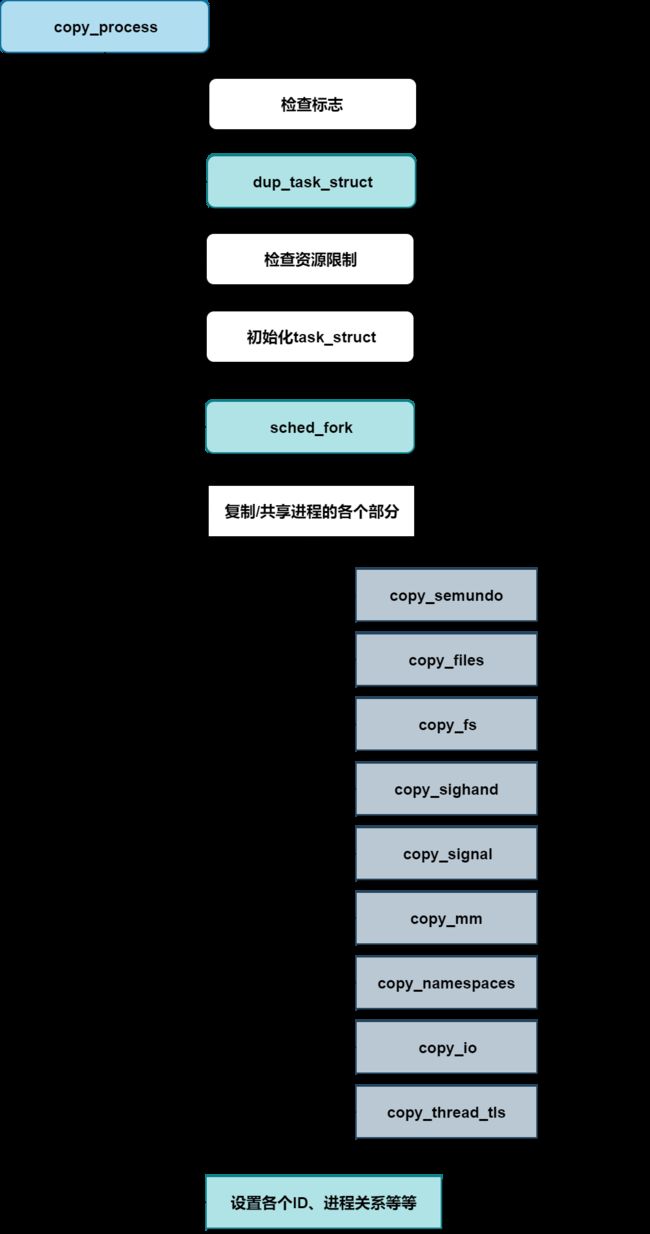
在内核建立了自洽的标志集之后,则用dup_task_struct来建立父进程task_struct的副本,分配一个task_struct实例,用于子进程的新的task_struct实例可以在任何空闲的内核内存位置分配;
static struct task_struct *dup_task_struct(struct task_struct *orig)
{
struct task_struct *tsk;
struct thread_info *ti;
int node = tsk_fork_get_node(orig);
int err;
tsk = alloc_task_struct_node(node); // 新建task_struct实例
if (!tsk)
return NULL;
ti = alloc_thread_info_node(tsk, node); // 新建thread_info实例,并让tsk中的
if (!ti)
goto free_tsk;
err = arch_dup_task_struct(tsk, orig); // 复制父进程的进程描述符给新分配的描述符
if (err)
goto free_ti;
tsk->stack = ti;
#ifdef CONFIG_SECCOMP
tsk->seccomp.filter = NULL;
#endif
setup_thread_stack(tsk, orig); // 把父进程的struct thread_info数据结构中的内容复制给新分配的子进程的thread_info中
clear_user_return_notifier(tsk);
clear_tsk_need_resched(tsk);
set_task_stack_end_magic(tsk);
#ifdef CONFIG_CC_STACKPROTECTOR
tsk->stack_canary = get_random_int();
#endif
atomic_set(&tsk->usage, 2);
#ifdef CONFIG_BLK_DEV_IO_TRACE
tsk->btrace_seq = 0;
#endif
tsk->splice_pipe = NULL;
tsk->task_frag.page = NULL;
tsk->wake_q.next = NULL;
account_kernel_stack(ti, 1);
return tsk;
free_ti:
free_thread_info(ti);
free_tsk:
free_task_struct(tsk);
return NULL;
}
dup_task_struct首先分配了一个struct task_struct和struct thread_info数据结构实例:
**第8行tsk = alloc_task_struct_node(node)**新建task_struct实例,用作子进程的进程描述符;
static inline struct task_struct *alloc_task_struct_node(int node)
{
return kmem_cache_alloc_node(task_struct_cachep, GFP_KERNEL, node);
}
**第12行ti = alloc_thread_info_node(tsk, node)**新建thread_info实例;
static struct thread_info *alloc_thread_info_node(struct task_struct *tsk,
int node)
{
struct page *page = alloc_kmem_pages_node(node, THREADINFO_GFP,
THREAD_SIZE_ORDER);
return page ? page_address(page) : NULL;
}
**在第16行arch_dup_task_struct(tsk, orig)**将父进程的进程描述符复制给新分配的进程描述符中;
int __weak arch_dup_task_struct(struct task_struct *dst,
struct task_struct *src)
{
*dst = *src;
return 0;
}
**第25行:setup_thread_stack(tsk, orig)**把父进程的struct thread_info数据结构中的内容复制给新分配的子进程的thread_info中;
static inline void setup_thread_stack(struct task_struct *p, struct task_struct *org)
{
*task_thread_info(p) = *task_thread_info(org);
task_thread_info(p)->task = p;
}
**第27行:clear_tsk_need_resched(tsk)**清除thread_info->flags中的标志位,新进程刚创建不宜被调度;
static inline void clear_tsk_need_resched(struct task_struct *tsk)
{
clear_tsk_thread_flag(tsk,TIF_NEED_RESCHED);
}
父子进程的task_struct实例只有一个成员不同:新进程分配了一个新的核心态栈,即task_struct->stack。通常栈和thread_info一同保存在一个联合中,thread_info保存了线程所需的所有特定于处理器的底层信息。
union thread_union {
struct thread_info thread_info;
unsigned long stack[THREAD_SIZE/sizeof(long)];
};
thread_info保存了特定于体系结构的汇编语言代码需要访问的那部分进程数据。
struct thread_info {
struct task_struct *task; /* 当前进程task_struct指针 */
__u32 flags; /* 底层标志 */
__u32 status; /* 线程同步标志 */
__u32 cpu; /* 当前 CPU */
mm_segment_t addr_limit; /* 线程地址空间 */
unsigned int sig_on_uaccess_error:1;
unsigned int uaccess_err:1; /* uaccess failed */
};
- task:指向进程task_struct实例的指针;
- flags:底层标志;
- status:线程同步标志;

前面dup_task_struct来建立父进程task_struct的副本,分配一个task_struct实例,但是task_struct中不可能百分百复用父进程的,因为子进程也是要加入调度器中参与调度的,这个时候就需要**sched_fork()->__sched_fork()**函数把新创建的进程调度实体相关成员初始化为0;
static void __sched_fork(unsigned long clone_flags, struct task_struct *p)
{
p->on_rq = 0;
p->se.on_rq = 0;
p->se.exec_start = 0;
p->se.sum_exec_runtime = 0;
p->se.prev_sum_exec_runtime = 0;
p->se.nr_migrations = 0;
p->se.vruntime = 0;
INIT_LIST_HEAD(&p->se.group_node);
...
...
p->node_stamp = 0ULL;
p->numa_scan_seq = p->mm ? p->mm->numa_scan_seq : 0;
p->numa_scan_period = sysctl_numa_balancing_scan_delay;
p->numa_work.next = &p->numa_work;
p->numa_faults = NULL;
p->last_task_numa_placement = 0;
p->last_sum_exec_runtime = 0;
p->numa_group = NULL;
#endif /* CONFIG_NUMA_BALANCING */
}
每个调度类都定了自己的操作方法集,CFS调度器调度类定义的操作方法如下:
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_waking = task_waking_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_common,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_move_group = task_move_group_fair,
#endif
};
调用CFS调度器的task_fork方法做一些fork相关的初始化,在sched_fork函数中执行如下:
int sched_fork(unsigned long clone_flags, struct task_struct *p)
{
unsigned long flags;
int cpu = get_cpu();
__sched_fork(clone_flags, p);
p->state = TASK_RUNNING;
p->prio = current->normal_prio;
...
if (p->sched_class->task_fork)
p->sched_class->task_fork(p); // 调用CFS调度器的task_fork方法做一些fork相关的初始化
...
put_cpu(); // put_cpu()函数和get_cpu()函数配对使用,put_cpu()会使能内核抢占
return 0;
}
2.5.3 .task_fork = task_fork_fair()
task_fork方法实现(.task_fork = task_fork_fair)在kernel/sched/fair.c中:
static void task_fork_fair(struct task_struct *p)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se, *curr;
int this_cpu = smp_processor_id(); // 从当前进程thread_info结构中的cpu成员获取当前CPU id
struct rq *rq = this_rq(); // this_rq()获取当前CPU的就绪队列数据结构struct rq,详见3.2小节
unsigned long flags;
raw_spin_lock_irqsave(&rq->lock, flags);
update_rq_clock(rq);
cfs_rq = task_cfs_rq(current); // 由current变量取得当前进程对应的CFS调度器就绪队列的数据结构cfs_rq
curr = cfs_rq->curr;
rcu_read_lock();
__set_task_cpu(p, this_cpu); // __set_task_cpu函数把当前CPU绑定到该进程中
rcu_read_unlock();
update_curr(cfs_rq); // CFS中比较核心的函数,用于更新当前任务的运行时统计信息,参数是当前进程的CFS就绪队列
if (curr)
se->vruntime = curr->vruntime;
place_entity(cfs_rq, se, 1); // 针对新进程的vruntime进行惩罚
if (sysctl_sched_child_runs_first && curr && entity_before(curr, se)) {
swap(curr->vruntime, se->vruntime);
resched_curr(rq);
}
se->vruntime -= cfs_rq->min_vruntime;
raw_spin_unlock_irqrestore(&rq->lock, flags);
}
[跳转struct rq](#3.2 就绪队列->运行队列)
2.5.3.1 task_fork_fair()->update_curr()
CFS核心函数之一update_curr()解析
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr; // curr指向的调度实体是当前进程,即父进程
u64 now = rq_clock_task(rq_of(cfs_rq)); // 获取当前就绪队列保存的clock_task值,该值在每次时钟tick到来时更新
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start; // delta_exec计算该进程从上次调用update_curr函数到现在的时间差(实际运行时间)
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now; // 更新curr->exec_start
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec; // 更新当前进程在CPU上执行花费的屋里时间
schedstat_add(cfs_rq, exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);// calc_delta_fair函数使用delta_exec时间差计算该进程的虚拟时间vruntime
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cpuacct_charge(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
这里涉及到权重的概念,[跳转查看权重解析](#3.3.1.2 负荷权重)。
2.5.3.2 task_fork_fair()->place_entity()
不管任务多寡,CPU每个周期的工作时间都是一样的,当新创建了一个进程导致CFS运行队列的权重放生变化,那么这里会对新进程的vruntime做惩罚,具体的惩罚时间根据新进程的权重由sched_vslice()函数计算虚拟时间,最后新进程调度实体的虚拟时间是在调度实体的实际虚拟时间和CFS运行队列中min_vruntime中取最大值
//参数:cfs_rq是父进程对应的cfs进程的就绪队列,se是新进程的调度实体,initial值为1
static void place_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int initial)
{
u64 vruntime = cfs_rq->min_vruntime;//cfs_rq->min_vruntime用于跟踪CFS队列中红黑树最小的vruntime值
if (initial && sched_feat(START_DEBIT))
vruntime += sched_vslice(cfs_rq, se); // 计算惩罚值
/* sleeps up to a single latency don't count. */
if (!initial) {
unsigned long thresh = sysctl_sched_latency;
/*
* Halve their sleep time's effect, to allow
* for a gentler effect of sleepers:
*/
if (sched_feat(GENTLE_FAIR_SLEEPERS))
thresh >>= 1;
vruntime -= thresh;
}
/* 新进程调度实体的虚拟时间是在调度实体的实际虚拟时间和CFS运行队列中min_vruntime中取最大值. */
se->vruntime = max_vruntime(se->vruntime, vruntime);
}
计算惩罚值的具体步骤:

-
__shced_period()函数会计算CFS就绪队列中的一个调度周期的长度,可以理解为一个调度周期的时间片具体根据当前运行的进程数目计算,CFS调度器有一个默认调度时间片,默认值得选择与sched_nr_latency有关;
unsigned int sysctl_sched_latency = 6000000ULL; // 默认时间片为6ms unsigned int normalized_sysctl_sched_latency = 6000000ULL; /* CPU绑定任务的最小抢占粒度即最小的调度延时0.75ms*进程数目(前提是当进程数量大于8的时候,否则使用默认的6ms)*/ unsigned int sysctl_sched_min_granularity = 750000ULL; unsigned int normalized_sysctl_sched_min_granularity = 750000ULL; static unsigned int sched_nr_latency = 8; static u64 __sched_period(unsigned long nr_running) { if (unlikely(nr_running > sched_nr_latency)) return nr_running * sysctl_sched_min_granularity; //如果当运行中的进程数大于sched_nr_latency时,调度周期时间片=0.75*nr_running(进程数目) else return sysctl_sched_latency; // 否者使用系统默认调度时间片6ms } -
sched_slice()根据当前进程的权重计算CFS就绪队列总权重中可以瓜分到的调度时间
-
sched_vslice()根据sched_slice()计算得到的时间来计算可以得到多少虚拟时间;
2.5.4 do_fork()->wake_up_new_task()
void wake_up_new_task(struct task_struct *p)
{
unsigned long flags;
struct rq *rq;
raw_spin_lock_irqsave(&p->pi_lock, flags);
init_entity_runnable_average(&p->se);
#ifdef CONFIG_SMP
/* 前面在copy_process()->sched_fork()->set_task_cpu()中设置了父进程的CPU到子进程中,
而现在为什么需要重新设置一次呢?
1.在fork的过程中,cpus_allowed可能发生变化;
2.之前选择的CPU可能被关闭了;
select_task_rq()方法用来选择一个合适的调度域中最休闲的CPU
*/
set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0));
#endif
rq = __task_rq_lock(p);
activate_task(rq, p, 0);
p->on_rq = TASK_ON_RQ_QUEUED;
trace_sched_wakeup_new(p);
check_preempt_curr(rq, p, WF_FORK);
#ifdef CONFIG_SMP
if (p->sched_class->task_woken) {
lockdep_unpin_lock(&rq->lock);
p->sched_class->task_woken(rq, p);
lockdep_pin_lock(&rq->lock);
}
#endif
task_rq_unlock(rq, p, &flags);
}
2.5.5 .enqueue_task = enqueue_task_fair()
把新进程添加到CFS就绪队列中
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags); // 把调度实体se添加到cfs_rq就绪队列中
if (cfs_rq_throttled(cfs_rq))
break;
cfs_rq->h_nr_running++;
flags = ENQUEUE_WAKEUP;
}
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
cfs_rq->h_nr_running++;
if (cfs_rq_throttled(cfs_rq))
break;
update_load_avg(se, 1);// 更新调度实体的负载load_avg_contrib和就绪队列的负载runnable_load_avg
update_cfs_shares(cfs_rq);
}
if (!se)
add_nr_running(rq, 1);
hrtick_update(rq);
}
2.5.5.1 enqueue_task_fair()->enqueue_entity()
把调度实体se添加到cfs_rq就绪队列中:
static void enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
/*task_fork_fair()函数中减掉了min_vruntime,现在在加入调度器时,再加上min_vruntime因为这个时候的min_vruntime是变化后的,现在加是比较准确的*/
if (!(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_WAKING))
se->vruntime += cfs_rq->min_vruntime;
update_curr(cfs_rq); // 更新当前进程的vruntime和该CFS就绪队列的min_vruntime
enqueue_entity_load_avg(cfs_rq, se);
account_entity_enqueue(cfs_rq, se);
update_cfs_shares(cfs_rq);
if (flags & ENQUEUE_WAKEUP) { // 处理刚被唤醒的进程
place_entity(cfs_rq, se, 0);// 对唤醒进程有一定的补偿,最多可以补偿一个调度周期的一般,即vruntime减去半个调度周期
enqueue_sleeper(cfs_rq, se);
}
update_stats_enqueue(cfs_rq, se);
check_spread(cfs_rq, se);
if (se != cfs_rq->curr)
__enqueue_entity(cfs_rq, se);// 把该调度实体添加到CFS就绪队列的红黑树中
se->on_rq = 1; // 置位sched_entity的on_rq成员为1,表示已经在CFS就绪队列中
if (cfs_rq->nr_running == 1) {
list_add_leaf_cfs_rq(cfs_rq);
check_enqueue_throttle(cfs_rq);
}
}
2.6 撤销进程
进程终止本身执行的代码,意味着该进程已经“死亡”,当这种情况发生时,必须通知内核释放该进程拥有的资源。
2.6.1 进程终止
进程终止一般方式是调用exit()库函数,该函数释放C函数所分配的资源,执行编程者所注册的每个函数,并结束从系统回收进程的那个系统调用。
- exit_group()系统调用,它终止整个线程组。do_group_exit()是实现这个系统调用的主要内核函数;
- exit()系统调用,它终止某一个线程,而不管该线程所属线程组中的所有其他进程。do_exit()是实现这个系统调用的主要内核函数;
2.6.2 do_group_exit()函数
do_group_exit()函数杀死属于current线程组的所有进程,它接受进程终止代号作为参数,进程终止代号可能是系统调用exit_group()(正常结束)指定的一个值,也可能是内核提供的一个错误代号(异常结束)。
void do_group_exit(int exit_code)
{
struct signal_struct *sig = current->signal;
BUG_ON(exit_code & 0x80); /* core dumps don't get here */
if (signal_group_exit(sig)) // 判断进程的SIGNAL_GROUP_EXIT标志是否不为0
exit_code = sig->group_exit_code;
else if (!thread_group_empty(current)) {
struct sighand_struct *const sighand = current->sighand;
spin_lock_irq(&sighand->siglock);
if (signal_group_exit(sig))
/* Another thread got here before we took the lock. */
exit_code = sig->group_exit_code;
else {
sig->group_exit_code = exit_code;
sig->flags = SIGNAL_GROUP_EXIT;
zap_other_threads(current); // 杀死current线程组中的其他进程
}
spin_unlock_irq(&sighand->siglock);
}
do_exit(exit_code); // 把进程的终止代号传递给do_exit()
}
2.6.3 do_exit()函数
所有进程的终止都由do_exit()函数来处理,这个函数从内核数据结构中删除对终止进程的大部分引用。它接受进程终止代号作为参数并执行下列操作:
-
把进程描述符的flag字段设置成PF_EXITING标志,表示该进程正在被删除;
-
删除
-
从动态定时器队列中删除进程描述符;
-
exit_mm(tsk)、exit_sem(tsk)、exit_shm(tsk)、exit_files(tsk)、exit_fs(tsk)等函数进程描述符分离出各种数据结构;释放资源;
-
exit_notify(tsk, group_dead); 通知所有"近亲"进程(父子、兄弟),更新亲属关系;
-
调用schedule(); 选择一个新的进程运行,调度程序忽略处于EXIT_ZOMBIE状态的进程;
2.7 小结
在do_fork()主函数中,copy_process()函数成功创建一个新的进程。对于vfork创建的子进程,首先要确保子进程先运行。
在调用exec或者exit之前,父子进程是共享数据的,在子进程调用exec或者exit之后,父进程才可以被调度运行,因此这里使用一个vfork_done完成量来达到阻塞父进程的作用。
wake_up_new_task()函数准备唤醒新创建的进程,也就是把进程加入调度器里接受调度运行,最终返回用户空间时,其返回值为进程的pid,而子进程返回用户空间时,其返回值为0;
三、调度器
Linux内核作为一个通用操作系统,需要兼顾各种各样类型的进程,比如实时进程、交互式进程、批处理进程等等,而调度器负责决定哪个进程投入运行,何时运行以及运行多长时间。
调度器可以看做可运行态进程之间分配有限的处理器时间资源的内核子系统,以实现系统资源最大限度的发挥作用,多进程才会有并发执行的效果。
schedule函数是理解调度操作的起点!
Linux调度器的一个杰出特性是:**它不需要时间片的概念。**经典的调度器对系统中的进程分别计算时间片,使进程运行到时间片用完,当所有进程的时间片都用完之后,就需要重新计算。而当前的调度器只考虑进程的等待时间,即进程在就绪队列中已经等待了多长时间即可。
每次调用调度器,它都会挑选具有最高等待时间的进程,把CPU提供给该进程。可运行进程是排队的,保存在一个队列中,所有的可运行进程都按时间在一个红黑树中排序,所谓时间即等待时间,等待CPU时间最长的保存在红黑树的最左侧,调度器下一次会考虑该进程,等待时间稍段的进程在该红黑树上从左到右排序。

模块化的结构被称为调度器类,有两种方法激活调度,第一种是直接激活,比如进程打算睡眠或出于其他原因放弃CPU;第二种是通过周期性机制,以固定的频率运行,不时检测是否有必要进行进程切换;称为通用调度器或核心调度器。
- 调度类用于判断接下来运行哪个进程;
- 在选中将要运行的进程后,必须执行底层任务切换。
- 每个进程刚好属于某一个调度类,必须执行底层人物切换!
在进程描述符中添加了优先级属性,成员解析具体如下:
task_struct节选:
{
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
struct sched_dl_entity dl;
#ifdef CONFIG_PREEMPT_NOTIFIERS
/* list of struct preempt_notifier: */
struct hlist_head preempt_notifiers;
#endif
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
int nr_cpus_allowed;
cpumask_t cpus_allowed;
....
}
- task_struct采用了3个成员来表示进程的优先级: int prio,、static_prio、 normal_prio;
- static_prio表示进程的静态优先级,静态优先级是进程启动时分配的优先级,他可以用nice和sched_setscheduler系统调用修改;
- normal_priority表示基于进程的静态优先级和调度策略计算出的优先级;
- rt_priortity:表示实时进程的优先级,数字越高,优先级越高级;
- shced_class:表示该进程所属的调度器类;
- se:se在task_struct中内嵌了一个sched_entity实例,调度器可以根据此操作各个task struct(se不是一个指针,因为该实例嵌入到task_struct中)
- policy:保存了对该进程应用的调度策略,Linux中支持了5种调度策略!
- **SCHED_NORMAL:**用于普通进程,属于完全公平调度CFS调度类;
- SCHED_BATCH和SCHED_IDLE也通过完全公平调度器来处理,不过可用于次要的进程;
- SCHED_RR和SCHED_FIFO用于实现软实时进程,SCHED_RR实现了一种循环方法,而SCHED_FIFO则使用先进先出机制,由实时调度器类处理。
- cpus_allowed是一个位域,在多处理器系统上使用,用来限制进程可以在哪些CPU上运行。
- run_list和time_slice是循环实时调度器所需要的,但不用于完全公平调度器。run_list是一个表头,用于维护包含各进程的一个运行表,而time_slice则指定进程可使用CPU的剩余时间段。
3.1 调度器类
调度器类提供了通用调度器和各个调度方法之间的关联,调度器类特定的数据结构中汇集了几个函数指针表示。
struct sched_class {
const struct sched_class *next;
// 向就绪队列添加一个新进程。在进程从睡眠状态变为可运行状态时,即发生该操作;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
// 提供逆向操作,将一个进程从就绪队列去除;
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
// 进程想要自愿放弃对处理器的控制权时,调用sched_yield系统调用,导致内核调用yield_task;
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
// 调用check_preempt_curr用一个新唤醒的进程来抢占当前进程,例如在wake_up_new_task唤醒新进程时,会调用该函数;
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
// pick_next_task用于选择下一个将要运行的进程;
struct task_struct * (*pick_next_task) (struct rq *rq, struct task_struct *prev);
// put_prev_task则在用另一个进程代替当前运行的进程之前调用;
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p);
void (*task_waking) (struct task_struct *task);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_move_group) (struct task_struct *p);
#endif
};
各个调度类都必须提供一个struct sched_class实例,调度类之间,实时进程最重要,在完全公平进程之前处理!而完全公平进程则优先于空闲进程,空闲进程只有CPU无事可做才会开始活动。
用户层应用程序无法直接与调度类交互,常量就需要和调度类之间提供适当的映射,SCHED_NORMAL、SCHED_BATCH和SCHED_IDLE映射到fair_sched_class,而SCHED_RR和SCHED_FIFO与rt_sched_class关联。fair_sched_class和rt_sched_class都是struct sched_class的实例,分别表示完全公平调度器和实时调度器。
CFS调度器的sched_class初始化在kernel/sched/fair.c下:
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
#ifdef CONFIG_SMP
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_waking = task_waking_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_common,
#endif
.set_curr_task = set_curr_task_fair,
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_move_group = task_move_group_fair,
#endif
};
[部分函数解析跳转](#2.5.3 .task_fork = task_fork_fair())
3.2 就绪队列->运行队列
核心调度器用于管理活动进程的主要数据结构称之为就绪队列,每个CPU都有自身的就绪队列,rq数据结构中记录了一个就绪队列所需要的全部信息,包括一个CFS调度器就绪队列数据结构struct cfs_rq、一个实施进程调度器就绪队列数据结构struct rt_rq和一个deadline调度器就绪数据结构struct dl_rq等等,每个活动进程只能出现在一个就绪队列中,所以在多个CPU上同时执行一个进程是不可能的。
**就绪队列是全局调度器许多操作的起点!**进程不是由就绪队列的成员直接管理的,这是各个调度器类的职责,因此在各个就绪队列中嵌入特定于调度器类的子就绪队列。
struct rq {
/* 运行队列锁 */
raw_spinlock_t lock;
unsigned int nr_running;
...
struct load_weight load;
unsigned long nr_load_updates;
u64 nr_switches;
struct cfs_rq cfs; // cfs调度器
struct rt_rq rt; // 实时进程调度器
struct dl_rq dl; // deadline调度器
...
unsigned long nr_uninterruptible;
struct task_struct *curr, *idle, *stop;
unsigned long next_balance;
struct mm_struct *prev_mm;
unsigned int clock_skip_update;
u64 clock;
u64 clock_task;
atomic_t nr_iowait;
...
#endif
...
};
- nr_running指定了队列上可运行进程的数目,不考虑其优先级或调度类;
- load提供了就绪队列当前符合的度量,就绪队列的权重信息;
- cpu_load用于跟踪此前的负荷状态;
- cfs和rt是嵌入子就绪队列,分别用于完全公平调度器和实时调度器;
- curr指向当前运行的进程的task_struct实例;
- idle指向idle进程的task_struct实例,也被称为idle线程,在无其他可运行进程时执行;
- clock和prev_raw_clock用于实现就绪队列自身的时钟。每次调用周期性调度器都会更新clock的值。
在SMP架构中,系统的所有就绪队列都在runqueues数组中,该数组的每个元素分别对应于系统中的一个CPU。在单处理器系统中,由于只需要一个就绪队列,数组只有一个元素。
具体可见kernel/sched.h:
DECLARE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
#define cpu_rq(cpu) (&per_cpu(runqueues, (cpu)))
#define this_rq() this_cpu_ptr(&runqueues)
#define task_rq(p) cpu_rq(task_cpu(p))
#define cpu_curr(cpu) (cpu_rq(cpu)->curr)
#define raw_rq() raw_cpu_ptr(&runqueues)
CFS调度器就绪队列数据结构如下:
struct cfs_rq {
struct load_weight load;
unsigned int nr_running, h_nr_running;
u64 exec_clock;
u64 min_vruntime; // 单步递增的值
#ifndef CONFIG_64BIT
u64 min_vruntime_copy;
#endif
struct rb_root tasks_timeline;
struct rb_node *rb_leftmost;
struct sched_entity *curr, *next, *last, *skip;
...
};
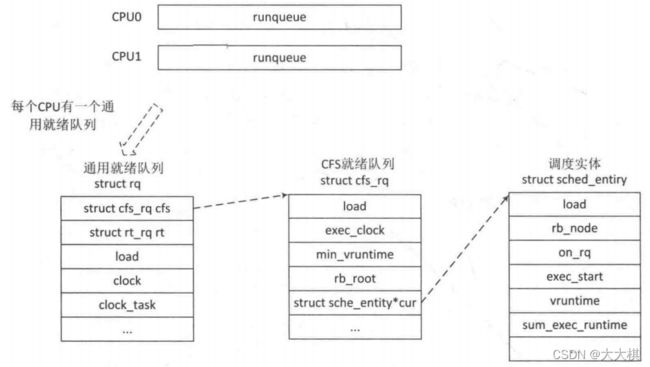
CFS调度器不再有时间片的概念,但是必须维护每个进程运行的时间记账,以确保每个进程公平分配它的处理器时间内运行,CFS使用调度器实体结构如下:
struct sched_entity {
struct load_weight load; /* 用于均衡负载,表示该调度实体的权重 */
struct rb_node run_node; /* 用于红黑树上排序的节点 */
struct list_head group_node;
unsigned int on_rq; /* 表示该实体当前是否在就绪队列上接受调度,在进程注册到就绪队列时,嵌入的sched_entity实例的on_rq成员设置为1,否则为0。 */
// 以下数据提供给计算虚拟时间需要的信息
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
#ifdef CONFIG_SCHEDSTATS
struct sched_statistics statistics;
#endif
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
#endif
#ifdef CONFIG_SMP
/* 每个实体平均负载跟踪 */
struct sched_avg avg; // 表示该调度实体的负载信息
#endif
};
- load指定了权重,决定了各个实体占队列总负荷的比例。计算负荷权重是调度器的一项重任,因为CFS所需的虚拟时钟的速度最终依赖于负荷;
- run_node是标准的树结点,使得实体可以在红黑树上排序;
- on_rq表示该实体当前是否在就绪队列上接受调度;
- 在进程被撤销CPU时,其当前sum_exec_runtime值保存到prev_exec_runtime。
3.3.1 处理优先级
内核使用0~139的数值表示进程的优先级,数值越低优先级越高。优先级0~99给实时进程使用,100~139给普通进程使用。另外在用户空间有一个传统的变量nice值[-20~19]映射到普通进程的优先级,即100~139;

struct task_struct {
...
int prio, static_prio, normal_prio;
unsigned int rt_priority;
...
}
static_prio(静态优先级),不随时间而改变,在启动的时候就分配了,用户可以通过nice或者sched_setscheduler等系统调用修改static_prio值。,内核不存储nice值,由static_prio取代。内核中提供了两个宏实现nice与prio互相转换:
#define NICE_TO_PRIO(nice) ((nice) + DEFAULT_PRIO)
#define PRIO_TO_NICE(prio) ((prio) - DEFAULT_PRIO)
normal_prio(普通优先级)是基于static_prio和调度策略计算出来的优先级,在创建进程时会继承父进程的normal_prio。
prio(动态优先级),是调度类考虑的优先级;
3.3.1.1 计算优先级
单独考虑进程的静态优先级是不够的,需要结合上述的3个优先级,虽然对于普通进程来说,normal_prio等同于static_prio;对于实时进程来说,会根据rt_priority重新计算。
通过effective_prio函数进行计算:
static int effective_prio(struct task_struct *p)
{
p->normal_prio = normal_prio(p);
/* 如果是实时进程或已经提高到实时优先级,则保持优先级不变。否则,返回普通优先级 */
if (!rt_prio(p->prio))
return p->normal_prio;
return p->prio;
}
这里计算了普通优先级,并保存到normal_priority,函数rt_prio会检测普通优先级是否在实时范围中,即是否小于RT_RT_PRIO,该检测与调度类无关,只涉及优先级的数值。
如果处理普通进程,不涉及实时调度。在这种情况下,normal_prio()只是返回静态优先级。结果很简单:所有3个优先级都是同一个值,即静态优先级!
普通优先级需要根据普通进程和实时进程进行不同的计算,__normal_prio的只是用于计算普通进程,而实时进程的普通优先级计算需要根据rt_priority设置,因为rt_priority越大,实时进程优先级越高,而内核内部优先级恰恰相反,值越低优先级越高,所以实时进程在内核内部的优先级数值,正确的算法是MAX_RT_PRIO - 1 - p->rt_priority。:
static inline int normal_prio(struct task_struct *p)
{
int prio;
if (task_has_dl_policy(p))
prio = MAX_DL_PRIO-1; //
else if (task_has_rt_policy(p))
prio = MAX_RT_PRIO-1 - p->rt_priority; // 计算实时进程优先级
else
prio = __normal_prio(p); // 普通优先级,直接返回静态优先级
return prio;
}
针对上次不同类型进程的计算,有如下结果:
| 进程类型/优先级 | static_prio | normal_prio | prio |
|---|---|---|---|
| 非实时进程 | static_prio | static_prio | static_prio |
| 优先级提高非实时进程 | static_prio | static_prio | prio不变 |
| 实时进程 | static_prio | MAX_RT_PRIO-1-rt_priority | prio不变 |
3.3.1.2 负荷权重
进程不仅仅通过简单的优先级进行重要性分级,而且还需要考虑负荷权重!(其保存在task_struct->se.load中)。weight是调度实体的权重,inv_weight是inverse weight的缩写,它是权重的一个中间计算。该值根据进程的类型以及静态优先级计算负荷权重,由set_load_weight完成;
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
在内核中,负荷权重也与nice相关,内核提供了两个数组,具体详见源码 kernel/sched/sched.h:
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
static const u32 prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
进程每降低一个nice值,就多获得10%的CPU时间,反之则放弃10%的CPU时间,具体转换表如上;内核约定 nice=0的权重为1024,其他nice值对应的权重值可以通过查上表或者计算可得。CFS调度器抛弃以前固定的时间片和固定调度周期的算法,采用的是进程权重值得比重来量化和计算实际运行时间,另外引入虚拟时钟的概念,每个进程的虚拟时间是实际运行时间相对nice值为0的权重的比例值。
prio_to_wmult[]表中的计算公式如下:
i n v _ w e i g h t = 2 32 / w e i g h t inv\_weight=2^{32}/weight inv_weight=232/weight
inv_weight指权重被倒转,方便后面计算使用。
在CFS调度中,有一个计算虚拟时间的核心函数是calc_delta_fair(),它的计算公式为:
v r u n t i m e = d e l t a _ e x e c ∗ n i c e _ 0 _ w e i g h t / w e i g h t vruntime=delta\_exec*nice\_0\_weight/weight vruntime=delta_exec∗nice_0_weight/weight
其中vruntime表示进程虚拟的运行时间,delta_exec表示实际运行时间,nice_0_weight表示nice为0的权重值,weight表示该进程的权重值;

当然vruntime一般不会相同,CFS总是在红黑树中选择vruntime最小的进程进行调度,优先级高的进程总会被优先选择,随着vruntime的增长,优先级高的进程也有机会运行!
内核提供以下函数来查表获取权重信息,并保存到struct load_weight中:
#define WEIGHT_IDLEPRIO 3
#define WMULT_IDLEPRIO 1431655765
static void set_load_weight(struct task_struct *p)
{
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/* SCHED_IDLE任务的权重最小 */
if (idle_policy(p->policy)) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}
3.3.2 核心调度器
调度器的实现基于两个函数:**周期性调度器函数和主调度器函数。**这些函数根据现有进程的优先级分配CPU时间。
3.3.2.1 周期性调度器
周期性调度器在scheduler_tick中实现;如果系统正在活动中,内核会按照频率HZ自动调用该函数;如果没有进程在等待调度,那么在计算机电力供应不足的情况下,也可以关闭该调度器以减少电能消耗,该函数主要有下面两个任务:
- 管理内核中与整个系统和各个进程的调度相关的统计量,其执行的主要操作是对各种计数器加1;
- 激活负责当前进程的调度类的周期性调度方法;
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
sched_clock_tick();
raw_spin_lock(&rq->lock);
update_rq_clock(rq); // 更新就绪队列时钟(负责更新就绪队列的cpu_load[])
curr->sched_class->task_tick(rq, curr, 0);
update_cpu_load_active(rq);
calc_global_load_tick(rq);
raw_spin_unlock(&rq->lock);
perf_event_task_tick();
#ifdef CONFIG_SMP
rq->idle_balance = idle_cpu(cpu);
trigger_load_balance(rq);
#endif
rq_last_tick_reset(rq);
}
task_tick的实现方式取决于底层的调度器类,如果当前进程应该被重新调度,那么调度器类方法会在task_struct中设置TIF_NEED_RESCHED标志,以表示该请求,而内核会在接下来的适当时机完成该请求。
3.3.3 主调度器
在内核中许多地方,如果需要将CPU分配与当前活动进程不同的另一个进程,都会直接调用**主调度器函数(schedule)。**在从系统调用返回之后,内核也会检查当前进程是否设置了重调度标志TIF_NEED_RESCHED,例如,前述的scheduler_tick就会设置该标志。如果是这样,则内核会调用schedule。该函数假定当前活动进程一定会被另一个进程取代。
调度的时机有三种:
- 阻塞操作:互斥量(mutex)、信号量(semaphore)、等待队列(waitqueue)等;
- 如前面所说的,在中断返回前和系统调用返回用户空间时,检查TIF_NEED_RESCHED,判断是否需要调度;
- 将要被唤醒的进程(wakeups)不会马上就调用schedule()的,而是会被添加到CFS就绪队列中,并且设置TIF_NEED_RESCHED标志,具体什么时候被调度需要再根据内核是否具有可抢占功能分两种情况:
- 内核可抢占:
- 如果唤醒动作发生在系统调用或者异常处理上下文中,在下一次调用preempt_enable()时会检查是否需要抢占调度;
- 如果唤醒动作发生在硬中断上下文中,硬件中断处理返回前夕(不管中断是发生在内核空间还是用户空间)都会检查是否需要抢占当前进程;
- 内核不可抢占:
- 当前进程调用cond_resched()会检查是否要调度;
- 主动调度调用schedule();
- 系统调用或者异常处理返回用户空间时;
- 中断处理完成返回用户空间时;
- 内核可抢占:
对于可能调用schedule的函数,一般都会使用到**__sched**作为前缀,**前缀的目的在于将相关函数的代码编译后,放到目标文件的一个特定的段中,即.sched.text中!**包括schedule自身:
asmlinkage __visible void __sched schedule(void)
{
struct task_struct *tsk = current;
sched_submit_work(tsk);
do {
preempt_disable();
__schedule(false);
sched_preempt_enable_no_resched();
} while (need_resched());
}
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
rcu_note_context_switch();
prev = rq->curr;
if (unlikely(prev->state == TASK_DEAD))
preempt_enable_no_resched_notrace();
schedule_debug(prev);
if (sched_feat(HRTICK))
hrtick_clear(rq);
smp_mb__before_spinlock();
raw_spin_lock_irq(&rq->lock);
lockdep_pin_lock(&rq->lock);
rq->clock_skip_update <<= 1; /* promote REQ to ACT */
switch_count = &prev->nivcsw;
if (!preempt && prev->state) {
if (unlikely(signal_pending_state(prev->state, prev))) {
prev->state = TASK_RUNNING;
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP);
prev->on_rq = 0;
if (prev->flags & PF_WQ_WORKER) {
struct task_struct *to_wakeup;
to_wakeup = wq_worker_sleeping(prev, cpu);
if (to_wakeup)
try_to_wake_up_local(to_wakeup);
}
}
switch_count = &prev->nvcsw;
}
if (task_on_rq_queued(prev))
update_rq_clock(rq);
next = pick_next_task(rq, prev);// 让进程调度器从就绪队列中选择一个最合适的进程next
clear_tsk_need_resched(prev); // 清除当前运行进程task_struct中的重调度标志TIF_NEED_RESCHED
clear_preempt_need_resched();
rq->clock_skip_update = 0;
if (likely(prev != next)) {
rq->nr_switches++;
rq->curr = next;
++*switch_count;
trace_sched_switch(preempt, prev, next);
rq = context_switch(rq, prev, next); /* unlocks the rq 切换到next进程运行*/
cpu = cpu_of(rq);
} else {
lockdep_unpin_lock(&rq->lock);
raw_spin_unlock_irq(&rq->lock);
}
balance_callback(rq);
}
3.4 小结
内核根据进程的优先级属性支持多个调度类,包括deadline、realtime、CFS、idle调度类,为了更好的管理定义了很多数据结构以及一些重要的变量,包括就绪队列struct rq、CFS调度器就绪队列struct cfs_rq、调度实体struct sched_entity、调度平均负载struct sched_avg、虚拟时间vruntime、min_vruntime等;
- 每个CPU有一个通用的就绪队列struct rq;
- 每个进程task_struct中内嵌一个调度实体 struct sched_entity se结构体;
- 每个通用就绪队列struct rq数据结构中内嵌CFS就绪队列,RT就绪队列和deadline就绪队列结构体;
- 每个调度实体struct sched_entity se内嵌一个权重struct load_weight load结构体;
- 每个调度实体struct sched_entity se内嵌一个平均负载struct sched_av avg结构体;
- 每个调度实体struct sched_entity se有一个vruntime成员表示该调度实体的虚拟时钟;
- 每个调度实体struct sched_entity se有一个on_rq成员表示该调度实体是否在就绪队列中接受调度;
- 每个CFS就绪队列struct cfs_rq中内嵌一个权重struct load_weight load结构体;
- 每个CFS就绪队列struct cfs_rq中有一个min_vruntime来跟踪该队列红黑树中最小的vruntime值;
- 每个CFS就绪队列struct cfs_rq中有一个runnable_load_avg变量跟踪该队列中总平均负载;
- task_struct数据结构中有一个on_cpu表示该进程是否在执行状态中,on_rq成员标志该进程的调度状态。与调度实体中的on_rq成员不同;