无需训练代码,推理性能提升1.4~7.1倍,业界首个自动模型压缩工具开源!

导读
模型压缩的价值与意义
模型压缩技术,一般是指在基础模型结构的基础上,通过精简模型结构、减少模型参数量或者降低模型存储量化位数,从而减小计算量,降低所需存储资源,提升模型推理速度。
端侧设备相关场景要求响应速度快、内存占用少和能耗低,模型压缩可以有效提升模型推理速度、减少模型所需存储空间和降低模型能耗。在超大模型落地应用场景中,模型压缩可以降本增效和低碳环保,从而提升产品竞争力。

图1 端侧和边侧应用对模型压缩的需求
模型压缩面临的技术挑战
传统的模型压缩技术是比较高门槛的技术,其难度主要来源于以下4点:
传统模型压缩算法依赖训练
在不考虑时间成本的情况下,当前最好的模型压缩方法都依赖于训练过程。但是由于没有原始数据或者算法复杂度,用户无法拿到训练代码也无法复现训练过程。
模型压缩算法种类繁多、调参难度大
仅以离线量化(Post Training Quantization)为例,经典常用的离线量化算法就有8种(包括KLD,ABS_MAX,AVG,MSE,HIST,EMD,Bias Correctiony以及AdaRound),每种离线量化算法有2~4个参数对压缩的效果有影响。如何针对特定场景下的模型,高效地选择合适的离线量化算法及其参数,是困扰模型压缩技术项目落地的主要问题。
模型压缩多种策略组合复杂度
除了离线量化,模型压缩还有剪枝、蒸馏等多种压缩技术,随着模型小型化需求的增加,多种压缩算法也可叠加组合使用。压缩算法之间会相互影响,其效果不能简单累加 。如何从多种候选压缩算法中,选择合适的一组压缩算法,这件事深度依赖人工经验和长期的实验。
被压缩模型结构众多、部署环境具有复杂性
模型结构方面,主干网络层出不穷,激活函数持续演进。不同的结构和激活函数对压缩的敏感性不同,可无损压缩的比例也不同。部署环境方面,芯片特性、推理库的优化细节,都是在压缩时需要考虑的因素。综合考虑模型结构和部署环境,靠手动压缩,很难达到预期目标。
为了解决上述问题,PaddleSlim结合业务实践中的上百个模型优化经验,沉淀出一套自动模型压缩工具(ACT, Auto Compression Toolkit),大幅降低模型压缩的技术门槛。本次发布主要包括以下内容:
ACT重点模型效果提升示例
ACT核心技术方案详解
快速开始使用ACT
更多模型效果提升Benchmark
小编送上传送门:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
ACT自动压缩工具效果展示
相比传统的模型压缩方法,自动化压缩代码量减少50%以上。传统的压缩方法,比如量化训练和稀疏化训练,不仅需要用户提供模型结构定义代码,还会侵入修改用户的训练代码。自动化压缩则是直接加载推理模型,新增1~2行代码调用压缩API即可。
自动化压缩精度与手工压缩基本持平。在PP-YOLOE模型上,效果还优于手动压缩,如图2所示。
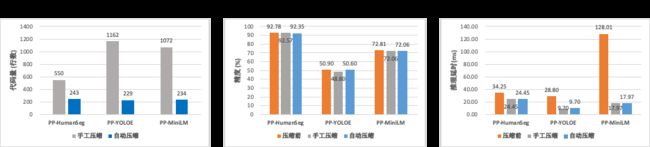
图2 自动化压缩效果
自动化压缩后的推理性能收益也基本与手工压缩持平,相比压缩前,推理速度可以提升1.4~7.1倍。
除了以上3个不同场景下的典型模型,我们还在更多开源模型上验证了自动化压缩的效果,主要覆盖了图像分类、图像语义分割、 NLP预训练模型和图像目标检测4个场景。另外,自动化压缩还支持PyTorch、TensorFlow产出的推理模型。
ACT核心技术方案详解
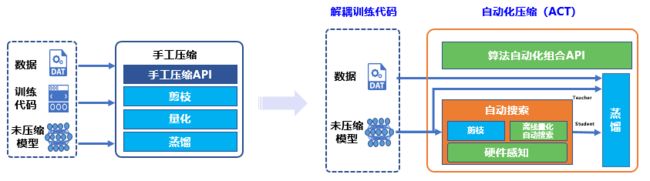
图3 传统手工压缩与自动化压缩工具对比
相比于传统手工压缩,自动化压缩的“自动”主要体现在4个方面:解耦训练代码、离线量化超参搜索、算法自动组合和硬件感知。
解耦训练代码
用户只用提供推理模型和无标注数据,就可以执行量化训练、稀疏训练等依赖训练过程的压缩方法。
自动化压缩功能利用了知识蒸馏技术,自动为推理模型添加训练逻辑。首先,加载用户指定的推理模型文件,并将推理模型在内存中复制一份,作为知识蒸馏中的教师模型,原模型则作为学生模型。然后,自动地分析模型结构,寻找适合添加蒸馏loss的层,一般是最后一个带可训练参数的层。最后,教师模型通过蒸馏loss监督原模型的稀疏训练或量化训练。过程如图4所示。
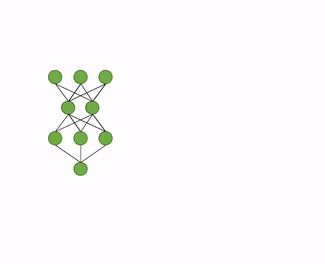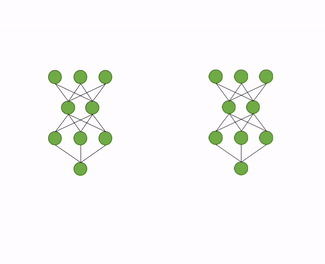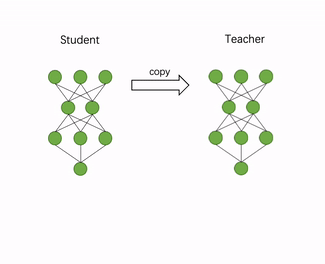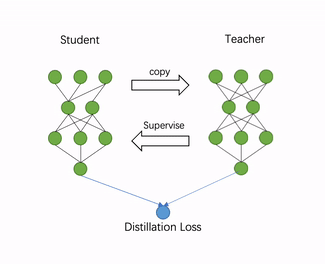
图4 自动化压缩流程
经对来自各个场景30个模型验证,该方法适用于图像分类、图像语义分割、BERT/ERNIE预训练模型和部分图像目标检测模型。除了以上完全自动化的使用方式,用户还可以在配置文件中修改知识蒸馏相关的参数。配置文件示例如下:
Distillation:
# alpha: 蒸馏loss所占权重;可输入多个数值,支持不同节点之间使用不同的ahpha值
alpha: 1.0
# loss: 蒸馏loss算法;可输入多个loss,支持不同节点之间使用不同的loss算法
loss: l2
# node: 蒸馏节点,即某层输出的变量名称,可以选择:
# 1. 使用自蒸馏的话,蒸馏节点仅包含学生网络节点即可, 支持多节点蒸馏;
# 2. 使用其他蒸馏的话,蒸馏节点需要包含教师网络节点和对应的学生网络节点,
# 每两个节点组成一对,分别属于教师模型和学生模型,支持多节点蒸馏。
node:
- relu_30.tmp_0
# teacher_model_dir: 保存预测模型文件和预测模型参数文件的文件夹名称
teacher_model_dir: ./inference_model
# teacher_model_filename: 预测模型文件,格式为 *.pdmodel 或 __model__
teacher_model_filename: model.pdmodel
# teacher_params_filename: 预测模型参数文件,格式为 *.pdiparams 或 __params__
teacher_params_filename: model.pdiparams用户可以在上述配置文件中,指定知识蒸馏所用的损失函数类型,添加损失函数的层,也可以将教师模型指定为其它更大、效果更好的模型。
离线量化自动搜索
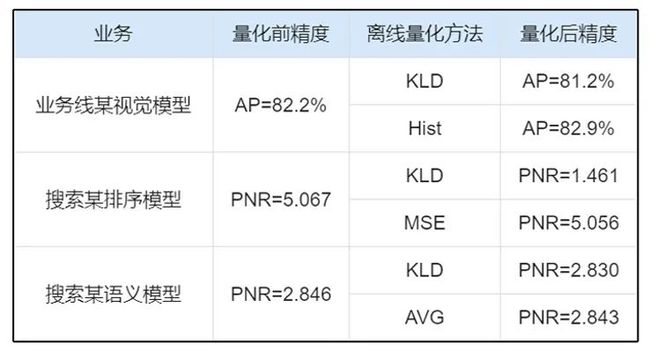
表1 各业务模型适用不同的量化方法
举例来说,在搜索场景中,模型多、迭代速度快,离线量化是最适合该场景的压缩方法。如上表所示,在实践中发现,不同的业务模型适用不同的离线量化算法。受此驱动,PaddleSlim实现了多种离线量化算法。如下图所示,不同的离线量化算法在MobileNetV1模型上表现各异,部分算法还可以组合使用。
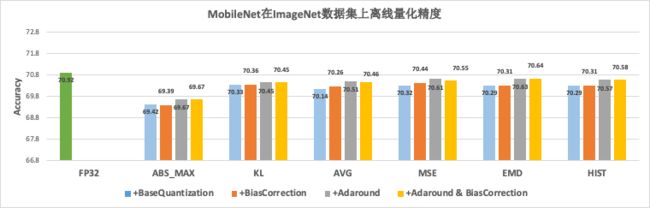
图5 离线量化精度对
面对多种离线量化算法及其参数的组合,靠人工实验,难以跟上模型迭代的速度。PaddleSlim借助随机森林超参搜索方法改进了离线量化过程,将原来一周的工作量缩短至1~2天。

图6 随机森林超参搜索示意图
使用离线量化自动搜索,相比人工调参,模型的效果有普遍的提升,如下表所示。

算法自动组合
除了丰富的离线量化算法,PaddleSlim还针对不同部署环境的特性,实现了多种稀疏化方法。非结构化稀疏可用于部署在ARM CPU上的模型,ASP半结构化稀疏可用于部署在NVIDIA GPU上的模型。卷积通道稀疏虽然可以用于各种部署环境,但是根据经验,它在NVIDIA GPU上的推理加速效果不如在CPU上明显。
为了更极致的压缩取得更好的加速,通常可以将稀疏化方法和量化方法叠加使用。两种方法的叠加效果不仅取决于部署环境,还取决于模型结构。自动压缩功能会分析模型结构,并根据模型结构特点和用户指定的部署环境,自动选择合适的组合算法。
硬件感知
在选定组合压缩算法后,如何确定各个压缩算法的参数,则是另一个难点。压缩算法的参数设定与部署环境密切相关,需要考虑芯片特性、推理库的优化程度等各种因素。硬件感知模块作为部署环境的代理,建模并学习部署环境的特性,为参数设定提供性能查询服务。
受推理库算子融合等优化的约束,压缩参数与推理速度的关系并不是线性的。以稀疏为例,推理库可能支持大于75%稀疏度的矩阵乘运算,也就是60%稀疏度和10%稀疏度都没有推理加速效果。因此,设置60%的稀疏度完全没有意义。另外,稀疏的加速效果还受矩阵乘算子的输入形状影响。总之,在模型结构多样化和部署环境多样化的背景下,靠人工经验或简单的公式,无法准确评估压缩参数与推理速度的关系。
为此,我们开发了硬件延时预估功能。该功能利用数据表结合深度学习模型的方式,对影响推理速度的因素进行建模,为组合算法的参数设置提供指导信息。
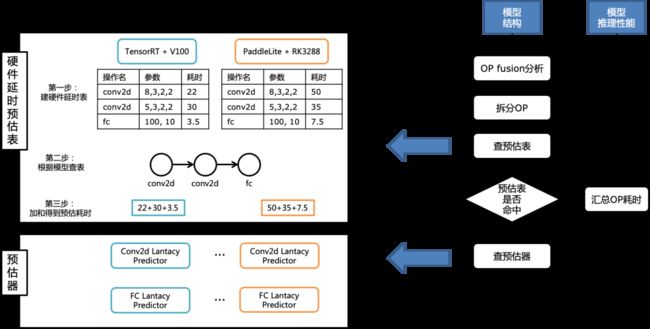
图7 延时预估功能原理图
如图7左侧所示,硬件延时预估功能的两个关键模块为延时预估表和预估器:
预估表:针对每种部署环境,采样并测试大量算子的推理性能,并记录在数据表中。数据表中的每一行包括算子类型,算子本身的参数(如:输入形状stride、padding等),稀疏度,是否量化等信息。预估表可以准确预估命中的算子的信息,但是难以覆盖算子所有可取的参数。
预估器:使用预估表中的数据,为每类算子训练一个预测器,用于预测推理性能。预估器的准确性不如预估表,但是有更强的泛化能力,可以覆盖算子参数的更多取值。
该功能的工作流程如图7右侧流程图所示:
第一步:分析模型结构,对推理模型做OP融合(为了得到最终在部署时执行的OP);
第二步:对第一步产出的推理模型中的所有OP,依次查预估表,如果无法命中,则查预估器;
第三步:累加所有OP的耗时得到候选模型最终的推理性能。
在以上功能的支持下,我们可以快速得到各种压缩参数下的模型推理性能,再根据用户指定的在特定硬件的推理加速倍数,锁定少量候选模型,最后逐个验证候选模型的精度。
快速开始使用ACT
在准备好基础数据集和DateLoader的基础上,仅需要少量代码,就可以实现自动压缩任务。
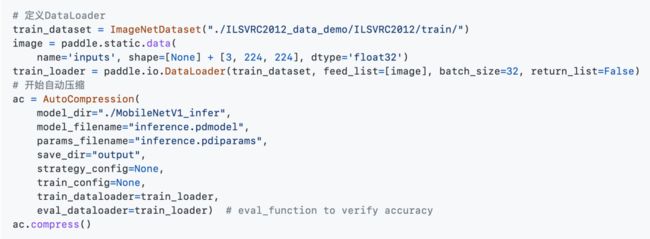
在自动压缩完成之后,分别执行精度评估脚本和速度评估脚本,可以分别获得自动压缩前后的精度和速度对比,如下表所示。

完整示例请参考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression
更多模型效果提升
Benchmark
图像分类
自动化压缩不仅可以有效压缩ResNe这种部署于服务端的大模型,还可以作用于MobileNet、ShuffleNet等为移动端设计的小模型。经过自动化压缩,各种模型在ARM CPU和NVIDIA GPU上的推理耗时都明显减少。
值得强调的是,PP-LCNetv2和PP-HGNet是飞桨模型团队针对特定芯片设计的高效模型结构。在人工深度优化的基础上,自动化压缩可以进一步提升这些模型的推理性能。
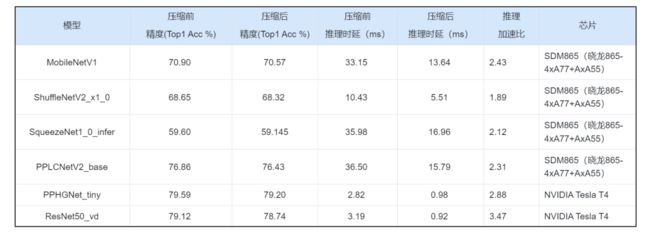
关于测试环境、数据集等更多信息,请参考图像分类模型自动压缩示例。
图像语义分割
自动化压缩在PP-HumanSeg-Lite、PP-LiteSeg、HRNet和UNet等模型上,精度几乎无损,在NVIDIA GPU上的加速达1.23~1.49倍。

关于测试环境、数据集等更多信息,请参考图像语义分割模型自动压缩示例。
NLP中文预训练模型
PP-MiniLM是在BERT-base模型基础上,通过知识蒸馏得到的小模型,并在飞桨自然语言处理模型库PaddleNLP中开源。PP-MiniLM在NVIDIA T4上的推理性能是BERT-base的2倍。在PP-MiniL模型基础上,进一步使用自动化压缩技术,在保证7个中文任务上平均得分几乎无损的情况下,可进一步将推理速度提升7倍以上。

关于测试环境、数据集等更多信息,请参考:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/nlp
其他框架的模型压缩效果
除了对飞桨模型的压缩效果显著,PaddleSlim自动化压缩还支持其它框架产出的推理模型。
以Hugging Face开源的PyTorch实现的英文预训练模型BERT-base为例,如下表所示。自动化压缩之后,在GLUE数据集上的平均准确率有略微提升。

测试环境:NVIDIA Tesla T4 GPU, CUDA 11.2, cuDNN 8.0, TensorRT 8.4, batch_size: 40, seqence length: 128
基于PyTorch的YOLOv5s模型和YOLOv6s模型自动化压缩效果如下:

mAP的指标均在COCO val2017数据集中评测得到
测试环境:
NVIDIA Tesla T4 GPU, TensorRT 8.4.1, batch_size=1, input_shape=640X640
基于TensorFlow的MobileNetV1模型上的自动压缩效果如下:

Top1_Acc是在ImageNet1k分类数据集上测试得到
测试环境:骁龙865 4A77 4A55
具体压缩方法请参考:
基于Hugging Face的BERT自动化压缩示例:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_huggingface
基于PyTorch的YOLOv5自动化压缩示例:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression/pytorch_yolov5
私享线上交流会
为了充分和开发者交流产品使用中遇到的难题,7月14日晚20:30,PaddleSlim产研团队核心成员将和进群开发者一起召开一次线上腾讯会议讨论会,针对性讨论目前大家遇到的问题与未来需求,欢迎大家扫码进群,获取线上会议链接!限定200席,报满为止。
扫码报名线上交流会

想了解更多自动模型压缩工具产品信息,可以参看github或点击阅读原文详细了解:
https://github.com/PaddlePaddle/PaddleSlim/tree/develop/example/auto_compression

关注【飞桨PaddlePaddle】公众号
获取更多技术内容~