openresty lua-resty-mlcache多级缓存
openresty lua-resty-mlcache多级缓存
官网:https://github.com/thibaultcha/lua-resty-mlcache
多级缓存
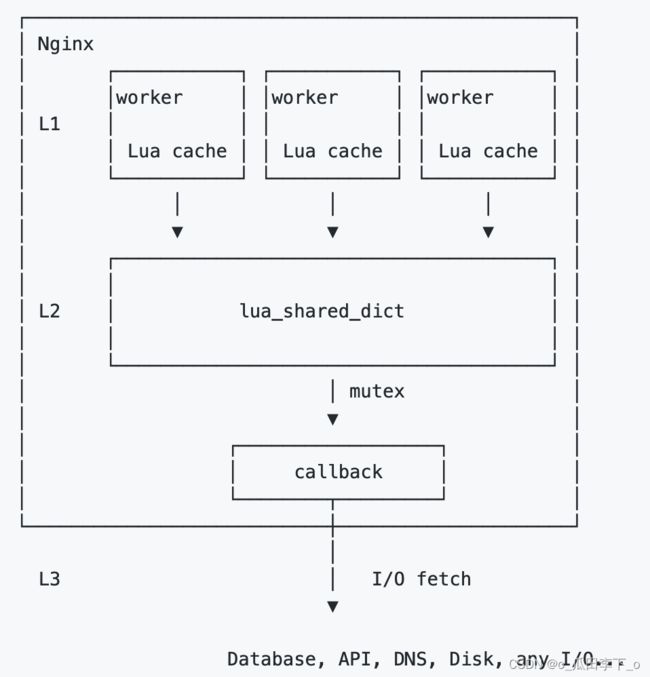
一级缓存:使用lrucache存储最常使用的数据,每个worker单独使用一份内存
二级缓存:使用lua_shared_dict存储共享数据,当一级缓存没有命中时,到二级缓存中读取数据
三级缓存:一、二级缓存没有命中,就从后端读取数据(使用lock加锁,避免大量请求同时访问),并将数据存储到二级缓存,和其他worker共享
创建缓存实例
new:创建缓存实例
语法格式:cache, err = mlcache.new(name, shm, opts?)
* 创建缓存实例,如果创建失败,返回nil、错误信息
* name:缓存实例的名称,如果不同的缓存实例name相同,则数据共享
* shm:lua_shared_dict共享缓存名称,如果不同的mlcache的shm相同,则数据共享
* opts:可选参数
* lru_size:一级缓存大小,默认100
* ttl:缓存过期时间,单位为秒,设置为0表示永不过期,默认30
* neg_ttl:当三级缓存返回nil时,缓存过期时间,单位为秒,设置为0表示永不过期,默认5
* resurrect_ttl:当3级缓存返回nil,延长过期缓存时间,单位为秒
* lru:使用的lua-resty-lrucache实例
* shm_set_tries:缓存重试次数
* shm_miss:the name of a lua_shared_dict. When specified, misses
(callbacks returning nil) will be cached in this separate lua_shared_dict
单独使用额外的共享空间存储三级接口返回的nil值,可使原来的缓存不过期
* shm_locks:The name of a lua_shared_dict. When specified,
lua-resty-lock will use this shared dict to store its lock
* resty_lock_opts:Options for lua-resty-lock instances. When mlcache runs the
L3 callback, it uses lua-resty-lock to ensure that a single
worker runs the provided callback
* ipc_shm:使用共享空间进行一级缓存同步
If you wish to use set(), delete(), or purge(), you must provide
an IPC (Inter-Process Communication) mechanism for workers to
synchronize and invalidate their L1 caches
* ipc:Like the above ipc_shm option, but lets you use the IPC library
of your choice to propagate inter-worker events
* l1_serializer:缓存序列化
Its signature and accepted values are documented under the
get() method, along with an example. If specified, this function
will be called each time a value is promoted from the L2 cache
into the L1 (worker Lua VM)
示例:创建分级缓存
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("my_cache", "cache_shared_dict", {
lru_size = 1000, -- hold up to 1000 items in the L1 cache (Lua VM)
ttl = 3600, -- caches scalar types and tables for 1h
neg_ttl = 60 -- caches nil values for 60s
})
if not cache then
error("could not create mlcache: " .. err)
end
示例:创建多个分级缓存,二级缓存使用相同空间
local mlcache = require "mlcache"
local cache_1 = mlcache.new("cache_1", "cache_shared_dict", { lru_size = 100 })
local cache_2 = mlcache.new("cache_2", "cache_shared_dict", { lru_size = 1e5 })
in the above example, cache_1 is ideal for holding a few, very large values. cache_2 can be used to hold a large number of small values.
* cache_1:存储少量的大值
* cache_2:存储大量的小值
Both instances will rely on the same shm: lua_shared_dict cache_shared_dict 2048m;.
Even if you use identical keys in both caches, they will not conflict with each
other since they each have a different namespace
* 两个分级缓存都使用相同的shm(共享缓存,二级缓存)
* 因为有不同的命名空间,即使key相同,cache_1、cache_2也不会冲突
示例:一级缓存使用共享空间同步
local mlcache = require "resty.mlcache"
local cache, err = mlcache.new("my_cache_with_ipc", "cache_shared_dict", {
lru_size = 1000,
ipc_shm = "ipc_shared_dict"
})
获取缓存值
get:获取缓存值
语法格式:value, err, hit_level = cache:get(key, opts?, callback?, ...)
Perform a cache lookup. This is the primary and most efficient method
of this module. A typical pattern is to not call set(), and let get()
perform all the work.
* 执行缓存查找
When this method succeeds, it returns value and no error. Because nil
values from the L3 callback can be cached (i.e. "negative caching"),
value can be nil albeit already cached. Hence, one must rely on the
second return value err to determine if this method succeeded or not.
* 方法调用成功,返回value、没有错误输出
* 因为三级缓存可能返回nil,需要对err进行判断,是否出错
The third return value is a number which is set if no error was
encountered. It indicated the level at which the value was fetched: 1
for L1, 2 for L2, and 3 for L3.
* hit_level:数据值是从哪个缓存中获取的
* 1:一级缓存、2:二级缓存、3:三级缓存
If an error is encountered, this method returns nil plus a string
describing the error
* 如果发生错误,返回nil、错误信息
The first argument key is a string. Each value must be stored
under a unique key
* 第一个参数key:缓存名称,需要唯一标识
* opts:可选参数
* ttl:缓存过期时间,单位为秒,设置为0表示永不过期,默认从缓存实例继承
* neg_ttl:当三级缓存返回nil时,缓存过期时间,单位为秒,设置为0表示永不过期,默认从缓存实例继承
* resurrect_ttl:当3级缓存返回nil,延长过期缓存时间,单位为秒
* shm_set_tries:缓存重试次数
* l1_serializer:缓存序列化
Its signature and accepted values are documented under the
get() method, along with an example. If specified, this function
will be called each time a value is promoted from the L2 cache
into the L1 (worker Lua VM)
callback:回调函数,可选
If provided, it must be a function whose signature and return
values are documented in the following example
* 如果设置了,必须是一个函数
* 返回结果:value, err, ttl
-- arg1, arg2, and arg3 are arguments forwarded to the callback from the
-- `get()` variadic arguments, like so:
-- cache:get(key, opts, callback, arg1, arg2, arg3)
* ars1、arg2、arg3是get方法中紧跟在callback后面的参数
* 返回3个值:value、err、ttl
local function callback(arg1, arg2, arg3)
-- I/O lookup logic
-- ...
-- value: the value to cache (Lua scalar or table)
-- err: if not `nil`, will abort get(), which will return `value` and `err`
-- ttl: override ttl for this value
-- If returned as `ttl >= 0`, it will override the instance
-- (or option) `ttl` or `neg_ttl`.
-- If returned as `ttl < 0`, `value` will be returned by get(),
-- but not cached. This return value will be ignored if not a number.
return value, err, ttl
end
没有提供回调函数
If callback is not provided, get() will still lookup the requested key in
the L1 and L2 caches and return it if found. In the case when no value is
found in the cache and no callback is provided, get() will return nil, nil,
-1, where -1 signifies a cache miss (no value). This is not to be confused
with return values such as nil, nil, 1, where 1 signifies a negative cached
item found in L1 (cached nil)
* 如果没有设置回调函数,get方法会在一级、二级缓存中查找缓存
* 如果没有找到value,并且没有callback,返回nil、nil、-1(表示没有找到缓存)
* 如果在一级缓存中找到缓存,并且value为nil,则返回nil、nil、1
提供了回调函数
When provided a callback, get() follows the below logic:
* 如果提供了回调函数,执行以下查询过程
query the L1 cache (lua-resty-lrucache instance). This cache lives in the Lua VM, and as such, it is the most efficient one to query.
if the L1 cache has the value, return it.
if the L1 cache does not have the value (L1 miss), continue.
* 查询一级缓存,如果找到返回值
* 如果没有找到,到二级缓存中查找
query the L2 cache (lua_shared_dict memory zone). This cache is shared by all workers, and is almost as efficient as the L1 cache. It however requires serialization of stored Lua tables.
if the L2 cache has the value, return it.
if l1_serializer is set, run it, and promote the resulting value in the L1 cache.
if not, directly promote the value as-is in the L1 cache.
if the L2 cache does not have the value (L2 miss), continue.
* 二级缓存查找,
* 如果找到,并且设置了l1_serializer,将序列化后的结果存储到一级缓存
* 如果找到,没有设置了l1_serializer,直接将结果存储到一级缓存
* 如果没有找到,到后端数据库去查找
create a lua-resty-lock, and ensures that a single worker will run the callback (other workers trying to access the same value will wait).
* 创建锁,获得所得worker去后端查询,其他想要查找相同值的worker需要等待
a single worker runs the L3 callback (e.g. performs a database query)
the callback succeeds and returns a value: the value is set in the L2 cache, and then in the L1 cache (as-is by default, or as returned by l1_serializer if specified).
the callback failed and returned nil, err: a. if resurrect_ttl is specified, and if the stale value is still available, resurrect it in the L2 cache and promote it to the L1. b. otherwise, get() returns nil, err.
* 三级缓存查找数据,如果找到,将数据存储到二级缓存、一级缓存(l1_serializer判断是否需要序列化)
* 如果查找失败,返回nil、err,
* 如果设置了resurrect_ttl,就将旧值返回,并更新存活时间
* 如果没有设置resurrect_ttl,直接返回nil, err
other workers that were trying to access the same value but were waiting are unlocked and read the value from the L2 cache (they do not run the L3 callback) and return it.
* 其他的worker等待获取锁,释放锁后,从二级缓存中读取数值,不去后端查找
When not provided a callback, get() will only execute steps 1. and 2
* 如果没有提供回调函数,直接在一级、二级缓存中查找,不去三级缓存查找
示例
local mlcache = require "mlcache"
local cache, err = mlcache.new("my_cache", "cache_shared_dict", {
lru_size = 1000,
ttl = 3600,
neg_ttl = 60
})
local function fetch_user(user_id)
local user, err = db:query_user(user_id)
if err then
-- in this case, get() will return `nil` + `err`
return nil, err
end
return user -- table or nil
end
local user_id = 3
local user, err = cache:get("users:" .. user_id, nil, fetch_user, user_id)
if err then
ngx.log(ngx.ERR, "could not retrieve user: ", err)
return
end
-- `user` could be a table, but could also be `nil` (does not exist)
-- regardless, it will be cached and subsequent calls to get() will
-- return the cached value, for up to `ttl` or `neg_ttl`.
if user then
ngx.say("user exists: ", user.name)
else
ngx.say("user does not exists")
end
示例:l1_serializer
-- Our l1_serializer, called when a value is promoted from L2 to L1
--
-- Its signature receives a single argument: the item as returned from
-- an L2 hit. Therefore, this argument can never be `nil`. The result will be
-- kept in the L1 cache, but it cannot be `nil`.
--
-- This function can return `nil` and a string describing an error, which
-- will bubble up to the caller of `get()`. It also runs in protected mode
-- and will report any Lua error.
local function load_code(user_row)
if user_row.custom_code ~= nil then
local f, err = loadstring(user_row.raw_lua_code)
if not f then
-- in this case, nothing will be stored in the cache (as if the L3
-- callback failed)
return nil, "failed to compile custom code: " .. err
end
user_row.f = f
end
return user_row
end
local user, err = cache:get("users:" .. user_id,
{ l1_serializer = load_code },
fetch_user, user_id)
if err then
ngx.log(ngx.ERR, "could not retrieve user: ", err)
return
end
-- now we can call a function that was already loaded once, upon entering
-- the L1 cache (Lua VM)
user.f()
批量查询
get_bulk:批量查询
语法格式:res, err = cache:get_bulk(bulk, opts?)
Performs several get() lookups at once (in bulk). Any of these lookups
requiring an L3 callback call will be executed concurrently, in a pool
of ngx.thread.
* 批量查询,三级缓存查询会同时进行
The first argument bulk is a table containing n operations.
* 第一个参数时table类型
The second argument opts is optional. If provided, it must be a
table holding the options for this bulk lookup. The possible options are:
concurrency: a number greater than 0. Specifies the number of threads
that will concurrently execute the L3 callbacks for this bulk
lookup. A concurrency of 3 with 6 callbacks to run means than
each thread will execute 2 callbacks. A concurrency of 1 with
6 callbacks means than a single thread will execute all 6
callbacks. With a concurrency of 6 and 1 callback, a single
thread will run the callback. Default: 3.
* 第二个参数可选
* concurrency:并发执行callback函数,需要>0,默认为3
Upon success, this method returns res, a table containing the
results of each lookup, and no error.
* 执行成功,返回res(table类型)、error(nil)
Upon failure, this method returns nil plus a string describing the error
* 执行失败,返回nil、错误信息
示例
local mlcache = require "mlcache"
local cache, err = mlcache.new("my_cache", "cache_shared_dict")
cache:get("key_c", nil, function() return nil end)
local res, err = cache:get_bulk({
-- bulk layout:
-- key opts L3 callback callback argument
"key_a", { ttl = 60 }, function() return "hello" end, nil,
"key_b", nil, function() return "world" end, nil,
"key_c", nil, function() return "bye" end, nil,
n = 3 -- specify the number of operations
}, { concurrency = 3 })
if err then
ngx.log(ngx.ERR, "could not execute bulk lookup: ", err)
return
end
-- res layout:
-- data, "err", hit_lvl }
for i = 1, res.n, 3 do
local data = res[i]
local err = res[i + 1]
local hit_lvl = res[i + 2]
if not err then
ngx.say("data: ", data, ", hit_lvl: ", hit_lvl)
end
end
# 执行结果
data: hello, hit_lvl: 3
data: world, hit_lvl: 3
data: nil, hit_lvl: 1
批量查询条件
new_bulk:批量查询条件
语法格式:bulk = mlcache.new_bulk(n_lookups?)
Creates a table holding lookup operations for the get_bulk() function.
It is not required to use this function to construct a bulk lookup table,
but it provides a nice abstraction.
* 创建批量查询条件
The first and only argument n_lookups is optional, and if specified, is a
number hinting the amount of lookups this bulk will eventually contain so
that the underlying table is pre-allocated for optimization purposes
* 只有一个参数,该参数可选,表示批量查询个数
示例
local mlcache = require "mlcache"
local cache, err = mlcache.new("my_cache", "cache_shared_dict")
local bulk = mlcache.new_bulk(3)
# 参数依次为:key、opts、callback、回调函数参数
bulk:add("key_a", { ttl = 60 }, function(n) return n * n, 42)
bulk:add("key_b", nil, function(str) return str end, "hello")
bulk:add("key_c", nil, function() return nil end)
local res, err = cache:get_bulk(bulk)
遍历批量结果
each_bulk_res:遍历批量结果
语法格式:iter, res, i = mlcache.each_bulk_res(res)
Provides an abstraction to iterate over a get_bulk() res return table.
It is not required to use this method to iterate over a res table,
but it provides a nice abstraction
* 遍历批量结果
示例
local mlcache = require "mlcache"
local cache, err = mlcache.new("my_cache", "cache_shared_dict")
local res, err = cache:get_bulk(bulk)
for i, data, err, hit_lvl in mlcache.each_bulk_res(res) do
if not err then
ngx.say("lookup ", i, ": ", data)
end
end
二级缓存查询
peek:直接查询二级缓存,不将结果放入一级缓存
语法格式:ttl, err, value = cache:peek(key, stale?)
Peek into the L2 (lua_shared_dict) cache.
The first argument key is a string which is the key to lookup in the cache.
The second argument stale is optional. If true, then peek() will consider
stale values as cached values. If not provided, peek() will consider stale
values, as if they were not in the cache
This method returns nil and a string describing the error upon failure.
If there is no value for the queried key, it returns nil and no error.
If there is a value for the queried key, it returns a number indicating the remaining TTL of the cached value (in seconds) and no error. If the value for key has expired but is still in the L2 cache, returned TTL value will be negative. Finally, the third returned value in that case will be the cached value itself, for convenience.
This method is useful when you want to determine if a value is cached. A value stored in the L2 cache is considered cached regardless of whether or not it is also set in the L1 cache of the worker. That is because the L1 cache is considered volatile (as its size unit is a number of slots), and the L2 cache is still several orders of magnitude faster than the L3 callback anyway.
As its only intent is to take a "peek" into the cache to determine its warmth for a given value, peek() does not count as a query like get(), and does not promote the value to the L1 cache