CS231n 之 INTRODUCTION
一. 一些前导和同步课程
CS131:Computer Vision: Foundations and Applications
CS231a: Computer Vision, from 3D Reconstruction to Recognition
CS 224n: Natural Language Processing with Deep Learning
CS 230: Deep Learning,Andrew Ng
二. 计算机视觉的发展历程
(1) 五亿四千万年前,出现生物大爆炸,有研究称是由于眼睛被进化出来。

(2) 16世纪时,出现照相机,利用了小孔成像原理。
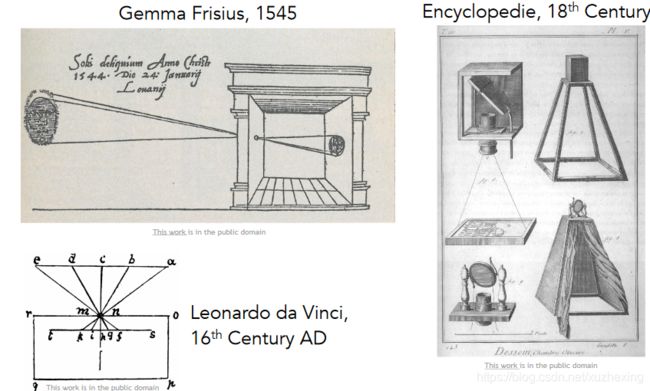
(3) 上世纪60年代,对猫的视觉中枢部分进行研究,发现分层结构:不同层级的神经元逐步将简单的视觉信息组合成复杂信息。
- 一个非常interesting的事情,也是作为“眼睛”这个器官的最大的特点就是,视觉神经组织是在离眼睛最远的地方,不像我们的耳朵,鼻子,其相应的神经组织都是离着最近的地方。这就使得我们有更大的好奇心去探索“视觉神经组织”的未解的神秘所在。早期的科学家们做了很多的尝试和研究,以猫为例子,他们发现,在给猫看一些花,鱼的照片的时候,神经元的脉冲没有受到任何刺激,一次偶然的尝试,不得不说,科学研究不仅需要努力,有时候运气还是很重要的,他们在以幻灯片的方式更换花,鱼照片的时候,就是更换幻灯片的动作使得神经元的脉冲出现变化,激活了神经元,这是极具重要意义的发现,接着,他们发现,神经元是一列一列地组织起来的,每一列神经元只“喜欢”某一种特定的形状,喜欢简单的线条组合。而所谓的边缘,形状,正是构成了边缘模型(Edge Model)。
(4) 1963年,计算机视觉领域的第一篇博士论文:Block World,识别并重建简单形状。
- Larry Roberts提出我们大脑对视觉信息的处理是基于边缘和形状的。用英文表达会更贴切,edge defines the structure ,edge defines the shape。
(5) 1966年,MIT视觉工程暑期项目,声称要花一个暑假的时间构建计算机视觉领域的框架。
(6) 上世纪70年代,一本Vision的书,如何逐步构建计算机视觉:由边、角、点搭建2D草图,由曲面朝向等构建2.5D草图,最终由曲面、空间体等要素形成3D重建。
我们人类的视觉在识别物体的时候,是从一些简单的形状开始的,而不是一个整体,同时,视觉是分层次的。

第一层,是边缘结构(Edge Image);第二层是2.5D,我们看一个图像,视觉上是2D,从而呈现在我们脑海中是3D,而中间会出现一些遮挡,因此David Marr称之为2.5D;到了第三层,就是整合成3D模型。而这一层次结构,也被业界认为是视觉模型结构的representation。
(7) 上世纪80年代:将3D世界简化为简单图形,如将人体简化为多个圆柱体按一定距离组合在一起;将剃须刀简化为线图。
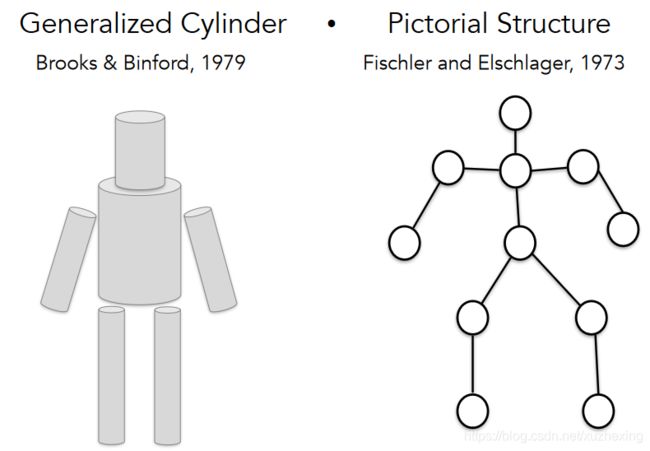
一个是Generalize Cylinder模型,认为整个世界是由simple shape构成,进而通过一些simple shape 去重建3D模型。另一个是Pictorial Structure模型,它是基于概率的模型,它所提出的是,这些simple part是由弹簧连接的。进而直到90年代,Computer Vision领域都不是去识别物体,而是将图片分割成有意义的部分。
(8) 上世纪90年代:统计机器学习方法开始加速发展,支持向量机模型、boosting方法,图模型等,还有基于AdaBoost的人脸检测算法。
在计算机视觉领先发展的是人脸检测,由 Viola & Jones 利用 AdaBoost 算法实现了准确高速的人脸检测,其成果快速转化到了工业界,有了人脸检测相机。
(9) 本世纪初,基于特征的图像识别算法,SIFT算子。
通过观察目标的某些部分、某些特征,它们往往能够在变化中具有表现性和不变性,所以目标识别的首要任务是在目标上确认这些关键的特征,然后把这些特征与相似的目标进行匹配,它比匹配整个目标要容易的多。例如,上图中一个stop标识中的SIFT特征与另一个stop标识中的SIFT特征相匹配。
Using the same building block which is features, diagnostic features in image. 在这个领域有一个重要进展是识别整幅图的场景,以一个算法为例,叫空间金字塔匹配(Spatial Pyramid Matching),背后的思想是,图片里有各种特征告诉我们它可能是什么,这个算法从图中的各部分抽取特征,并把他们放在一起作为一个特征描述符(feature descriptor),然后在特征描述符上做一个支持向量机的运算。
在这个方向上,有一个研究是合理地在图像上构成人体姿态并识别姿态,这被称为 方向梯度直方图(histogram of gradients),另一个被称为 可变形部件模型(deformable part models)。
(10) 本世纪:数据驱动的计算机视觉领域,PASCAL数据集,20类别,每个类别成千上万张图片。ImageNet数据集:1400万张图,22000个类别。ImageNet竞赛:140万张图,2000个类别。
随着计算机视觉的发展,有一个必要解决的问题就是高质量的标注数据里,其中 PASCAL Visual Object Challenge 就是一个非常有影响力的数据集,它拥有二十个类别。
同时,斯坦福的一组学者,在思考我们是否具备了识别真实世界大部分物体的能力,这也是为了解决由于可视化数据非常复杂而常常出现的训练过拟合问题。在高维模型上训练时,由于训练数据量不够,很快就会产生过拟合现象。由于这两方面的动力,他们用了三年时间完成了ImageNet项目,致力于将目标识别算法推向一个新的高度。
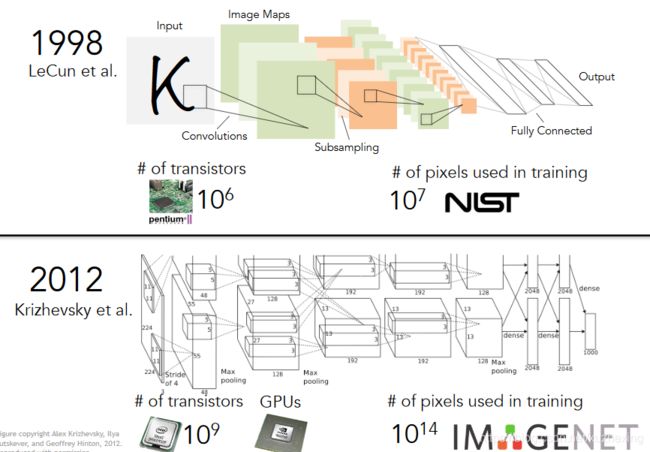
(11) 深度神经网络:2012年,使用卷积神经网络,将ImageNet竞赛中的错误率由25%降低到16%,降幅将近10%。2012年采用的AlexNet深度为7层,2014年,Google的研究人员提出19层的VGG;2015年,MSRA提出152层的ResNet。
(12) 在计算机视觉领域,正尝试着制造一个拥有和人类一样视觉能力的机器,这样可以利用这些视觉系统可以实现很多惊奇的事情,但是当继续在该领域深入的时候,仍然有着大量的挑战和问题亟待解决,比如对整个照片进行密集标记、感知分组、使能够确定每个像素点的归属,这些仍是研究中的问题,所以需要持续不断地改进算法,从而做到更好。
与简单的“在物体上贴标签”比起来,我们往往希望深入地理解图片中的人们在做什么、各个物体之间的关系是什么,于是我们开始探究物体之间的联系,这是一个被称为视觉基因组的项目。
计算机视觉领域的一个愿景即是“看图说故事”,人类的生物视觉系统是非常强大的,看到一张图片,就能够描述图片的内容,并且只需不到一秒种的时间,如果能够让计算机也能做的同样的事情,那毋庸置疑是一项重大的突破;如果要实现真实深刻的图像理解,如今的计算机视觉算法仍然有很长的路要走。
计算机视觉能让世界变得更加美好,它还可以被应用到类似医学诊断、自动驾驶、机器人或者和这些完全版不同的领域。
三. 本课程的主要内容
专注于图像分类,会涉及目标检测、图像描述,以及诸如图像风格迁移等前沿方向。
四. 主要技术手段与工具
卷积神经网络。
编程语言:python。
第三方包:Numpy,Matplot。
IDE:Jupyter Notebook
备注
CS231n为斯坦福李飞飞老师开设的计算机视觉领域的课程。最新的资源是2018年的,但没有开放视频。因此,本系列博文是依托于2017年的相关材料。
一些有用的链接
中英文课程网址。http://www.mooc.ai/course/268
斯坦福cs231n课程主页。http://cs231n.stanford.edu/
课程大纲。http://cs231n.stanford.edu/2017/syllabus
课程配套笔记。http://cs231n.github.io/
CS231n是斯坦福大学教授针对使用深度学习处理图像(计算机视觉处理)的一门公开课,课程内容很不错。
免费视频观看网址:https://www.bilibili.com/video/av17204303/?p=7

slides:https://github.com/autoliuweijie/DeepLearning/tree/master/cs231n/Slides
2.assignment:https://github.com/autoliuweijie/DeepLearning/tree/master/cs231n/HomeWorks
3.notes:https://github.com/autoliuweijie/DeepLearning/tree/master/cs231n/Notes
4.GitHub批量下载工具
下载某一个GitHub上文件时,不允许直接下载一个文件夹的内容,必须一个一个下载文件,这样回很慢很慢。网上有很多办法,在此提供一个特么简单的方法,不需用安装虚拟机,也不许用安装插件,直接可以下载,打开下面链接,输入要在下的GitHub上文件夹的网址,点击下载即可。downgit
文件内部包括的内容很多,主要不是PPT,在线视频已经很清楚,能够看清PPT内容,主要是下载assignment和notes,特别是assignment中,每一个assignment都有图片、文件以及程序,需要仔细研究。
作者:suredied
来源:CSDN
原文:https://blog.csdn.net/suredied/article/details/82226512
版权声明:本文为博主原创文章,转载请附上博文链接!