数模1232
适应赛
题目1
随机森林

增加一列BMI参数
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm']/100)**2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14,'是否得病', d)
print(df3.head(5))
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm']/100)**2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14,'是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第一题只分析元数据即可
df = df3[['性别', '年龄', '身高cm', '体重kg', 'BMI','是否得病']]
print(df.head(5))
# step3 模型建立
dataset = pd.get_dummies(df, columns=['性别', '是否得病']) # 将分类变量转成独热变量
# print(dataset.head(5))
standardScaler = StandardScaler()
columns_to_scale = ['年龄', '身高cm', '体重kg','BMI' ]
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head())
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
X = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 创建一个随机森林分类器的实例
randomforest = RandomForestClassifier(random_state=42, n_estimators=100)
# 利用训练集样本对分类器模型进行训练
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
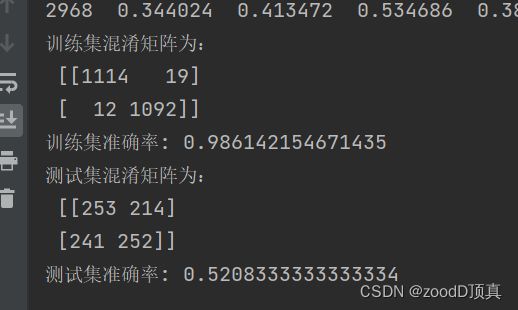
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
'''
训练集混淆矩阵为:
[[1102 16]
[ 17 1102]]
训练集准确率: 0.9852481001341081
测试集混淆矩阵为:
[[261 221]
[239 239]]
测试集准确率: 0.5166666666666667
'''SVM
注意SVM 的数据集的类别分布不能相差guo
import pandas as pd
import numpy as np
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import metrics
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1)
# print(df1) # [4923 rows x 13 columns] 读取阴性 数量太多导致数据不平衡
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm']/100)**2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14,'是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第一题只分析元数据即可
df = df3[['身高cm','年龄', '体重kg', 'BMI','是否得病']]
print(df.head(5))
# step3 模型建立
# dataset = pd.get_dummies(df, columns=['性别', '是否得病']) # 将分类变量转成独热变量
dataset = df
# print(dataset.head(5))
standardScaler = StandardScaler()
columns_to_scale = ['身高cm','年龄', '体重kg', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head())
y = dataset[['是否得病']]
# print(y) # target目标
X = dataset.drop(['是否得病'],axis=1)
# print(X) # 输入的特征
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
# 创建一个SVM分类器
model = svm.SVC() # 创建SVM分类器
model = model.fit(x_train, y_train) # 用训练集做训练
print(y_train)
prediction = model.predict(x_train) # 用测试集做预测
# p_svm = pd.DataFrame(prediction)
# p_svm.to_csv("train_svm.csv", index=False, sep=',')
# print(prediction)
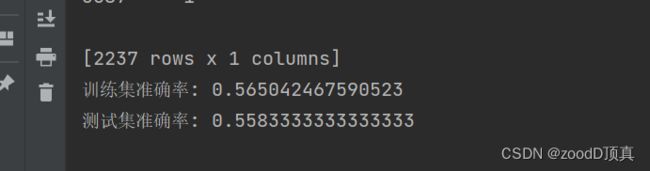
print('训练集准确率:', metrics.accuracy_score(prediction, y_train))
prediction = model.predict(x_test) # 用测试集做预测
p_svm = pd.DataFrame(prediction)
p_svm.to_csv("test_svm.csv", index=False, sep=',')
print('测试集准确率:', metrics.accuracy_score(prediction, y_test))
神经网络MLP
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.neural_network import MLPClassifier
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm']/100)**2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14,'是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第一题只分析元数据即可
df = df3[['性别', '年龄', '身高cm', '体重kg', 'BMI','是否得病']]
print(df.head(5))
# step3 模型建立
dataset = pd.get_dummies(df, columns=['性别', '是否得病']) # 将分类变量转成独热变量
# print(dataset.head(5))
standardScaler = StandardScaler()
columns_to_scale = ['年龄', '身高cm', '体重kg','BMI' ]
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head())
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
X = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=(5,4),activation='logistic',max_iter=5000)
mlp.fit(x_train, y_train)
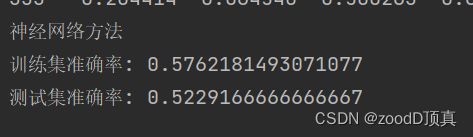
print("神经网络方法")
y_t = mlp.predict(x_train)
print('训练集准确率:', metrics.accuracy_score(y_t, y_train))
y_pred = mlp.predict(x_test)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
题目2
随机森林
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第二题
df = df3[['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']]
# 标签类别
set(df['是否得病']) #{0,1} 阴性-0,阳性-1
print(df.shape)
# 统计缺失值
print(df.isna().sum())
print(df.describe())
'''
# 潮气量有大量空值
(6520, 10)
潮气量(L) 1974
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
潮气量(L) 用力肺活量(%) ... 外周气道参数D(%) 是否得病
count 4546.000000 6520.000000 ... 6520.000000 6520.000000
mean 1.388097 98.463413 ... 83.906838 0.244939
std 0.558965 11.734124 ... 33.676596 0.430084
min 0.160000 68.711656 ... 0.000000 0.000000
25% 0.990000 89.880350 ... 61.896197 0.000000
50% 1.310000 97.291561 ... 79.493590 0.000000
75% 1.730000 105.834854 ... 101.187574 0.000000
max 4.070000 188.603989 ... 679.464286 1.000000
[8 rows x 10 columns]
Process finished with exit code 0
'''
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print('填充之后','\n',df.head(5))
print(df.isna().sum())
'''
1636 0.650000 106.319703 110.917031 ... 84.887460 62.626263 0
901 1.020000 108.368201 111.500000 ... 91.600000 61.160714 0
478 0.810000 100.000000 99.130435 ... 111.003861 93.534483 0
6145 1.388097 127.960526 124.809160 ... 69.047619 33.913043 1
4401 1.060000 83.266932 91.866029 ... 80.276134 73.660714 0
[5 rows x 10 columns]
潮气量(L) 0
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
'''
# step3 模型建立
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
feat_labels = df.columns[0:9] # 特征的名称
# print(feat_labels)
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1,max_depth=3)
forest.fit(x_train, y_train)
score = forest.score(x_test, y_test) # score=0.98148
importances = forest.feature_importances_ # 随机森林模型认为训练特征的重要程度
indices = np.argsort(importances)[::-1] # 下标排序
for f in range(x_train.shape[1]): # x_train.shape[1]
print("%2d) %-*s %f" % \
(f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
'''
1) FEV1/FVC(%) 0.573146
2) 外周气道参数A(%) 0.172901
3) 外周气道参数B(%) 0.079313
4) 中心气道参数(%) 0.068985
5) 潮气量(L) 0.037866
6) 用力肺活量(%) 0.033652
7) 最高呼气流速(%) 0.022079
8) 外周气道参数D(%) 0.006881
9) 外周气道参数C(%) 0.005177
选前面5个的效果可能会好一点
'''

先看下不做选择时模型的预测效果
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第二题
df = df3[['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']]
# 标签类别
set(df['是否得病']) #{0,1} 阴性-0,阳性-1
print(df.shape)
# 统计缺失值
print(df.isna().sum())
print(df.describe())
'''
# 潮气量有大量空值
(6520, 10)
潮气量(L) 1974
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
潮气量(L) 用力肺活量(%) ... 外周气道参数D(%) 是否得病
count 4546.000000 6520.000000 ... 6520.000000 6520.000000
mean 1.388097 98.463413 ... 83.906838 0.244939
std 0.558965 11.734124 ... 33.676596 0.430084
min 0.160000 68.711656 ... 0.000000 0.000000
25% 0.990000 89.880350 ... 61.896197 0.000000
50% 1.310000 97.291561 ... 79.493590 0.000000
75% 1.730000 105.834854 ... 101.187574 0.000000
max 4.070000 188.603989 ... 679.464286 1.000000
[8 rows x 10 columns]
Process finished with exit code 0
'''
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print('填充之后','\n',df.head(5))
print(df.isna().sum())
'''
1636 0.650000 106.319703 110.917031 ... 84.887460 62.626263 0
901 1.020000 108.368201 111.500000 ... 91.600000 61.160714 0
478 0.810000 100.000000 99.130435 ... 111.003861 93.534483 0
6145 1.388097 127.960526 124.809160 ... 69.047619 33.913043 1
4401 1.060000 83.266932 91.866029 ... 80.276134 73.660714 0
[5 rows x 10 columns]
潮气量(L) 0
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
'''
# step3 模型建立
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# 创建一个随机森林分类器的实例
randomforest = RandomForestClassifier(random_state=42, n_estimators=500)
# 利用训练集样本对分类器模型进行训练
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))进行特征选择,选择前7个

import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第二题
df = df3[['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']]
# 标签类别
set(df['是否得病']) #{0,1} 阴性-0,阳性-1
print(df.shape)
# 统计缺失值
print(df.isna().sum())
print(df.describe())
'''
# 潮气量有大量空值
(6520, 10)
潮气量(L) 1974
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
潮气量(L) 用力肺活量(%) ... 外周气道参数D(%) 是否得病
count 4546.000000 6520.000000 ... 6520.000000 6520.000000
mean 1.388097 98.463413 ... 83.906838 0.244939
std 0.558965 11.734124 ... 33.676596 0.430084
min 0.160000 68.711656 ... 0.000000 0.000000
25% 0.990000 89.880350 ... 61.896197 0.000000
50% 1.310000 97.291561 ... 79.493590 0.000000
75% 1.730000 105.834854 ... 101.187574 0.000000
max 4.070000 188.603989 ... 679.464286 1.000000
[8 rows x 10 columns]
Process finished with exit code 0
'''
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print('填充之后','\n',df.head(5))
print(df.isna().sum())
'''
1636 0.650000 106.319703 110.917031 ... 84.887460 62.626263 0
901 1.020000 108.368201 111.500000 ... 91.600000 61.160714 0
478 0.810000 100.000000 99.130435 ... 111.003861 93.534483 0
6145 1.388097 127.960526 124.809160 ... 69.047619 33.913043 1
4401 1.060000 83.266932 91.866029 ... 80.276134 73.660714 0
[5 rows x 10 columns]
潮气量(L) 0
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
'''
# step3 模型建立
# 进行特征选择
df = df[['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)','是否得病']]
print(df.head(5))
'''
FEV1/FVC(%) 外周气道参数A(%) 外周气道参数B(%) ... 用力肺活量(%) 最高呼气流速(%) 是否得病
1491 88.235294 56.373938 91.962617 ... 82.156134 89.898990 0
80 79.794521 45.555556 91.546763 ... 97.333333 92.721519 0
296 82.951654 84.552846 94.329897 ... 85.249458 116.040956 0
2187 87.401575 66.954023 67.620751 ... 82.200647 76.863354 1
1071 86.764706 68.318966 99.506579 ... 97.142857 101.744186 0
'''
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# 创建一个随机森林分类器的实例
randomforest = RandomForestClassifier(random_state=42, n_estimators=500)
# 利用训练集样本对分类器模型进行训练
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
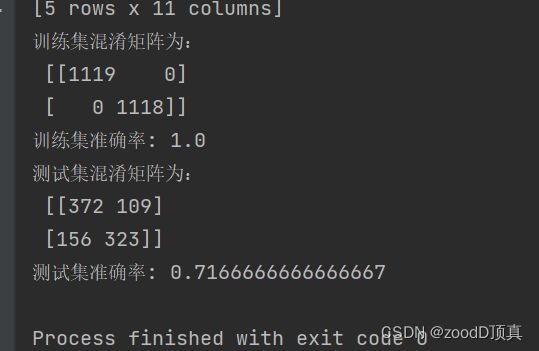
print("特征选择之后")
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
'''
训练集混淆矩阵为:
[[1119 0]
[ 0 1118]]
训练集准确率: 1.0
测试集混淆矩阵为:
[[372 109]
[156 323]]
测试集准确率: 0.7166666666666667
'''svm
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn import svm
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第二题
df = df3[['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']]
# 标签类别
set(df['是否得病']) #{0,1} 阴性-0,阳性-1
print(df.shape)
# 统计缺失值
print(df.isna().sum())
print(df.describe())
'''
# 潮气量有大量空值
(6520, 10)
潮气量(L) 1974
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
潮气量(L) 用力肺活量(%) ... 外周气道参数D(%) 是否得病
count 4546.000000 6520.000000 ... 6520.000000 6520.000000
mean 1.388097 98.463413 ... 83.906838 0.244939
std 0.558965 11.734124 ... 33.676596 0.430084
min 0.160000 68.711656 ... 0.000000 0.000000
25% 0.990000 89.880350 ... 61.896197 0.000000
50% 1.310000 97.291561 ... 79.493590 0.000000
75% 1.730000 105.834854 ... 101.187574 0.000000
max 4.070000 188.603989 ... 679.464286 1.000000
[8 rows x 10 columns]
Process finished with exit code 0
'''
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print('填充之后','\n',df.head(5))
print(df.isna().sum())
'''
1636 0.650000 106.319703 110.917031 ... 84.887460 62.626263 0
901 1.020000 108.368201 111.500000 ... 91.600000 61.160714 0
478 0.810000 100.000000 99.130435 ... 111.003861 93.534483 0
6145 1.388097 127.960526 124.809160 ... 69.047619 33.913043 1
4401 1.060000 83.266932 91.866029 ... 80.276134 73.660714 0
[5 rows x 10 columns]
潮气量(L) 0
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
'''
# step3 模型建立
# 进行特征选择
df = df[['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)','是否得病']]
print(df.head(5))
'''
FEV1/FVC(%) 外周气道参数A(%) 外周气道参数B(%) ... 用力肺活量(%) 最高呼气流速(%) 是否得病
1491 88.235294 56.373938 91.962617 ... 82.156134 89.898990 0
80 79.794521 45.555556 91.546763 ... 97.333333 92.721519 0
296 82.951654 84.552846 94.329897 ... 85.249458 116.040956 0
2187 87.401575 66.954023 67.620751 ... 82.200647 76.863354 1
1071 86.764706 68.318966 99.506579 ... 97.142857 101.744186 0
'''
# dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
dataset = df
standardScaler = StandardScaler()
columns_to_scale = ['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病']]
# print(y) # target目标
x = dataset.drop(['是否得病'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
model = svm.SVC() # 创建SVM分类器
model = model.fit(x_train, y_train) # 用训练集做训练
print(y_train)
prediction = model.predict(x_train) # 用测试集做预测
# p_svm = pd.DataFrame(prediction)
# p_svm.to_csv("train_svm.csv", index=False, sep=',')
# print(prediction)
print('训练集准确率:', metrics.accuracy_score(prediction, y_train))
prediction = model.predict(x_test) # 用测试集做预测
p_svm = pd.DataFrame(prediction)
p_svm.to_csv("test_svm.csv", index=False, sep=',')
print('测试集准确率:', metrics.accuracy_score(prediction, y_test))
MLP

import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.neural_network import MLPClassifier
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第二题
df = df3[['潮气量(L) ','用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']]
# 标签类别
set(df['是否得病']) #{0,1} 阴性-0,阳性-1
print(df.shape)
# 统计缺失值
print(df.isna().sum())
print(df.describe())
'''
# 潮气量有大量空值
(6520, 10)
潮气量(L) 1974
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
潮气量(L) 用力肺活量(%) ... 外周气道参数D(%) 是否得病
count 4546.000000 6520.000000 ... 6520.000000 6520.000000
mean 1.388097 98.463413 ... 83.906838 0.244939
std 0.558965 11.734124 ... 33.676596 0.430084
min 0.160000 68.711656 ... 0.000000 0.000000
25% 0.990000 89.880350 ... 61.896197 0.000000
50% 1.310000 97.291561 ... 79.493590 0.000000
75% 1.730000 105.834854 ... 101.187574 0.000000
max 4.070000 188.603989 ... 679.464286 1.000000
[8 rows x 10 columns]
Process finished with exit code 0
'''
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print('填充之后','\n',df.head(5))
print(df.isna().sum())
'''
1636 0.650000 106.319703 110.917031 ... 84.887460 62.626263 0
901 1.020000 108.368201 111.500000 ... 91.600000 61.160714 0
478 0.810000 100.000000 99.130435 ... 111.003861 93.534483 0
6145 1.388097 127.960526 124.809160 ... 69.047619 33.913043 1
4401 1.060000 83.266932 91.866029 ... 80.276134 73.660714 0
[5 rows x 10 columns]
潮气量(L) 0
用力肺活量(%) 0
中心气道参数(%) 0
FEV1/FVC(%) 0
最高呼气流速(%) 0
外周气道参数A(%) 0
外周气道参数B(%) 0
外周气道参数C(%) 0
外周气道参数D(%) 0
是否得病 0
dtype: int64
'''
# step3 模型建立
# 进行特征选择
df = df[['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)','是否得病']]
print(df.head(5))
'''
FEV1/FVC(%) 外周气道参数A(%) 外周气道参数B(%) ... 用力肺活量(%) 最高呼气流速(%) 是否得病
1491 88.235294 56.373938 91.962617 ... 82.156134 89.898990 0
80 79.794521 45.555556 91.546763 ... 97.333333 92.721519 0
296 82.951654 84.552846 94.329897 ... 85.249458 116.040956 0
2187 87.401575 66.954023 67.620751 ... 82.200647 76.863354 1
1071 86.764706 68.318966 99.506579 ... 97.142857 101.744186 0
'''
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['FEV1/FVC(%)','外周气道参数A(%)','外周气道参数B(%)','中心气道参数(%)','潮气量(L) ','用力肺活量(%)','最高呼气流速(%)']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=(5,4),activation='logistic',max_iter=5000)
mlp.fit(x_train, y_train)
print("神经网络方法")
y_t = mlp.predict(x_train)
print('训练集准确率:', metrics.accuracy_score(y_t, y_train))
y_pred = mlp.predict(x_test)
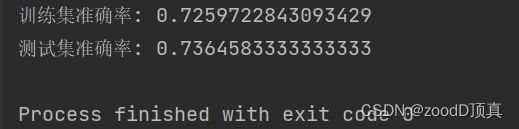
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
题目三
随机森林
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn import svm
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第三题 元数据选年龄、体重、身高、BMI、 检查参数选前7个
# drop_features = ['性别','外周气道参数C(%)','外周气道参数C(%)']
# df = df3.drop(drop_features, axis=1)
df = df3
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print(df.head(10))
print(df.columns)
'''
Index(['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI', '是否得病'],
dtype='object')
'''
# step3 模型建立
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# 创建一个随机森林分类器的实例
randomforest = RandomForestClassifier(random_state=42, n_estimators=500)
# 利用训练集样本对分类器模型进行训练
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
# print("特征选择之后")
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
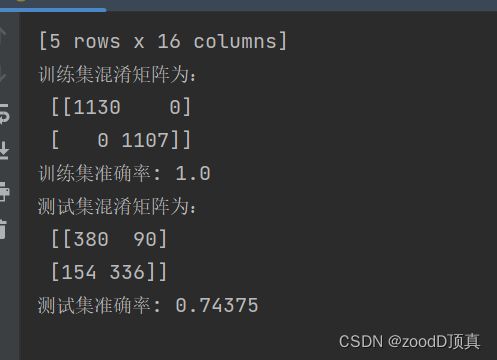
'''
[5 rows x 16 columns]
训练集混淆矩阵为:
[[1130 0]
[ 0 1107]]
训练集准确率: 1.0
测试集混淆矩阵为:
[[380 90]
[154 336]]
测试集准确率: 0.74375
'''SVM

import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn import svm
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第三题 元数据选年龄、体重、身高、BMI、 检查参数选前7个
# drop_features = ['性别','外周气道参数C(%)','外周气道参数C(%)']
# df = df3.drop(drop_features, axis=1)
df = df3
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print(df.head(10))
print(df.columns)
'''
Index(['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI', '是否得病'],
dtype='object')
'''
# step3 模型建立
dataset = df
standardScaler = StandardScaler()
columns_to_scale = ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病']]
# print(y) # target目标
x = dataset.drop(['是否得病'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
model = svm.SVC() # 创建SVM分类器
model = model.fit(x_train, y_train) # 用训练集做训练
print(y_train)
prediction = model.predict(x_train) # 用测试集做预测
# p_svm = pd.DataFrame(prediction)
# p_svm.to_csv("train_svm.csv", index=False, sep=',')
# print(prediction)
print('训练集准确率:', metrics.accuracy_score(prediction, y_train))
prediction = model.predict(x_test) # 用测试集做预测
p_svm = pd.DataFrame(prediction)
p_svm.to_csv("test_svm.csv", index=False, sep=',')
print('测试集准确率:', metrics.accuracy_score(prediction, y_test))
特征选择之后

import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn import svm
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第三题 元数据选年龄、体重、身高、BMI、 检查参数选前7个
drop_features = ['性别','外周气道参数C(%)','外周气道参数C(%)']
df = df3.drop(drop_features, axis=1)
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print(df.head(10))
print(df.columns)
'''
Index(['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)',
'最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数D(%)', 'BMI', '是否得病'],
dtype='object')
'''
# step3 模型建立
dataset = df
standardScaler = StandardScaler()
columns_to_scale = ['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)',
'最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数D(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病']]
# print(y) # target目标
x = dataset.drop(['是否得病'],axis=1)
# print(X) # 输入的特征
#
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
model = svm.SVC() # 创建SVM分类器
model = model.fit(x_train, y_train) # 用训练集做训练
print(y_train)
prediction = model.predict(x_train) # 用测试集做预测
# p_svm = pd.DataFrame(prediction)
# p_svm.to_csv("train_svm.csv", index=False, sep=',')
# print(prediction)
print('训练集准确率:', metrics.accuracy_score(prediction, y_train))
prediction = model.predict(x_test) # 用测试集做预测
p_svm = pd.DataFrame(prediction)
p_svm.to_csv("test_svm.csv", index=False, sep=',')
print('测试集准确率:', metrics.accuracy_score(prediction, y_test))神经网络
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.neural_network import MLPClassifier
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第三题 元数据选年龄、体重、身高、BMI、 检查参数选前7个
drop_features = ['性别','外周气道参数C(%)','外周气道参数C(%)']
df = df3.drop(drop_features, axis=1)
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print(df.head(10))
print(df.columns)
'''
Index(['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)',
'最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数D(%)', 'BMI', '是否得病'],
dtype='object')
'''
# step3 模型建立
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler() # 数据标准化
columns_to_scale = ['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)',
'最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数D(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
#
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=(5,4),activation='logistic',max_iter=5000)
mlp.fit(x_train, y_train)
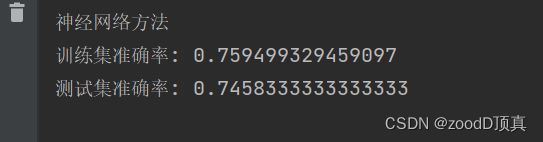
print("神经网络方法")
y_t = mlp.predict(x_train)
print('训练集准确率:', metrics.accuracy_score(y_t, y_train))
y_pred = mlp.predict(x_test)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))K折交叉验证
机器学习—模型选择与优化7-1(k-fold交叉验证法) - 橘子橘子呀 - 博客园 (cnblogs.com)
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn import metrics
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import plot_confusion_matrix
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn import svm
from sklearn.model_selection import cross_val_score
from sklearn.neural_network import MLPClassifier
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
# df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
ColNames_List = df3.columns.values.tolist()
# print('------------------------------------------------------')
# print(ColNames_List,type(ColNames_List))
# ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ',
# '用力肺活量(%)', '中心气道参数(%)', 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)', '外周气道参数D(%)', '是否得病']
# print(df3)
'''
性别 年龄 身高cm 体重kg ... 外周气道参数B(%) 外周气道参数C(%) 外周气道参数D(%) 是否得病
0 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
1 男 55 151.0 49.0 ... 59.870550 101.844262 83.653846 0
2 男 30 181.0 69.0 ... 64.519906 103.146067 107.100592 0
3 男 25 179.0 75.0 ... 62.237762 104.092072 92.814371 0
4 男 23 171.0 59.0 ... 54.024390 74.943567 48.076923 0
... .. .. ... ... ... ... ... ... ...
6515 女 36 167.0 60.0 ... 96.875000 102.512563 100.000000 1
6516 男 28 183.0 68.0 ... 102.870264 63.942308 82.269504 1
6517 女 36 160.0 55.0 ... 64.957265 58.203125 54.585153 1
6518 女 60 159.0 74.0 ... 100.957854 72.000000 48.529412 1
6519 女 63 156.0 46.0 ... 66.336634 92.553191 87.368421 1
[6520 rows x 14 columns]
'''
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# print(df3.head(5))
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
# print(df3)
# 第三题 元数据选年龄、体重、身高、BMI、 检查参数选前7个
# drop_features = ['性别','外周气道参数C(%)','外周气道参数C(%)']
# df = df3.drop(drop_features, axis=1)
df = df3
#使用均值填充缺失值
mean_val =df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
print(df.head(10))
print(df.columns)
'''
Index(['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI', '是否得病'],
dtype='object')
'''
# step3 模型建立
dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler()
columns_to_scale = ['性别', '年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', '外周气道参数C(%)',
'外周气道参数D(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# 切分训练集与测试集,注意所有的交叉验证等都是在训练集上做的操作,测试集只有最后的最后才会使用到
# 创建一个随机森林实例
rf = RandomForestClassifier(random_state=42, n_estimators=500)
rf_mse = cross_val_score(estimator = rf , X = x_train, y = y_train, scoring = 'r2', cv = 5, verbose = 1, n_jobs=6)
print('随机森林模型中,R2的平均数是 %.4f,标准差是 %.4f' %(rf_mse.mean(), rf_mse.std()))
mlp = MLPClassifier(solver='lbfgs',hidden_layer_sizes=(5,4),activation='logistic',max_iter=5000)
mlp_mse = cross_val_score(estimator = mlp, X = x_train, y = y_train, scoring = 'r2', cv = 5, verbose = 1, n_jobs=6)
print('MLP模型中,R2的平均数是 %.4f,标准差是 %.4f' %(mlp_mse.mean(), mlp_mse.std()))
# 平均数最高(低偏差),标准差最小(低方差) 就是好模型
# 随机森林模型中,R2的平均数是 -0.2770,标准差是 0.0515
# MLP模型中,R2的平均数是 -0.3461,标准差是 0.0922
# 因此模型选择为 随机森林随机森林参数调优
RandomForest 随机森林算法与模型参数的调优 - 码农充电站 - 博客园 (cnblogs.com)
(88条消息) gridsearchcv参数_随机森林算法参数解释及调优_weixin_39953578的博客-CSDN博客
# 参数优化 对n_estimators参数择优
randomforest = RandomForestClassifier(random_state=42)
param_test1 = {"n_estimators": range(1, 101, 10)}
gsearch1 = GridSearchCV(estimator=RandomForestClassifier(), param_grid=param_test1,
scoring='roc_auc', cv=10)
gsearch1.fit(x_train, y_train)
print(gsearch1.best_score_)
print(gsearch1.best_params_)
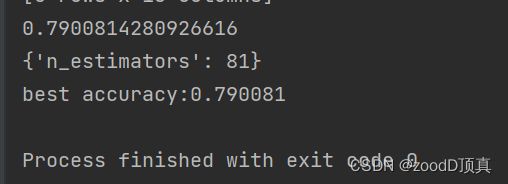
print("best accuracy:%f" % gsearch1.best_score_)
'''
0.7900814280926616
{'n_estimators': 81}
best accuracy:0.790081
''' 
# 参数优化 最大特征数max_features,其他参数设置为常数,且n_estimators为81
randomforest = RandomForestClassifier(random_state=42)
param_test2 = {"max_features":range(1,11,1)}
gsearch1 = GridSearchCV(estimator=RandomForestClassifier(n_estimators=81,
random_state=10),
param_grid = param_test2,scoring='roc_auc',cv=10)
gsearch1.fit(x_train, y_train)
print(gsearch1.best_score_)
print(gsearch1.best_params_)
print("best accuracy:%f" % gsearch1.best_score_)
'''
0.7900814280926616
{'n_estimators': 81}
best accuracy:0.790081
0.7973612760484702
{'max_features': 9}
best accuracy:0.797361
'''比较优化后的结果
没啥变化,草拟吗
randomforest = RandomForestClassifier(random_state=42,n_estimators=81,max_features=9)
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
# print("特征选择之后")
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
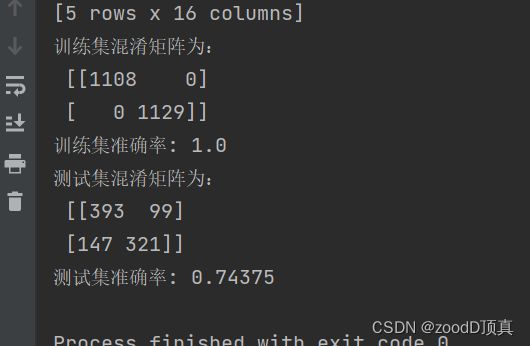
'''
训练集混淆矩阵为:
[[1108 0]
[ 0 1129]]
训练集准确率: 1.0
测试集混淆矩阵为:
[[393 99]
[147 321]]
测试集准确率: 0.74375
'''
样本不平衡问题
import numpy
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
from sklearn import metrics
from sklearn.metrics import recall_score #召回率
# step1 数据预处理
# 读取数据
path = 'xiaochuan.xlsx'
xl = pd.ExcelFile(path)
# print(xl.sheet_names) # ['阴性', '阳性']
df1 = xl.parse('阴性', index_col=0)
# df1 = df1.loc[0:1600,:]
# print(df1) # [4923 rows x 13 columns] 读取阴性
df2 = xl.parse('阳性', index_col=0)
# print(df2) # [1597 rows x 13 columns] 读取阳性数据
# 先分别添加一列 是否患病 阴性0 阳性 1
df1.insert(loc=13, column='是否得病', value=0) # 阴性为0
# print(df1) # 1 男 40 176.0 67.0 ... 64.661654 105.070423 76.190476 0
df2.insert(loc=13, column='是否得病', value=1) # 阳性为1
# print(df2) # 1 男 20 174.0 77.0 ... 62.248521 67.021277 58.035714 1
# 将df1 和df 2 合并在一起
df3 = pd.concat([df1, df2], axis=0).reset_index(drop=True)
# 增加BMI参数 BMI=体重(kg)÷身高2(m2)。
df3['BMI'] = df3['体重kg'] / ((df3['身高cm'] / 100) ** 2)
# print(3**2)
d = df3.pop('是否得病')
df3.insert(14, '是否得病', d)
# 对性别列进行处理
df3.replace('男', 1, inplace=True)
df3.replace('女', 0, inplace=True)
df3 = shuffle(df3)
drop_features = ['性别', '外周气道参数C(%)', '外周气道参数D(%)'] # 之前相关性啥的不重要的特征给他删除
df = df3.drop(drop_features, axis=1)
# 使用均值填充缺失值
mean_val = df['潮气量(L) '].mean()
# print(mean_val) # 1.3880972283325999
df['潮气量(L) '].fillna(mean_val, inplace=True)
# print(df.head(5))
# print(df.isna().sum())
dataset = df
x = dataset.iloc[:, :-1] # 特征
y = dataset.iloc[:, -1] # 标签
groupby_data_o = dataset.groupby(['是否得病'])['是否得病'].count() #标签类别分类计数
# 分析样本不平衡问题
print(groupby_data_o)
'''
是否得病
0 4923
1 1597 存在样本不平衡问题
Name: 是否得病, dtype: int64
'''
# 使用过采样
# 使用SMOTE方法进行过抽样处理
from imblearn.over_sampling import SMOTE # 过抽样处理库SMOTE
model_smote = SMOTE()
x_smote_resampled, y_smote_resampled = model_smote.fit_resample(x, y) # 输入数据进行过抽样处理
y_smote_resampled = pd.DataFrame(y_smote_resampled, columns=['是否得病'])
smote_resampled = pd.concat([x_smote_resampled, y_smote_resampled], axis=1) # 将特征和标签重新拼接
group_data_smote = smote_resampled.groupby(['是否得病'])['是否得病'].count() # 查看标签类别个数
print(group_data_smote)
'''
是否得病
0 4923
1 4923
Name: 是否得病, dtype: int64
'''
dataset = pd.get_dummies(smote_resampled, columns=['是否得病']) # 将分类变量转成独热变量
standardScaler = StandardScaler() # 标准化
columns_to_scale = ['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', 'BMI']
dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
print(dataset.head(5))
y = dataset[['是否得病_0','是否得病_1']]
# print(y) # target目标
x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# print(X) # 输入的特征
# 随机森林 不管样本分类不平衡
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# 创建一个随机森林分类器的实例
randomforest = RandomForestClassifier(random_state=42,n_estimators=81,max_features=9)
# 利用训练集样本对分类器模型进行训练
model = randomforest.fit(x_train, y_train)
# print(model.predict(x_train))
# print(y_train)
# print(type(model.predict(x_train)))
y_train = numpy.array(y_train)
xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
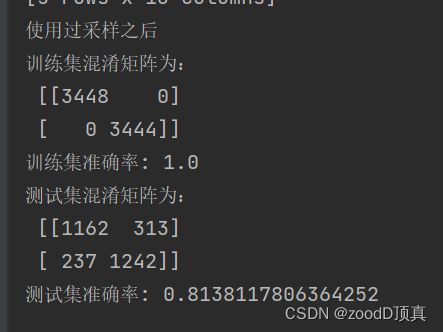
print("使用过采样之后")
print('训练集混淆矩阵为:\n',xm)
print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
y_test = numpy.array(y_test)
y_pred = model.predict(x_test)
cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
print('测试集混淆矩阵为:\n',cm)
print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
'''
使用过采样之后
训练集混淆矩阵为:
[[3477 0]
[ 0 3415]]
训练集准确率: 1.0
测试集混淆矩阵为:
[[1130 316]
[ 226 1282]]
测试集准确率: 0.8165199729180772
'''
# # 使用RandomUnderSampler进行欠抽样处理
# from imblearn.under_sampling import RandomUnderSampler # 欠抽样处理库RandomUnderSampler
#
# model_RandomUnderSampler = RandomUnderSampler() # 实例化
# x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled = model_RandomUnderSampler.fit_resample(x,y) # 输入数据进行欠抽样处理
# y_RandomUnderSampler_resampled = pd.DataFrame(y_RandomUnderSampler_resampled, columns=['是否得病'])
#
# RandomUnderSampler_resampled = pd.concat([x_RandomUnderSampler_resampled, y_RandomUnderSampler_resampled],
# axis=1) # 将特征和标签重新拼接
# group_data_RandomUnderSampler = RandomUnderSampler_resampled.groupby(['是否得病'])['是否得病'].count() # 查看标签类别个数
#
# print(group_data_RandomUnderSampler)
#
# # RandomUnderSampler_resampled 采样后的数据
#
# dataset = pd.get_dummies(RandomUnderSampler_resampled, columns=['是否得病']) # 将分类变量转成独热变量
# standardScaler = StandardScaler() # 标准化
# columns_to_scale = ['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
# 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', 'BMI']
# dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
# print(dataset.head(5))
#
# y = dataset[['是否得病_0','是否得病_1']]
# # print(y) # target目标
# x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# # print(X) # 输入的特征
#
#
# # 随机森林 不管样本分类不平衡
# x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# # 创建一个随机森林分类器的实例
# randomforest = RandomForestClassifier(random_state=42,n_estimators=81,max_features=9)
# # 利用训练集样本对分类器模型进行训练
# model = randomforest.fit(x_train, y_train)
#
# # print(model.predict(x_train))
# # print(y_train)
# # print(type(model.predict(x_train)))
# y_train = numpy.array(y_train)
# xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
# print("使用欠采样之后")
# print('训练集混淆矩阵为:\n',xm)
# print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
#
# y_test = numpy.array(y_test)
#
# y_pred = model.predict(x_test)
# cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
#
# print('测试集混淆矩阵为:\n',cm)
# print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
#
# '''
# 使用欠采样之后
# 训练集混淆矩阵为:
# [[1089 0]
# [ 0 1146]]
# 训练集准确率: 1.0
# 测试集混淆矩阵为:
# [[321 187]
# [145 306]]
# 测试集准确率: 0.6538060479666319
# '''
# dataset = pd.get_dummies(df, columns=['是否得病']) # 将分类变量转成独热变量
# standardScaler = StandardScaler() # 标准化
# columns_to_scale = ['年龄', '身高cm', '体重kg', '潮气量(L) ', '用力肺活量(%)', '中心气道参数(%)',
# 'FEV1/FVC(%)', '最高呼气流速(%)', '外周气道参数A(%)', '外周气道参数B(%)', 'BMI']
# dataset[columns_to_scale] = standardScaler.fit_transform(dataset[columns_to_scale])
# print(dataset.head(5))
#
# y = dataset[['是否得病_0','是否得病_1']]
# # print(y) # target目标
# x = dataset.drop(['是否得病_0','是否得病_1'],axis=1)
# # print(X) # 输入的特征
#
#
# # 随机森林 不管样本分类不平衡
# x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
# # 创建一个随机森林分类器的实例
# randomforest = RandomForestClassifier(random_state=42,n_estimators=81,max_features=9)
# # 利用训练集样本对分类器模型进行训练
# model = randomforest.fit(x_train, y_train)
#
# # print(model.predict(x_train))
# # print(y_train)
# # print(type(model.predict(x_train)))
# y_train = numpy.array(y_train)
# xm = confusion_matrix(y_train.argmax(axis=1),model.predict(x_train).argmax(axis=1)) # 混淆矩阵
# # print("特征选择之后")
# print('训练集混淆矩阵为:\n',xm)
# print('训练集准确率:', metrics.accuracy_score(model.predict(x_train), y_train))
#
# y_test = numpy.array(y_test)
#
# y_pred = model.predict(x_test)
# cm = confusion_matrix(y_test.argmax(axis=1),y_pred.argmax(axis=1)) # 混淆矩阵
#
# print('测试集混淆矩阵为:\n',cm)
# print('测试集准确率:', metrics.accuracy_score(y_pred, y_test))
# '''
# 训练集混淆矩阵为:
# [[3459 0]
# [ 0 1105]]
# 训练集准确率: 1.0
# 测试集混淆矩阵为:
# [[1362 102]
# [ 380 112]]
# 测试集准确率: 0.7535787321063395
# '''
plt.imshow(cm, cmap=plt.cm.Blues)
indices = range(len(cm))
plt.xticks(indices, [0,1])
plt.yticks(indices, [0,1])
plt.colorbar()
plt.xlabel('guess')
plt.ylabel('fact')
for first_index in range(len(cm)):
for second_index in range(len(cm[first_index])):
plt.text(first_index, second_index, cm[second_index][first_index])
plt.title('优化随机森林测试集混淆矩阵')
plt.show()