【卷积核设计】Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
文章目录
-
- 一、背景
- 二、方法
- 三、RepKLNet:a Large-Kernel Architecture
-
- 3.1 结构
- 3.2 尽可能的让卷积核变大
- 3.3 图像分类
- 3.4 语义分割
- 3.5 目标检测
- 四、分析
- 五、限制
- 六、结论

论文链接:https://arxiv.org/pdf/2203.06717.pdf
代码链接:https://github.com/DingXiaoH/RepLKNet-pytorch
本文收录于 CVPR2022
一、背景
CNN 虽然在计算机视觉上处于长期的统治地位,但由于 transformer 方法的提出,这一现象发生了改变。比如 ViT,已经在分类、特征学习、目标检测、语义分割、图像复原等方面都取得了超越 CNN 的效果。
有人认为 ViT 的效果离不开 MHSA (多头自注意)的结构,也有人替换了 MHSA 后仍然能取得好的效果,所以到底是什么造成了 CNN 和 ViT 的差距呢?
作者聚焦到了个这问题:长距离空间信息间联系的建立
在 ViT 中,MHSA 能够同时抽取长距离和短距离的依赖关系,也就是能够聚合大感受野的信息
在 CNN 中,基本没有使用很大的卷积核(除了第一层)
所以作者提出质疑:能否使用少量大卷积核来代替大量小卷积核?这样能弥补两者之间的差距吗?
DW 卷积概念补充:不同于常规卷积操作,Depth-wise Convolution 的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。
二、方法

1、作者提出了 RepLKNet,一个纯 CNN 网络。类似于 swin transformer 的结构,但做了些修改:
- 使用大的 depth-wise 卷积代替了 MHSA
- 主要对比较大的模型作为基准测试,因为 vit 过去被认为在大数据和模型方面超过了CNN
2、本文中,作者系统的探索了大卷积核的效果:
- 在 CNN 中使用的 depth-wise 卷积,卷积核大小从 3 × 3 3 \times 3 3×3 → 31 × 31 31 \times 31 31×31
- 这种简单增加卷积核大小的操作是很有效的,也能很好的和 ViT 的机理契合
作者由此给出了如下总结:
① 很大的卷积核在实际使用中也会很高效
大的卷积核一直被认为计算量很大,但 depth-wise 可以很好的克服这个问题。当本文作者将不同 stage 的卷积核大小从 [3, 3, 3, 3] 提高到 [31, 29, 27,13] 后,FLOPs 和 参数量分别提升了 18.6% 和 10.4%。
② 残差连接是很重要的,尤其对于大卷积核的网络
以 mobilenetv2 为例,作者使用 13x13 的卷积核代替了 3x3 的卷积核,结果如表 2 所示。

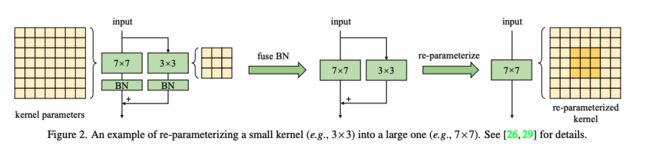
③ 使用小卷积核重参数化有助于解决参数优化问题
论文将MobileNetV2中的 3x3 卷积核分别替换为 9x9 和 13x13,再采用结构重参数帮助更好地训练。具体的做法如图2所示,先将卷积核替换为更大的卷积核,再并行一个深度卷积层,经过BN处理后将其结果相加作为输出。训练完成后,合并并行的大小卷积层及其BN层,得到没有小卷积层的模型。

④ 大卷积能够提高下游任务的效果多于 ImageNet
表 3 中,mobilinetv2 的卷积核从 3x3 提高到 9x9 后,ImageNet 的准确率提高了 1.33%,Cityscapes 的 mIoU 提高了 3.99%。表 5 中,不同 stage 的卷积核大小从 [3, 3, 3, 3] 提高到 [31, 29, 27,13] 后,ImageNet 的准确率仅仅提高了 0.96%,ADE20K 的 mIoU 提高了 3.12%。
什么原因导致的呢?
作者认为:
-
大的卷积核能够有效提高有效感受野,能够获取更多的上下文信息,这些信息对下游的任务很重要。
-
大的卷积核能够学到更多的形状信息。我们已知,ImageNet 中的图像能够被正确的分类,是因为网络能够学习到相关的纹理信息和形状信息,但对于人类来说,辨别不同目标会更关注形状信息。所以,如果一个模型能够捕获更强的形状偏置信息,则对下游任务更加友好。也有研究[86]证明,ViT 在形状偏置的提取上有更强的能力,CNN 更能提取纹理偏置,而提高卷积核大小能很好的提升 CNN 捕捉形状偏置的能力。
⑤ 大核(如 13x13)在小特征图(如 7x7)上仍然适用
- 为了验证这个结论,作者在 mobilenetv2 的最后一层将深度可分离卷积大小提升到了 7x7 或 13x13,表 4 展示了相关结果。

当卷积核大小越来越大,CNN 的平移不变性会变得不严格,如图 3 所示,两个相邻位置的输出仅仅会共享部分卷积核权重(因为卷积核很大),也就是不同的映射转换,这个其实也符合 ViT 的特征——在网络获得更大的容量之前放松对称先验。
此外,作者还发现, 2D 相对位置坐标可以看成大小为 ( 2 H − 1 ) × ( 2 W − 1 ) (2H-1) \times (2W-1) (2H−1)×(2W−1) 的 depth-wise 卷积,H 和 W 分别的特征图的高和宽。所以,大的卷积核不但能够帮助学习相对位置,而且可以编码位置信息。

三、RepKLNet:a Large-Kernel Architecture
由于 CNN 在小体量模型上还是优于 transformer 的,所以本文主要聚焦于大模型(复杂度和 ResNet-152 或 Swin-B 相似),来验证大尺度卷积核能否弥补 CNN 和 ViT 的差距。
3.1 结构
如图 4 所示:
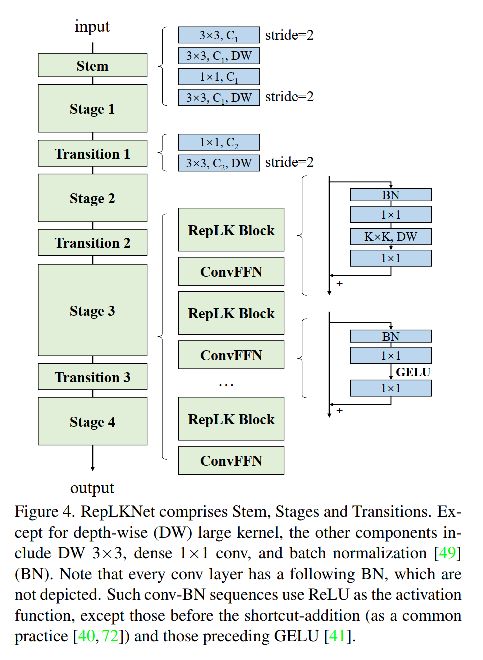
1、Stem
因为作者为了提高下游密集预测的任务,所以需要捕捉更多的细节信息。
3x3 conv (2↓下采样) → 3x3 DW(捕捉 low-level 信息) → 1x1 conv → 3x3 DW(下采样)
2、Stages
每个 stage 都包含了多个 RepLK Blocks,这些 Blocks 使用了 shortcuts 和 DW 大尺度核。
在每个 DW 前后都使用 1x1 conv 是本文的常规操作,且每个 DW 大卷积都使用 5x5 的核来进行重参数化。
虽然大尺度的卷积核能够实现更好的感受野感知并聚合更多的空间特征,但模型的容量其实和模型的深度也有很大的相关性。所以,为了引入更多的非线性,和实现通道间的信息交互,作者使用 1x1 conv 来实现网络加深。
此外,FFN 在 transformer 中应用广泛,所以,作者实现了一个 CNN-style 的类似于 FFN 的模块,叫做 ConvFFNBlock。该模型组成方式:BN、2 个 1x1 conv、GELU、残差连接。
3、Transition Blocks
没两个 stage 之间,都放置了 Transition Blocks。先通过 1x1 conv 来进行通道增加,然后使用 3x3 DW 实现 2↓ 下采样。
所以,每个 stage 有三个结构超参数:
- B: RepLK Blocks 个数
- C:channel dimension
- K:kernel size
所以,RepLKNet 的结构参数如下:
[ B 1 , B 2 , B 3 , B 4 ] , [ C 1 , C 2 , C 3 , C 4 ] , [ K 1 , K 2 , K 3 , K 4 ] [B1, B2, B3, B4],[C1, C2, C3, C4],[K1, K2, K3, K4] [B1,B2,B3,B4],[C1,C2,C3,C4],[K1,K2,K3,K4]
3.2 尽可能的让卷积核变大
为了探索不同大小的卷积核带来的不同效果,作者给定两组参数:
B=[2, 2, 18, 2], C=[128, 256, 512, 1024],然后改变卷积核大小 K 来实现效果的探索。
作者做了三组大卷积核实验,K 分别为:
- [13, 13, 13, 13]
- [25, 25, 25, 13]
- [31, 29, 27, 13]
还有两组小卷积核实现,K 分别为:
- [3, 3, 3, 3]
- [7, 7, 7, 7]
表 5 展示了不同大小卷积核取得的结果,在 ImageNet 上,将卷积核从 3 提升到 13 时,能有效的提升准确率,但再提升了时候就没有提升了。
在 ADE20K 上,从 [13, 13, 13, 13] 提升到 [31, 29, 27, 13] 后,mIoU 提升了 0.82,参数增高了 5.3%, FLOPs 增高了3.5%。

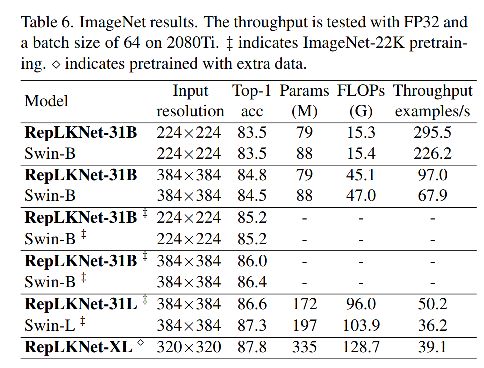
3.3 图像分类
3.4 语义分割
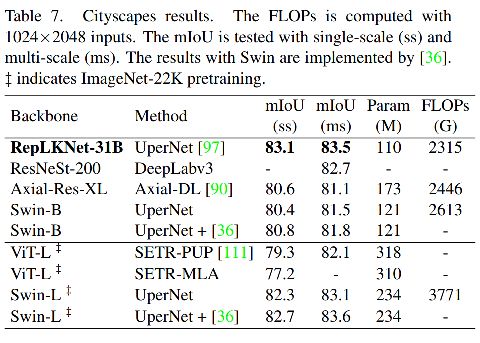

3.5 目标检测
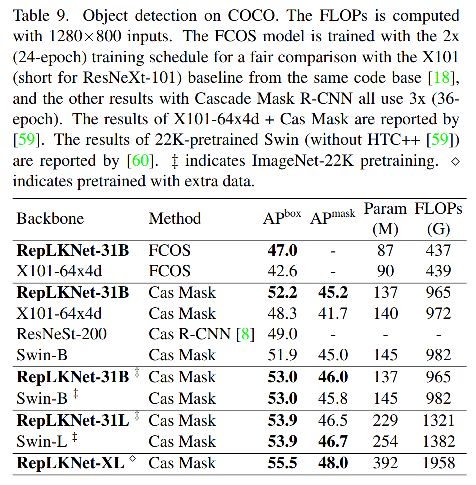
四、分析
1、 大尺度卷积核 CNN 比小尺度卷积核的更深的 CNN 有效感受野更大
我们已知卷积什么网络可以通过多层的累积来实现大感受野感知。那为什么有数十上百层卷积的小卷积核网络效果仍然次于大卷积核网络呢。
-
① 已知,有效感受野 ERF 是和 O ( K ( L ) O(K \sqrt(L) O(K(L) 成正比的,K 是卷积核大小,L 是深度。也就是说,ERF 和卷积核大小呈线性关系,和深度呈开方关系。
-
② 深度的增加,会使得反向传播优化越来越困难,虽然 ResNet 基本解决了这个问题,能够训练上百层的网络。但[89]提出,ResNet 的行为类似于浅层网络的集合,也就是说,即使深度显著增加,ResNet 带来的 ERF 提升也非常有限,[52] 中也有相似的证论。也就是说,大的均价和只需要很少的层就可以实现大的 ERF,同时能够避免深度增大带来的优化问题。
例如,[89]表明ResNets的行为类似于浅层网络的集合,这意味着ResNets的erf可能仍然非常有限
即使深度急剧增加。这种现象在之前的作品中也有经验观察到,如[52]。综上所述,大型内核设计需要更少的层来获得更大的erf,同时也避免了深度增加带来的优化问题
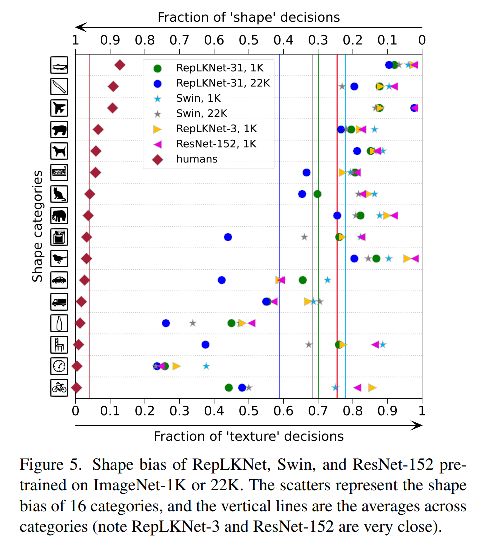
2、大尺度模型更类似于人类对形状偏置的感知
[86] 认为 vision transformer 更类似于人类的视觉系统,也就是更依赖于目标的形状来进行判断,CNN 更依赖于纹理。
作者使用了相应的 toolbox 来获得 shape bias,图 5展示了 RepLKNet 有比 Swin 更高的 shape bias。
由于 RepLKNet 和 Swin 有类似的结构,所以作者认为 RepLKNet 更高是由于其有效的大感受野,而非 self-attention 结构。
3、密集卷积和膨胀卷积的对比
膨胀卷积是有效的提高感受野但参数增加少的方法,然而,表11显示,尽管深度膨胀卷积可能具有与深度密集卷积相同的最大RF,但其表示容量要低得多,因为它在数学上与稀疏大卷积等效。文献(如[92,98])进一步表明,膨胀卷积会遇到网格化问题。作者认为通过混合使用不同的卷积,可能可以克服卷积扩张的缺点。
五、限制
如表 6 所示,虽然大卷积核能够提高 CNN 在分类和其下游任务的效果,但随着数据量和模型的增大,RepLKNets 又比 Swin 的效果低了。
目前还不太清楚这是由于超参数并非最优的或其他的缺点导致的,还在研究中。
六、结论
使用少量大卷积核而非大量小卷积核,能够有效的提升有效感受野,提高 CNN 的效果。所以作者建议研究更好的有效感受野来提升效果。并且,大卷积核既然能够取得类似好的成绩,那么也可以被用来理解 self-attention 的内在机理。