NLP中的各种Attention机制
Attention机制是在Seq2Seq模型的基础上被提出来的,Seq2Seq通过encoder拿到(输入)文本信息的context向量(矩阵)。Attention机制让decoder部分更加关注与当前时刻相关性最高的item。因此,在回顾Attention机制之前,需要先回顾一下Seq2Seq(即Encoder-Decoder)模型。
Seq2Seq(Encoder-Decoder)
在此前的博文《NLP中面向文本表示的模型梳理》https://blog.csdn.net/weikai_w/article/details/103657943中,已经简要的介绍了Seq2Seq模型,它主要来自于2014年的两篇论文。
- Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.[GRU] http://emnlp2014.org/papers/pdf/EMNLP2014179.pdf
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).[Google:LSTM] https://arxiv.org/pdf/1409.3215.pdf
这两篇差不多同一时间发表的论文讲述着同样的模型架构,该模型可以有效的解决输出序列定长的问题(在RNN中,输入和输出必须是等长的),区别在于对于文本信息编码方法的细微差别,Seq2Seq模型用的是LSTM,Encoder-Decoder模型用的是GRU。那么问题来了,***为什么文本信息处理都需要用RNN或者类RNN结构呢?***(文本序列的时序性,链式的特征揭示了RNN本质上是与序列和列表相关的。他们是对于这类数据的最自然的神经网络架构。)
Seq2Seq模型的原理:
上图是Encoder-Decoder的模型结构,Encoder部分用来处理每一个时刻的输入序列,encoder会捕获输入序列的信息到一个vector中,该vector称做context(C),在处理完整个encoder阶段的输入序列后,encoder会把context发送给decoder,decoder再一个接一个的生成新的输出序列。
context是一个向量,在文本类任务中,通常是采用encoder的最后一个时刻的hidden state作为context,这个context的大小是可以设置的,其维度等于rnn的hidden state的维度,可能是256,512甚至1024。
基于Seq2Seq的机器翻译
图 基于Seq2Seq的机器翻译
文本信息被encoder成context ( C),而在单向LSTM模型中,C=h4。Decoder是添加了特殊token(< S> 和< E>)的语言模型,其输入和输出维度一致。语言模型中的预测词利用Softmax完成多分类,并采用cross entropy作为loss训练模型。
因此,sequence-to-sequence 模型是对序列的item建模,这样的item可以有多种,例如文字,语音,或者图像等,输出的内容也是序列的item。分别根据Encoder和Decoder模态的不同,Seq2Seq可以用来处理多模态的端对端任务(end-end),比如:Text-Text, Text-Image, Image-Text, Speech-Text, Text-Speech等。
Seq2Seq模型的缺陷:
- 训练速度慢,计算无法并行化(根本原因是encoder和decoder阶段中的RNN/LSTM/GRU的结构,由于decoder实际上是一个语言模型,因此其时间复杂度为O(n));
- 对于长序列来说,效果不理想;无论多长的句子,都会被编码成一个固定长度的向量,作为解码器的输入。那么对于长句子而言,编码过程中势必就会有信息的损失;
Attention机制
Seq2Seq的缺陷可以采用Attention机制解决。Attention机制能让decoder只关注与当前时刻相关性最高的items。2015年,Bahdanau 在Seq2Seq模型的基础上,加上Attention机制做机器翻译,实现了翻译效果的显著提升。
Seq2Seq模型中加入Attention机制,本质上就是对Encoder部分每一时刻产生的Hidden State的处理,如下图所示:
其中,
- encoder会传递每一个时刻的context到decoder中(上图中的三个橙色向量代表着encoder部分中的每一时刻的隐状态),而不单单是最后一个时刻的隐状态;
- decoder会接收到多个context(即encoder中的所有隐状态),所以decoder需要一种方法来选择最适合当前时刻的context;
Attention机制对Encoder部分隐状态的处理过程,如下图:
对于Encoder阶段每一个时刻生成的隐藏状态h1,h2和h3,decoder的第一个时刻随机初始化一个向量s0,用于计算decoder中的第一个时刻与encoder中的每一个隐状态hi的scores,上图中的计算分别是13、9、9,再通过softmax进行权重的归一化,分别获得encoder中每一个隐状态的权重,为0.96、0.02、0.02,分配与当前时刻相关的隐状态的权重,即注意力。再通过计算权重和隐变量加权和(weighted sum),得到decoder中当前时刻的context信息,用于输入。
下图中的C4即为如上所述获得的初始时刻context信息, h i n i t h_{init} hinit为decoder在第一时刻随机初始化的向量,h4为decoder中第一时刻的隐状态,由 h i n i t h_{init} hinit和’< S>'token的embedding所获得。再将C4和h4进行拼接后,经过full connection层,再经过softmax多分类层,预测当前时刻的输出。
下一时刻:h4与encoder中所有的hidden state计算scores,再通过softmax进行权重分配,加权平均获得,针对当前时刻的context:C5,h5由h4和当前时刻输入的embedding获得,拼接C5和h5后,经过全连接层和softmax,预测当前时刻的输出。
以下时刻的信息生成过程,依此类推。
可以说,attention机制是对encoder部分所有的hidden state加权,而加权的方式有很多种,上述只是将decoder中的hidden state h j h_{j} hj与encoder中的所有hidden state相乘,即dot-product: s c o r e ( s i , h j ) = s i T h j score(s_{i}, h_{j})=s_{i}^{T}h_{j} score(si,hj)=siThj。
那么,不同的加权方式可以产生多种不同的Attention机制,几种常见的Attention机制如下表所示:
下面将对当前主流的几种Attention机制进行论述。
Bahdanau Attention
Bahdanau Attention是Bahdanau在2015年提出(Neural Machine Translation by Jointly Learning to Align and Translate https://arxiv.org/pdf/1409.0473.pdf),在Seq2Seq模型的基础上,加上Attention机制做机器翻译任务,实现了更好的效果。
- Encoder是一个双向RNN,这样做的好处就是能够在一些语序影响翻译的语言中表现得更好,比如:后面的词语对冠词、代词翻译提供参考。
- 对输入的每一个隐变量进行attention加权,解码的时候将整个context信息进行weighted-sum传入,这种方法称为soft attention(软对齐),也叫Global Attention,因为每个输入词的 hj 都参与了权重的计算,这种方法方便梯度的反向传播,便于我们训练模型。对应的有 Hard Attention,也叫Local Attention,就是在输出中找到某个特定的单词,其对应权重为 100%,其余都是 0。这种模型非常的粗暴,同时也因为在文本中一一对应的难度太大,而且这样我们模型的训练会变得非常困难,需要很多优化的技巧,所以很少会 NLP 中使用 Hard Attention;但是在图像处理领域,Hard Attention 被证明是有用的。
- Ci是Attention矩阵的一行,表示输入X1到XT分别对decoder第i时序这个target word所对应的注意力大小。
- αij是Attention矩阵的一个值,表示输入表示Xj对decoder第i时序的target word的权重。
Attention也可以看成是一种对齐模型,用来衡量输入端j位置和输出端i位置的匹配程度。Attention矩阵的计算方法如红框所示,由一个线性层和softmax层叠加得到。其输入是上一时刻 decoder 的状态 s i − 1 s_{i-1} si−1和encoder对第j个词的输出hj,Wa、Ua 和 va则是需要我们模型去学习的参数。
Luong Attention
论文:Effective Approaches to Attention-based Neural Machine Translation https://arxiv.org/abs/1508.04025
该模型与Bahdanau Attention类似,不同点在于:介绍了几种不同的score function方法。
Our various attention-based models are classifed into two broad categories, global and local. These classes differ in terms of whether the “attention” is placed on all source positions or on only a few source positions.
Luong对于两种Attention(Global Attention和Local Attention)进行描述,其核心在于:在获得上下文C的计算中,是否所有Encoder的hidden states都参与计算,全部参与的就称为Global Attention,部分参与的就称为Local Attention。
Global Attention
如下图所示,蓝色部分是Encoder,红色部分表示decoder,灰色部分表示将attention的Ct和decoder的ht链接再经过softmax分类的过程。其中,所有的hidden states都参与了Ct的计算。
关于attention权重还是通过softmax获得,表示源端第s个词和目标端第t个输出所对应的权重,hs表示源端的词对应的状态,ht表示目标端的时序对应的状态,通过这两个状态的分数获得其权重:
其分数由下式score函数得到:
Bahdanau论文中用的是第三种,而在这篇论文中发现,第一种对于 Global Attention 效果更好,而第二种应用在 Local Attention 效果更好。
Local Attention
作者在计算attention时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置Pt,然后通过上下文窗口,仅考虑窗口内的词(如果窗口长度超出了句子边界,以句子边界为准)。
有2种对齐位置的方式,分别为:
- monotonic alignment
直接设置Pt=t的一对一方式(显然在NMT场景中不符合逻辑),然后窗口内的attention矩阵还是通过下式计算;
- Predictive alignment
Pt的对齐位置是由目标端的隐层状态决定的,其中Wp和Vp都是模型参数,S是源端句子的长度。
同时文章使用了一个服从N(pi,D/2)的高斯分布来设置权重,直觉上来说里对齐位置pi越近,对后序决策影响越大。因此其对齐概率计算如下:
实际上就是在基础权重上加上个正太分布的权重调整系数。
Self Attention
Self-attention最早出自于Transformer,Transformer也是encoder-decoder的结构。
- encoder是由6个相同结构的层堆叠在一起,每一个层包含两个子层,分别是multi-head attention 层与一个全连接层,每个子层跟了一个residual connection与一个layer normalization。
- decoder也是由6个相同结构的层堆叠在一起,除了和encoder一样的两个子层外,还有一个masked multi-head attention。
总所周知,Transformer来源于论文《Attention is all you need》https://arxiv.org/pdf/1706.03762.pdf,文中主要介绍了self-attention、multi-head attention和masked multi-head attention。 。本文后续将谈到multi-head attention和masked multi-head attention,有关Transformer的详细细节,将在接下来的文章中详细描述。
self-attention具有Bi-RNN的功能,即在完全感知输入sequence的情况下输出sequence。同时self-attention可以克服RNN无法被并行计算的问题(即并行化),使得计算加速。因此,可以采用self-attention取代RNN。关于self-attention的基础介绍推荐台湾大学李宏毅教授的课程,里面讲的比较浅显易懂,资源在YouTube或者Bilili中都可以搜索到。
在NMT任务中,比如用Transformer翻译这句话"The animal didn’t cross the street because it was too tired"。当我们翻译到 it 的时候,我们知道 it 指代的是 animal 而不是 street。所以,如果有办法可以让 it 对应位置的 embedding 适当包含 animal 的信息,就会非常有用。self-attention的出现就是为了完成这一任务。
- 第一步:每个输入位置,第一步产生三个向量(q,k,v),并计算分数
为了实现 self-attention,每个输入的位置需要产生三个向量,分别是 Query 向量,Key 向量和 Value 向量。拿每一个输入的Query 向量与所有输入数据的Key 向量做attention,获得当前输入与所有信息之间的相关程度,如下图所示。
问题:为什么需要对dot-product attention做scaled处理呢?
假如q与k的初始化的值满足均值为0,方差为1,那么点乘后的结果均值为0,方差为 d k d_{k} dk,这就导致不同的值之间相差过大, softmax的输出值之和为1,如果有一个输出单元的值增大了,那么其他所有单元的值都将会受到抑制,导致出现全盘通吃的情况。Scaled Dot-Product Attention就是在dot-product attention的基础上加上了一个缩放因子。 d k d_{k} dk为key_size。
- 第二步: 将q和k的dot-product结果经过softmax,获得注意力权重
- 第三步:将注意力权重与所有value向量做weighted sum,形成context
下面这张图清晰的概括了self-attention工作的三个步骤。
图片来源 https://blog.csdn.net/xiaosongshine/article/details/90573585
这些向量都是由输入 embedding 通过三个 matrices(Q、K、V) (也就是线性变化)产生的,matrix的维度为 h h i d d e n × l s r c h_{hidden}\times l_{src} hhidden×lsrc。注意到在Transformer架构中,这些新的向量比原来的输入向量要小,原来的向量是512维,转变后的三个向量都是64维。
得到了self-attention生成的词向量之后,我们就可以将它们传入feed-forward network了。
self attention中的矩阵计算
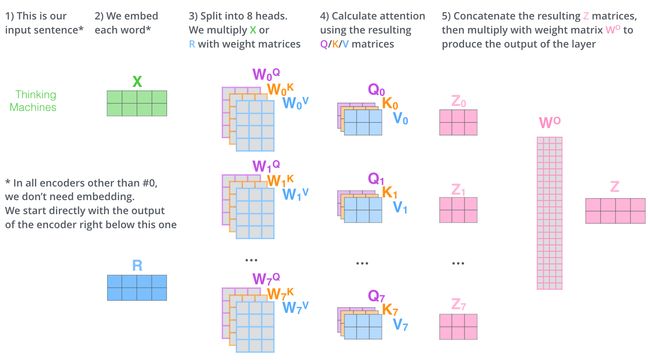
- 第一步: 对每一个词向量计算Query, Key和Value矩阵
我们把句子中的每个词向量拼接到一起变成一个矩阵X,然后乘以不同的矩阵做线性变换(WQ, WK, WV)。
- 第二步: 用矩阵乘法实现上面介绍过的Self-Attention机制
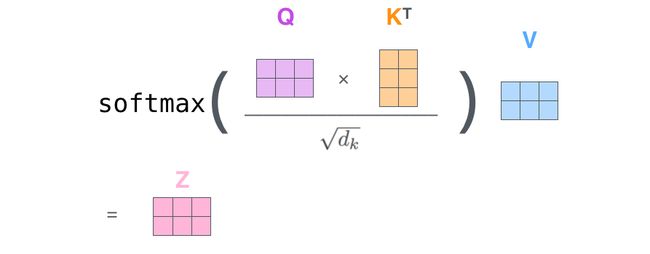
Multi-head Attention
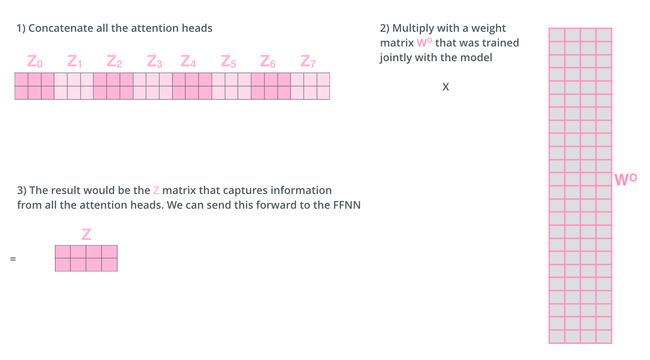
单个attention只能考虑到一个维度,对于nlp这样较为复杂的任务,一个维度肯定是不够的,就好比CNN的卷积核个数,不可能只设置一个。这么做的好处就是:模型有更强的能力产生不同的attention机制,focus在不同的单词上。multi-head attention原理图如下所示。通过多组Q、K、V后每一个单词产生多个context,再拼接这些context即可。
每个attention head最终都产生了一个matrix表示这个句子中的所有词向量。在transformer模型中,我们产生了八个matrices。我们知道self attention之后就是一个feed-forward network。那么我们是否需要做8次feed-forward network运算呢?事实上是不用的。我们只需要将这8个matrices拼接到一起,然后做一次前向神经网络的运算就可以了。multi-head attention的计算过程图示如下:
综合起来,我们可以用下面一张图表示Self-Attention模块所做的事情。
参考资料
[1] Attention Mechanism 学习笔记1 https://tobiaslee.top/2017/08/15/Attention-Mechanism-%E5%AD%A6%E4%B9%A0%E7%AC%94%E8%AE%B0/
[2] Attention机制实践解读 https://blog.csdn.net/xiaosongshine/article/details/90573585