在本系列的前一篇博客《将流转化为数据产品》中,我们谈到了减少数据生成/摄取之间的延迟以及从这些数据中产生分析结果和洞察力的日益增长的需求。我们讨论了如何使用带有 Apache Kafka 和 Apache Flink 的Cloudera 流处理(CSP) 来实时和大规模地处理这些数据。在这篇博客中,我们将展示一个真实的例子来说明如何做到这一点,看看我们如何使用 CSP 来执行实时欺诈检测。
构建实时流分析数据管道需要能够处理流中的数据。流内处理的一个关键先决条件是能够收集和移动在源点生成的数据。这就是我们所说的第一英里问题。本博客将分两部分发布。在第一部分中,我们将研究由 Apache NiFi 提供支持的Cloudera DataFlow如何通过轻松高效地获取、转换和移动数据来解决第一英里问题,以便我们可以轻松实现流分析用例。我们还将简要讨论在 Cloudera DataFlow 的云原生 Kubernetes 部署中运行此流程的优势。
在第二部分中,我们将探讨如何使用 Apache Flink 运行实时流分析,我们将使用 Cloudera SQL Stream Builder GUI 仅使用 SQL 语言(无需 Java/Scala 编码)轻松创建流作业。我们还将使用流分析作业产生的信息来提供不同的下游系统和仪表板。
用例
欺诈检测是我们探索的时间关键用例的一个很好的例子。我们都经历过这样一种情况,即我们的信用卡或我们认识的人的卡的详细信息已被泄露,并且非法交易被记入卡中。为了最大限度地减少这种情况下的损失,信用卡公司必须能够立即识别潜在的欺诈行为,以便它可以阻止信用卡并联系用户以验证交易,并可能发行一张新卡来替换受损的信用卡。
卡交易数据通常来自事件驱动的数据源,新数据会随着现实世界中发生的卡购买而出现。但是,除了流数据之外,我们还有传统的数据存储(数据库、键值存储、对象存储等),其中包含可能必须用于丰富流数据的数据。在我们的用例中,流数据不包含帐户和用户详细信息,因此我们必须将流与参考数据连接起来,以生成我们需要检查每个潜在欺诈交易的所有信息。
根据所产生信息的下游用途,我们可能需要以不同的格式存储数据:为 Kafka 主题生成潜在欺诈交易列表,以便通知系统可以立即采取行动;将统计数据保存在关系或操作仪表板中,以进行进一步分析或提供仪表板;或将原始事务流保存到持久的长期存储中,以供将来参考和进行更多分析。
我们在本博客中的示例将使用 Cloudera DataFlow 和 CDP 中的功能来实现以下功能:
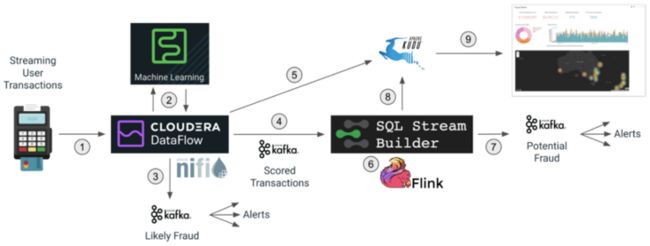
- Cloudera DataFlow 中的 Apache NiFi 将读取通过网络发送的交易流。
- 对于每笔交易,NiFi 都会调用 Cloudera 机器学习 (CML) 中的生产模型来评估交易的欺诈潜力。
- 如果欺诈分数高于某个阈值,NiFi 会立即将事务路由到通知系统订阅的 Kafka 主题,该主题将触发适当的操作。
- 评分的事务被写入 Kafka 主题,该主题将为在 Apache Flink 上运行的实时分析过程提供数据。
- 带有分数的交易数据也被保存到 Apache Kudu 数据库中,以供以后查询和提供欺诈仪表板。
- 使用 SQL Stream Builder (SSB),我们使用连续流式 SQL 来分析交易流,并根据购买的地理位置检测潜在的欺诈行为。
- 识别出的欺诈交易被写入另一个 Kafka 主题,该主题为系统提供必要的操作。
- 流式 SQL 作业还将欺诈检测保存到 Kudu 数据库。
来自 Kudu 数据库的仪表板提要显示欺诈摘要统计信息。
使用 Cloudera DataFlow 获取
Apache NiFi 是 Cloudera DataFlow 的一个组件,可以轻松为您的用例获取数据并实施必要的管道来清理、转换和提供流处理工作流。凭借 300 多个开箱即用的处理器,它可用于执行通用数据分发、获取和处理来自几乎任何类型的源或接收器的任何类型的数据。
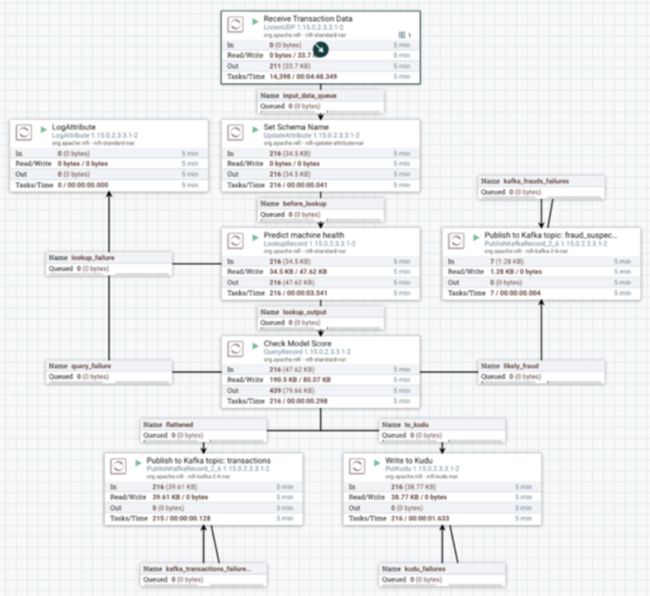
在这个用例中,我们创建了一个相对简单的 NiFi 流程,它实现了上述步骤 1 到 5 的所有操作,我们将在下面更详细地描述这些操作。
在我们的用例中,我们正在处理来自外部代理的金融交易数据。该代理将每笔交易发送到一个网络地址。每笔交易都包含以下信息:
- 交易时间戳
- 关联账户的ID
- 唯一的交易 ID
- 交易金额
交易发生地的地理坐标(经纬度)
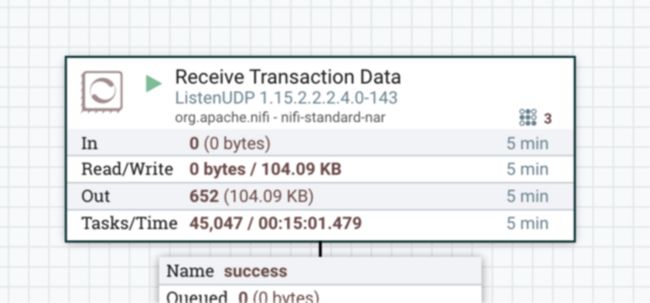
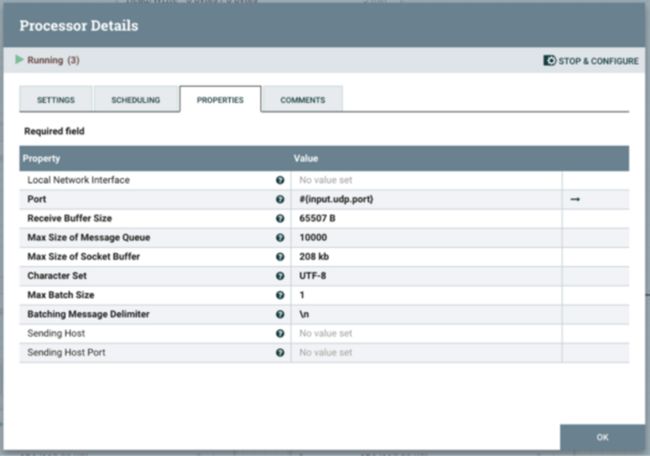
交易消息采用 JSON 格式,如下例所示:{ "ts": "2022-06-21 11:17:26", "account_id": "716", "transaction_id": "e933787c-f0ff-11ec-8cad-acde48001122", "amount": 1926, "lat": -35.40439536601375, "lon": 174.68080620053922 }NiFi 能够创建网络侦听器来接收来自网络的数据。对于此示例,我们可以简单地将 ListenUDP 处理器拖放到 NiFi 画布中,并使用所需的端口对其进行配置。可以参数化处理器的配置以使流可重用。在这种情况下,我们定义了一个名为 #{input.udp.port} 的参数,稍后我们可以将其设置为我们需要的确切端口。
用模式描述数据
模式是描述数据结构的文档。在环境中的多个应用程序甚至 NiFi 流中的处理器之间发送和接收数据时,拥有一个存储库非常有用,在该存储库中集中管理和存储所有不同类型数据的模式。这使应用程序更容易相互通信。
Cloudera 数据平台 (CDP) 附带 Schema Registry 服务。对于我们的示例用例,我们已将事务数据的模式存储在模式注册表服务中,并将我们的 NiFi 流配置为使用正确的模式名称。NiFi 与 Schema Registry 集成,它会自动连接到它以在整个流程中需要时检索模式定义。
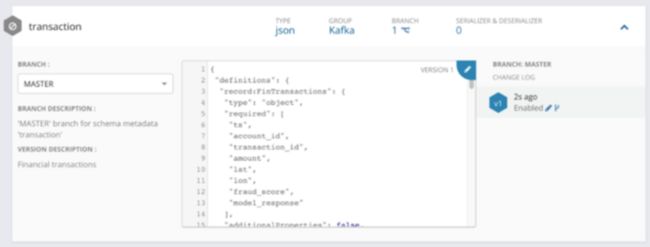
数据在 NiFi 流中的路径由不同处理器之间的视觉连接决定。例如,在这里,ListenUDP 处理器先前接收到的数据被“标记”为我们要使用的模式的名称:“事务”。
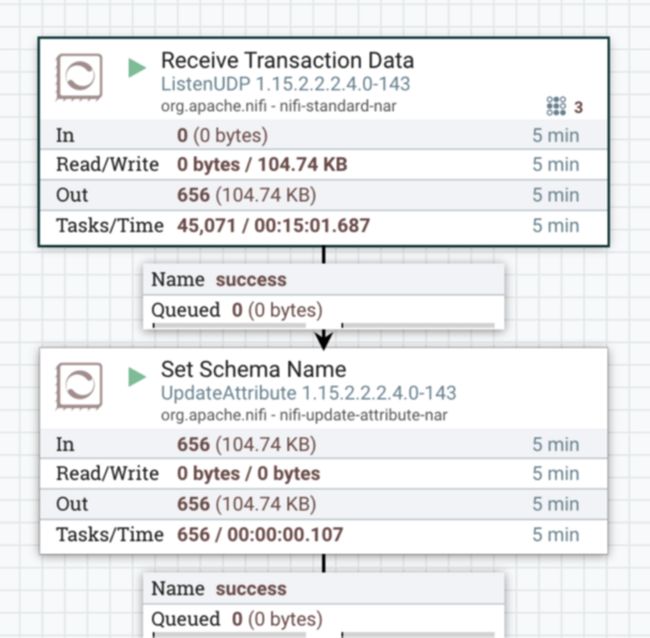
评分和路由事务
我们使用 Cloudera 机器学习 (CML) 训练并构建了一个机器学习 (ML) 模型,以根据每笔交易的欺诈潜力对其进行评分。CML 提供了一个带有 REST 端点的服务,我们可以使用它来执行评分。当数据流经 NiFi 数据流时,我们希望调用数据点的 ML 模型服务来获取每个数据点的欺诈分数。
为此,我们使用 NiFi 的 LookupRecord,它允许针对 REST 服务进行查找。CML 模型的响应包含一个欺诈分数,由一个介于 0 和 1 之间的实数表示。
LookupRecord 处理器的输出,其中包含与 ML 模型的响应合并的原始交易数据,然后连接到 NiFi 中一个非常有用的处理器:QueryRecord 处理器。
QueryRecord 处理器允许您为处理器定义多个输出并将 SQL 查询与每个输出相关联。它将 SQL 查询应用于通过处理器流式传输的数据,并将每个查询的结果发送到关联的输出。
在这个流程中,我们定义了三个 SQL 查询在这个处理器中同时运行:

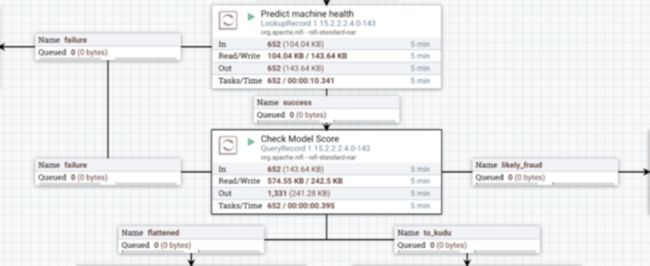
请注意,一些处理器还定义了额外的输出,例如“失败”、“重试”等,以便您可以为流程定义自己的错误处理逻辑。
将流送入其他系统
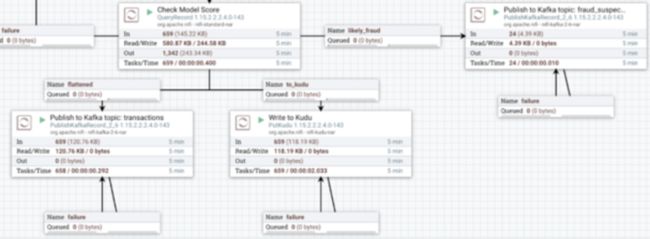
在流程的这一点上,我们已经用 ML 模型的欺诈分数丰富了我们的流,并根据我们下游的需要转换了流。完成我们的数据摄取剩下的就是将数据发送到 Kafka,我们将使用它来提供我们的实时分析过程,并将事务保存到 Kudu 表,我们稍后将使用它来提供我们的仪表板,如以及其他非实时分析过程。
Apache Kafka 和 Apache Kudu 也是 CDP 的一部分,配置 Kafka 和 Kudu 特定的处理器来为我们完成任务非常简单。
在云上本地运行数据流
构建 NiFi 流程后,它可以在您可能拥有的任何 NiFi 部署中执行。Cloudera DataFlow for the Public Cloud (CDF-PC) 提供了一个云原生弹性流运行时,可以高效地运行流。
与固定大小的 NiFi 集群相比,CDF 的云原生流运行时具有许多优势:
- 您不需要管理 NiFi 集群。您可以简单地连接到 CDF 控制台,上传流定义并执行它。必要的 NiFi 服务会自动实例化为 Kubernetes 服务来执行流程,对用户透明。
- 它在流之间提供了更好的资源隔离。
- 流执行可以自动向上和向下扩展,以确保有适量的资源来处理当前正在处理的数据量。这避免了资源匮乏,并通过在不再使用时重新分配不必要的资源来节省成本。
具有用户定义的 KPI 的内置监控可以针对每个特定流进行定制,具有不同的粒度(系统、流、处理器、连接等)。
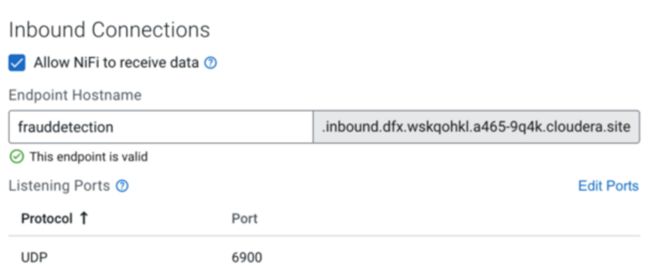
安全入站连接
除了上述之外,将安全网络端点配置为入口网关是众所周知的云中难以解决的问题,并且每个云提供商的步骤各不相同。
它需要设置负载平衡器、DNS 记录、证书和密钥库管理。

CDF-PC 通过入站连接功能抽象出这些复杂性,允许用户通过提供所需的端点名称和端口号来创建入站连接端点。
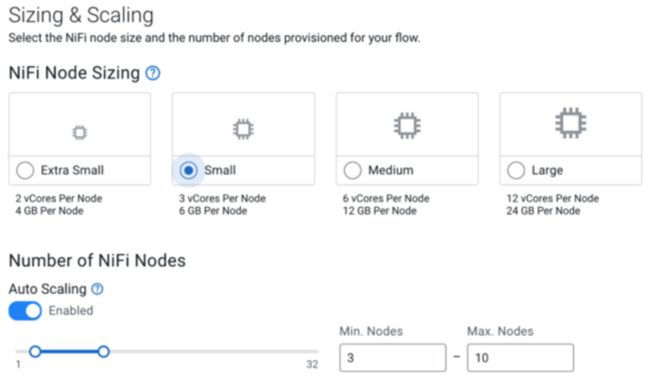
参数化和可定制的部署
在流程部署中,您可以定义流程执行的参数,还可以选择流程的大小和自动缩放特性:
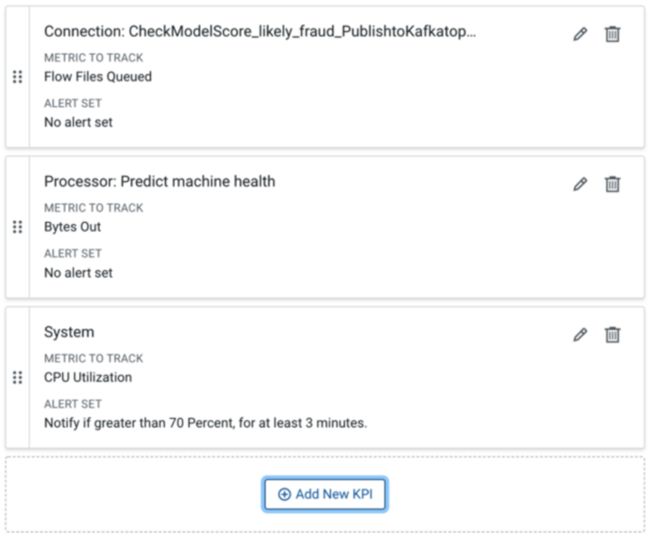
本机监控和警报
可以定义自定义 KPI 来监控对您很重要的流程方面。还可以定义警报以在超过配置的阈值时生成通知:
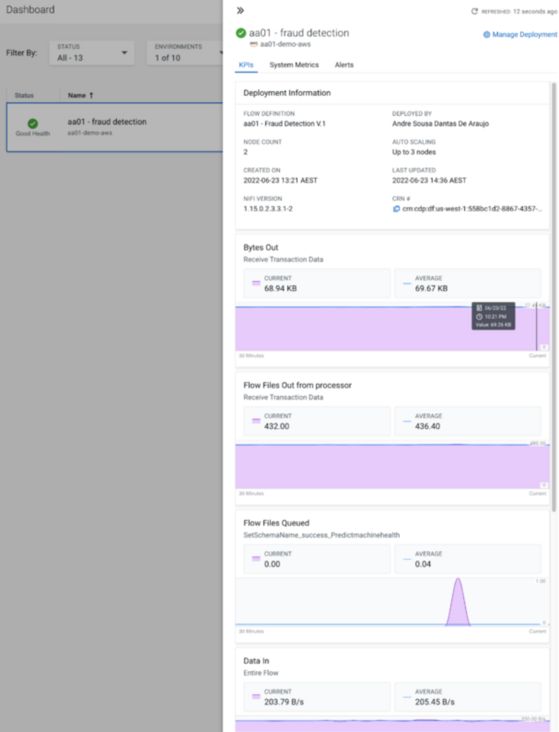
部署后,可以在 CDF 仪表板上监控为定义的 KPI 收集的指标:

Cloudera DataFlow 还提供对流的 NiFi 画布的直接访问,以便您可以在必要时检查执行的详细信息或解决问题。GUI 中的所有功能也可以通过 CDP CLI 或 CDF API 以编程方式使用。创建和管理流程的过程可以完全自动化并与 CD/CI 管道集成。
结论
在生成数据时收集数据并在分析平台上快速提供数据,这对于任何需要实时处理数据流的项目的成功都是至关重要的。在这篇博客中,我们展示了 Cloudera DataFlow 如何让在云中创建、测试和部署数据管道变得容易。
Apache NiFi 的图形用户界面和丰富的处理器允许用户创建简单和复杂的数据流,而无需编写代码。交互式体验使得在开发过程中对流程进行测试和故障排除变得非常容易。
Cloudera DataFlow 的流运行时在云原生和弹性环境中为生产中的流执行增加了稳健性和效率,使其能够扩展和缩小以适应工作负载需求。
在本博客的第二部分,我们将了解如何使用 Cloudera 流处理 (CSP) 来完成我们的欺诈检测用例的实施,对我们刚刚摄取的数据执行实时流分析。
了解有关 Cloudera DataFlow 的更多信息并试一试的最快方法是什么?首先,访问我们新的Cloudera DataFlow 主页。然后,参加我们的互动产品之旅或注册免费试用。
原文作者:André Araújo
原文链接:https://blog.cloudera.com/fraud-detection-with-cloudera-stream-processing-part-1/
关注微信公共号了解更多信息:
本文由mdnice多平台发布