【重识云原生】第四章云网络4.9.1节——网络卸载加速技术综述

1 网络卸载加速的起源
1.1 网络卸载(Offload)概念
网络offload主要是指将原本在内核网络协议栈中进行的IP分片、TCP分段、重组、checksum校验等操作,转移到网卡硬件中进行,CPU的发包路径更短,消耗更低,提高处理性能。
一开始这些offload功能都是在普通网卡上针对特定功能设计一个专门的电路并且带有很小的缓存,去做专门的事情。普通网卡是用软件方式进行一系列TCP/IP相关操作,因此,会在三个方面增加服务器的负担,这三个方面是:数据复制、协议处理和中断处理。于是便诞生了如下技术来实现offload:
- LSO(Large Segment Offload):协议栈直接传递打包给网卡,由网卡负责分割;
- LRO(Large Receive Offload):网卡对零散的小包进行拼装,返回给协议栈一个大包;
- GSO(Generic Segmentation Offload):LSO需要用户区分网卡是否支持该功能,GSO则会自动判断,如果支持则启用LSO,否则不启用;
- GRO(Generic Receive Offload):LRO需要用户区分网卡是否支持该功能,GRO则会自动判断,如果支持则启用LRO,否则不启用;
- TSO(TCP Segmentation Offload):针对TCP的分片的offload。类似LSO、GSO,但这里明确是针对TCP;
- USO(UDP Segmentation offload):正对UDP的offload,一般是IP层面的分片处理;

后来随着技术的发展,可直接在网卡上部署一个可编程的通用小型CPU,一般称为网络协处理器,也就是现在的智能网卡(Smart NIC)。智能网卡的协处理器可以先对该数据包进行一些预处理,根据处理结果考虑是不是要把数据包发送给主机CPU,智能网卡中的offload功能一般是使用eBPF编程来实现的。
1.2 数据中心级网络功能卸载技术发展
传统数据中心基于冯诺依曼架构,所有的数据都需要送到CPU进行处理。随着数据中心的高速发展,摩尔定律逐渐失效,CPU的增长速度无法满足数据的爆发式增长,CPU的处理速率已经不能满足数据处理的要求。

通用服务器处理网络负载的消耗情况图
以24核计算型服务器为例,网络功能占用6个core,虚拟化功能占用1个core,可用于VM的core数量为17个,可用CPU资源比例为70%。当网卡升级到100G时,CPU资源基本都被占用,算力资源基本不可用。
计算架构从以CPU为中心的Onload模式,向以数据为中心的Offload模式转变。以数据为中心的计算架构成为了趋势。以数据为中心的模式即数据在哪里,计算就部署在哪里。当数据在存储资源上,对数据的计算就在存储上执行。当数据在网络中流动时,对数据的处理就在网络上执行。通过架构的演进,典型的通信延时可以从30-40微秒,缩短为3-4微秒。网络计算和智能网卡/DPU成为数据中心计算架构的核心。

NVIDIA DPU功能框架
智能网卡/DPU通过集成多个面向不同应用的加速引擎,进行数据平面卸载,通过内嵌的ARM处理器或者其他协处理器进行控制平面的卸载。
在网络功能卸载方面,硬件替代CPU完成专业设备NFV后处理逻辑,实现硬件加速。同时,网络功能卸载将观察点从硬件交换机延伸到主机侧,实现网络端到端运维可视化。
1.3 交换offload在主机侧的实现
Linux 4.0引入了一个switchdev框架,它代表一类拥有“交换”能力芯片的多网口设备的抽象。其中每一个网口就是一个port,在switchdev框架中被注册成一个net_device。
switchdev起源于Open vSwitch项目,由Jiři Pirko在2014年9月首次提出。在2015年2月的Netdev 0.1会议上,网络开发人员决定扩展并采用switchdev作为硬件交换机芯片的通用解决方案。switchdev驱动模型出现之前,Linux需要交换机厂商的专门工具套件操作交换机,而在switchdev驱动模型之后,通用接口被实现,交换机正式纳入Linux网络设备体系,Linux可以用标准接口实现交换机的控制面和管理面。
架构:
在switchdev驱动框架下,硬件交换机设备上的每个物理端口都在内核中注册为一个net_device,就像对现有的网络接口卡(nic)所做的那样。可以使用现有的工具(如桥接、ip和iproute2)将端口绑定或桥接、隧道化或划分vlan。switchdev驱动程序的优点是这样的交换结构可以被卸载到交换机硬件上。因此,驱动程序将转发数据库(FDB)中的每个条目镜像到硬件,并监视其更改情况。
内核中switch架构图如下:

最初,switchdev支持的唯一设备是QEMU的“rocker”软件交换机。后来Mellanox和Broadcom等公司均提供了支持switchdev的交换机器。
OpenStack Pike版本中引入了对switchdev的支持,实现了Open vSwitch硬件卸载offloading功能。
OpenStack官方文档关于网络offload部分描述:
Supported Ethernet controllers:
The following manufacturers are known to work:
Mellanox ConnectX-4 NIC (VLAN Offload)
Mellanox ConnectX-4 Lx/ConnectX-5 NICs (VLAN/VXLAN Offload)
Prerequisites:
Linux Kernel >= 4.13
Open vSwitch >= 2.8
iproute >= 4.12
Mellanox NIC
2 网络加速的技术架构
目前业界主流智能网卡有四种实现方案:SoC、NP、FPGA、ASIC。
SoC方案在终端市场应用较成熟,硬件需要根据客户需求定制,部署周期较长,但是计算效率高,适合成熟算法及应用,功耗较低。
NP方案生态封闭,主流厂商已不再发布路标,不支持重编程,难以解耦,成本高于FPGA,但是功耗较低。
FPGA方案生态开放,在数据中心场景中得到广泛应用,可以重复编程实现特定应用,适合演进中的算法及应用,适用于网络转发等并行计算场景,该方案处理时延低,支持虚拟化,功耗适中。
ASIC方案,其硬件根据用户需求定制,开发成本昂贵,生产周期长,不具备灵活性,但是计算效率高,功耗较低,适合大规模成熟算法及应用。
2.1 基于智能网卡的网络卸载加速技术
智能网卡实现的网络加速有多种,除基本的网络功能外,还包括RoCEv2、VXLAN、OVS ct功能、TF-vRouter虚拟路由、kTLS/IPSec加速等技术。智能网卡的网络加速技术可以进一步细分为网络功能的加速以及网络能力的虚拟化。这里仅列举常见的几种技术及其应用。
OVS卸载技术,SmartNIC 负责L2转发,通过额外的处理逻辑实现部分vSwitch功能,能够卸载部分网络流量(例如基于Tc Flower Offload功能),支持对网络数据包包头的处理(如Push/Pop VLAN Tag、VXLAN Encap/Decap)。
Connection Tracking offload可以实现L3/L4 Firewall功能。
Header Re-write Offload 能够对packet header进行set/copy/add操作,可以实现路由、NAT等功能。
VIRTIO-net网络虚拟化技术。传统加速方式通过软件优化比如DPDK实现VM对网络设备的访问。大量的资源和时间损耗在软件层面,当前网络和PCIe设备的性能优势没有彻底发挥出来。智能网卡支持SR-IOV和VIRTIO技术,实现了IO硬件虚拟化,虚拟机可以直接访问网卡硬件设备的寄存器和DMA内存,同时借助于FPGA和SoC将OVS数据和控制平面完全卸载,大大提升了数据传输和处理的性能。SRIOV技术引入了两种虚拟化设备,PF和VF,在大多数虚拟机场景下,VM里的设备映射到不同的VF上,每增加一个虚机时,需要新增VF与其绑定。VF的配置和管理均由VMM完成。在裸金属场景,PF通常被用来作为网络或存储设备,PF的资源在FPGA加载时生成,当资源不足时,分配新的PF。PF设备的管理通过智能网卡SOC来管理。当增加PF时,SOC上将对应的PF设备使能,然后通知Host端添加新的设备。当不再需要PF设备时,通过SoC disable释放资源。
2.2 智能网卡网络加速的技术实现
智能网卡的本质能力是实现网络加速,在2021中国智能网卡研讨会中,包括中国移动、电信等企业的智能网卡产品,采用了多种智能网卡技术架构,实现了不同的网络加速功能。
中国移动IT云和网络云采用混合SDN方案,面向不同业务提供虚拟机或裸机部署能力,面向虚拟化场景,引入智能网卡突破提升vSwitch转发性能和数据处理能力;面向裸机场景,引入智能网卡构建弹性裸金属服务。面向虚拟化场景,将vSwitch转发面卸载至智能网卡中,提升转发性能及表项规格。软件vSwitch依靠CPU转发,通过将转发面卸载到硬件网卡,实现主机侧CPU零消耗,满足25G、100G网卡及后续更大带宽线速转发要求,提升块表规格到百万级甚至千万级,满足SBC等大规格网元部署需求。
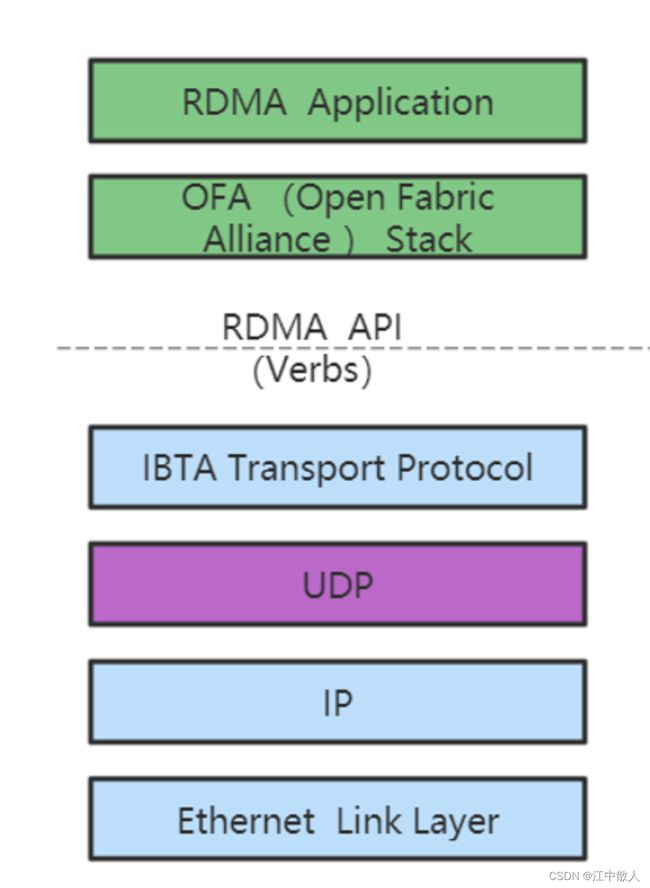
电信智能网卡协议栈
天翼云高级工程师、硬件加速组负责人孙晓宁在《天翼云智能网卡产品的前世、今生和未来》中介绍了电信ASIC架构的智能网卡中采用的网络加速技术,包括RDMA的代表性技术,以及RoCEv2、VXLAN隧道技术和OVS ct功能。
芯启源基于NP-SoC实现的全可编程DPU芯片具备网络报文处理引擎、流处理器引擎、接口引擎和加速硬件,支持高效的网络报文处理,具备极高的编程自由度。其基于DPU芯片的Agilio智能网卡支持OVS卸载,支持内核TC-Flower、DPDK RTE_FLOW,支持vRouter卸载,也支持Contrail 内核卸载。
迈普SNC5000-2S-NPDH1智能网卡,采用国产CPU飞腾+FPGA架构,在网络加速方面实现了VXLAN、GENEVE卸载、VIRTIO-NET模式卸载、SR-IOV卸载。OVS-DP通过FPGA实现硬件加速,用于卸载转发策略,实现数据快速转发。控制面卸载通过内嵌CPU实现,用于openflow协议运行和北向通信,支持OVS-DPDK。
腾讯智能网卡采用FPGA+SoC架构,网络加速技术实现方面自研vDPA,支持VIRTIO-net卸载,能够实现虚拟化性能零损耗,数据面直通,软硬结合跟踪脏页的功能。自研VIRTIO-net硬件后端核心IP,自研vSwitch Fastpath硬件卸载;自研vSwitch offload高度软硬协同的硬件驱动层。借助自研技术,智能网卡网络性能大幅度提升,PPS提升到40Mpps+,带宽提升到100Gbps。网络功能全部offload到智能网卡上,彻底消除Host CPU占用。内存带宽零抢占,高速网络流量在Host内存只穿越一次,降低内存带宽占比高造成对租户应用内存访问的影响。
Intel FPGA IPU C6000平台采用FPGA+x86 CPU架构,支持OVS卸载、NVMe over Fabric、RoCE卸载。
阿里通过主机协议栈延时优化、网络动态延时优化,将高性能网络的时延降低1个数量级。通过端网协同的网络流控,多路径优化和全链路网络QoS等机制来降低网络动态延时,减少网络拥塞,故障时快速切换,保障大小流之间的公平性,有效处理网络incast。其中端侧通过智能网卡/DPU的硬件卸载来优化网络协议处理。其自研的高性能网络协议,包括HPCC拥塞控制算法、Multi-path、xRD传输方式,去PFC实现Lossy RDMA,进一步优化长尾延时,增加RDMA扩展性。其自研的高性能网卡,实现了自研高性能网络协议卸载,目前已经落地云存储。
锐文科技推出的RAYMAX xSmartNIC智能网卡,支持SR-IOV、VIRTIO,支持Open vSwitch卸载,VXLAN、NVGRE tunnel加载及卸载,通过智能网卡的卸载应用,把耗费CPU大量资源的数据层查找卸载到智能网卡中,可提升超过30%吞吐量。
浪潮智能网卡采用了FPGA+CPU架构,FPGA提供了接近ASIC的处理能力,而X86为异常处理、存储和安全业务提供了高速处理能力。通过硬件方式实现了VIRTIO-net,数据面基于FPGA的可编程硬件网络包处理,SoC侧处理异常报文和控制面,支持OVS、VLAN、VXLAN、Conntrack Table以及IPSec等,减少Host端CPU负载,降低报文的延迟和抖动。
锐捷网络新推出的湛卢1.0 2*25G网卡产品,采用了FPGA+x86 CPU架构。该智能网卡产品基于RTE_Flow的流表卸载模型,支持开源OVS和锐捷商用vSwitch(RG-S1000v)。同时支持DPDK/SPDK的二次合作开发,支持VIRTIO-net、OVS全卸载,支持裸金属网络卸载。
英伟达的BlueField-2采用SoC架构设计,最大200Gbps带宽,内置ConnectX-6 Dx网卡芯片,支持RDMA,同时支持TLS/IPSec。以IPSec+VXLAN通信场景为例,通常情况下(X86+普通网卡),Throughput能达到21.2Gbps,采用DPU卸载方式能够达到88.9Gbps。如果达到90G处理速率,理想情况下需要消耗60个CPU核,采用DPU卸载方式,只需要消耗10个CPU 核,CPU核资源节省了83.3%。
3 总述
智能网卡进入高速发展期,行业内的主流厂家凭借其技术积累及应用场景,采用了多样化的技术架构,实现了效果差异的网络加速。正像赵慧玲女士在致辞中讲到的,产业发展呼吁加快标准化进程。技术标准化、规范化对于产业的发展起着积极作用。
参考链接
从DPDK和eBPF感受一下Smart NIC
智能网卡的网络加速技术 - 腾讯云开发者社区-腾讯云
NVIDIA ASAP² 技术保护并加速现代数据中心应用 - 知乎
FPGA加速器 - 知乎
常见网络加速技术浅谈(一) - 知乎
常见网络加速技术浅谈(二) - 知乎
网卡VXLAN的offload技术介绍_天马行空_xaut的博客-CSDN博客_offload
网卡offload功能介绍_hello_courage的博客-CSDN博客_offload
FPGA智能网卡综述(5): FPGA inline - 知乎
ASIC智能网卡综述(10):5层协议卸载L5P - 知乎
FPGA智能网卡综述(6):HostSDN - 知乎
网络硬件卸载简介_虚拟化云计算技术的博客-CSDN博客_硬件卸载
《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第三章云存储第1节——分布式云存储总述
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
-
第四章云网络4.9.1节——网络卸载加速技术综述
-
第四章云网络4.9.2节——传统网络卸载技术
-
第四章云网络4.9.3.1节——DPDK技术综述
-
第四章云网络4.9.3.2节——DPDK原理详解
-
第四章云网络4.9.4.1节——智能网卡SmartNIC方案综述
-
第四章云网络4.9.4.2节——智能网卡实现