MySQL 增删改查(进阶)
上一篇我们介绍了MySQL的比较基础的增删改查,这里介绍增删查改的一些进阶用法,说是进阶用法,实际上,最主要的进阶部分是查询部分,新增主要是把查询的结果在作为值插入;而查询的部分包含聚合查询、联合查询(多表查询);不涉及修改和删除的进阶。
MySQL 增删查改(基础)_Naion的博客-CSDN博客 https://blog.csdn.net/Naion/article/details/125809324?spm=1001.2014.3001.5501这里继续使用idea远程连接数据库来进行说明。idea如何远程连接请点击链接。
https://blog.csdn.net/Naion/article/details/125809324?spm=1001.2014.3001.5501这里继续使用idea远程连接数据库来进行说明。idea如何远程连接请点击链接。
数据库约束
如图所示,现在我的想法是:能不能当没有给id赋值的时候,给他一个默认的值?或者要求只能插入一个张三。要实现这些功能,需要用到数据库的约束。
约束类型
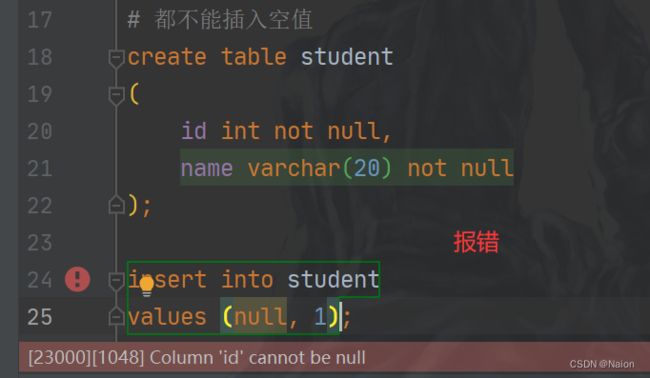
(1)NOT NULL - 指示某列不能存储 NULL 值,当插入的值为null的时候,报错;
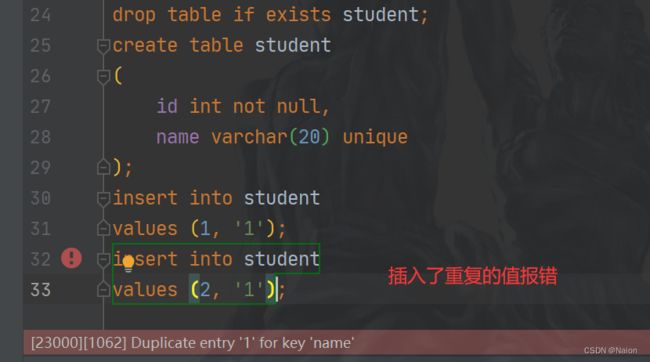
(2)UNIQUE - 保证某列的每行必须有唯一的值,不能出现重复的值;
(3)DEFAULT - 规定没有给列赋值时的默认值;
(4)PRIMARY KEY - NOT NULL 和 UNIQUE 的结合,确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。
(5)FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
(6)CHECK - 保证列中的值符合指定的条件。但是MySQL不支持check语句。
比如:
not null约束
unique约束
default默认值约束
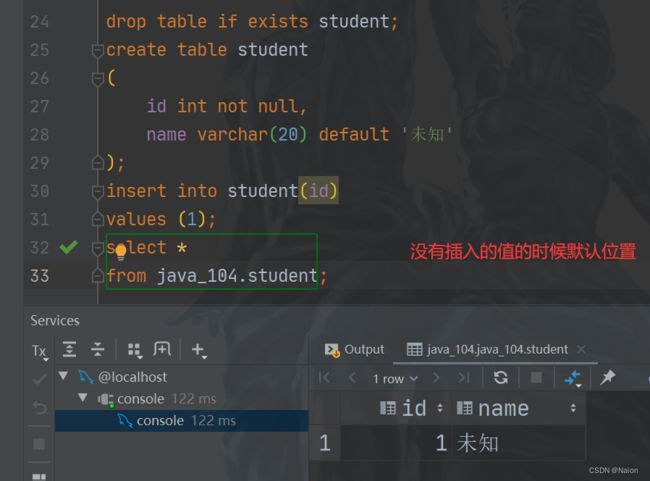
primary key主键约束
主键是not null 和 unique 的结合,对于整数类型的主键,经常和auto_increment使用,这样就可以只插入name,id就会自动给你计算,每插入一个,数值加1。
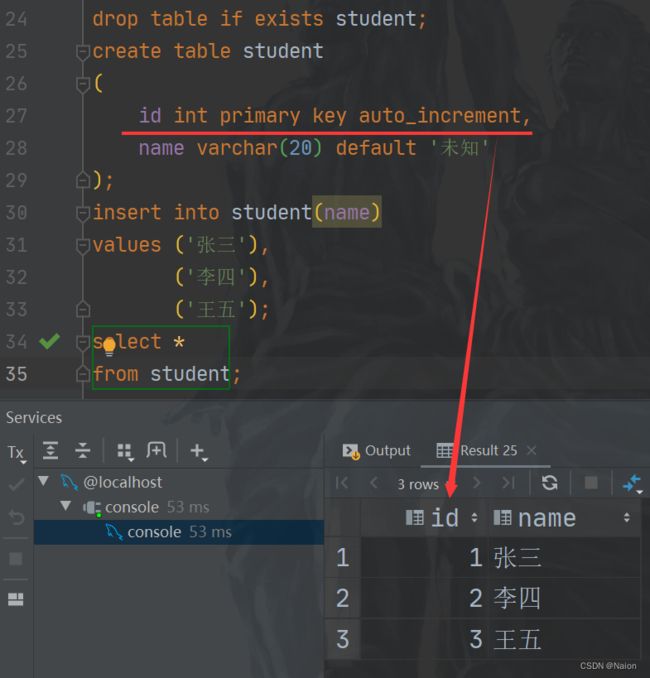
foreign key 外键约束
foreign key (字段名) references 主表(列)
用于关联其他表的主键或唯一键。关联不是主键或唯一键就会报错。比如,学生有自己的班级,张三和李四是1班的,王五是2班的。
create table class
(
class_id int primary key auto_increment,
class_name varchar(20) unique
);
insert into class(class_name)
values ('mysql1班'),
('mysql2班');
create table student
(
id int primary key auto_increment,
name varchar(20) not null,
class_id int, # 班级id
foreign key (class_id) references class(class_id)
);
insert into student(name, class_id)
values ('张三', 1),
('李四', 1),
('王五', 2);
select *
from student;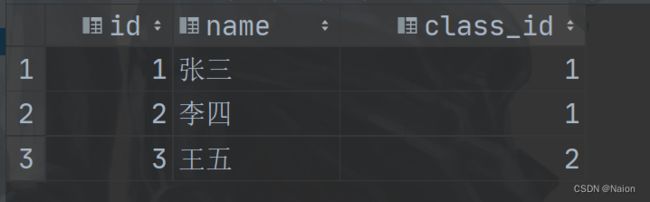
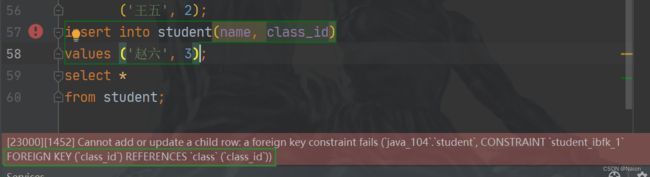
如果我插入了三班,就会报错。
新增
把查询的结果作为值插入。
INSERT INTO table_name [(column [, column ...])] SELECT ...
比如,创建了student2表,把student的内容拷贝到student2表中。

聚合查询
基础的查询和条件查询是针对列和列之间的查询。要针对行和行之间进行插入,就要使用聚合查询。
聚合函数
比如查询student表的人数,使用count()函数。

group by子句
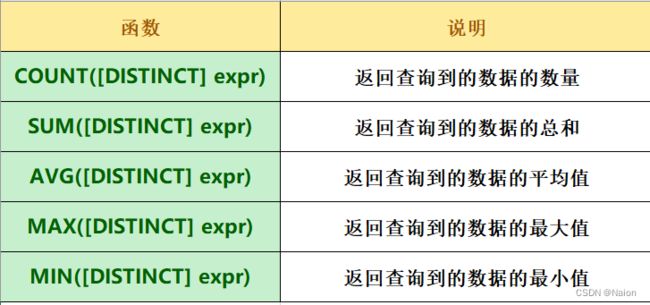
select column1, sum(column2), .. from table group by column1,column3;
使用group by子句对指定的列进行分组,注意的是使用group by进行分组查询时,select指定的字段必须是“分组依据字段”,其他字段若想出现在select中则必须包含在聚合函数中。比如查询两个班分别有多少人。
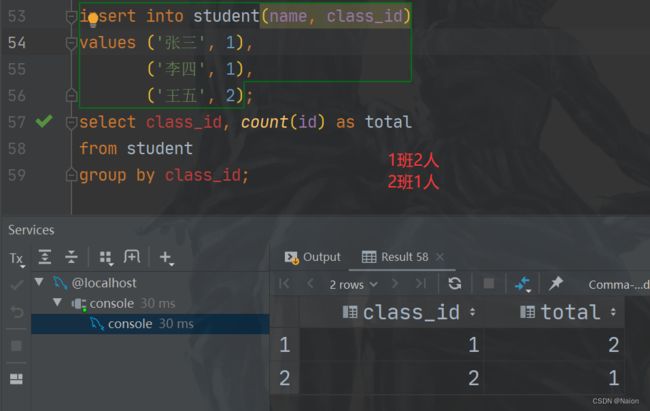
当然也可以在group by子句之前使用where语句,达到先筛选后分组的效果,不允许where语句放在group by子句后面,否则使用having语句。
having
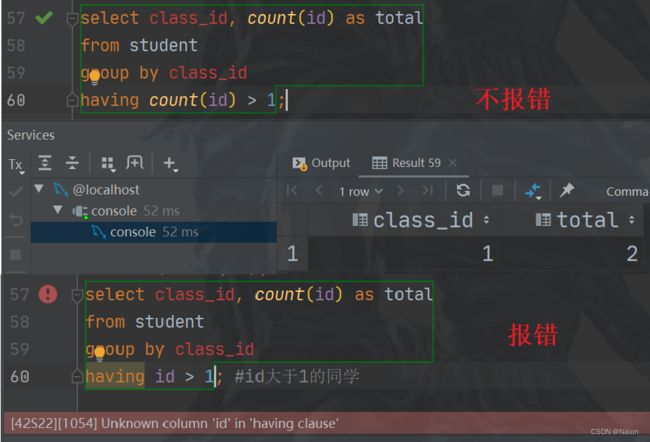
where放在group by之前,是先筛选在分组;group by之后要进行筛选,不允许使用where,而是使用having。where子语句作用于没有经过分组的表和视图,having语句作用于经过分组的组。where语句不能包含聚合函数,而having里面经常使用聚合函数。
比如分组后查询人数大于1的班级。
当然可以同时使用where 和 having 在group by子句中。
联合查询(多表查询)
在实际的开发中,需要使用多张表进行联合查询,比如,联合查询学生对应的班级,这里不是查询对应的id,而是每一个学生对应的班级名。多表查询就是对多张表数据取笛卡尔积。
笛卡尔积,又叫cross join,是SQL中两表连接的一种方式。假如A表中的数据为m行,B表中的数据有n行,那么A和B做笛卡尔积,结果为m*n行。
通常我们都要在实际SQL中避免直接使用笛卡尔积,因为它会使“数据爆炸”,尤其是数据量很大的时候。但是巧妙使用,反而快速帮助我们解决问题。
内连接
select * from A,B;
select * from A [inner] join B on 连接条件 and 其他条件;
联合查询学生对应的班级,先进行笛卡尔积。
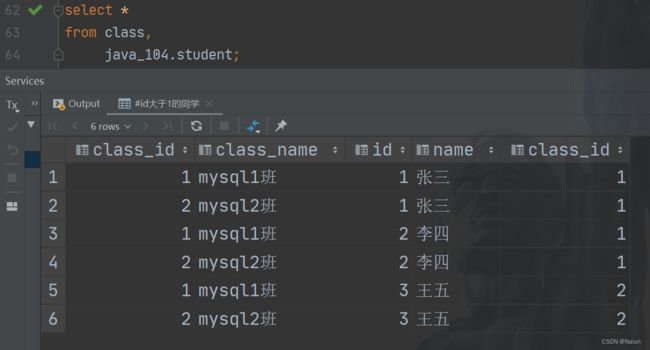
我们可以看见查询的结果是非常多的,这个时候,需要确定连接条件,过滤无效信息。观察就可以知道,student表中的class_id一定是和class_id中的值一一对应的关系,在student表中,1班当然对应class表中的1班,加上这个条件。
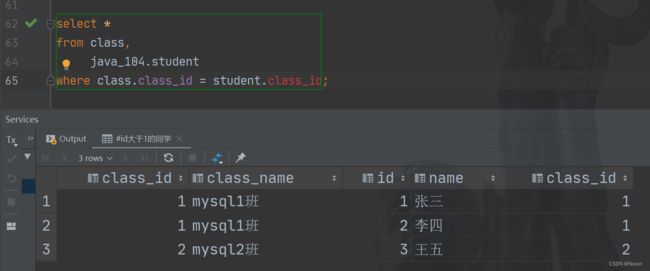
现在看起来这个表的数据就好多了。我们需要的是学生对应的班级,所以在筛选一下列。
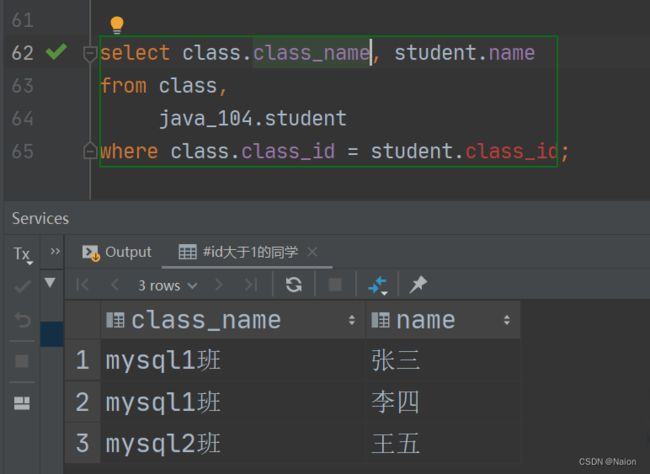
上面的步骤可以一气呵成,但是刚开始的时候,就需要慢慢来。
使用带join的语句。
select class.class_name, student.name
from class
join java_104.student
where class.class_id = student.class_id;
# on class.class_id = student.class_id; # 或者使用on来连接两个语法都能达到目的,join还有特殊的用法。
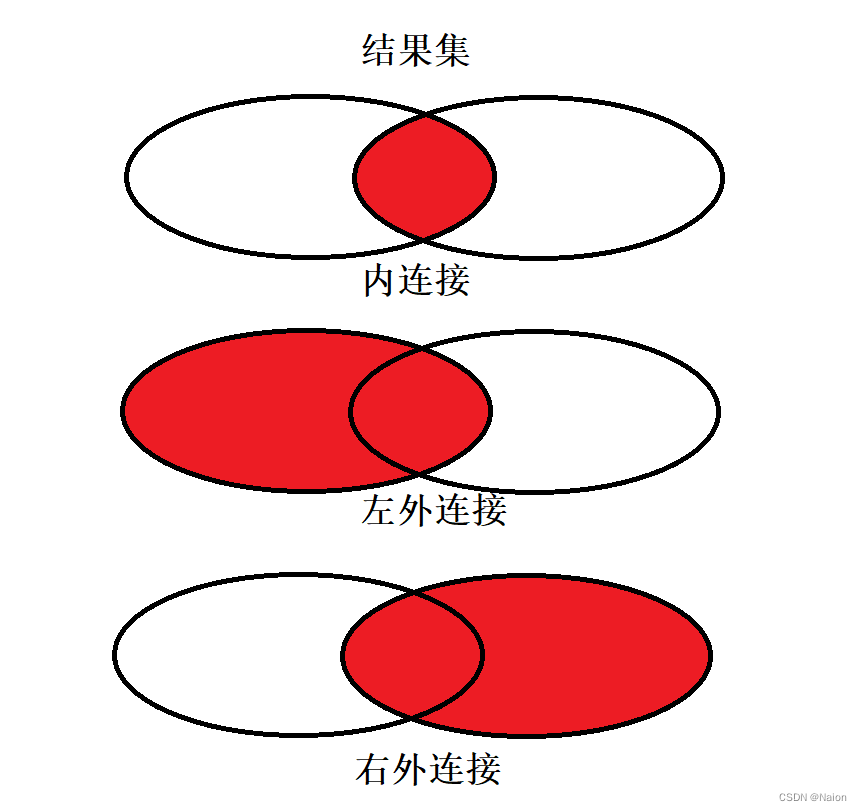
外连接
外连接分为左外连接和右外连接。如果联合查询,左侧的表完全显示我们就说是左外连接;右侧的表完全显示我们就说是右外连接。
-- 左外连接,表1完全显示
select 字段名 from 表名1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
现在在class表中新增班级,student表中新增学生,但是没有班级。
然后看看左外连接和右外连接的区别,以及和内连接的区别。
insert into class(class_name)
values ('mysql3班');
insert into student(name)
values ('王麻子');
select class.class_name, student.name
from class
left join student
on class.class_id = student.class_id;
select class.class_name, student.name
from class
right join student
on class.class_id = student.class_id;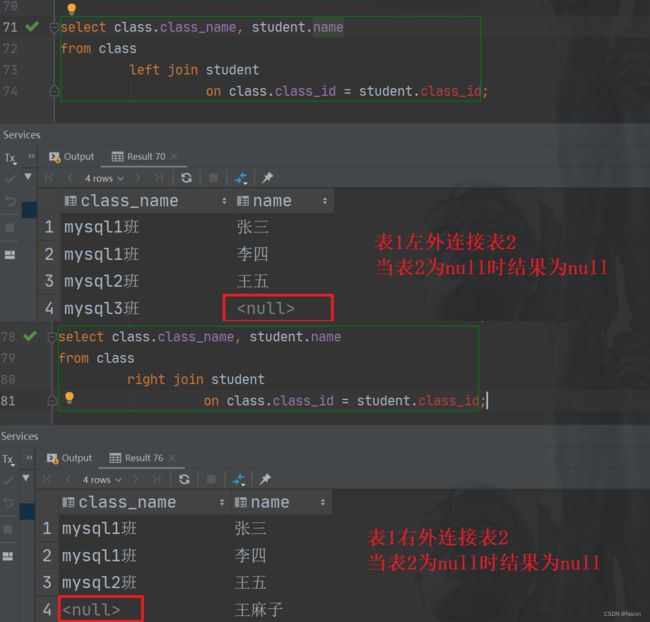
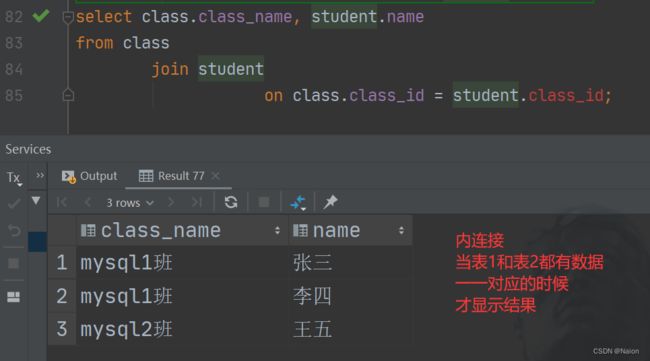
他们的结果可以使用图来清晰的表示。
自连接
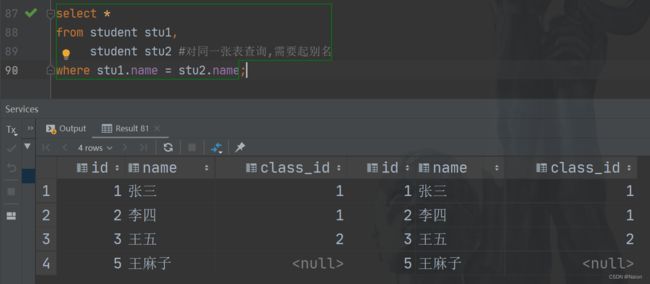
自己连接自己进行查询。这种查询是一种奇技淫巧,用来把行转换成列进行查询。查询的过程中需要对表起别名,否则报错。比如在同一张表中进行比较就需要用到这种查询。这里只写用法。
子查询
子查询是嵌入在其他sql语句中的select语句,也是叫嵌套查询,俗称套娃。
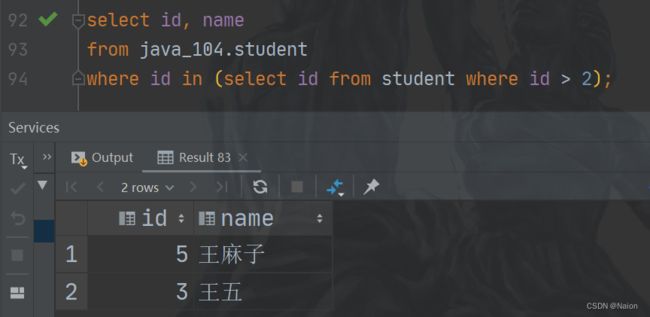
单行子查询只返回一行记录,多行子查询使用 in 关键字返货多条查询。比如,查询学生id大于2的学生 id 和姓名,这里不使用条件查询。
合并查询
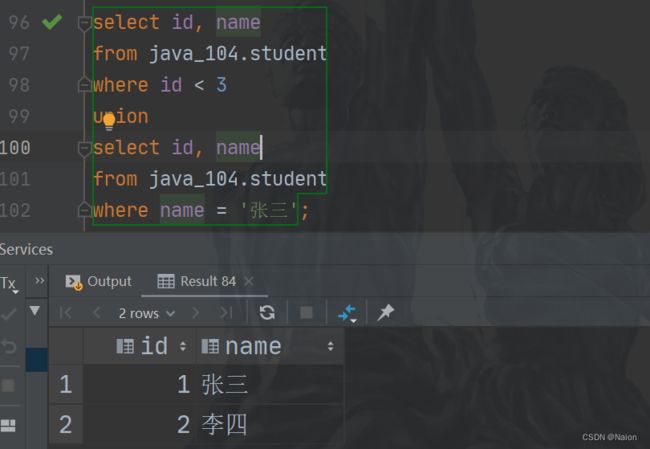
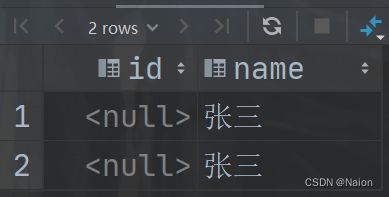
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION 和UNION ALL时,前后查询的结果集中,字段需要一致。该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
union 查询的结果会自动去掉结果集中的重复行,但是union all不会。
查询 id 小于3或者学生姓名为"张三"的结果。结果和使用or条件查询结果一致。