MySQL--增删改查(进阶)
MySQL--增删改查(进阶--上)
- 一丶数据库约束
-
- (1)约束类型
-
- 前三种约束示范
- 主键约束和外键约束
- (2)新增
- 二丶查询
-
- (1)聚合查询
-
- 1>聚合函数
- 2>group by 子句
- 3>having子句
- (2)联合查询
-
- 1> 内连接
- 2> 外连接
- 3> 自连接
- 4>子查询
- 5>合并查询
一丶数据库约束
我们在查询数据库的时候,通常要进行约束,不然就会出现各种各样意外的情况,导致我们的查询遇到困难。
(1)约束类型
通常我们的约束有以下几种:
NOT NULL - 指示某列不能为 NULL。
UNIQUE - 保证某列的每行不能重复
DEFAULT - 规定没有给列赋值时的默认值。
PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或多个列的结合)有唯
一标识,有助于更容易更快速地找到表中的一个特定的记录。
FOREIGN KEY - 保证一个表中的数据匹配另一个表中的值的参照完整性。
CHECK - 保证列中的值符合指定的条件。对于MySQL数据库,对CHECK子句进行分析
,但是忽略CHECK子句。
前三种约束示范
首先,上面就是关于非空约束,唯一约束,默认值约束的正确写法,那么我们来实验一下,是否真的约束成功。
非 空 约 束 \color{red}{非空约束} 非空约束
唯 一 约 束 \color{red}{唯一约束} 唯一约束

默 认 值 约 束 \color{red}{默认值约束} 默认值约束
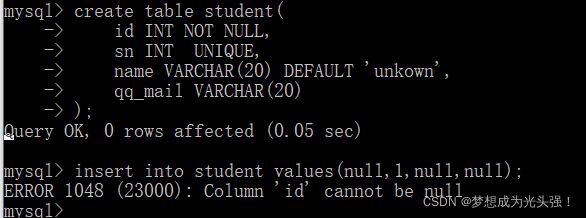
这里有一个问题需要注意:

我们在插入值的时候一定要指定是那一列,不然数据库识别不出来,所以上面的写法会报错。
正确的写法如下:

主键约束和外键约束
主 键 约 束 \color{red}{主键约束} 主键约束
首先什么是主键约束呢?
主键约束就是 unique + not null。
那么主键约束有什么用呢?
用来标识数据库中的数据,数据是在不同设备中流转的,一般来说,web开发中的数据是在:
<1>用户浏览器
<2>java程序
<3>数据库
中流转,当我们使用主键约束时候,就知道是哪条数据了。
那这里有一点需要特别说明的,如果主键为整形数字,可以指定为auto_increment表示从1开始自增,但是插入数据的时候,不要指定插主键字段。
具体形式如下:

可以看到第一行,我除了加入约束主键之外,我还加入了自增,那么有什么用呢?
可以看到,每当我插入一个数据的时候,主键id就开始了自增,这也是auto_increment的作用
外 键 约 束 \color{red}{外键约束} 外键约束
关于外键约束,目的是在于使用内外连接的时候,关联其他表的主键或者说是唯一键。
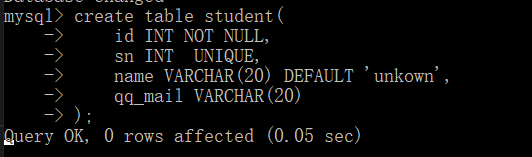
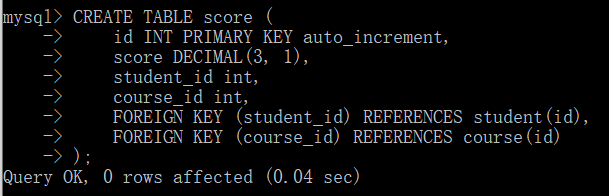
具体用法如下,这里我们重写一下student表。
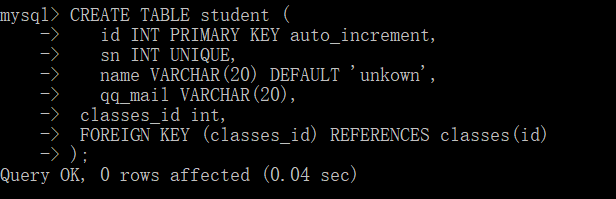
这样我们就把班级表的id和学生表的id关联起来了。
(2)新增
这里的新增指的是把查询结果新增到一个表当中。
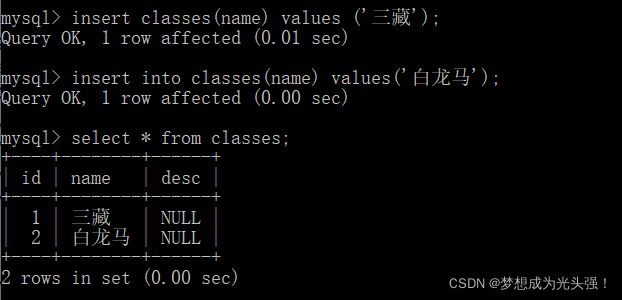
那我们先创建一张表用来测试:
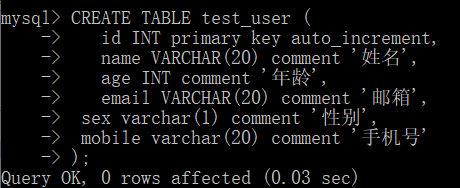
创建成功之后,接下来我们把查询结果新增到一个表当中。
insert into test_user(name, email) select name, qq_mail from student;
二丶查询
这里的查询也是这里的重难点。
(1)聚合查询
1>聚合函数
首先我们常用的聚合函数有以下几种
1、AVG函数;2、COUNT函数;3、MAX函数;4、MIN函数;5、SUM函数;
其作用分别是
1.平均值
2.求数据量
3.求最大值
4.求最小值
5.求总和
具体的写法如下:
select 函数名(字段名) from 表名
比如就像下面这样:
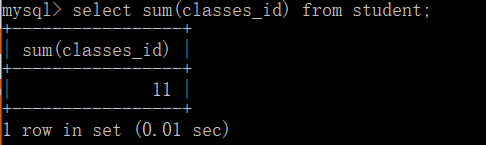
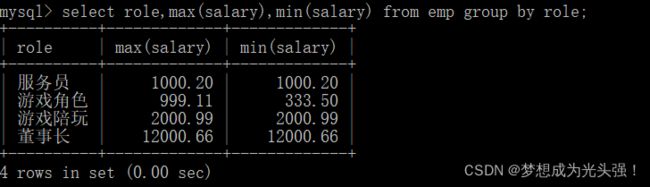
2>group by 子句
select 中使用 group by子句对指定列进行分组查询,这里需要注意:使用group by进行分组查询的时候,select指定的字段必须是分组依据字段,其他字段若想出现在select中则必须包含在聚合函数中。
接下来对group by子句进行试验。
首先准备一张测试表:
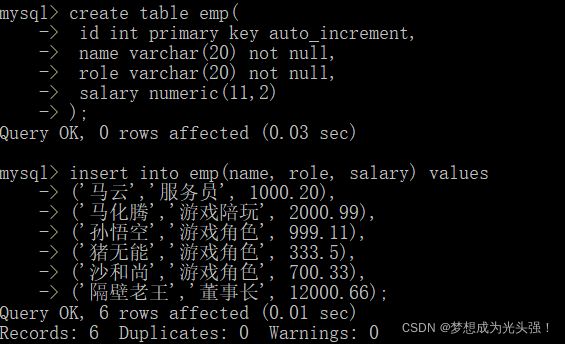
然后我们对其进行分组+聚合查询。
那么这里特别注意的就是分组时候选择的字段。是name还是role呢?
注意是role,因为name是唯一的,所以没必要进行分组。
3>having子句
这里注意了,使用group by子句进行分组以后,如果想要继续进行条件过滤,就不可以使用where了,因为使用where在某些条件下会造成查询结果的错误。那么这里我们就需要使用having子句。

(2)联合查询
在讲联合查询之前,首先要引入笛卡尔积的概念,
笛卡尔乘积是指在数学中,两个集合X和Y的笛卡尔积(Cartesian product),又称直积,表示为X×Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
什么意思呢?就是说如果集合A有两个元素:a,b。集合B有两个元素:c,d。那么他们笛卡尔积就是:ac,ad,bc,cd。
有了这个概念,我们接下来引入接下来的内容。
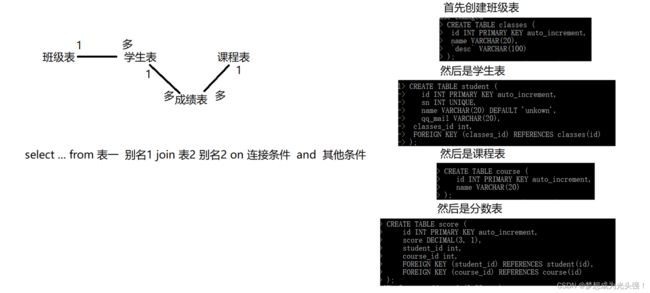
首先我们要重新创建表,用来演示接下里的内容。
总共四张表,其关系如下:
我们把其数据处理完毕之后,然后开始进行我们接下来的内容。
首先验证一下笛卡尔积
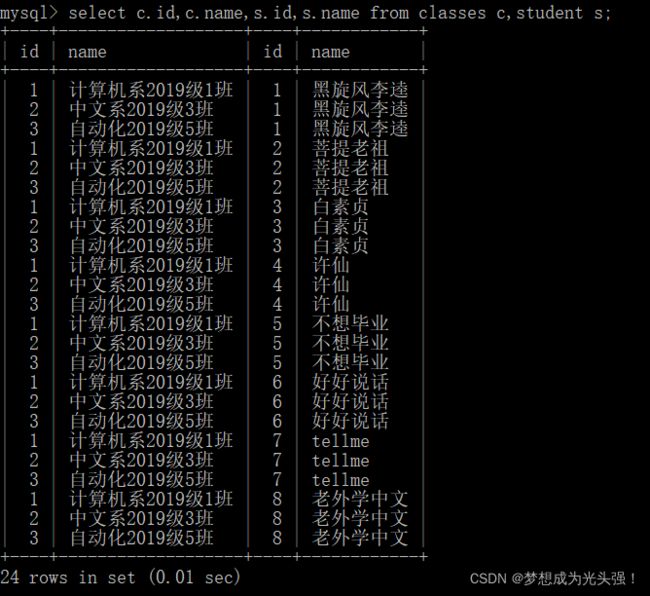
当然,这里的id和name可能看起来不是很清晰,所以我们可以给后面取别名加以分辨。
1> 内连接
我们可以发现,上面的查询结果有很多我们不想要的,因为笛卡尔积是把两个对象的元素两两互相匹配,就导致有很多其他的以外的元素。
这个时候就需要使用到内连接。内连接有两种写法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他
条件;
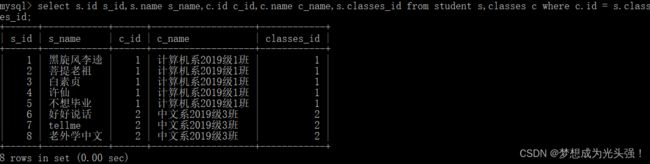
select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
首先试一下第二种:
然后再试一下第一种:
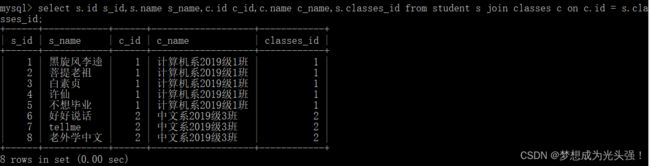
这就是内连接的两种写法。
然后具体应用场景可以有以下几种。
(1)查询某位同学的成绩

可以发现,我们联合学生表和成绩表就可以查出某位同学的具体成绩,但是问题是我们不知道这四门成绩分别对应的哪一门,这个时候我们就有了更高的需求。
(2)查询某位同学的成绩,带上课程名称
这里我们就需要第三张表了,也就是我们的课程表。
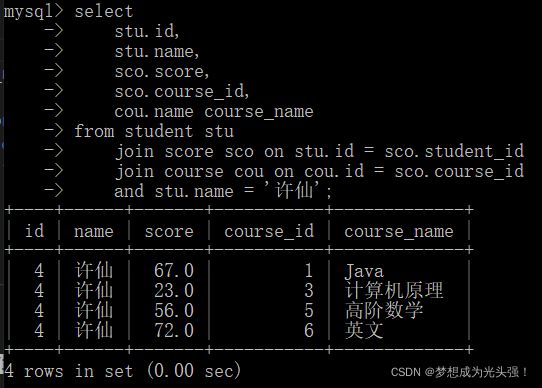
(3)查询所有同学的总成绩,以及同学的个人信息
首先如果说我们要满足上面的需求,那么先要查询成绩表,和学生表
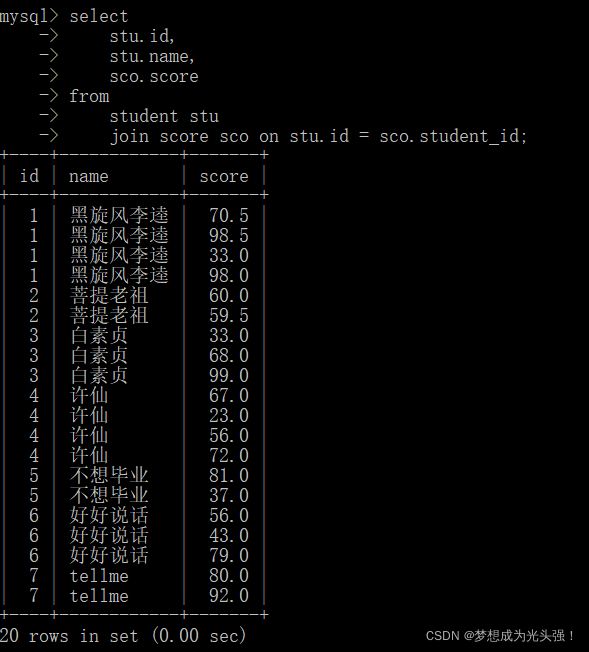
这里每一门成绩都有了,但是我们不需要,我们需要的是总成绩。
所以这里需要换一种写法。
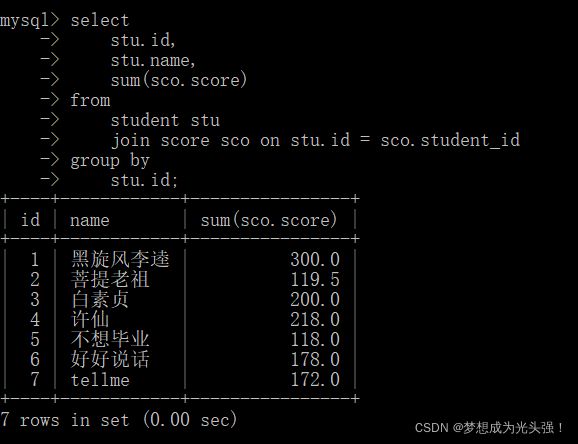
2> 外连接
这里内连接其实是有一个小问题的,那就是如果说没有stu.id对应相等的sco.student_id,那么这个数据是不会显示出来的,所以为了应对这种情况,我们就需要使用外连接。
所谓外连接:
外连接:左外连接,左表叫外表,右外连接,右边的表叫外表
– 两张表关联,外表中在按其他条件过滤后的数据,会全部显示(按连接条件,另一张表没有的数据,也会显示)
– 要显示没有分数的学生,需要使用外连接
是什么意思呢?首先我们用内连接来看一下:
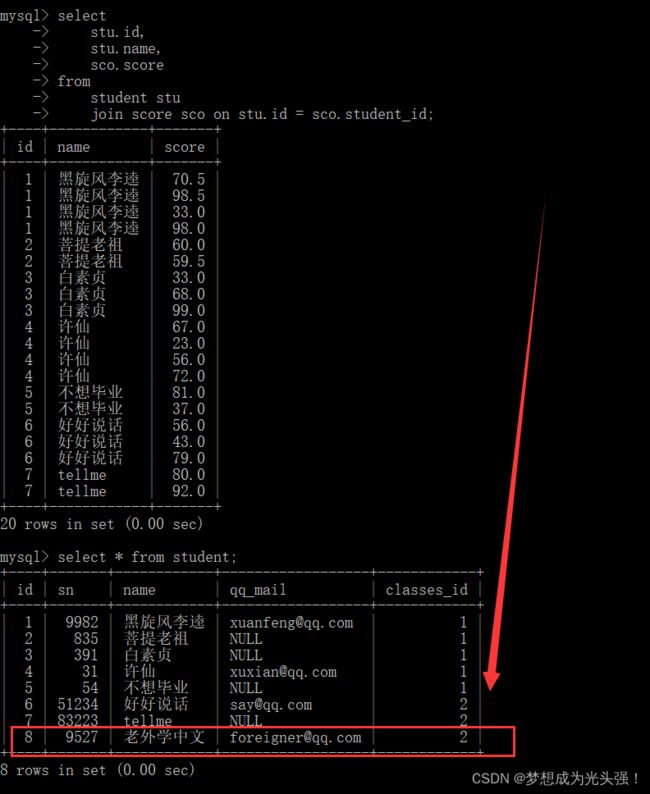
如果使用内连接,我们的“老外学中文”同学的成绩因为没找到对应的sco.student_id就不会显示。
为了应对这种情况。我们就需要使用内连接。
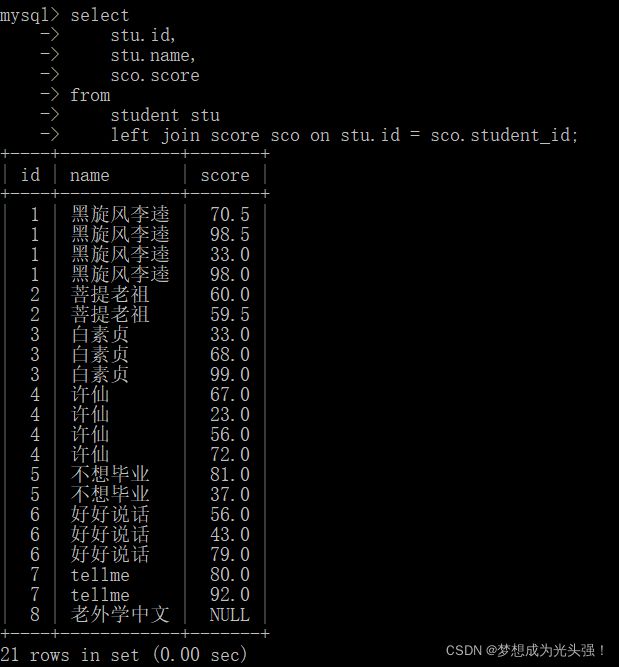
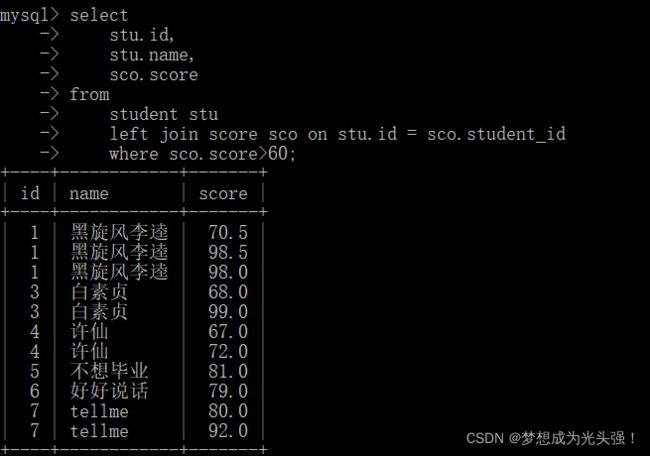
但是我们还可以继续加其他的约束条件,比如说我们想要成绩在60分以上的成绩,就想看看那些成绩是合格的。
3> 自连接
所谓自连接,就是自己和自己连接,就是在同一张表连接自身进行查询。举个例子,查询一下“计算机原理”成绩比“java”高成绩
SELECT
s1.*
FROM
score s1
JOIN score s2 ON s1.student_id = s2.student_id
AND s1.score < s2.score
AND s1.course_id = 1
AND s2.course_id = 3;
对应查询结果如下
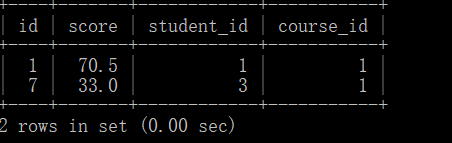
当然我们可以发现上面的只显示了成绩信息,并且执行分布,我们如果说要显示成绩等信息还需要增加额外的条件。
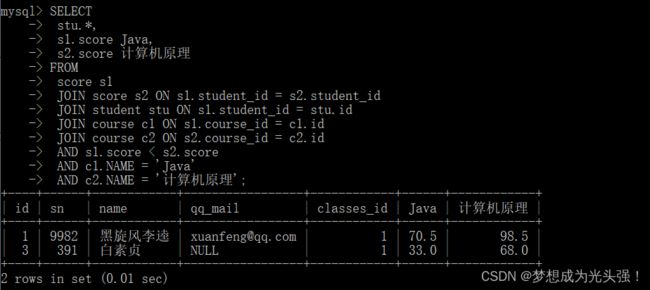
SELECT
stu.*,
s1.score Java,
s2.score 计算机原理
FROM
score s1
JOIN score s2 ON s1.student_id = s2.student_id
JOIN student stu ON s1.student_id = stu.id
JOIN course c1 ON s1.course_id = c1.id
JOIN course c2 ON s2.course_id = c2.id
AND s1.score < s2.score
AND c1.NAME = 'Java'
AND c2.NAME = '计算机原理';
对应查询结果如下
4>子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
1.单行子查询
单行子查询:返回一行记录的子查询。比如说查询与“不想毕业” 同学的同班同学:
select * from student where classes_id=(select classes_id from student where
name='不想毕业');
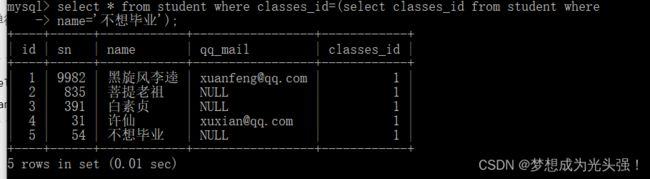
2.多行子查询
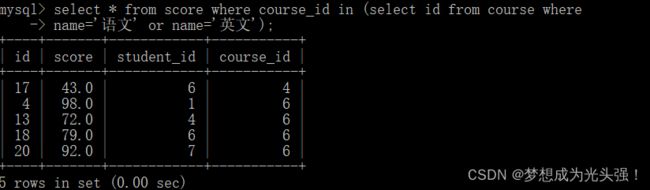
多行子查询:返回多行记录的子查询,比如说:查询“语文”或“英文”课程的成绩信息
select * from score where course_id in (select id from course where
name='语文' or name='英文');
3.在from子句中使用子查询
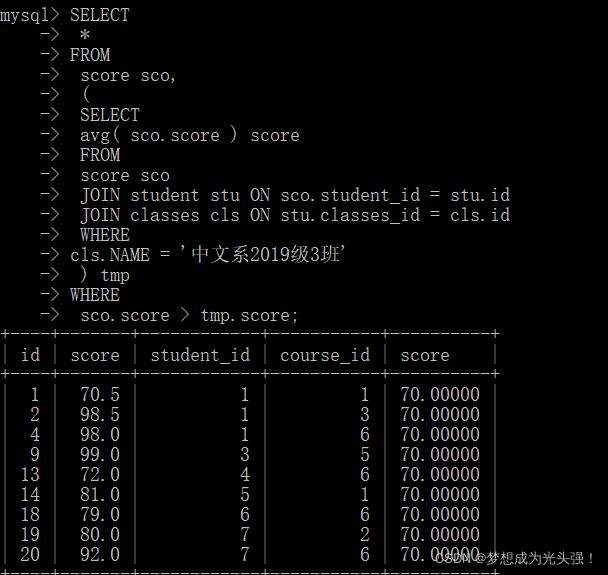
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。比如查询所有比“中文系2019级3班”平均分高的成绩信息:
SELECT
*
FROM
score sco,
(
SELECT
avg( sco.score ) score
FROM
score sco
JOIN student stu ON sco.student_id = stu.id
JOIN classes cls ON stu.classes_id = cls.id
WHERE
cls.NAME = '中文系2019级3班'
) tmp
WHERE
sco.score > tmp.score;
5>合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all。使用UNION和UNION ALL时,前后查询的结果集中,字段需要一致。
u n i o n \color{red}{union} union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行
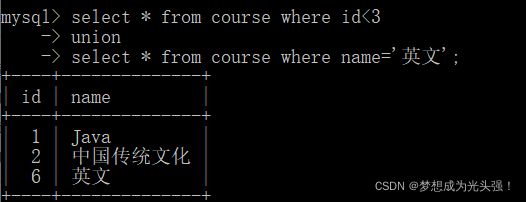
举一个例子:
//查询id小于3,或者名字为“英文”的课程:
select * from course where id<3
union
select * from course where name='英文';
u n i o n a l l \color{red}{union all} unionall
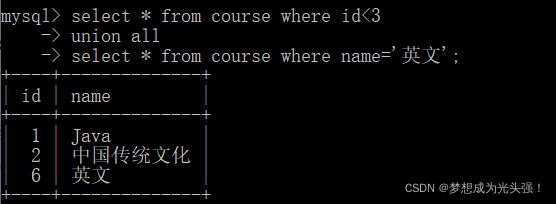
该操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。
举一个例子:
//查询id小于3,或者名字为“Java”的课程
select * from course where id<3
union all
select * from course where name='英文';