服务端渲染(SSR) 通用技术解决方案
项目背景
服务端渲染(SSR) 通用技术解决方案的诞生来源于对 360搜索百科移动端项目的一次重构实践。而当时决定重构该项目的主要原因有以下几点:
1. 技术栈陈旧,熟悉、开发以及维护成本都较高
项目重构前的开发技术栈是 smarty + php + jQuery 的模式。在前端技术发展迅速的今天,vue 与 react 裹挟下的组件化开发模式愈发盛行,模块化语法开发模式也是层出不穷,这使得 smarty 开发模式对新人来说理解起来比较生涩难懂。
2. 项目结构管理混乱
项目重构之前存在2个代码库并存的状况。之前的同学为了项目开发的模式更加与时俱进,对项目的图册页进行了单独的抽离,采用了当时最新的 esNext 语法 和 webpack 的模块化开发模式进行了一次重构。但项目的开发流程很复杂:
- 首先两个分离的项目需要并存在同一个开发环境下。
- 其次需要对图册页的 webpack 进行自定义的配置,才能使得图册页项目的开发代码被构建到另一个整体代码项目中,这需要对 webpack 有一定的了解。
- 最后编译到整体代码中的 css 文件中还需要手动删除多余的 js 文件避免内部编译的报错。
3. 重构的目标
除去上述两种原因外,由于该项目的周期已经非常久远,随着开发维护的不断变更,很多项目模块、代码文件也已经变的非常臃肿。所以本次的重构,除了要统一所有的页面技术栈,通过 eslint、commitlint、stylelint 等工具来统一开发规范外,重新梳理组织项目文件和目录结构以及相关业务模块也是重中之重。
重构技术选型
对于该项目的重构,最初我们构想了三种方案:
保持当前的技术栈 smarty + php + jQuery 模式,对现有的模块及目录结构进行重新梳理和调整。
采用 React + Next + Webpack 的技术栈做 SSR 渲染。
采用 Vue + Nuxt + Webpack 的技术栈做 SSR 渲染
首先,无论从技术发展的角度,或是从后期项目的维护与开发效率来看,方案一都失去了重构本来的初衷。毕竟,拥抱前沿技术,提高开发效率的重构才更有意义。
其次,我们对 React + Next 和 Vue + Nuxt 的技术栈做了调研对比:
在相同吞吐量的情况下,两者的平均响应时间几乎是相同的,都比 smarty 模式要慢但在可接受范围内。
从学习成本来说 vue 的技术栈更为大家熟悉和容易接受,这在一定程度上可以减少学习和开发时间。
鉴于同期开展的 solib/m-vue 项目,可以在本次采用 vue 技术栈重构的同时,将可公用的模块进行组件化抽离到 solib/m-vue 中,形成一个既支持 SSR 又支持 CSR 模式的组件库,为后续其他移动端项目的重构提升开发效率。
团队的星座项目就采用了 vue + nuxt + webpack 的技术栈,有可以借鉴的案例。
鉴于上述的对比和考虑,我们决定采用 Vue + Nuxt + Webpack 的技术栈进行 SSR 渲染模式的方案。
什么是 SSR 渲染?
在技术选型上,无论是采用 React 或是 Vue 我们都提到了一个关键字 —— SSR渲染。
什么是 SSR 渲染模式,以及为什么要使用 SSR 渲染呢?我们以 Vue 的 SSR 渲染模式为例。
CSR 模式
先从 CSR 模式说起,CSR 又称 "客户端渲染"(Client Side Render),它还有另一个常见的称呼 ——"单页应用" (SPA)。
SPA的请求流程大概如下:
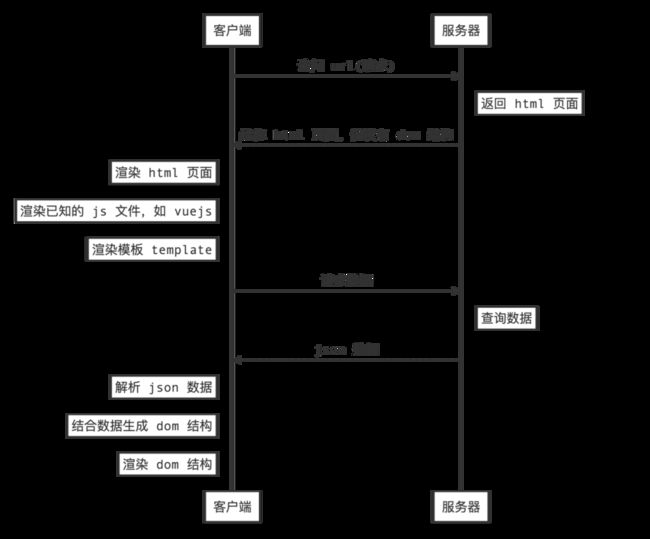
SPA 模式的请求执行顺序至少包含两个来回(空的 html 页面和数据的获取渲染),它有两个痛点:
首屏内容到达时间较长,也就是常说的白屏时间较长。毕竟先渲染的是一个空白的 html 结构,然后再发送请求获取相关的页面数据信息进行渲染。
SEO不够友好,搜索引擎爬虫抓取工具需要直接查看完全渲染的页面。
爬虫可以很好的对同步 JavaScript 应用程序进行索引,同步是关键。如果应用程序初始展示 loading 状态,然后通过 Ajax 获取内容,抓取工具并不会等待这个异步的过程。所以,如果 SEO 对站点至关重要,而页面又是异步获取内容,CSR显然不能满足需求。
于是,便有了 SSR 渲染模式。
SSR 模式
SSR 被称为"服务端渲染"(Server Side Render)。
Vue.js 是构建客户端应⽤程序的框架。默认情况下,它是在浏览器中输出 Vue 组件,进⾏DOM 的⽣成与操作。
然而,如果将⼀个组件在服务器端渲染成带有静态标记的 HTML 字符串,然后将它们直接发送到浏览器,最后将这些静态标记进行 "激活",使其成为客户端上完全可交互的应⽤程序,一个 SSR 渲染模式的雏形就形成了。
更进一步,如果只针对页面刷新或第一次访问服务的 url 在服务端渲染出对应的 dom 结构进行返回。然后将类似于路由信息、状态信息等以⼀种延迟的⽅式返回到客户端,当客户端获取到⾸屏结构和 spa 运⾏机制后,对带有静态标记的部分进⾏激活,然后使其按照 spa 的模式运⾏就更完美了,这就是常说的 "首屏渲染" 模式。
由于程序⼤部分的代码可以在服务器和客户端上同时使⽤,Vue SSR 很多时候也被称为"同构"应⽤。
来看一下它的请求流程图:
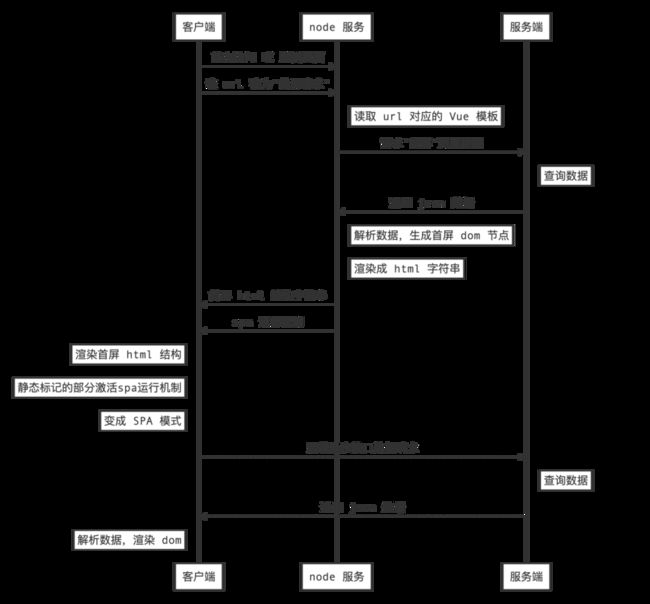
Vue SSR 构建基础原理
下图就是 vue ssr 构建的基础原理图,详情可以参考Vue.js 服务器端渲染指南。
它是通过 webpack 在构建服务时,生成两份配置:一份客户端 bundle.js、一份服务端 bundle.js。
服务端的 bundle 用来渲染生成首次访问的 html 字符串并返回给客户端,到了客户端之后实际上挂载执行的是客户端的 bundle,这个流程在客户端叫 "Hydrate" 。类似于泡面,服务端负责包装出售,客户端负责拆袋加水放调料即可。

SSR 通用解决方案都有什么?
说完 SSR 渲染的原理,我们来看看 SSR 通用解决方案都有什么内容。
so_nuxt 脚手架
首先,项目的重构是站在巨人的肩膀上开展的,我们使用了针对 Vue.js 设计的 ssr 开发框架 —— Nuxt.js。而so_nuxt 脚手架则是以 nuxt 为基础,在适合我们当前开发和部署的环境下进行了功能补充。
我们对重构的项目结构进行抽象化剥离,去掉业务代码部分,将公共部分封装成通用模板文件。接入了询问流程,根据使用者的意愿生成不同开发形式的项目结构。同时,将 so_nuxt 脚手架接入了我们搜索前端团队开发的so-cli 通用脚手架工程中。使用者在安装 so-cli 后,可以像使用 npm 或 yarn 指令一样在全局通过 socli run 创建 SSR 项目,便利且快速!
在 so_nuxt 脚手架创建的项目中,提供了服务端日志打印、node 服务的探针配置以及 solib/m-vue 组件库接入等示例方案。
nuxt2-qcdn-plugin 插件
静态资源上传至 qcdn 是一个项目上线前最基础的优化方案。它不仅能加速网站的访问速度,还拥有实现跨运营商、跨地域的全网覆盖,更能保障网站的安全,节约成本的投入等等好处。nuxt 独特的资源构建目录无法兼容先前组内同学开发的 webpack-qcdn-file 插件。于是,为了便于后续的维护和其他项目的接入,我们为 nuxt 单独开发了上传静态资源的插件。
CSR 兜底策略
为了保证服务的稳定性,确保在 node 服务出现无法预料的突发状况下仍能保证线上服务可以访问,我们设计了 CSR 兜底策略。项目中接入了团队同学开发的 vm-spider 工程,在服务变更成 CSR 模式后,不仅保证了服务的可访问性,更不影响爬虫的收录。
所有信息记录在案
鉴于 SSR 通用解决方案并非都是代码角度的实现,我们对其他的流程的配置提供了详细的 wiki 信息,如报警配置参考方案、项目压测参考方案、报警问题排查参考方案等等。
当前架构设计
下图是当前项目重构的 SSR 通用解决方案的架构设计,如图:
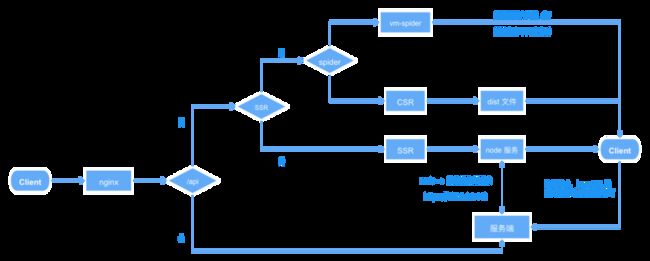
SSR 项目结构下,服务端只负责提供接口数据即可,数据的加工与视图的结合均由 node 服务来处理。服务部署时通过配置的环境变量 ssr为 true 或是 false 来决定选用 ssr 服务还是 csr 服务。不过请注意,在选用 csr 服务时,就不需要部署 node 环境了。
当开发 SSR 服务时,我们目前的建议是将服务端项目与前端项目放在同一个部署下。
一方面可以直接通过 node 服务去请求本地环境下的接口数据,也就是将 axios 的 baseURL 设置成 https://127.0.0.1:443,这种 baseURL 的设置方式是我们通过实践得到的最佳方案,我们将在后续性能优化章节中说到。
另一方面,由于当前强跳 https 的配置是在 nginx 的 80 端口中设置的,为了避免每次的接口请求都会多一次转发操作,我们选择在 node 服务端直接请求 443端口。
项目重构都经历了什么?
理论来源于实践,SSR 通用解决方案的架构设计之所以是当前的模样,还要从项目重构过程中的各种细节说起。项目的重构大致经历了以下环节:
公共组件模块化抽离到 solib/m-vue
公共 svg 图标维护到 solib/icons 中,并封装成 vue 图标组件
solib/m-vue 与 nuxt 的结合
项目的各页面功能模块的梳理与重构
性能优化的漫漫旅程
nuxt2-qcdn-plugin 和 CSR 兜底方案
solib/m-vue 结合 nuxt
使用 nuxt 做服务端渲染,包含 window、document 等关键字的组件或者工具方法是不能直接通过 import 引入的,这会导致在编译阶段发生报错。
经过摸索,我们同时对 solib 库做了cjs 的构建处理,然后在特殊的地方进行动态的 require 引用模式。另外 nuxt 对于 lodash 等库的编译也存在一些问题,这些问题的解决方案都已经补充到 so_nuxt 通用脚手架中了。
最初的架构图
下图是项目初始阶段重构个别页面的架构设计图:
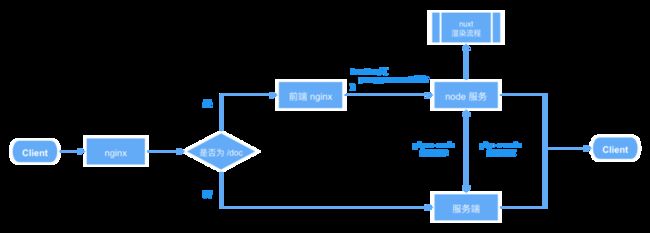
重构最初的想法是将前后端项目进行分离,便于开发时前后端同学只需要关注各自的开发层面即可。服务端同学不需要关心前端 package.json 中的依赖安装,前端同学也不需要关注服务端的初始化流程。另一个也是最重要的原因,前端和服务端可以分开部署,两者的各种部署配置也都可以分离。
而访问的流程就是服务先进入服务端的 nginx,然后判断是当前重构的页面时再代理到前端的 node 服务,接下来就进入我们所说的 ssr 渲染流程。
但是重构结束后,我们进入了漫长的性能优化阶段。
性能优化(一)
最初的版本,压测信息是:平均响应时间 1275.75ms,QPS:38/s,完全不满足上线的条件。
最初的关注焦点是 nuxt 的性能问题,比如 dom 节点过多导致的渲染瓶颈。于是尝试减少服务端渲染 dom 的数量,让那些对爬虫不重要的部分 dom 模块(如信息流板块)在客户端层面渲染,同时将部分插件的引入时机也调整到客户端层面,比如打点用的log.js,其他细节优化暂时忽略。
部署时在同一个机房部署了 6 个 pod,配置是 nginx: 4G_2核,node:6G_4核,压测流程是从平台配置的 lvs作为入口。
经过压测,平均响应时间已经降低到了500ms以下,最佳的并发数是30,最大的 QPS 是 221/s。但是 P99 的毛刺较多且都在 3s 以上,P95 更是大于了 250ms。虽然满足了上线的基础条件,但是小流量上线后,报警频率比较高,考虑到没有完善的兜底方案,暂时做了下线处理,继续寻找优化点。
压测信息如下:

20-40并发,不固定 QPS

30并发,QPS = 120
性能优化(二)
鉴于当时没有找到针对 P99 和 P95 的合适优化点,同时团队同学开发的 vm-spider 工程取得了一定的成果。我们尝试了 CSR 渲染模式,通过在 nginx 中判断 UA 信息,使得用户访问是 CSR 模式,爬虫则通过 vm-spider 走代理模式。同时添加了骨架屏代替白屏做体验优化以及别的工作点。
同样的部署配置:6 个 pod、nginx: 4G_2核,node:6G_4核,压测流程是从平台配置的 lvs作为入口。
CSR 渲染模式在响应时间和 QPS 上肯定是没有问题的。但是通过压测响应曲线发现,P99 和 P95 还是会出现个别延迟较高的毛刺。另外,接口本身有内网限制,同时还要接入内容保护策略,这都需要服务端同学配合处理,导致开发成本的增加。
压测信息如下:

25-50并发,不固定 QPS
性能优化小结
经过上述两轮的优化,我们发现 P99 和 P95 的毛刺延迟较高的情况一直存在,这是上线后经常报警的原因,更是一直需要做性能优化的元凶。经过多方的沟通排查,发现压测的 LVS 地址在配置时被直接指向了云平台的 VIP 节点,这使得服务的中间又多了一层负载均衡。如下:
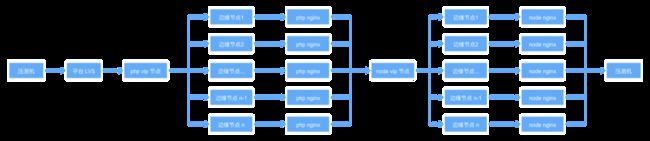
错误的配置
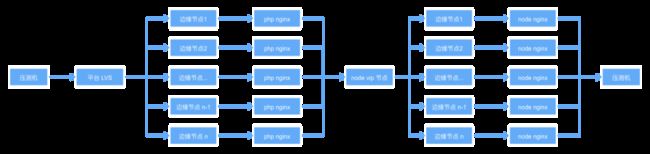
正确的配置
为了确定后续性能优化的着力点确实是在 node 服务之前,我们专门压测了前端部署的 VIP 节点地址进行了验证。
部署配置:6 个 pod、nginx: 2G_2核、node:4G_2核

不固定 QPS, 20-50并发
可以看到,在50并发之前,P99与 P95均在500ms 波动,最大 QPS 不到 300,并没有出现毛刺较高的情况。所以,可以肯定毛刺的频繁出现且延迟较高的原因在 node 服务之外。
性能优化(三)
经过上述的排查与结论可知,目前的性能瓶颈并不是 SSR 渲染模式的问题。而 CSR 模式针对爬虫的处理也主要依赖于 vm-spider工程这种外力,从项目的稳定性与耦合性来看是不合适的。
所以,我们决定重新回归 SSR 渲染模式。
在前期的压测过程中,我们发现前端部署服务的 cpu 和 内存 的使用率都比较低,我们又尝试了三种方案:
pm2 模式,在一个 pod 中开启多个实例,增加单 pod 的内存和 cpu 使用率
降低单 pod 的 cpu 与内存配置,减少单 pod成本,同时增加 pod 数
前端接入缓存(redis ,lru-cache)
pm2模式
1. 压测信息对比
部署配置:6 个 pod、nginx: 2G_2核、node:4G_2核,直接压测前端的 VIP 节点地址。
pm2模式下,分别实验了在一个 pod 中开启最多实例数、2个实例数、以及一半实例数的方案,进行了压测对比。
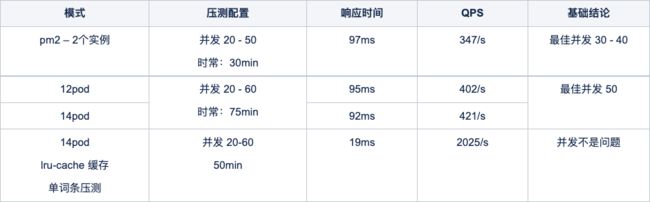
发现每个 pod 开启 2 个实例数,性能是最佳的。对比信息如下:
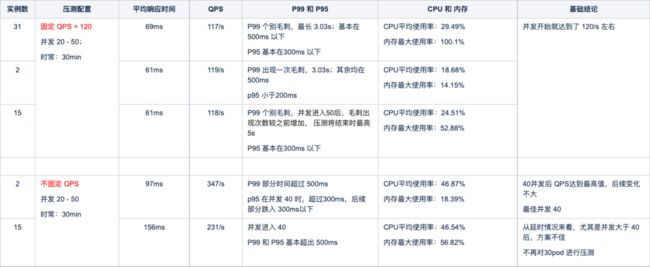
pm2 压测对比
2. pm2 接入的问题
问题1:pm2 在 docker环境和非docker环境下的启动命令执行的结果如下:

pm2 与 pm2-runtime的区别:
pm2-runtime是为 Docker 容器而设计的,它将应用程序保持在前台,从而使容器保持运行
pm2专为在后台发送或运行应用程序的正常使用而设计
docker 容器的生命周期就是 CMD 或 entrypoint 的生命周期。在这种情况下,使用 pm2 start 容器将在运行过程后立即死亡,导致无法访问,所以我们需要采用 docker-runtime start 的方式来启动。
问题2:然而在 nuxt.js 的源码中,启动脚本 nuxt start 会将启动时传入的配置文件(假如叫 ecosystem.config.js )当成项目的目录进行嵌套,导致找不到最终构建的应用文件而出现报错。
报错信息如下:

pm2 启动下 nuxt 报错信息
解决方案:将 nuxt 的源码中 @nuxt/config/dist/config.js 中的 loadNuxtConfig 下的 rootDir 赋值成 process.cwd(),也就是取当前项目的根目录即可。
问题3:在容器启动时,原来版本的云平台没有对环境变量进行隔离,导致所有的环境变量都可以被取到。环境变量过多会导致 pm2 的启动失败。
解决方案: 通过启动服务时,执行脚本遍历并删除不相关的环境变量解决了该问题。
从上述情况来看,pm2 的接入方案本身就存在很大的问题。
调整pod数模式
部署配置:
- 6个pod
- 单pod nginx: 1G_1核、node:1G_1.5核
- 不固定 QPS,并发 20 -- 60
- 压测流程是从平台配置的 lvs作为入口
该模式下分别压测了 12、14、20个 pod 数。随着 pod 数的增加,并发、响应时间和 QPS 都会在一定程度上增加。14个 pod明显比12pod 性能要好,但增加到 20pod 后,与14pod 相比,性能并没有达到预期。
所以,选择了14pod 为最优解。对比信息如下:
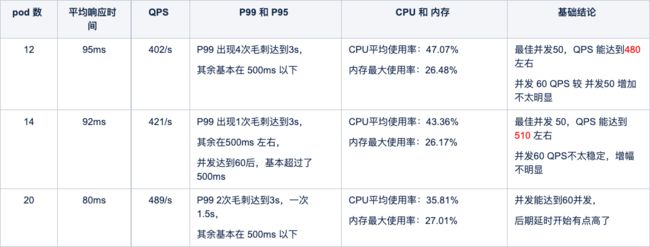
不同 pod 数压测对比
多方案对比
缓存方案,我们仅尝试了 lru-cache 方案的可行性,使用了总内存(1G)的 1/8,大约能存储 1000多条信息。
采用不固定 QPS 的压测方式,同时对三种方案进行了压测对比。对比信息如下:
多方案对比
从开发角度上,pm2的接入、维护以及监控都会增加开发成本,同时流程也会变得很复杂,而动态调整 pod 数不存在这些问题。
从性能角度上,14pod 在响应时间、qps 以及并发上都优于 pm2。
所以,动态调整 pod数可以作为最优解决方案。考虑到 lru-cache 缓存的数据在多 pod 间是不共享的,为了避免线上出现内存溢出等问题,上线的方案中没有采用该缓存方案。
上线后的新问题
经过多轮性能优化的 SSR 渲染模式上线后,延迟过高的情况基本消失了。但 P99 报警仍过于频繁,几乎每两天都会有一轮报警,每几天就会出现个别前端 pod 重启的情况。
对于单 pod 重启的因素大概有以下几点:
外部因素。首先,同一个服务下的多个 pod 部署时会随机落在各个机房上。当机房出现问题时,会自动重启当前机器上的全部 pod。
服务自身因素。当延迟过高积压的任务足够多时,如果 cpu 和 内存的使用率出现了暴增的情况就会导致 pod 的重启;另外,如果服务端或 node 服务的探针一直没有响应时,会导致相关的容器重启,重复如此也会导致整个 pod 的重启。
单 pod 自愈方案。它通过配置延迟时间的最大临界点,在服务的响应效率已经不达标时立刻做出重启的回调处理,解决人力反应不及时的突发情况。该方案是后期做通用解决方案时为了保证服务稳定性才添加的。
根据上述因素并结合 Prometheus 平台中 nginx 状态码 499 出现频率较高的情况,考虑是第二个因素的问题。
分析多天的日志信息后,我们发现重启的 pod 中 axios 请求超时的量确实很多,而且前端 nginx 日志中部分请求超时的日志信息在服务端 nginx 日志中却找不到对应的记录,请求信息丢失了。
经过排查发现是服务的边缘节点之间会有丢包的情况。
而且,当前的服务链路也很长,如 nginx 多层转发,域名解析等等。所以,最终决定将前后端项目放在一起。首页渲染时,每个 pod 中的 node 服务去请求对应 pod 中的服务端即可,于是就有了文章中最初的架构设计模式。
最终的结论
部署配置:nginx 2G_2核、php 4G_2核、node 4G_2核
不同 pod 数的压测结果如下:
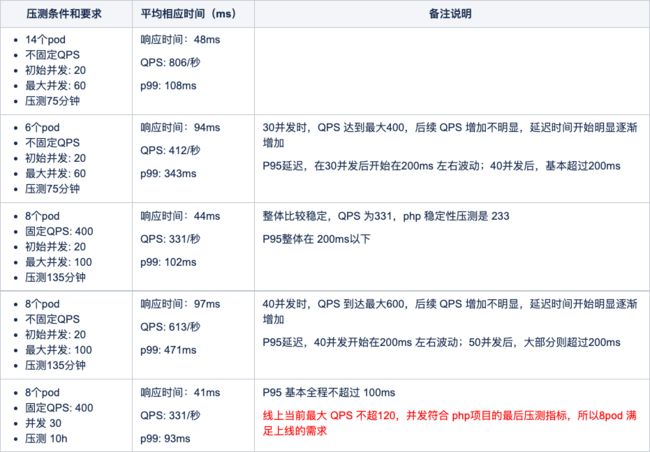
不同 pod 数压测记录

对标当前线上情况的稳定性压测
依据团队内部定制的前端项目代码质量衡量标准对重构前后的版本做了性能方面的数据对比,两个版本整体的性能质量几乎持平:
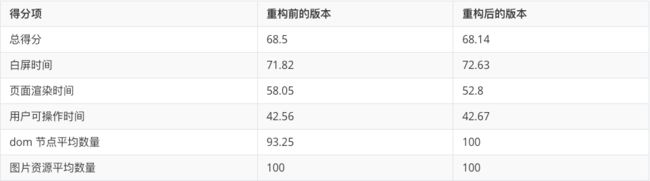
总结
对于知识产品类的服务网站来说,SEO 对搜索引擎的爬虫抓取工具的重要性以及快速的内容到达时间都是非常重要的指标。而本次的项目重构,不仅验证了 SSR 渲染模式的可行性,更为前端同学在后续工作中拥抱前沿技术的尝试提供了可行性参考方案。