tensor和op是神经网络模型最基本的组件:op是模型的节点,tensor是连接节点的边。
然而,构建一个tensor并不仅仅是构造一个对象那么简单,至少要考虑下面这些问题:
- 要支持节点本地的local tensor,以及分布式的global tensor。
- 要支持eager和lazy执行模式。
- 要支持不同的数据类型,包括float、double、int等。
- 要支持不同设备。
1 创建tensor的方法
从init.py看,有两个方法可以创建tensor对象,一个是Tensor,另一个是tensor。这两种方式最终都会通过PyFunction转发到特定的Functor。
1.1 Tensor类型
Tensor是在tensor.py中引入的,构造函数被绑定为C++的ApiNewTensor,通过RegisterMethods为Tensor注册了一些Python实现的方法(如将get_item/set_item等转发给对应的C++函数),在包初始化时会通过RegisterMethod4Class完成这些方法的注册。
RegisterMethod4Class的调用流程如下:
1.2 tensor函数
tensor是一个函数,其绑定定义在tensor_api.yaml.pybind.cpp中,这是构建阶段自动生成的文件。tensor函数直接绑定到PyFunction。
1.3 手动构建tensor的两种方式
分析Tensor和tensor的PyFunction签名,可以通过如下方式构造local tensor,也就是只能在节点内部使用的tensor。其中只有tensor可以指定dtype参数。
import oneflow as flow
flow.tensor([[1,2,3],[4,5,6]])
flow.tensor([1, 2, 3], dtype=flow.int64)
flow.Tensor([[1,2,3],[4,5,6]])
# error
# flow.Tensor([1, 2, 3], dtype=flow.int64)2 oneflow的tensor类型体系
ApiNewTensor函数返回Tensor类型。这是一个抽象类接口。通过其继承和子类的字段包含关系,可以得到如下的类图:
以上主要是Tensor相关的接口定义。MirroredTensor即节点内的local tensor,ConsistentTensor即一致性视角的、分布式的global tensor。
Tensor使用了Bridge模式,每个Tensor子类内部有一个TensorImpl字段。TensorImpl相关的类图如下: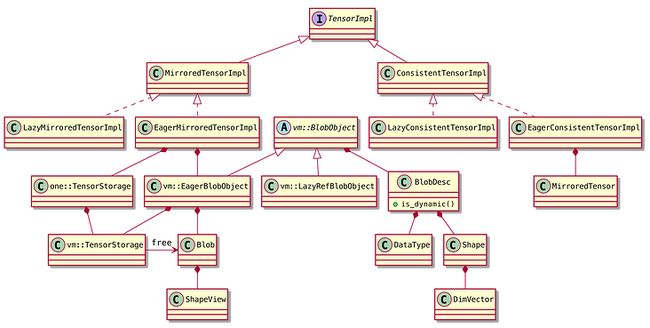
3 local tensor的构造
我们以flow.Tensor([[1,2,3],[4,5,6]])为例,看一下Tensor对象构造的过程。主要的流程如下:
在这个例子中,TensorWithDataCtorFunctor最终会调用MakeLocalTensorFromData,主要的逻辑都在这个函数中。其中大量调用Python和numpy的接口,检查PyObject的数据类型,获取Shape和DataType,如果用户没有制定device,默认会设置为CPU设备。
后面主要是调用EmptyFunctor和SwitchCopyMirroredTensorFromUntypedArray。前者为tensor分配内存,后者进行数据拷贝,两个步骤都会通过虚拟机指令完成。
为什么要通过虚拟机指令完成呢?无论是内存资源的分配,还是数据拷贝,CPU和CUDA等不同设备上的操作都不一样。之前讨论Op/Kernel时已经看到,虚拟机和InstructionType支持不同的设备,所以内存分配和数据拷贝也通过虚拟机执行。
3.1 分配内存:EmptyFunctor
matmul和relu(inplace=false时)等操作在执行过程中也会创建output tensor。之前讨论relu时重点关注了op和kernel的计算逻辑,而忽略了tensor相关的内容。
而这里只需要构造一个tensor对象,不需要其它计算,所以是一个Empty操作,EmptyKernel没有实质性的计算逻辑。
因为是eager模式下的local tensor,EmptyFunctor会进入NaiveInterpret执行。在这里会先构造EagerMirroredTensorImpl和MirroredTensor对象,用于存放tensor结果。但这只是一个壳子,还没有为tensor的数据分配存储空间。
之后会初始化EagerBlobObject、创建TensorStorage,这样tensor主要的字段基本构建完毕。
然后构造指令、提交虚拟机执行。EmptyFunctor是UserOp,最终会进入LocalCallOpKernelUtil: Compute,其中AllocateOutputBlobsMemory完成内存分配任务。
EmptyFunctor的调用流程如下:
AllocateOutputBlobsMemory的调用流程如下。BlobDesc::ByteSizeOfBlobBody提供内存size,即elem_cnt * SizeOf(data_type。CPU环境下,CpuAllocator通过aligned_alloc申请内存资源。
3.2 拷贝数据:SwitchCopyMirroredTensorFromUntypedArray
SwitchCopyMirroredTensorFromUntypedArray其实是MAKE_SWITCH_ENTRY宏展开后的函数名。宏展开后的代码如下。实际会调用CopyMirroredTensorFromUntypedArray。
template
static Maybe SwitchCopyMirroredTensorFromUntypedArray(
const std::tuple& switch_tuple, Args&& ... args) {
static const std::map, std::function(Args && ...)>>
case_handlers {
{SwitchCase(DataType::kFloat),
[](Args&&... args) {
return CopyMirroredTensorFromUntypedArray(std::forward(args)...);
}},
// ...
};
return case_handlers.at(switch_tuple)(std::forward(args)...);
}; 数据拷贝的调用流程如下:
根据上述宏展开后的代码,CopyMirroredTensorFromUntypedArray的模版参数是tensor的dtype,如DataType::kFloat。在tensor构造的场景下,函数CopyBetweenMirroredTensorAndNumpy的模版参数如BlobNumpyCopyUtil
CopyBetweenMirroredTensorAndNumpy中会构造指令提交虚拟机执行。PhysicalRun的逻辑类似如下代码:
vm::InstructionMsgList instruction_list;
InstructionsBuilder instructions_builder(std::make_shared(),
&instruction_list);
// JUST(Build(&instructions_builder));
builder->AccessBlobByCallback(
tensor,
[array_ptr, Copy](uint64_t ofblob_ptr) { CHECK_JUST(Copy(ofblob_ptr, array_ptr)); },
modifier);
JUST(vm::Run(instructions_builder.mut_instruction_list())); lambda表达式中的Copy就是BlobNumpyCopyUtilarray_ptr表示Python端传过来的数组数据指针;后面我们会看到,ofblob_ptr就是tensor的Blob中的指针。
InstructionsBuilder::AccessBlobByCallback中创建AccessBlobArgCbPhyInstrOperand对象,对应的指令类型是AccessBlobByCallbackInstructionType。所以虚拟机执行指令时,会进入AccessBlobByCallbackInstructionType::Compute执行。实际的执行逻辑类似如下代码:
const auto* ptr =
dynamic_cast(phy_instr_operand.get());
OfBlob ofblob(device_ctx->stream(), ptr->eager_blob_object()->mut_blob());
// ptr->callback()(reinterpret_cast(&ofblob));
BlobNumpyCopyUtil::From(&ofblob, array_ptr); ptr->callback()就是上述lambda表达式。OfBlob是对tensor的Blob的封装。一路追踪下去,CPU环境下最终会调用std::memcpy拷贝数据。