Word2Vec学习(自用)
一. 引言 
本文仅作简要概述,萌新可扫盲用。不涉及算法推导过程,具体算法推导过程请关注参考文献2。笔者也会将自己的学习推导过程附在文章后,有兴趣者可以留言交流,共同学习。
二. 参考资料总结
1. Mikolov原论文(两篇):
《Efficient Estimation Of Word Representations In Vector Space》
贡献:
《Distributed Representations Of Sentences And Documents》
贡献:
2. Xin Rong的论文:
《Word2Vec Parameter Learning Explained》
(重点推荐!理论完备;易懂;直击要害;)
【R.I.P,Rong Xin于2017年驾驶飞机失事,缅怀;感谢为科研奉献了如此优秀的论文】
3. [NLP] 秒懂词向量Word2vec的本质 - 穆文的文章 - 知乎 https://zhuanlan.zhihu.com/p/26306795(本文主要借鉴、学习路线;感觉写的有很多勘误,作者学习后予以改进)
三. 正文
3.1 什么是Word2Vec?
NLP中最细粒度的是词语,词语组成句子,句子再组成段落、篇章、文档。所以处理NLP的问题,首先就要拿词语开刀。由于机器本质上处理的是数值型数据,所以想利用机器学习处理文本首先就是要将符号形式的文本,转换成数值形式,或者说是嵌入到一个数学空间中,即词嵌入(word embedding),而 Word2Vec 即是其中一种方法。
大部分的有监督机器学习模型都可以归结为:![]()
在NLP中,把 x 视为一个句子中的一个词语,y 是这个词语的上下文词语,则 f 便是 NLP 中经常出现的语言模型(language model)。这个模型的目的就是判断(x, y)是不是符合符合自然语言规则,或者直白些说:“是不是人话?”。
值得注意的是:将文本映射到数学空间中,以向量的形式可以保留其语义。很著名的例子当属: 'King' - 'Man' + 'Woman' = 'Queen' 旨在用向量的运算推导出语义。
笔者认为;Word2Vec 正是来源于这两个思想。
3.2 Skip-gram 和 CBOW 模型
- 将一个词语作为输入,来预测它的上下文; 即 “ Skip-Gram 模型”
- 将某个词语的上下文作为输入,来预测这个词语; 即 ” CBOW (Continuous Bag-of-Word) 模型“
3.2.1 Skip-gram 和 CBOW 的简单形式(Bigram)
首先撇开Word2Vec,前文提到,机器只能处理数值型数据,那词语 x 的原始输入形式应该如何定义呢?这里就要引入 one-hot encoding(独热编码),本质上即用一个仅含一个 1、其他均为 0 的向量作为唯一标识编码。
接下来,我们来看一下 Skip-gram (简单形式,仅预测下一个词)的网络结构:

其中,V 代表了总共有多少个词语(即词汇表数量),x 为词语的 one-hot encoding 形式,y 代表在这 V 个词上输出的概率,我们希望输出的 y 与真实值 y_hat 相同。
首先需要说明的是隐藏层左侧,由于是one-hot encoding形式,对于第 j 个词,只会用到 W 矩阵中的第 j 行。另外,隐藏层的激活函数(即左侧W)其实是线性的,并不做任何的处理!
(即![]() 并不经过激活函数)
并不经过激活函数)
需要注意的是 N 是自定义的,而且即是隐藏层节点个数。
同理,由于h为N-dim向量,与W‘做矩阵乘法时,每个词仅会用到某一列。隐藏层右侧我们需要使用Sigmoid激活函数得到词向量每个维度的概率,并取maximum为预测词;
训练这个神经网络利用Bp算法,本质上是链式求导,此处不展开说明。
Word2Vec 的精髓实际上即是将 1 x V 的独热编码表示降维成 N 维的词向量形式。(我们称其为Input Vector)其中 V >> N。以及在后将其“转换为” 另一种 N 维的词向量形式。 (W’ 的某一列,我们称其为Output Vector)
即:Input Vector 和 Output Vector 是 词w 的两种不同的表达形式!其向量均为 N-dim。
另外,我们需要注意:
1. 在输入某个词x时,迭代只会更新对应 W 的行,因为其他行的导数均为 0。
2. Rong论文推导中 EH 是 所有词汇输出向量的预测误差权重按比例组成。
3. 每个输入向量的更新迭代取决于词汇表中所有词汇向量,并且预测误差越大,迭代作用效果越大;
4. 可视化显示:输出向量会被拉扯来拉扯去。直观的原因正是向量被其他词汇的单词共同拉扯作用;输入向量同理。
5. 若有效,在多轮迭代后,输入/输出向量的相对位置最终会相对稳定。
3.2.2 Skip-gram 的一般情形

这些模型如何并联、cost function形式,详见参考资料2。
3.2.3 CBOW 的一般情形
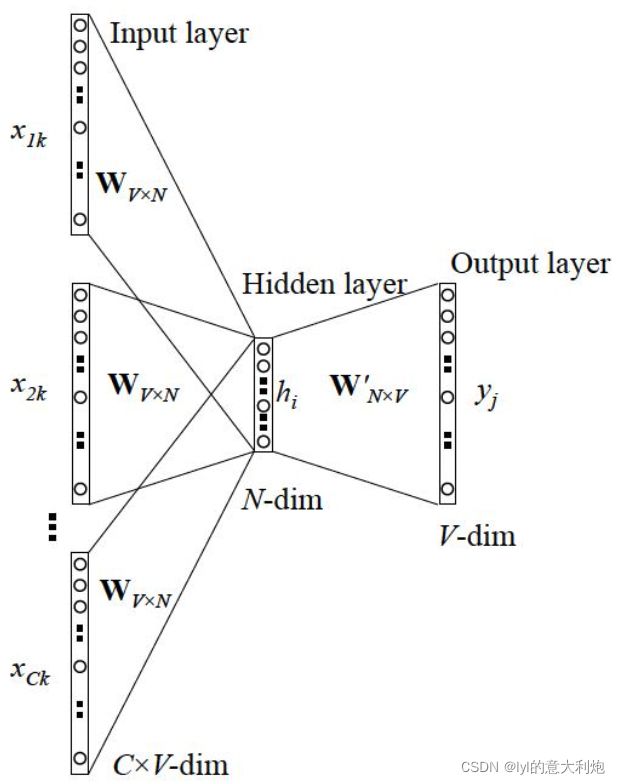
这些模型如何并联、cost function形式,详见参考资料2。
3.3 Word2Vec 的training trick(优化计算效率)
相信很多初次踩坑的同学,会跟我一样陷入 Mikolov 那篇论文(参考资料1.)里提到的 hierarchical softmax 和 negative sampling 里不能自拔,但其实,它们并不是 Word2vec 的精髓,只是它的训练技巧,但也不是它独有的训练技巧。 Hierarchical softmax 只是 softmax 的一种近似形式,而 negative sampling 也是从其他方法借鉴而来。
为什么要用训练技巧呢? 如我们刚提到的,Word2vec 本质上是一个语言模型,它的输出节点数是 V 个,对应了 V 个词语,本质上是一个多分类问题,但实际当中,词语的个数非常非常多,会给计算造成很大困难,所以需要用技巧来加速训练。
在每一个训练实例进行训练的过程中,对于 W‘ 中某一列,我们都需要迭代一次词汇表中的每一个词。在训练大型语料库时,这代价无疑是难以承受的。
hierarchical softmax
- 本质是把 N 分类问题变成 log(N)次二分类
- negative sampling
- 本质是预测总体类别的一个子集
2019年更新:最新的语言模型 Bert 也借鉴了 Word2vec 的 CBOW 模式,请阅读文章:
穆文:[NLP] 从语言模型看Bert的善变与GPT的坚守133 赞同 · 8 评论文章正在上传…重新上传取消