Python中的魔法方法
| 方法名 | 说明 |
|---|---|
| __str__ | 用于返回对象的描述 |
| __iter__ | 使类可以迭代 |
| __getitem__ | 按照下标获取类元素,例如list |
| __getattr__ | 调用类不存在的属性 |
| __call__ | 类实例化默认调用方法 |
看到类似 __slots__这种形如__xxx__的变量或者函数名就要注意,这些在Python中是有特殊用途的。
__slots__我们已经知道怎么用了,__len__方法我们也知道是为了能让class作用于 len() 函数。
这些在Python有另外的一些名称叫魔术方法
除此之外,Python的class中还有许多这斜体样式样有特殊用途的函数,可以帮助我们定制!
1.__str__
用于定制对象的描述信息
我们先定义一个 Student 类,打印一个实例:
>>> class Student(object):
def __init__(self, name):
self.name = name
>>> print(Student('张三'))
<__main__.Student object at 0x000001AC142D3370>
>>>
打印出一堆<__main__.Student object at 0x000001AC142D3370>, 不好看。
怎么才能打印得好看呢?只需要定义好 __str__() 方法,返回一个好看的字符串就可以了:
# -*- coding: utf-8 -*-
class Person(object):
def __init__(self, name):
self.name = name
# 用于定制对象的描述信息
def __str__(self):
return "Person object (name:%s)" % self.name
if __name__ == '__main__':
p = Person('张三')
print(p)

这样打印出来的实例,不但好看,而且容易看出实例内部重要的数据。
2.__iter__
如果一个类想被用于 for ... in 循环,类似list或tuple那样,就必须实现一个 __iter__()方法,该方法返回一个迭代对象,然后,Python的for循环就会不断调用该迭代对象的 __next__() 方法拿到循环的下一个值,直到遇StopIteration 错误时退出循环。
我们以斐波那契数列为例,写一个Fib类,可以作用于for循环:
class Fib(object):
# Fib默认不是可迭代对象,变成一个可迭代对象,必须返回一个迭代器
def __init__(self):
self.a, self.b = 0, 1 # 斐波那契数列前两个固定的值
# 重写 __iter__方法,Fib变为可迭代对象
def __iter__(self):
return self
# 重写__next__方法,Fib就变成一个迭代器
def __next__(self):
self.a, self.b = self.b, self.a + self.b # 计算下一个值
if self.a > 1000:
raise StopIteration
return self.a
if __name__ == '__main__':
print('小于1000的所有斐波那契数:', end=' ')
for i in Fib():
print(i, end=' ')

3.__getitem__
Fib实例虽然能作用于for循环,看起来和list有点像,但是,把它当成list来使用还是不行,比如,取第5个元素:
>>> Fib()[5]
Traceback (most recent call last):
File "", line 1, in
TypeError: 'Fib' object does not support indexing
>>>
要表现得像list那样按照下标取出元素,需要实现 __getitem__() 方法:
# -*- coding: utf-8 -*-
class Fib(object):
# 重写__getitem__,Fib 可以类似于 list
def __getitem__(self, item):
a, b = 1, 1
for x in range(item):
a, b = b, a+b
return a
现在,就可以按下标访问数列的任意一项了
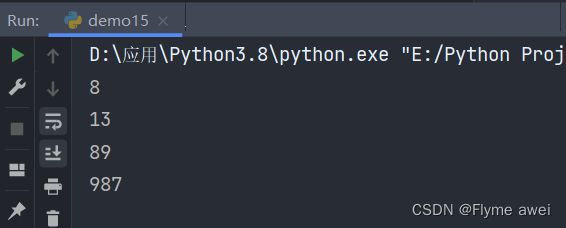
if __name__ == '__main__':
f = Fib()
print(f[5])
print(f[6])
print(f[10])
print(f[15])
输出:
但是list有个神奇的切片方法:
>>> list(range(100)[5:10])
[5, 6, 7, 8, 9]
对于Fib却报错。原因是 __getitem__() 传入的参数可能是一个int,也可能是一个切片对象 slice ,所以要做判断
# -*- coding: utf-8 -*-
class Fib(object):
def __getitem__(self, item): # # item是一个下标, 也有可能是一个切片
if isinstance(item, int): # item 是一个 int 下标
a, b = 1, 1
for _ in range(item): # rage(item) 用作循环次数
a, b = b, a+b
return a
elif isinstance(item, slice): # item 是一个切片(范围)
start = item.start
stop = item.stop
if start is None:
start = 0 # start初始值为 0
a, b = 1, 1
l = []
for _ in range(stop):
l.append(a)
a, b = b, a+b
return l
现在试试Fib的切片:
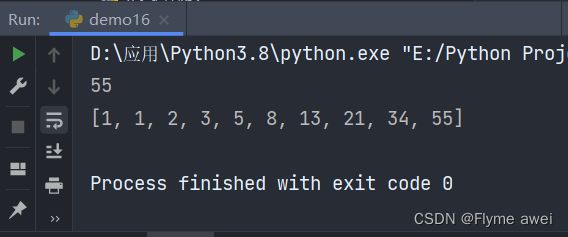
if __name__ == '__main__':
print(Fib()[9])
print(Fib()[1:10])
输出:
但是没有对step参数作处理:
>>> f[:10:2]
[1, 1, 2, 3, 5, 8, 13, 21, 34, 55, 89]
也没有对负数作处理,所以,要正确实现一个 __getitem__() 还是有很多工作要做的。
此外,如果把对象看成 dict , __getitem__() 的参数也可能是一个可以作key的object,例如 str 。
与之对应的是 __setitem__() 方法,把对象视作list或dict来对集合赋值。最后,还有一个 __delitem__() 方法,用于删除某个元素。
总之,通过上面的方法,我们自己定义的类表现得和Python自带的list、tuple、dict没什么区别,这完全归功于动态语言的“鸭子类型”,不需要强制继承某个接口。
4.__getattr__
正常情况下,当我们调用类的方法或属性时,如果不存在,就会报错。比如定义 Student 类:
class Student(object):
def __init__(self):
self.name = 'Michale'
调用 name 属性,没问题,但是,调用不存在的 score 属性,就有问题了:
>>> s = Student()
>>> print(s.name)
Michael
>>> print(s.score)
>Traceback (most recent call last):
...
AttributeError: 'Student' object has no attribute 'score'
错误信息很清楚地告诉我们,没有找到 score 这个attribute。
要避免这个错误,除了可以加上一个 score 属性外,Python还有另一个机制,那就是写一个 __getattr__() 方法,动态返回一个属性。修改如下:
class Student(object):
def __init__(self):
self.name = 'Michale'
def __getattr__(self, item):
if item == 'score':
return 99
当调用不存在的属性时,比如 score ,Python解释器会试图调用 __getattr__(self, 'score') 来尝试获得属性,这样,我们就有机会返回 score 的值:
>>> s = Student()
>>> s.name
'Michael'
>>> s.score
99
>>>
返回函数也是完全可以的:
class Student(object): def __getattr__(self, start): if attr == 'age': return lambda : 25
只是调用方法变为:
>>> s,age()
25
注意,只有在没有找到属性的情况下,才调用 __getattr__ ,已有的属性,比如 name ,不会在 __getattr__中查找。
此外,注意到任意调用如 s.abc 都会返回 None ,这是因为我们定义的 __getattr__ 默认返回就是 None 。要让class只响应特定的几个属性,我们就要按照约定,抛出 AttributeError 的错误:
class Student(object):
def __getattr__(self, attr):
if attr == 'age':
return lambda: 25
raise AttributeError('\'Student\' object has no attribute \'%s\'' % attr)
这实际上可以把一个类的所有属性和方法调用全部动态化处理了,不需要任何特殊手段。
这种完全动态调用的特性有什么实际作用呢?作用就是,可以针对完全动态的情况作调用。
5.__call__
一个对象实例可以有自己的属性和方法,当我们调用实例方法时,我们用instance.method() 来调用。
能不能直接在实例本身上调用呢?在Python中,答案是肯定的。
任何类,只需要定义一个 __call__() 方法,就可以直接对实例进行调用。请看示例:
class Student(object):
def __init__(self, name):
self.name = name
def __call__(self, *args, **kwargs):
print('My name is %s.' % self.name)
调用方式如下:
>>> s = Student('awei')
>>> s() # self参数不要传入
My name is awei.
__call__() 还可以定义参数。对实例进行直接调用就好比对一个函数进行调用一样,所以你完全可以把对象看成函数,把函数看成对象,因为这两者之间本来就没啥根本的区别。
如果你把对象看成函数,那么函数本身其实也可以在运行期动态创建出来,因为类的实例都是运行期创建出来的,这么一来,我们就模糊了对象和函数的界限。
那么,怎么判断一个变量是对象还是函数呢?其实,更多的时候,我们需要判断一个对象是否能被调用,能被调用的对象就是一个 Callable 对象,比如函数和我们上面定义的带有 __call__() 的类实例:
>>> callable(Student())
True
>>> callable(max)
True
>>> callable([1, 2, 3])
False
>>> callable(None)
False
>>> callable('str')
False
通过 callable() 函数,我们就可以判断一个对象是否是“可调用”对象。
到此这篇关于Python定制类你不知道的魔术方法的文章就介绍到这了,更多相关Python定制类内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!