「docker实战篇」python的docker-抖音web端数据抓取(19)
原创文章,欢迎转载。转载请注明:转载自IT人故事会,谢谢!
原文链接地址:「docker实战篇」python的docker-抖音web端数据抓取(19)抖音抓取实战,为什么没有抓取数据?例如:有个互联网的电商生鲜公司,这个公司老板想在一些流量上投放广告,通过增加公司产品曝光率的方式,进行营销,在投放的选择上他发现了抖音,抖音拥有很大的数据流量,尝试的想在抖音上投放广告,看看是否利润和效果有收益。他们分析抖音的数据,分析抖音的用户画像,判断用户的群体和公司的匹配度,需要抖音的粉丝数,点赞数,关注数,昵称。通过用户喜好将公司的产品融入到视频中,更好的推广公司的产品。一些公关公司通过这些数据可以找到网红黑马,进行营销包装。源码:https://github.com/limingios/dockerpython.git (douyin)

抖音分享页面
- 介绍
https://www.douyin.com/share/user/用户ID,用户ID通过源码中的txt中获取,然后通过链接的方式就可以打开对应的web端页面。然后通过web端页面。爬取基本的信息。

- 安装谷歌xpath helper工具
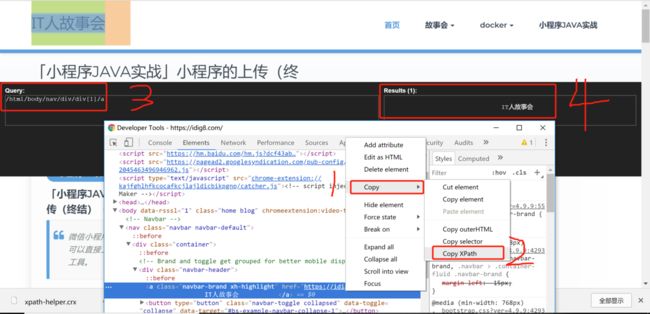
源码中获取crx

谷歌浏览器输入:chrome://extensions/

直接将xpath-helper.crx 拖入界面chrome://extensions/
安装成功后

快捷键 ctrl+shift+x 启动xpath,一般都是谷歌的f12 开发者工具配合使用。
开始python 爬取抖音分享的网站数据
分析分享页面https://www.douyin.com/share/user/76055758243
1.抖音做了反派机制,抖音ID中的数字变成了字符串,进行替换。
{'name':[' ',' ',' '],'value':0},
{'name':[' ',' ',' '],'value':1},
{'name':[' ',' ',' '],'value':2},
{'name':[' ',' ',' '],'value':3},
{'name':[' ',' ',' '],'value':4},
{'name':[' ',' ',' '],'value':5},
{'name':[' ',' ',' '],'value':6},
{'name':[' ',' ',' '],'value':7},
{'name':[' ',' ',' '],'value':8},
{'name':[' ',' ',' '],'value':9},
2.获取需要的节点的的xpath
# 昵称
//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()
#抖音ID
//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()
#工作
//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()
#描述
//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()
#地址
//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text()
#星座
//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text()
#关注数
//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()
#粉丝数
//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()
#赞数
//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()

- 完整代码
import re import requests import time from lxml import etree
def handle_decode(input_data,share_web_url,task):
search_douyin_str = re.compile(r'抖音ID:')
regex_list = [
{'name':[' ',' ',' '],'value':0},
{'name':[' ',' ',' '],'value':1},
{'name':[' ',' ',' '],'value':2},
{'name':[' ',' ',' '],'value':3},
{'name':[' ',' ',' '],'value':4},
{'name':[' ',' ',' '],'value':5},
{'name':[' ',' ',' '],'value':6},
{'name':[' ',' ',' '],'value':7},
{'name':[' ',' ',' '],'value':8},
{'name':[' ',' ',' '],'value':9},
]
for i1 in regex_list:
for i2 in i1['name']:
input_data = re.sub(i2,str(i1['value']),input_data)
share_web_html = etree.HTML(input_data)
douyin_info = {}
douyin_info['nick_name'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]
douyin_id = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/i/text()"))
douyin_info['douyin_id'] = re.sub(search_douyin_str,'',share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]).strip() + douyin_id
try:
douyin_info['job'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()")[0].strip()
except:
pass
douyin_info['describe'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()")[0].replace('\n',',')
douyin_info['location'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text()")[0]
douyin_info['xingzuo'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text()")[0]
douyin_info['follow_count'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()")[0].strip()
fans_value = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str((int(fans_value)/10))+'w'
like = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(int(like)/10)+'w'
douyin_info['from_url'] = share_web_url
print(douyin_info)def handle_douyin_web_share(share_id):
share_web_url = 'https://www.douyin.com/share/user/'+share_id
print(share_web_url)
share_web_header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
share_web_response = requests.get(url=share_web_url,headers=share_web_header)
handle_decode(share_web_response.text,share_web_url,share_id)
if name == 'main':
while True:
share_id = "76055758243"
if share_id == None:
print('当前处理task为:%s'%share_id)
break
else:
print('当前处理task为:%s'%share_id)
handle_douyin_web_share(share_id)
time.sleep(2)

#### mongodb
>通过vagrant 生成虚拟机创建mongodb,具体查看
「docker实战篇」python的docker爬虫技术-python脚本app抓取(13)
``` bash
su -
#密码:vagrant
docker
>https://hub.docker.com/r/bitnami/mongodb
>默认端口:27017
``` bash
docker pull bitnami/mongodb:latest
mkdir bitnami
cd bitnami
mkdir mongodb
docker run -d -v /path/to/mongodb-persistence:/root/bitnami -p 27017:27017 bitnami/mongodb:latest
#关闭防火墙
systemctl stop firewalld

- 操作mongodb
读txt文件获取userId的编号。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/1/30 19:35
# @Author : Aries
# @Site :
# @File : handle_mongo.py.py
# @Software: PyCharm
import pymongo
from pymongo.collection import Collection
client = pymongo.MongoClient(host='192.168.66.100',port=27017)
db = client['douyin']
def handle_init_task():
task_id_collections = Collection(db, 'task_id')
with open('douyin_hot_id.txt','r') as f:
f_read = f.readlines()
for i in f_read:
task_info = {}
task_info['share_id'] = i.replace('\n','')
task_id_collections.insert(task_info)
def handle_get_task():
task_id_collections = Collection(db, 'task_id')
# return task_id_collections.find_one({})
return task_id_collections.find_one_and_delete({})
#handle_init_task()
- 修改python程序调用
import re import requests import time from lxml import etree from handle_mongo import handle_get_task from handle_mongo import handle_insert_douyin
def handle_decode(input_data,share_web_url,task):
search_douyin_str = re.compile(r'抖音ID:')
regex_list = [
{'name':[' ',' ',' '],'value':0},
{'name':[' ',' ',' '],'value':1},
{'name':[' ',' ',' '],'value':2},
{'name':[' ',' ',' '],'value':3},
{'name':[' ',' ',' '],'value':4},
{'name':[' ',' ',' '],'value':5},
{'name':[' ',' ',' '],'value':6},
{'name':[' ',' ',' '],'value':7},
{'name':[' ',' ',' '],'value':8},
{'name':[' ',' ',' '],'value':9},
]
for i1 in regex_list:
for i2 in i1['name']:
input_data = re.sub(i2,str(i1['value']),input_data)
share_web_html = etree.HTML(input_data)
douyin_info = {}
douyin_info['nick_name'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]
douyin_id = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']/p[@class='shortid']/i/text()"))
douyin_info['douyin_id'] = re.sub(search_douyin_str,'',share_web_html.xpath("//div[@class='personal-card']/div[@class='info1']//p[@class='nickname']/text()")[0]).strip() + douyin_id
try:
douyin_info['job'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/div[@class='verify-info']/span[@class='info']/text()")[0].strip()
except:
pass
douyin_info['describe'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='signature']/text()")[0].replace('\n',',')
douyin_info['location'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[1]/text()")[0]
douyin_info['xingzuo'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='extra-info']/span[2]/text()")[0]
douyin_info['follow_count'] = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='focus block']//i[@class='icon iconfont follow-num']/text()")[0].strip()
fans_value = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='follower block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['fans'] = str((int(fans_value)/10))+'w'
like = ''.join(share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']//i[@class='icon iconfont follow-num']/text()"))
unit = share_web_html.xpath("//div[@class='personal-card']/div[@class='info2']/p[@class='follow-info']//span[@class='liked-num block']/span[@class='num']/text()")
if unit[-1].strip() == 'w':
douyin_info['like'] = str(int(like)/10)+'w'
douyin_info['from_url'] = share_web_url
print(douyin_info)
handle_insert_douyin(douyin_info)def handle_douyin_web_share(task):
share_web_url = 'https://www.douyin.com/share/user/'+task["share_id"]
print(share_web_url)
share_web_header = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36'
}
share_web_response = requests.get(url=share_web_url,headers=share_web_header)
handle_decode(share_web_response.text,share_web_url,task["share_id"])
if name == 'main':
while True:
task=handle_get_task()
handle_douyin_web_share(task)
time.sleep(2)
* mongodb字段
>handle_init_task 是将txt存入mongodb中
>handle_get_task 查出来一条然后删除一条,因为txt是存在的,所以删除根本没有关系
``` python
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/1/30 19:35
# @Author : Aries
# @Site :
# @File : handle_mongo.py.py
# @Software: PyCharm
import pymongo
from pymongo.collection import Collection
client = pymongo.MongoClient(host='192.168.66.100',port=27017)
db = client['douyin']
def handle_init_task():
task_id_collections = Collection(db, 'task_id')
with open('douyin_hot_id.txt','r') as f:
f_read = f.readlines()
for i in f_read:
task_info = {}
task_info['share_id'] = i.replace('\n','')
task_id_collections.insert(task_info)
def handle_insert_douyin(douyin_info):
task_id_collections = Collection(db, 'douyin_info')
task_id_collections.insert(douyin_info)
def handle_get_task():
task_id_collections = Collection(db, 'task_id')
# return task_id_collections.find_one({})
return task_id_collections.find_one_and_delete({})
handle_init_task()


PS:text文本中的数据1000条根本不够爬太少了,实际上是app端和pc端配合来进行爬取的,pc端负责初始化的数据,通过userID获取到粉丝列表然后在不停的循环来进行爬取,这样是不是就可以获取到很大量的数据。
转载于:https://blog.51cto.com/12040702/2402066