Redis基础知识
redis
1. redis的概念

redis由C语言开发的, 基于内存的数据库, 数据的存储方式是以KEY-VALUE的形式存储, redis中也是有丰富的数据类型的
2. redis的特点
-
- redis将数据存储到了内存当中, 所以读写的效率非常的高: 读 : 11w/s 写: 8w/s
-
- redis中也是有丰富的数据类型: 五种 string , hash, list, set ,sortedSet
注意: redis的数据类型指的是key-value的value的数据类型,而key只有string
-
- redis可以很方便的将数据移植到另一台装有redis的服务器中
-
- redis中所有的操作都是原子性的, 保证数据的完整性
3. redis的数据类型特点和使用范围
-
string: 字符串
- 特点: 和 java中 String 是类似的, 指代的是字符串
- 使用范围: 做缓存
-
hash :
-
特点: 和 java中 hashMap是类似的, 可以很方便的保存对象
-
使用范围: 做缓存(这种数据类型使用较少,可以被string所替代)
-
-
list :
- 特点: 和 java 中 linkedList是类似的, 看做是一个队列(FIFO)
- 使用范围: 做任务队列
-
set:
- 特点: 和 java中 set集合类似的, 无序 不重复
- 使用范围: 去重业务
-
sortedSet
- 特点: 和 java 中 sortedSet集合类似的 有序的, 不重复的’
- 使用范围: 做排序(排行榜)
4. redis的安装
建议大家将其安装到一台没有mysql的虚拟机当中, 如果三台都安装了mysql, 随意的找一台安装redis即可
4.1 安装目录的准备:
安装目录: /export/servers
软件存放的目录: /export/software
日志文件的目录: /export/logs
数据存放的目录: /export/data
创建以上目录:
mkdir -p /export/servers
mkdir -p /export/software
mkdir -p /export/logs
mkdir -p /export/data
###4.2 下载redis安装包
cd /export/software/
wget http://download.redis.io/releases/redis-4.0.2.tar.gz
tar -zxvf redis-4.0.2.tar.gz -C ../servers
cd /export/servers/
mv redis-4.0.2 redis-src
4.3 安装编译环境
由于下载下来的只是redis的源码包, 需要对其进行编译执行, 故需要安装C语言环境
yum -y install gcc gcc-c++ libstdc++-devel tcl -y
###4.4 编译并进行安装redis
cd /export/servers/redis-src/
make MALLOC=libc
make PREFIX=/export/servers/redis install
###4.5 准备redis的启动的相关配置文件
在指定的位置创建一个redis的配置文件
mkdir -p /export/servers/redis/conf
cd /export/servers/redis/conf
vi redis_6379.conf
配置文件内容
bind 192.168.75.101
protected-mode yes
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 300
daemonize yes
supervised no
pidfile /export/data/redis/6379/redis_6379.pid
loglevel notice
logfile "/export/data/redis/6379/log.log"
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump.rdb
dir /export/data/redis/6379/
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble no
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
4.6 启动redis的服务
mkdir -p /export/data/redis/6379/
cd /export/servers/redis/bin/
./redis-server ../conf/redis_6379.conf
在Redis的bin目录下,执行如下命令启动Redis服务
./redis-server ../conf/redis_6379.conf
在Redis的bin目录下启动客户端
./redis-cli -h 192.168.72.144
5. redis的客户端工具: jedis
jedis其实就是一款java连接redis的客户端工具, 可以使用jedis方便和redis建立连接, 完成相关的curd, jedis中最大的特点就是jedis的API 和 redis的命令的名称是一致的
- 基本的入门代码
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
// jedis的入门程序
@Test
public void test01(){
//1. 创建jedis对象 : jedis 看做是 JDBC当中的connection
// 注意: 不要使用空参构造, 因为空参构造默认连接的本地的redis
Jedis jedis = new Jedis("192.168.72.142",6379);
//2. 执行操作:
String pong = jedis.ping();
System.out.println(pong);
//3. 释放
jedis.close();
}
- 在进行连接的时候, 一定要将linux的防火墙关闭了(开放端口号)

5.1 使用jedis操作redis_string
//1. 使用jedis操作redis_ string
@Test
public void test02() throws InterruptedException {
//1. 创建jedis对象
Jedis jedis = new Jedis("192.168.72.142",6379);
//2. 执行相关的操作
//2.1 添加数据
jedis.set("name","夯哥");
//2.2 读取数据:
String name = jedis.get("name");
System.out.println(name);
//2.3 想让 age +1 操作
Long age = jedis.incr("age");
System.out.println(age);
//2.4 想让 age -1 操作
age = jedis.decr("age");
System.out.println(age);
//2.5 为key设置有效时间: 想让key只在redis中存活5秒钟
jedis.setex("birthday",5,"2000.12.12");
while(jedis.exists("birthday")){
Thread.sleep(1000);
// 返回值: -1: 当前key是一个永久有效的key -2:当前key已经不存在
Long time = jedis.ttl("birthday");
System.out.println(time);
}
//2.6 删除值:
jedis.del("age");
//3. 释放资源
jedis.close();
}
5.2 使用jedis操作redis_list
//2. 使用jedis操作redis_list
// 看做是一个队列(FIFO)
@Test
public void test03() throws Exception {
//1. 创建jedis对象
Jedis jedis = new Jedis("192.168.72.142",6379);
//初始化数据
jedis.del("list1");
//2. 执行相关的操作
//建议: 从左侧添加, 从右侧取元素, 或者从右侧添加, 从左侧取元素
//2.1 从左侧添加元素, 从右侧将元素取出
jedis.lpush("list1","A","B","C","D","E");
String rpop = jedis.rpop("list1");
System.out.println(rpop);
// rpush lpop
//2.2 查看当前元素中所的数据: 变量list集合
List<String> list = jedis.lrange("list1", 0, -1);
System.out.println(list);// []
//2.3 获取集合的个数
Long size = jedis.llen("list1");
System.out.println(size);
//2.4 : 需求 想在 C元素之前添加一个数值为0的元素
// 参数1: key
// 参数2 : 添加到哪里去: before after
// 参数3 : 在谁的前面或者后面
// 参数4: 添加的元素内容
jedis.linsert("list1", BinaryClient.LIST_POSITION.BEFORE,"C","0");
list = jedis.lrange("list1", 0, -1);
System.out.println(list);// []
//3. 释放资源
jedis.close();
}
5.3 使用jedis操作redis_set
//3. 使用jedis操作redis_set
// 无序, 没有重复值
@Test
public void test04() throws Exception {
//1. 创建jedis对象
Jedis jedis = new Jedis("192.168.72.142", 6379);
//2. 执行相关的操作
//2.1 添加元素:
jedis.sadd("set1","A","B","C","D","C","B");
//2.2 获取所有数据:
Set<String> set = jedis.smembers("set1");
System.out.println(set);
//2.3 判断某个元素是否在set集合中存在
Boolean flag = jedis.sismember("set1", "E");
System.out.println(flag);
//2.4 获取set集合的数量
Long size = jedis.scard("set1");
System.out.println(size);
//2.5 删除set集合中指定的元素: B
jedis.srem("set1","B");
//3. 释放资源
jedis.close();
}
5.4 jedis的连接池
- 基本入门代码
//4. jedis的连接池
@Test
public void jedisPoolTest01(){
//1. 创建 jedis的连接池对象:
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100); //最大连接数
config.setMaxIdle(50); //最大的闲时的数量
config.setMinIdle(20);//最小的闲时的数量
JedisPool jedisPool = new JedisPool(config,"192.168.72.142",6379);
//2. 从连接池取出连接对象
Jedis jedis = jedisPool.getResource();
//3. 测试
System.out.println(jedis.ping());
//4. 释放资源 : 归还连接 jedis连接池不会主动的归还连接, 必须通过手动归还
jedis.close();
}
- 抽取一个工具类
package com.itheima.jedis.utils;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
public class JedisUtils {
private static JedisPool jedisPool;
static {
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(100); //最大连接数
config.setMaxIdle(50); //最大的闲时的数量
config.setMinIdle(20);//最小的闲时的数量
jedisPool = new JedisPool(config,"192.168.72.142",6379);
}
//返回连接
public static Jedis getJedis() {
return jedisPool.getResource();
}
public static void closeJedis(Jedis jedis){
jedisPool.returnResourceObject(jedis)
}
}
6. redis基本命令(常用)
6.0 常规命令
对key设置失效时间:expire
查看剩余秒数:ttl
取消过期时间的设定:persist
切换库:select 库
key迁移库:move key 库
重命名key:rename oldkey newkey
查看key对应的类型:type key
清空库:flushdb <-----> flushall是把所有库都清空
6.1 String类型
- 赋值: set key value
- 设定key持有指定的字符串value,如果该key存在则进行覆盖操作。总是返回”OK”
- 取值: get key
- 获取key的value。如果与该key关联的value不是String类型,redis将返回错误信息,因为get命令只能用于获取String value;如果该key不存在,返回(nil)
- 删除: del key
- 删除指定的key
- 数值增减:
- 增减值: incr key
- 将指定的key的value原子性的递增1.如果该key不存在,其初始值为0,在incr之后其值为1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息。
- 减少值: decr key
- 将指定的key的value原子性的递减1.如果该key不存在,其初始值为0,在incr之后其值为-1。如果value的值不能转成整型,如hello,该操作将执行失败并返回相应的错误信息
- 增加固定的值: incrby key increment
- 将指定的key的value原子性增加increment,如果该key不存在,器初始值为0,在incrby之后,该值为increment。如果该值不能转成整型,如hello则失败并返回错误信息
- 减少固定的值: decrby key decrement
- 将指定的key的value原子性减少decrement,如果该key不存在,器初始值为0,在decrby之后,该值为decrement。如果该值不能转成整型,如hello则失败并返回错误信息
- 增减值: incr key
- 拼接value值: append key value
- 拼凑字符串。如果该key存在,则在原有的value后追加该值;如果该key不存在,则重新创建一个key|value
- 为key中内容设置有效时长:
- 为新创建的key设置时长
- setex key seconds value
- 为已有的key设置有效时长
- expire key seconds
- 为新创建的key设置时长
- 判断key是否存在: exists key
- 返回1 表示存在, 返回0 表示不存在
- 获取key还剩余有效时长: ttl key
- 特殊: 返回-1 表示永久有效 返回-2 表示不存在
6.2 hash类型
- 存值: hset key field value
- key为一个字符串, value类似于map,同样有一个field和value
- 取值:
- 获取指定key的field的值: hget key field
- 获取指定key的多个field值: hmget key fields
- 获取指定key中的所有的field与value的值: hgetall key
- 获取指定key中map的所有的field: hkeys key
- 获取指定key中map的所有的value: hvals key
- 删除:
- hdel key field [field … ] :可以删除一个或多个字段,返回值是被删除的字段个数
- del key :删除整个内容
- 增加数字:
- hincrby key field number:为某个key的某个属性增加值
- 判断某个key中的filed是否存在: hexists key field
- 返回 0表示没有, 返回1 表示有
- 获取key中所包含的field的数量: hlen key
6.3 list集合
redis的中的list集合类似于java中的linkedlist集合,此集合也是队列的一种, 支持向两端操作
- 添加:
- 从左侧添加: lpush key values[value1 value2…]
- 在指定的key所关联的list的头部插入所有的values,如果该key不存在,该命令在插入的之前创建一个与该key关联的空链表,之后再向该链表的头部插入数据。插入成功,返回元素的个数。
- 从右侧添加: rpush key values[value1、value2…]
- 在该list的尾部添加元素
- 从左侧添加: lpush key values[value1 value2…]
- 查看列表 : lrange key start end
- 获取链表中从start到end的元素的值,start、end从0开始计数;end可为负数,若为-1则表示链表尾部的元素,-2则表示倒数第二个,依次类推…
- 删除(弹出):
- 从左侧弹出:lpop key
- 返回并弹出指定的key关联的链表中的第一个元素,即头部元素。如果该key不存在,返回nil;若key存在,则返回链表的头部元素
- 从右侧弹出: rpop key
- 从尾部弹出元素
- 从左侧弹出:lpop key
- 获取列表中元素的个数: llen key
- 返回指定的key关联的链表中的元素的数量
- 向指定的key插入数据, 仅在key存在时插入, 不存在不插入
- 从左侧:lpushx key value
- 从右侧: rpushx key value
- lrem key count value:
- 删除count个值为value的元素,如果count大于0,从头向尾遍历并删除count个值为value的元素,如果count小于0,则从尾向头遍历并删除。如果count等于0,则删除链表中所有等于value的元素
- lset key index value:
- 设置链表中的index的脚标的元素值,0代表链表的头元素,-1代表链表的尾元素。操作链表的脚标不存在则抛异常。
- linsert key before|after pivot value
- 在pivot元素前或者后插入value这个元素。
- rpoplpush resource destination
- 将链表中的尾部元素弹出并添加到头部。[循环操作]
6.4 set集合
- 添加: sadd key values[value1、value2…]
- 向set中添加数据,如果该key的值已有则不会重复添加
- 删除: srem key members[member1、member2…]
- 删除set中指定的成员
- 获取所有的元素: smembers key
- 获取set中所有的成员
- 判断元素是否存在: sismember key member
- 判断参数中指定的成员是否在该set中,1表示存在,0表示不存在或者该key本身就不存在。(无论集合中有多少元素都可以极速的返回结果)
- 集合的差集运算: sdiff key1 key2…
- 返回key1与key2中相差的成员,而且与key的顺序有关。那个在前, 返回那个key对应的差集
- 集合的交集运算:sinter key1 key2 key3…
- 返回交集, 两个key都有的
- 集合的并集运算:sunion key1 key2 key3…
- 返回并集
- 获取set中成员的数量:
- scard key
- 随机返回set中的一个成员:
- srandmember key
- 将key1、key2相差的成员存储在destination上:
- sdiffstore destination key1 key2…
- 将返回的交集存储在destination上:
- sinterstore destination key[key…]
- 将返回的并集存储在destination上:
- sunionstore destination key[key…]
6.5 sortedset集合
-
添加数据: zadd key score member
- 将所有成员以及该成员的分数存放到sorted-set中。如果该元素已经存在则会用新的分数替换原有的分数。返回值是新加入到集合中的元素个数,不包含之前已经存在的元素
-
获得元素:
- zscore key member: 返回指定元素的值
- zcard key: 获取集合中的成员数量
-
删除元素:zrem key member[member…]
- 移除集合中指定的成员,可以指定多个成员。
-
zrank key member:
- 返回成员在集合中的排名。(从小到大)
-
zrevrank key member
- 返回成员在集合中的排名。(从大到小)
-
zincrby key increment member:
- 设置指定成员的增加的分数。返回值是更改后的分数 …
-
范围查询:
- zrange key start end [withscores]: 获取集合中脚标为start-end的成员,[withscores]参数表明返回的成员包含其分数
- zrevrange key start stop [withscores]: 按照元素分数从大到小的顺序返回索引从start到stop之间的所有元素(包含两端的元素)
-
zremrangebyrank key start stop: 按照排名范围删除元素
-
zremrangebyscore key min max: 按照分数范围删除元素
-
zrangebyscore key min max /[withscores][limit offset count]:
- 返回分数在[min,max]的成员并按照分数从低到高排序。[withscores]:显示分数;[limit offset count]:offset,表明从脚标为offset的元素开始并返回count个成员a
-
zcount key min max:
- 获取分数在[min,max]之间的成员
7. redis的持久化
redis中数据存储存储到了内存当中了, 如果服务器关闭, 那么就会导致内存中的数据, 也就会丢失了, 所以需要聊聊redis的持久化, 将内存的数据, 保存到硬盘当中了
redis中一共了两种持久化的方案:
- RDB: 是一种基于快照机制的持久化方案,可以将数据在内存当中的一个状态保存下来, 放置到本地磁盘当中
- 优点: 快照文件一般来说都是比较小, 适合于灾难恢复
- 弊端: 会存在数据丢失的风险
- AOF: 是一种基于日志机制的持久化的方案, 会将用户提交的操作命令, 整体的保存到文件当中
- 优点: 数据丢失的风险比较小的
- 弊端: 持久化的文件会比较大, 不适合做灾难恢复
保存机制:
- RDB保存机制: redis默认已经开启了RDB保存机制
save 900 1 在900秒时间内, 如果有一个数据被修改了, 就会执行一次持久化的保存
save 300 10 在300秒时间内, 如果有10个数据被修改了, 就会执行一次持久化的保存
save 60 10000 在60秒时间内, 如果有一万个数据被修改了, 就会执行一次持久化的保存
最大的丢失量: 在不到五分钟的时间内,丢失9999个数据
-
AOF保存机制: redis默认是不开启的
如果开启了AOF则RDB保存机制还在进行,但是当重启会有限根据AOF对应的日志文件对数据进行恢复。注意:操作日志文件如果出现杂乱数据,可以用redis-check-aof命令进行恢复。同理RDB
appendonly yes 是否开启AOF保存机制
appendfsync everysec 保存的时机设置: [always everysec no]
- always : 总是
- 将用户的每一次的命令都保存下来, 基本上不会有数据丢失的风险, 会极大的影响redis的性能
- everysec : 每秒钟执行
- 会每秒钟执行一次保存操作, 对redis的性能影响较小 , 会丢失一秒的数据
- no : redis不会主动的进行持久化数据, 将持久化的操作交给了操作系统(30/min保存一次)
开发中一般对redis的持久化如何设置的呢:
AOF+RDB(中小规模) RDB(大公司) AOF(小公司)
redis是一个非常稳定服务器, 一般是不会发送宕机的风险, 除非内存爆满了, 但是这个问题在大公司是不存在的
8.redis的事务
四大特性:ACID
- 原子性(不提供原子性)
- 一致性
- 隔离性(不存在隔离级别的概念)
- 持久性
8.1 正常执行

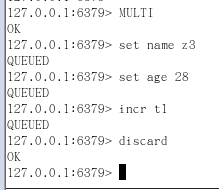
8.2 放弃事务
8.3 全体连坐

8.4 冤有头债有主
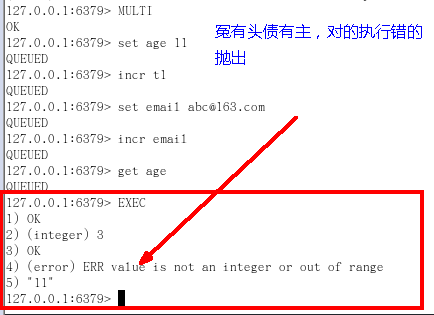
8.5 watch监控
两个重要的概念:乐观锁和悲观锁
乐观锁:
乐观锁(Optimistic Lock), 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量,
乐观锁策略:提交版本必须 大于 记录当前版本才能执行更新
悲观锁:
悲观锁(Pessimistic Lock), 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁l
(1)watch
有加塞篡改:监控了key,如果key被修改了,后面一个事务的执行失效

(2)unwatch
作用:一旦执行了exec之前加的监控锁都会被取消掉了
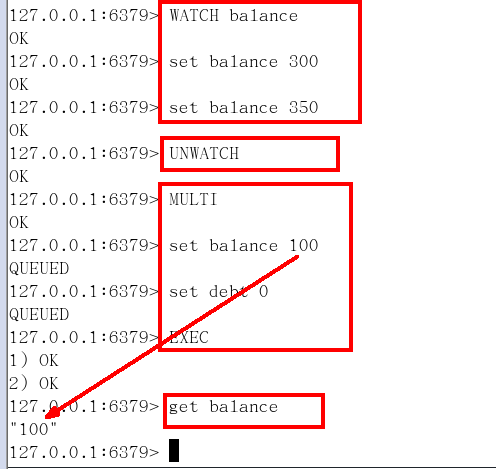
小结:
Watch指令,类似乐观锁,事务提交时,如果Key的值已被别的客户端改变,比如某个list已被别的客户端push/pop过了,整个事务队列都不会被执行。
通过WATCH命令在事务执行之前监控了多个Keys,倘若在WATCH之后有任何Key的值发生了变化,EXEC命令执行的事务都将被放弃,同时返回Nullmulti-bulk应答以通知调用者事务执行失败。
9.redis集群
redis支持集群部署,架构为主从复制,主机数据更新后根据配置和策略,自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主。
主要作用:
- 读写分离
- 容灾恢复
其主要缺点:
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
9.1 基本操作
(1)一主二仆
- init

- 一个Master两个Slave
注意命令:slaveof 主库IP 主库端口
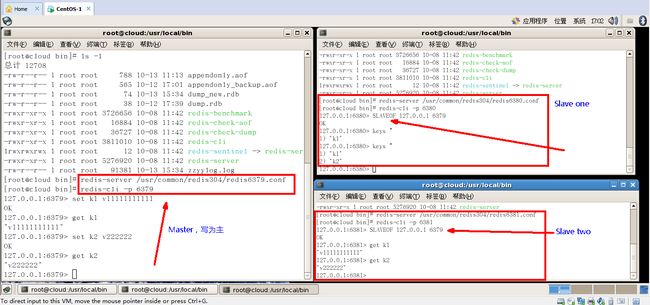
- 查看日志
主机日志
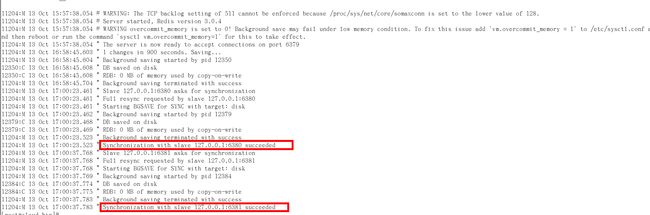
备机日志
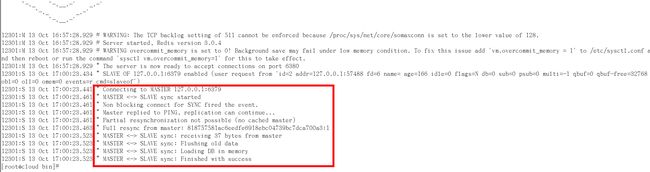
info replication

(2)薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他slaves的连接和同步请求,那么该slave作为了链条中下一个的master,可以有效减轻master的写压力(但是注意:集群中还是只有一个master)
中途变更转向:会清除之前的数据,重新建立拷贝最新的。
操作方法:slaveof 新主库IP 新主库端口
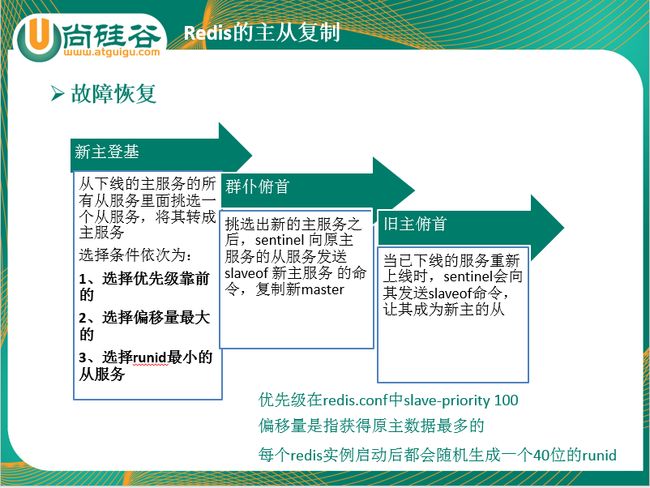
(3)反客为主
即一个命令:slaveof no one 将当前客户端转化为主master节点
使当前数据库停止与其他数据库的同步,转成主数据库
9.2 复制原理
(1)slave启动成功连接到master后会发送一个sync命令。
(2)Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步。
(3)全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
(4)增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步。
(5)但是只要是重新连接master,一次完全同步(全量复制)将被自动执行。
9.3 哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
作用:
哨兵的作用:
- 监控redis进行状态,包括master和slave
- 当master down机,自动选出master,能自动将slave切换成master
- 将原来的master降为slave
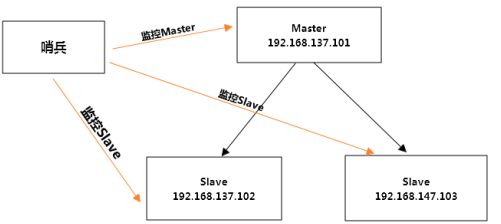
(1)配置哨兵模式
Redis Sentinel架构架构说明
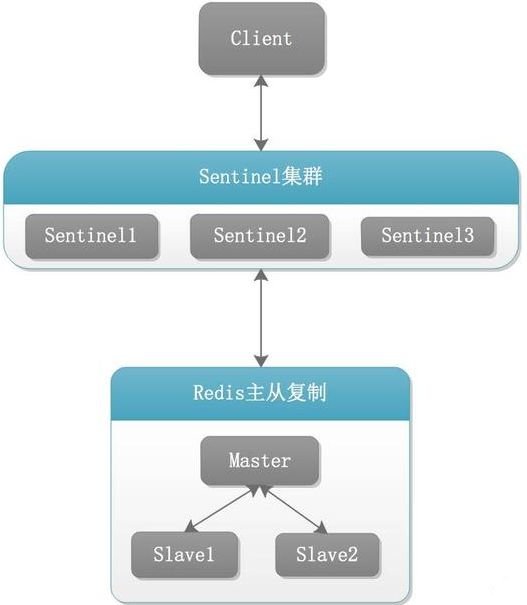
1)调整结构,6379带着80、81
2)在Redis配置文件的目录下新建sentinel.conf文件,名字绝不能错
3)配置哨兵,填写内容
sentinel monitor 被监控数据库名字(自己起名字) 127.0.0.1 6379 1
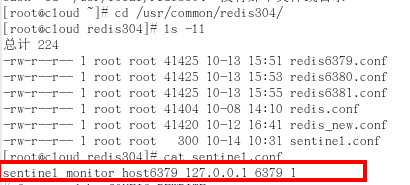
*行尾最后的一个数字代表什么意思呢?*数字1表示至少有多少个哨兵同意迁移的数量。
我们知道,网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,当sentinel集群式,解决这个问题的方法就变得很简单,只需要多个sentinel互相沟通来确认某个master是否真的死了,这个Number代表,当集群中有Nunber个sentinel认为master死了时,才能真正认为该master已经不可用了。(sentinel集群中各个sentinel也有互相通信,通过gossip协议)。
4)启动哨兵

(2)原理分析
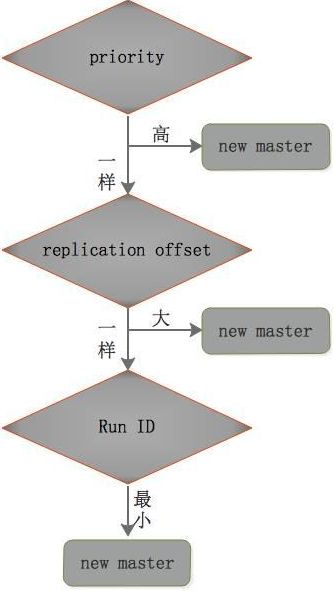
Sentinel集群对自身和Redis主从复制进行监控。当发现Master节点出现故障时,会经过如下步骤:
1)Sentinel之间进行选举,在剩余活着的机器里选举出一个leader,由选举出的leader进行failover(故障迁移)
2)Sentinel leader选取slave节点中的一个slave作为新的Master节点
3)Sentinel leader会在上一步选举的新master上执行slaveof no one操作,将其提升为master节点
4)Sentinel leader向其它slave发送命令,让剩余的slave成为新的master节点的slave
5)Sentinel leader会让原来的master降级为slave,当恢复正常工作。
6)Sentinel leader会发送命令让其从新的master进行复制。上述的failover操作均有sentinel自己独自完成,完全无需人工干预。
选举过程: