Elasticsearch之原理深入理解
文章目录
- 一、定义
- 二、基本概念
- 三、倒排索引
- 四、集群架构
- 五、大量数据下提升查询效率措施
一、定义
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene™ 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
二、基本概念
(一)索引 Index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
(二) 类型 Type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
(三) 文档 Document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
(四) 映射 Mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
(五) 字段 Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
(六) 节点 Node
一个运行中的 Elasticsearch 实例称为一个节点,而集群是由一个或者多个拥有相同cluster.name配置的节点组成, 它们共同承担数据和负载的压力。
ES集群中的节点有三种不同的类型:
- 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
- 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
- 协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
(七) 分片 Shard
一个索引中的数据保存在多个分片中,相当于水平分表。一个分片便是一个Lucene 的实例,它本身就是一个完整的搜索引擎。我们的文档被存储和索引到分片内,但是应用程序是直接与索引而不是与分片进行交互。
ES实际上就是利用分片来实现分布式。分片是数据的容器,文档保存在分片内,分片又被分配到集群内的各个节点里。 当你的集群规模扩大或者缩小时, ES会自动的在各节点中迁移分片,使得数据仍然均匀分布在集群里。
一个分片可以是主分片或者副本分片。 索引内任意一个文档都归属于一个主分片,所以主分片的数目决定着索引能够保存的最大数据量。一个副本分片只是一个主分片的拷贝。 副本分片作为硬件故障时保护数据不丢失的冗余备份,并为搜索和返回文档等读操作提供服务。
在索引建立的时候就已经确定了主分片数,并且要求不能更改,否则可能会导致查不到数据
主分片和副本分片的状态决定了集群的健康状态。每一个节点上都只会保存主分片或者其对应的一个副本分片,相同的副本分片不会存在于同一个节点中。如果集群中只有一个节点,则副本分片将不会被分配,此时集群健康状态为yellow,存在丢失数据的风险。

(八)小节
index:mysql数据库
type:就像一张表。
- ES5.X中一个index可以有多个type、
- ES6.X中一个type只能有一个type、
- ES7.X中移除了type这个概念,此时的index就像一张表了。
mapping:定义了每个字段的类型等信息。相当于关系型数据库中的表结构。
document:一条document就代表了mysql表里的一条记录。
field:每个field就代表了这个document中的一个字段的值。
三、倒排索引

这里有好几个概念。我们来看一个实际的例子,假设有如下的数据:
| docid | Age | Sex |
|---|---|---|
| 1 | 18 | 女 |
| 2 | 20 | 女 |
| 3 | 18 | 男 |
这里每一行是一个 document。每个 document 都有一个 docid。那么给这些 document 建立的倒排索引就是:
Age:
| Term | Posting List |
|---|---|
| 18 | [1,3] |
| 20 | 2 |
Sex:
| Term | Posting List |
|---|---|
| Male | 3 |
| Female | [1,2] |
可以看到,倒排索引是 per field 的,一个字段由一个自己的倒排索引。18,20 这些叫做 term,而 [1,3] 就是 posting list。Posting list 就是一个 int 的数组,存储了所有符合某个 term 的文档 id。那么什么是 term dictionary 和 term index?
假设我们有很多个 term,比如:
Carla,Sara,Elin,Ada,Patty,Kate,Selena
如果按照这样的顺序排列,找出某个特定的 term 一定很慢,因为 term 没有排序,需要全部过滤一遍才能找出特定的 term。排序之后就变成了:
Ada,Carla,Elin,Kate,Patty,Sara,Selena
这样我们可以用二分查找的方式,比全遍历更快地找出目标的 term。这个就是 term dictionary。有了 term dictionary 之后,可以用 logN 次磁盘查找得到目标。但是磁盘的随机读操作仍然是非常昂贵的(一次 random access 大概需要 10ms 的时间)。所以尽量少的读磁盘,有必要把一些数据缓存到内存里。但是整个 term dictionary 本身又太大了,无法完整地放到内存里。于是就有了 term index。term index 有点像一本字典的大的章节表。比如:
- A 开头的 term ……………. Xxx 页
- C 开头的 term ……………. Xxx 页
- E 开头的 term ……………. Xxx 页
如果所有的 term 都是英文字符的话,可能这个 term index 就真的是 26 个英文字符表构成的了。但是实际的情况是,term 未必都是英文字符,term 可以是任意的 byte 数组。而且 26 个英文字符也未必是每一个字符都有均等的 term,比如 x 字符开头的 term 可能一个都没有,而 s 开头的 term 又特别多。实际的 term index 是一棵 trie 树:
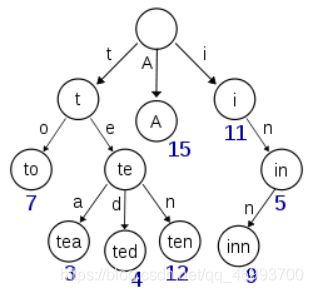
例子是一个包含 “A”, “to”, “tea”, “ted”, “ten”, “i”, “in”, 和 “inn” 的 trie 树。这棵树不会包含所有的 term,它包含的是 term 的一些前缀。通过 term index 可以快速地定位到 term dictionary 的某个 offset,然后从这个位置再往后顺序查找。再加上一些压缩技术(搜索 Lucene Finite State Transducers) term index 的尺寸可以只有所有 term 的尺寸的几十分之一,使得用内存缓存整个 term index 变成可能。整体上来说就是这样的效果。

现在我们可以回答“为什么 Elasticsearch/Lucene 检索可以比 mysql 快了。Mysql 只有 term dictionary 这一层,是以 b-tree 排序的方式存储在磁盘上的。检索一个 term 需要若干次的 random access 的磁盘操作。而 Lucene 在 term dictionary 的基础上添加了 term index 来加速检索,term index 以树的形式缓存在内存中。从 term index 查到对应的 term dictionary 的 block 位置之后,再去磁盘上找 term,大大减少了磁盘的 random access 次数。
额外值得一提的两点是:term index 在内存中是以 FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary 在磁盘上是以分 block 的方式保存的,一个 block 内部利用公共前缀压缩,比如都是 Ab 开头的单词就可以把 Ab 省去。这样 term dictionary 可以比 b-tree 更节约磁盘空间。
四、集群架构
(一)结点
1、结点属性
默认情况下,elasticsearch集群中每个节点都有成为主节点的资格,也都存储数据,还可以提供查询服务。
这些功能是由两个属性控制的。
node.master和node.data,默认情况下这两个属性的值都是true。
- node.master:这个属性表示节点是否具有成为主节点的资格。注意:此属性的值为true,并不意味着这个节点就是主节点。
- node.data:这个属性表示节点是否存储数据
这两个属性可以有四种组合:
第一种
node.master: true
node.data: true
这种组合表示这个节点即有成为主节点的资格,又存储数据
这个时候如果某个节点被选举成为了真正的主节点,那么他还要存储数据,这样对于这个节点的压力就比较大了。elasticsearch默认每个节点都是这样的配置,在测试环境下这样做没问题。实际工作中建议不要这样设置,这样相当于主节点和数据节点的角色混合到一块了。
第二种
node.master: false
node.data: true
这种组合表示这个节点没有成为主节点的资格,也就不参与选举,只会存储数据。
这个节点我们称为data(数据)节点。在集群中需要单独设置几个这样的节点负责存储数据。后期提供存储和查询服务。
第三种
node.master: true
node.data: false
这种组合表示这个节点不会存储数据,有成为主节点的资格,可以参与选举,有可能成为真正的主节点。
这个节点我们称为master节点
第四种
node.master: false
node.data: false
这种组合表示这个节点即不会成为主节点,也不会存储数据,
这个节点的意义是作为一个client(客户端)节点,主要是针对海量请求的时候可以进行负载均衡。
2、结点类型
ES集群中的节点有三种不同的类型:
- 主节点:负责管理集群范围内的所有变更,例如增加、删除索引,或者增加、删除节点等。 主节点并不需要涉及到文档级别的变更和搜索等操作。可以通过属性node.master进行设置。
- 数据节点:存储数据和其对应的倒排索引。默认每一个节点都是数据节点(包括主节点),可以通过node.data属性进行设置。
- 协调节点:如果node.master和node.data属性均为false,则此节点称为协调节点,用来响应客户请求,均衡每个节点的负载。
(二)选举过程
1、ZenDiscovery算法
Zen发现机制默认配置是用多播来寻找其它的节点。如果各个模块工作正常,该节点就会自动添加到与节点中集群名字(cluster.name)一样的集群,同时其它的节点都能感知到新节点的加入。在比较大的集群中,多播发现机制可能会产生太多不必要的流量开销,Zen发现机制引入了第二种发现节点的方法:单播模式。
- 单播: 关闭多播,就可以安全地使用单播。当节点不是集群的一部分时(比如节点重启,启动或者由于某些错误从集群中断开),节点会发送一个ping请求到事先设置好的地址中,来通知集群它已经准备好加入到集群中了。
- 多播:当节点并非集群的一部分时(比如节点只是刚刚启动或者重启 ),它会发送一个多播的ping请求到网段中,该请求只是用来通知所有能连接到节点和集群它已经准备好加入到集群中。
为了安全考虑,阿里一般用单播模式。
2、服务发现以及选主过程
1.节点启动后先ping(这里的ping的对象在 discovery.zen.ping.unicast.hosts 设置,若不设置则尝试ping localhost 的几个端口, Elasticsearch 支持同一个主机启动多个节点)Ping的response会包含该节点的基本信息以及该节点认为的master节点。
2.选举开始,会对所有可以成为master的节点(node.master: true)根据nodeId字典排序,然后选出第一个(第0位)节点,暂且认为它是master节点。
3.如果各节点都没有认为的master,则从所有节点中选择,规则同上。这里有个限制条件就是 discovery.zen.minimum_master_nodes,如果节点数达不到最小值的限制,则循环上述过程,直到节点数足够可以开始选举。
4.如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举一直到满足上述条件。
5.最后选举结果是肯定能选举出一个master,如果只有一个local节点那就选出的是自己。
6.如果当前节点是master,则开始等待节点数达到 minimum_master_nodes(最小候选节点数),然后提供服务。
7.如果当前节点不是master,则尝试加入master。
(三)分片(lucene索引结构,segment的生成,合并),路由算法
1、本质
Shard 实际上是一个 Lucene 的一个实例(Lucene Index),但往往一个 Elastic Index 都是由多个 Shards (primary & replica)构成的。
特别注意,在单个 Lucene 实例里最多包含2,147,483,519 (= Integer.MAX_VALUE - 128) 个 Documents。
2、Lucene Index结构
一个 Lucene Index 在文件系统的表现上来看就是存储了一系列文件的一个目录。一个 Lucene Index 由许多独立的 segments 组成,而 segments 包含了文档中的词汇字典、词汇字典的倒排索引以及 Document 的字段数据(设置为Stored.YES的字段),所有的 segments 数据存储于 _.cfs的文件中。
3、Segment
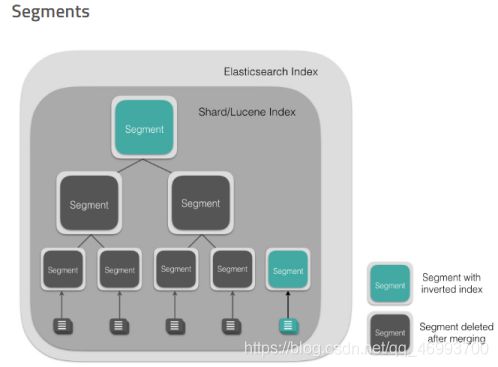
Segment 直接提供了搜索功能的,ES 的一个 Shard (Lucene Index)中是由大量的 Segment 文件组成的,且每一次 fresh 都会产生一个新的 Segment 文件,这样一来 Segment 文件有大有小,相当碎片化。ES 内部则会开启一个线程将小的 Segment 合并(Merge)成大的 Segment,减少碎片化,降低文件打开数,提升 I/O 性能。
Segment 文件是不可变更的。当一个 Document 更新的时候,实际上是将旧的文档标记为删除,然后索引一个新的文档。在 Merge 的过程中会将旧的 Document 删除掉。具体到文件系统来说,文档 A 是写入到 .cfs 文件里的,删除文档 A 实际上是在.del文件里标记某个 document 已被删除,那么下次查询的时候则会跳过这个文档,是为逻辑删除。当归并(Merge)的时候,老的 segment 文件将会被删除,合并成新的 segment 文件,这个时候也就是物理删除了。


4、路由算法
Elasticsearch针对路由计算选择了一个很简单的方法,计算如下:
routing = hash(routing) % number_of_primary_shards
每个数据都有一个routing参数,默认情况下,就使用其_id值,将其_id值计算hash后,对索引的主分片数取余,就是数据实际应该存储到的分片ID
由于取余这个计算,完全依赖于分母,所以导致Elasticsearch索引有一个限制,索引的主分片数,不可以随意修改。因为一旦主分片数不一样,索引数据不可读。
一般来说,某个shard分配在哪个节点上,是由Elasticsearch自动决定的。以下几种情况会触发分配动作。
- 新索引生成
- 索引的删除
- 新增副本分片
- 节点增减引发的数据均衡
(五)副本
作为分布式系统,数据副本可算是一个标配。Elasticsearch数据写入流程。自然涉及副本,在有副本配置的情况下,数据从发向Elasticsearch节点,到接到Elasticsearch节点响应返回,流向如下

1)客户端请求发送给master Node1节点,这里也可以发送给其他节点
2)Node1节点用数据的_id计算出数据应该存储在shard0上,通过cluster state信息发现shard0的主分片在Node3节点上,Node1转发请求数据给Node3,Node3完成数据的索引,索引过程在上篇博客中详细介绍了。
3)Node3并行转发数据给分配有shard0的副本分片Node1和Node2上。当收到任一节点汇报副本分片数据写入成功以后,Node3即返回给初始的接受节点Node1,宣布数据写入成功。Node1成功返回给客户端。
(六)集群下的查询(tranlog、FileSystem cache与分页查询,segment合并)、写入、更新与删除过程
当用户向一个节点提交了一个索引新文档的请求,节点会计算新文档应该加入到哪个分片(shard)中。每个节点都存储有每个分片存储在哪个节点的信息,因此协调节点会将请求发送给对应的节点。注意这个请求会发送给主分片,等主分片完成索引,会并行将请求发送到其所有副本分片,保证每个分片都持有最新数据。
1、查询
读操作(Read):查询过程
查询的过程大体上分为查询(query)取回(fetch)两个阶段。这个节点的任务是广播查询请求到所有相关分片,并将它们的响应整合成全局排序后的结果集合,这个结果集合会返回给客户端。
查询阶段
当一个节点接收到一个搜索请求,则这个节点就变成了协调节点。

第一步是广播请求到索引中每一个节点的分片拷贝。 查询请求可以被某个主分片或某个副本分片处理,协调节点将在之后的请求中轮询所有的分片拷贝来分摊负载。
每个分片将会在本地构建一个优先级队列。如果客户端要求返回结果排序中从第from名开始的数量为size的结果集,则每个节点都需要生成一个from+size大小的结果集,因此优先级队列的大小也是from+size。分片仅会返回一个轻量级的结果给协调节点,包含结果集中的每一个文档的ID和进行排序所需要的信息。
协调节点会将所有分片的结果汇总,并进行全局排序,得到最终的查询排序结果。此时查询阶段结束。
取回阶段
查询过程得到的是一个排序结果,标记出哪些文档是符合搜索要求的,此时仍然需要获取这些文档返回客户端。
协调节点会确定实际需要返回的文档,并向含有该文档的分片发送get请求;分片获取文档返回给协调节点;协调节点将结果返回给客户端。

2、写入
每次写入新文档时,都会先写入内存中,并将这一操作写入一个translog文件(transaction log)中,此时如果执行搜索操作,这个新文档还不能被索引到。

ES会每隔1秒时间(这个时间可以修改)进行一次刷新操作(refresh),此时在这1秒时间内写入内存的新文档都会被写入一个文件系统缓存(filesystem cache)中,并构成一个分段(segment)。此时这个segment里的文档可以被搜索到,但是尚未写入硬盘,即如果此时发生断电,则这些文档可能会丢失。
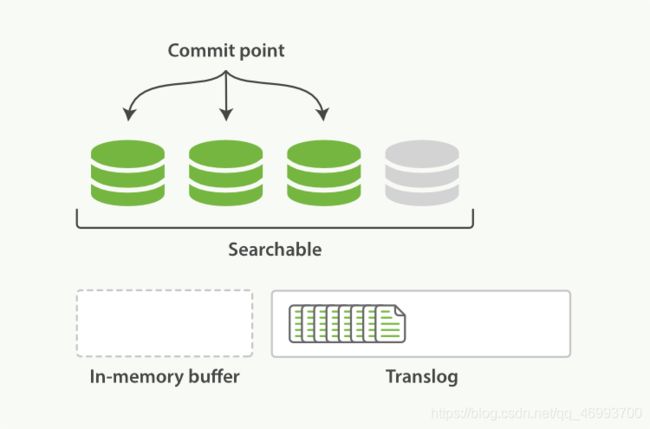
不断有新的文档写入,则这一过程将不断重复执行。每隔一秒将生成一个新的segment,而translog文件将越来越大。

每隔30分钟或者translog文件变得很大,则执行一次fsync操作。此时所有在文件系统缓存中的segment将被写入磁盘,而translog将被删除(此后会生成新的translog)。

由上面的流程可以看出,在两次fsync操作之间,存储在内存和文件系统缓存中的文档是不安全的,一旦出现断电这些文档就会丢失。所以ES引入了translog来记录两次fsync之间所有的操作,这样机器从故障中恢复或者重新启动,ES便可以根据translog进行还原。
当然,translog本身也是文件,存在于内存当中,如果发生断电一样会丢失。因此,ES会在每隔5秒时间或是一次写入请求完成后将translog写入磁盘。可以认为一个对文档的操作一旦写入磁盘便是安全的可以复原的,因此只有在当前操作记录被写入磁盘,ES才会将操作成功的结果返回发送此操作请求的客户端。
此外,由于每一秒就会生成一个新的segment,很快将会有大量的segment。对于一个分片进行查询请求,将会轮流查询分片中的所有segment,这将降低搜索的效率。因此ES会自动启动合并segment的工作,将一部分相似大小的segment合并成一个新的大segment。合并的过程实际上是创建了一个新的segment,当新segment被写入磁盘,所有被合并的旧segment被清除。


3、更新与删除
ES的索引是不能修改的,因此更新和删除操作并不是直接在原索引上直接执行。
删除(Delete)文档
每一个磁盘上的segment都会维护一个del文件,用来记录被删除的文件。每当用户提出一个删除请求,文档并没有被真正删除,索引也没有发生改变,而是在del文件中标记该文档已被删除。因此,被删除的文档依然可以被检索到,只是在返回检索结果时被过滤掉了。每次在启动segment合并工作时,那些被标记为删除的文档才会被真正删除。
更新(Update)
更新文档会首先查找原文档,得到该文档的版本号。然后将修改后的文档写入内存,此过程与写入一个新文档相同。同时,旧版本文档被标记为删除,同理,该文档可以被搜索到,只是最终被过滤掉。
(七)数据一致性问题(脑裂,master结点断开,数据结点断开)
1、脑裂
(1)什么是“脑裂”现象?
由于某些节点的失效,部分节点的网络连接会断开,并形成一个与原集群一样名字的集群,这种情况称为集群脑裂(split-brain)现象。这个问题非常危险,因为两个新形成的集群会同时索引和修改集群的数据。
(2)如何避免脑裂问题?
避免脑裂现象,用到的一个参数是:discovery.zen.minimum_master_nodes。这个参数决定了要选举一个Master需要多少个节点(最少候选节点数)。默认值是1。根据一般经验这个一般设置成 N/2 + 1,N是集群中节点的数量,例如一个有3个节点的集群,minimum_master_nodes 应该被设置成 3/2 + 1 = 2(向下取整)。
用到的另外一个参数是:discovery.zen.ping.timeout,等待ping响应的超时时间,默认值是3秒。如果网络缓慢或拥塞,建议略微调大这个值。这个参数不仅仅适应更高的网络延迟,也适用于在一个由于超负荷而响应缓慢的节点的情况。
2、集群如何恢复以及容灾
分布式系统的一个要求就是要保证高可用。如果是故障导致节点挂掉,Elasticsearch 就会主动allocation。但如果节点丢失后立刻allocation,稍后节点恢复又立刻加入,会造成浪费。Elasticsearch的恢复流程大致如下:
(1)数据结点容灾
集群中的某个非master节点丢失网络连接
如果该节点上的分片有副本,那么master提升该节点上的所有主分片的在其他节点上的副本为主分片。cluster集群状态变为 yellow ,因为副本数不够
等待一个超时设置的时间,如果丢失节点回来就可以立即恢复(默认为1分钟,通过 index.unassigned.node_left.delayed_timeout 设置)。如果该分片已经有写入,则通过translog进行增量同步数据。
否则将副本分配给其他节点,开始同步数据。
但如果该节点上的分片没有副本,则无法恢复,集群状态会变为red,表示可能要丢失该分片的数据了。
(2)主节点容灾
如果是主节点master挂掉怎么办呢?当从节点们发现和主节点连接不上了,那么他们会自己决定再选举出一个节点为主节点。
但是这里有个脑裂的问题,假设有5台机器,3台在一个机房,2台在另一个机房,当两个机房之间的联系断了之后,每个机房的节点会自己聚会,推举出一个主节点。
这个时候就有两个主节点存在了,当机房之间的联系恢复了之后,这个时候就会出现数据冲突了。解决的办法就是设置参数: discovery.zen.minimum_master_nodes
为3(超过一半的节点数),那么当两个机房的连接断了之后,就会以大于等于3的机房的master为主,另外一个机房的节点就停止服务了。
五、大量数据下提升查询效率措施
(一)filesystem cache
往es写入数据时,其实就是写入到磁盘中的。而es的搜索引擎底层是严重依赖于文件系统缓存的,es所有的indx segment file索引数据文件就存在这里面,如果filesystem cache的内存够大,那么你搜索的时候基本就是走内存的,性能会很高。打个比方说:
es节点有3台机器,每台机器,看起来内存很多,64G,总内存,64 * 3 = 192g;每台机器给es jvm heap是32G,那么剩下来留给filesystem cache的就是每台机器才32g,总共集群里给filesystem cache的就是32 * 3 = 96g内存。如果有1T的数据量,那就只有10%的索引文件被存到file cache里面去,效率肯定是比较低的,就是你的机器的内存,至少可以容纳你的总数据量的一半。
(二)数据预热/冷热分离
预热:比如file cache有50g内存,而数据超过了100g怎么办呢?我们可以做一个后台系统定时去拉取一些容易被人访问的数据。因为我们查询es时,它会重新记录这个索引的信息、进行排序将这些数据放到file cache中。
冷热分离:大量不搜索的字段拆到别的index里面去,就有点像mysql的垂直拆分,这样可以确保热数据在被预热之后,尽量都让他们留在filesystem os cache里,别让冷数据给冲刷掉。热数据可能就占总数据量的10%,此时数据量很少,几乎全都保留在filesystem cache里面了,就可以确保热数据的访问性能是很高的。
(三) document模型设计
es里面的复杂的关联查询,复杂的查询语法,尽量别用,一旦用了性能一般都不太好。有关联的最好写入es的时候,搞成两个索引,order索引,orderItem索引,order索引里面就包含id order_code total_price;orderItem索引直接包含id order_code total_price id order_id goods_id purchase_count price,这样就不需要es的语法来完成join了。
(四) 分页性能优化
es的分页是较坑的,假如建立一个结果集窗口,窗口大小为from+size,from=1000,size=10,则窗口大小为1010,实际上是会把每个shard上存储的前1010条数据都查到一个协调节点上,如果你有个5个shard,那么就有5050条数据,接着协调节点对这5050条数据进行一些合并、排序,再获取到最终10条数据。翻页的时候,翻的越深,每个shard返回的数据就越多,而且协调节点处理排序的时间越长,效率越低。所以用es做分页的时候,你会发现越翻到后面,就越是慢。
对于深度分页,可以使用scroll查询,sroll就像传统数据库中的游标一样。用scroll api一页页去刷,scroll的原理实际上是保留一个数据快照,然后在一定时间内,你如果不断的滑动往后翻页的时候,类似于你现在在浏览微博,不断往下刷新翻页。那么就用scroll不断通过游标获取下一页数据,这个性能是很高的,比es实际翻页要好的多的多。
参考:
[1] Elasticsearch-基础介绍及索引原理分析
[2] ElasticSearch概念介绍(一)ElasticSearch简介
[3] elasticsearch原理剖析
[4] ElasticSearch工作原理与优化