Hexagon_V65_Programmers_Reference_Manual(6)
Hexagon_V65_Programmers_Reference_Manual(6)
- 5 内存
-
- 5.1 内存模式
-
- 5.1.1 地址空间
- 5.1.2 字节顺序
- 5.1.3 对齐
- 5.2 内存加载
- 5.3 内存存储
- 5.4 双路存储
- 5.5 插槽1存储,插槽0加载
- 5.6 新类型存储
- 5.7 内存操作
- 5.8 寻址模式
-
- 5.8.1 绝对寻址
- 5.8.2 绝对寻址集合
- 5.8.3 带寄存器偏移的绝对寻址
- 5.8.4 全局指针相对
- 5.8.5间接寻址模式
- 5.8.6 带偏移量的间接
- 5.8.7 带寄存器偏移的间接
- 5.8.8 具有自动增量立即数的间接
- 5.8.9 带自动递增寄存器的间接
- 5.8.10 具有自动增量立即数的循环
- 5.8.11 带自动递增寄存器的循环
- 5.8.12 用自动递增寄存器反转位
- 5.9 条件加载/存储
- 5.10 高速缓存
-
- 5.10.1 未缓存内存
- 5.10.2 紧耦合存储器
- 5.10.3缓存维护操作
- 5.10.4 二级缓存操作
- 5.10.5 缓存线零
- 5.10.6 缓存预取
-
- 基于硬件的指令缓存预取
- 基于软件的数据缓存预取
- 基于软件的二级拿取
- 基于硬件的数据缓存预取
- 5.11 内存排序
- 5.12 原子操作
5 内存
Hexagon处理器具有加载/存储架构,其中数字和逻辑指令在寄存器上运行。显式加载指令从内存中移动操作数到寄存器,而存储指令将操作数从寄存器移动到内存。一个小执行数字和逻辑运算的指令数(称为mem-ops)直接存储。
地址空间是统一的:所有访问都以相同的线性地址空间为目标,这包含指令和数据
5.1 内存模式
本节介绍Hexagon处理器的内存模型
5.1.1 地址空间
Hexagon处理器具有32位字节可寻址内存地址空间。整个4G线性地址空间可由用户应用程序寻址。虚拟到物理提供了地址转换机制。
5.1.2 字节顺序
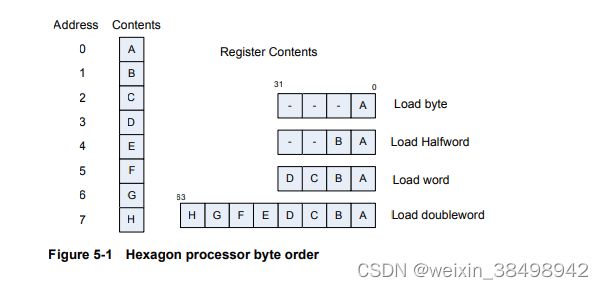
Hexagon处理器是一种小端机器:内存中的最低地址字节是
保存在寄存器的最低有效字节中,如图5-1所示
5.1.3 对齐
即使Hexagon处理器内存是字节可寻址的,指令和数据必须在内存中的特定地址边界上对齐:
- 指令和指令包必须32位对齐
- 数据必须与其本机访问大小对齐。
任何未对齐的内存访问都会导致内存对齐异常。置换指令(第4.3.6节)可用于需要参考的应用程序未对齐的矢量数据。加载和存储仍然必须与内存对齐;然而
排列指令使数据能够在寄存器中轻松重新排列。
表5-1总结了对齐限制。

5.2 内存加载
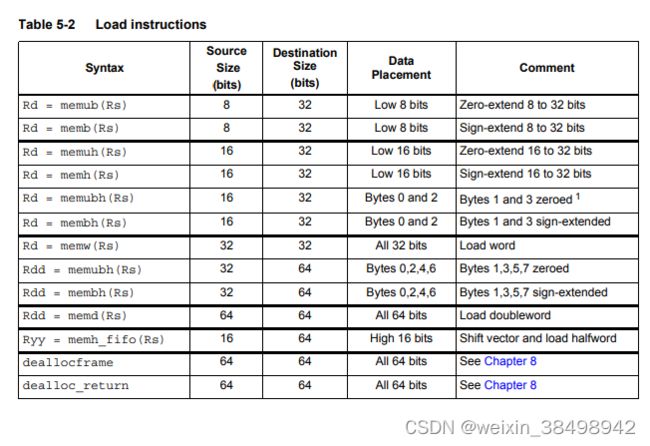
内存可以按字节、半字、字或双字大小加载。数据类型支持有符号或无符号。使用的语法是memXX,其中XX表示数据类型
表5-2总结了支持的加载说明
图中注解:
memubh和membh指令从内存加载连续字节(2或4个字节),并将这些字节解包到半字向量。当字节用作半字向量运算的输入时,这些指令很有用,半字向量运算在视频和图像处理。
注意,内存加载指令属于指令类LD,可以执行仅在插槽0或1中
5.3 内存存储
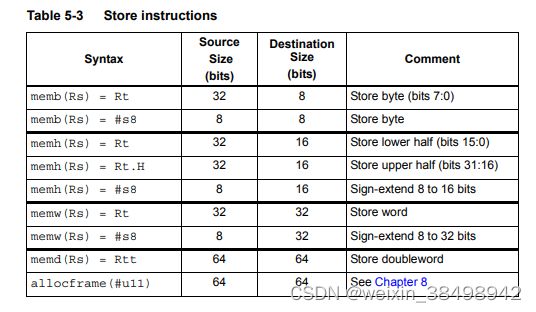
内存可以按字节、半字、字或双字大小存储。使用的语法为memX,其中X表示数据类型。
表5-3总结了支持的存储指令
注意,内存存储指令属于指令类ST,可以执行仅在插槽0中,或–当作为双存储的一部分时(第5.4节)–插槽1
5.4 双路存储
两条内存存储指令可以出现在同一个指令包中。由此产生的操作被视为双重存储。例如:
{
memw(R5) = R2 // dual store
memh(R6) = R3
}
与大多数打包操作不同,双存储不是并行执行的(第3.3.1节)。相反,插槽1中的store指令首先有效执行,然后是store指令插槽0中的指令
注:双存储器中的存储指令必须属于指令类ST(第5.3节),并且只能在插槽0和1中执行。
5.5 插槽1存储,插槽0加载
插槽1存储操作和插槽0加载操作可以出现在数据包中。数据包属性:mem\u noshuf禁止指令重新排序,否则将由汇编程序。例如:
{
memw(R5) = R2 // slot 1 store
R3 = memh(R6) // slot 0 load
}:mem_noshuf
与大多数打包操作不同,这些内存操作不是并行执行的(第3.3.1节)。相反,插槽1中的store指令有效地首先执行,然后执行通过插槽0中的加载指令。如果两个操作的地址重叠,则load将接收新存储的数据。处理器版本支持此功能V65或更高。
5.6 新类型存储
内存存储指令可以将分配了新值的寄存器存储在同一内存中指令包(第3.3节)。此功能在汇编语言中表示为将后缀“.new”附加到源寄存器。例如:
{
R2 = memh(R4+#8) // load halfword
memw(R5) = R2.new // store newly-loaded value
}
新类型存储指令具有以下限制:
- 如果指令使用自动递增或绝对设置寻址模式(第5.8节),其地址寄存器不能用作新的值寄存器。
- 如果指令产生64位结果,则其结果寄存器不能用作新值寄存器。
- 如果设置新值寄存器的指令是有条件的(第6.1.2节),则必须始终执行。
注意,新的值存储指令属于指令类NV,可以仅在插槽0中执行。
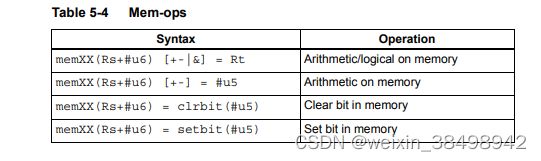
5.7 内存操作
内存操作直接在内存上执行基本的算术、逻辑和位操作操作数,无需单独加载或存储。Mem ops可以在字节、半字或字大小。表5-4列出了mem ops
注:mem op指令属于指令类MEMOP,可以仅在插槽0中执行。
5.8 寻址模式
表5-5总结了支持的寻址模式
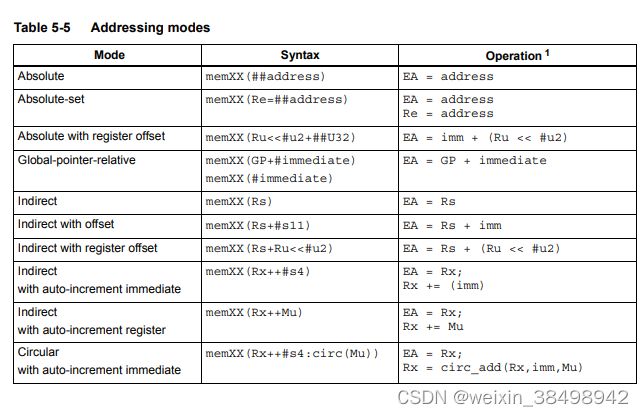

5.8.1 绝对寻址
绝对寻址模式使用32位常量值作为有效内存
住址例如
R2 = memw(##100000) // load R2 with word from addr 100000
memw(##200000) = R4 // store R4 to word at addr 200000
5.8.2 绝对寻址集合
绝对集寻址模式将32位常数值分配给指定的通用值寄存器,然后使用分配的值作为有效内存地址。例如
R2 = memw(R1=##400000) // load R2 with word from addr 400000
// and load R1 with value 400000
memw(R3=##600000) = R4 // store R4 to word at addr 600000
// and load R3 with value 600000
5.8.3 带寄存器偏移的绝对寻址
带寄存器偏移量的绝对寻址模式执行32的算术左移位-位通用寄存器值乘以2位无符号立即数值中指定的量,以及然后将移位结果与无符号32位常数值相加,以创建32位有效内存地址。例如:
R2 = memh(R3 << #3 + ##100000) // load R2 with signed halfword
// from addr [100000 + (R3 << 3)]
32位常量值是基址,移位后的结果是字节偏移量
注意,这种寻址模式对于从全局表加载元素很有用,其中立即数值是表的名称,寄存器保存元素的索引
5.8.4 全局指针相对
全局指针相对寻址模式将无符号偏移值添加到Hexagon处理器全局数据指针GP,用于创建32位有效内存地址。这在C语言中,寻址模式用于访问全局和静态数据。
全局指针相对地址可以用汇编语言表示为两种方式:
- 通过向寄存器GP显式添加无符号偏移值
- 通过仅指定立即数值作为指令操作数
例如:
R2 = memh(GP+#100) // load R2 with signed halfword
// from [GP + 100 bytes]
R3 = memh(#2000) // load R3 with signed halfword
// from [GP + #2000 - _SDA_BASE]
仅指定即时值会导致汇编器和链接器自动从立即数值中减去特殊符号_SDA\u BASE_的值,并使用结果作为与GP的有效偏移量。
全局数据指针编程在寄存器GP的GDP字段中(第2.2.8节)。该字段包含一个无符号26位值,该值指定32位全局数据指针。(指针的最低有效6位定义为始终为零。)
全局数据指针引用的内存区域称为全局数据区域。它由于全局数据指针的方式,其长度可达512 KB已定义–必须与虚拟内存中的64字节边界对齐。
当用汇编语言表示时,全局指针相对寻址总是指定距全局数据指针的字节偏移量。请注意,偏移必须是指令数据类型大小的整数倍。
表5-6列出了全局指针相对寻址的偏移范围
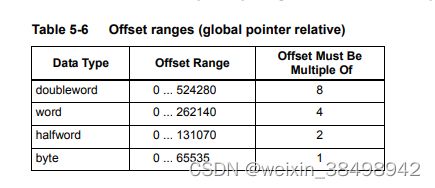
注意:使用全局指针相对寻址时,立即数操作数应成为中的一个符号。sdata或。sbss部分,以确保偏移有效
5.8.5间接寻址模式
间接寻址模式使用存储在通用寄存器中的32位值作为有效内存地址。例如
R2 = memub(R1) // load R2 with unsigned byte from addr R1
5.8.6 带偏移量的间接
带偏移量的间接寻址模式将有符号偏移量值添加到通用寄存器值来创建32位有效内存地址。例如:
R2 = memh(R3 + #100) // load R2 with signed halfword
// from [R3 + 100 bytes]
当用汇编语言表示时,偏移值始终指定字节偏移量通用寄存器值。请注意,偏移量必须是指令数据类型。
表5-7列出了带偏移寻址的间接寻址的偏移范围
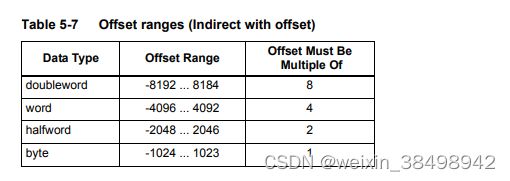
注:条件指令的偏移范围较小(第5.9节)
5.8.7 带寄存器偏移的间接
间接带寄存器偏移寻址模式将32位通用寄存器值添加到对第二个32位通用寄存器执行算术左移位所产生的结果值乘以2位无符号立即数中指定的量,形成32位
有效内存地址。例如
R2 = memh(R3+R4<<#1) // load R2 with signed halfword
// from [R3 + (R4 << 1)]
寄存器值始终指定字节地址。
5.8.8 具有自动增量立即数的间接
具有自动增量的间接即时寻址模式使用存储在中的32位值指定有效内存地址的通用寄存器。然而,地址是访问时,将有符号值(称为增量)添加到寄存器,以指定不同的内存地址(将在后续指令中访问)。例子:
R2 = memw(R3++#4) // R3 contains the effective address
// R3 is then incremented by 4
当用汇编语言表示时,增量值始终指定字节偏移量从通用寄存器值。请注意,偏移量必须是大小的整数倍指令数据类型的。
表5-8列出了具有自动增量立即数的间接增量范围寻址
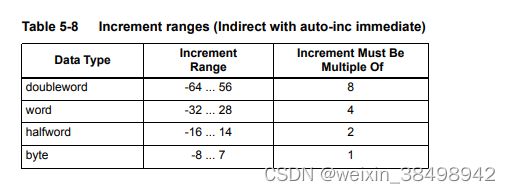
5.8.9 带自动递增寄存器的间接
间接自动递增寄存器寻址模式在功能上等效于具有自动增量立即数的间接,但使用修改器寄存器Mx(第2.2.4节)而不是立即值来保持增量。例如 :
R2 = memw(R0++M1) // The effective addr is the value of R0.
// Next, M1 is added to R0 and the result
// is stored in R0
当使用修改器寄存器自动递增时,增量是有符号的32位值已添加到普通登记册。与自动增量相比,这有两个优点立即:
- 更大的增量范围
- 可变增量(因为修改器寄存器可以在运行时编程)
增量值始终指定距通用寄存器值的字节偏移量。
注意:所有指令数据类型的有符号32位增量范围都是相同的(双字、字、半字、字节)
5.8.10 具有自动增量立即数的循环
带自动增量立即寻址模式的循环是带自动增量寻址–它以模环绕方式访问数据缓冲区。循环寻址通常用于数据流处理。
循环寻址用带有地址修饰符的汇编语言表示“:circ(Mx)”,其中Mx指定修改器寄存器,该寄存器编程为指定循环缓冲器(第2.2.4节)。例如
R0 = memb(R2++#4:circ(M0)) // load from R2 in circ buf specified
// by M0
memw(R2++#8:circ(M1)) = R0 // store to R2 in circ buf specified
// by M1
循环寻址通过编程以下元素来设置:
- Mx寄存器的长度字段设置为循环的长度(以字节为单位)
要访问的缓冲区。循环缓冲区的长度可以是4到(128K-1)字节。 - Mx寄存器的K字段始终设置为0。
- 对应于Mx的循环启动寄存器CSx(CS0表示M0,CS1表示M1)
设置为循环缓冲区的起始地址。
在循环寻址中,在按照通用寄存器,通用寄存器按立即增量值递增,然后
按循环缓冲区长度进行模化,以实现缓冲区的环绕访问。当用汇编语言表示时,增量值始终指定字节偏移量从通用寄存器值。请注意,偏移量必须是大小的整数倍指令数据类型的。
表5-9列出了具有自动增量立即数的圆形的增量范围寻址

编程循环缓冲区时,适用以下规则:
- 起始地址必须与缓冲区元素的本机访问大小对齐。
- ABS(增量)<长度。增量的绝对值必须小于缓冲区长度。
- 访问大小<(长度-1)。内存访问大小(1表示字节,2表示半字,4于字,8表示双字)必须小于(长度-1)。
- 缓冲区不得环绕在32位地址空间中。
注意:如果不遵循这些规则中的任何一条,则执行结果未定义。
例如,可以按如下方式设置和访问150字节的循环缓冲区
R4.H = #0 // K = 0
R4.L = #150 // length = 150
M0 = R4
R2 = ##cbuf // start addr = cbuf
CS0 = R2
R0 = memb(R2++#4:circ(M0)) // Load byte from circ buf
// specified by M0/CS0
// inc R2 by 4 after load
// wrap R2 around if >= 150
下面的C函数精确地描述了循环加法函数的行为
unsigned int
fcircadd(unsigned int pointer, int offset,
unsigned int M_reg, unsigned int CS_reg)
{
unsigned int length;
int new_pointer, start_addr, end_addr;
length = (M_reg&0x01ffff); // lower 17-bits gives buffer size
new_pointer = pointer+offset;
start_addr = CS_reg;
end_addr = CS_reg + lenth;
if (new_pointer >= end_addr) {
new_pointer -= length;
} else if (new_pointer < start_addr) {
new_pointer += length;
}
return (new_pointer);
}
5.8.11 带自动递增寄存器的循环
具有自动递增寄存器寻址模式的循环在功能上等效于具有自动递增立即数的循环,但使用寄存器而不是立即数值保持增量。
寄存器增量在循环寻址指令中使用符号I指定作为增量(而不是立即值)。例如:
R0 = memw(R2++I:circ(M1)) // load byte with incr of I*4 from
// circ buf specified by M1/CS1
当使用寄存器自动递增时,增量为有符号11位值,即加入普通注册。与循环寻址相比,这具有两个优点即时增量:
- 更大的增量范围
- 可变增量(因为增量寄存器可以在运行时编程)
循环寄存器增量值编程在修改器寄存器的I字段中Mx(第2.2.4节)作为设置循环数据访问的一部分。该寄存器字段保存有符号11位增量值。
增量值以缓冲区元素数据类型的单位表示,并为在运行时自动缩放到适当的数据访问大小。
表5-10列出了具有自动增量寄存器寻址的循环的增量范围。
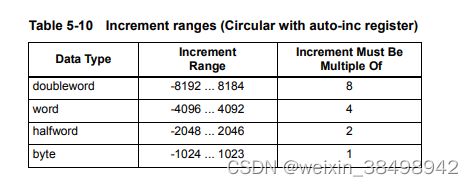
当编程循环缓冲区(使用寄存器或立即增量)时,所有必须遵循适用于循环寻址的规则–有关详细信息,请参阅第5.8.10节。
注意:如果不遵循这些规则中的任何一条,则执行结果未定义
5.8.12 用自动递增寄存器反转位
用自动递增寄存器寻址模式反转的位是间接寻址模式的变体自动增量寻址–它使用地址值访问数据缓冲区,该地址值是按位反转存储在通用寄存器中的值。使用位反转寻址在快速傅立叶变换(FFT)和维特比编码中。32位地址值的位反转定义如下:
- 低16位通过将位0与位15、位1与位1交换来转换14等等。
- 高16位保持不变。
位反向寻址用带有地址修饰符的汇编语言表示“:brev”。例如
R2 = memub(R0++M1:brev) // The address is (R0.H | bitrev(R0.L))
// The orginal R0 (not reversed) is added
// to M1 and written back to R0
地址和增量的初始值必须以位反转形式设置,并使用硬件位反转位反转地址值以形成有效地址。
位反转缓冲区的缓冲区长度必须是2的整数幂,其中最大长度为64K字节。为了支持位反转寻址,缓冲区必须在内存中正确对齐。当起始字节地址与2的幂对齐时,位反向缓冲区正确对齐大于或等于缓冲区大小(字节)。例如:
int bitrev_buf[256]_uattribute_uu((对齐(1024)));
上面声明的位反转缓冲区与1024字节对齐,因为缓冲区大小为1024字节(256个整数字 4字节),1024是2的整数幂。位反转缓冲区的缓冲区位置指针必须初始化,以使地址值的最低有效16位位位反转。增量值必须初始化为以下值:
位反转(buffer\u size\u in\u bytes/2)…其中bitreverse定义为在离开时对最低有效16位进行位反转其余位不变。
注:为了简化位反转指针、位反转缓冲区的初始化可以与64K字节边界对齐。这样做的优点是允许位反转指针,初始化为位反转的基址缓冲区,不需要对数据的最低有效16位进行位反转指针值(64K对齐方式将其全部设置为0)。
由于堆栈上分配的缓冲区仅具有8字节或更少的对齐,在大多数情况下,不应在堆栈上声明位反转缓冲区。
位反转内存访问完成后,通用寄存器递增寄存器增量值。注意,通用寄存器中的值从不受作为内存访问的一部分执行的位反转。
注:Hexagon处理器仅支持位反转的寄存器增量寻址–不支持即时增量
5.9 条件加载/存储
一些加载和存储指令可以基于断言值有条件地执行这是在以前的指令中设置的。编译器生成条件加载和存储以提高指令级并行性。
条件加载和存储用汇编语言和指令表示前缀“if(pred\u expr)”,其中pred\u expr指定断言寄存器表达式(第6.1节)。例如
if (P0) R0 = memw(R2) // conditional load
if (!P2) memh(R3 + #100) = R1 // conditional store
if (P1.new) R3 = memw(R3++#4) // conditional load
条件加载和存储并不支持所有寻址模式。表5-11显示支持哪些模式
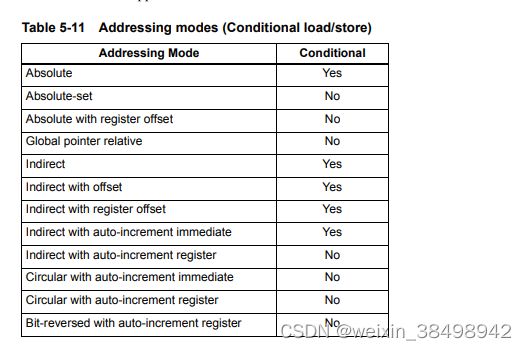
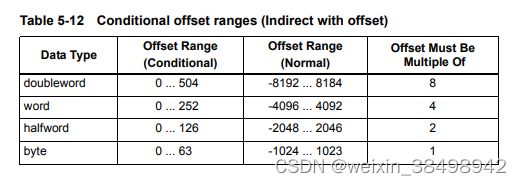
当条件加载或存储指令使用间接带偏移量寻址模式时,注意,偏移范围小于通常为带偏移寻址的间接寻址定义的范围(第5.8.6节)
表5-12列出了间接带偏移的条件和正常偏移范围寻址
5.10 高速缓存
Hexagon处理器具有基于缓存的内存架构:
- 一级指令缓存保存最近获取的指令。
- 一级数据缓存保存最近访问的数据内存。
通过1级缓存访问内存的加载/存储操作称为缓存访问。绕过1级缓存的加载/存储称为未缓存访问。可以配置特定的内存区域,以便执行缓存或非缓存访问。
此配置由Hexagon处理器的内存管理单元执行(MMU)。操作系统负责对MMU进行编程。支持两种类型的缓存(作为缓存模式):
- 直写缓存通过以下方式保持缓存数据与外部内存一致:始终将存储在缓存中的任何数据写入内存。
- 回写缓存允许数据存储在缓存中,而不需要立即写入外部存储器。与不一致的缓存数据
外部内存被称为脏内存。Hexagon处理器包括专用的缓存维护指令,可以用于将脏数据推送到外部内存.
5.10.1 未缓存内存
在某些情况下,加载/存储操作需要绕过缓存并进行维护外部(例如,当访问内存映射的输入/输出、寄存器和外围设备时设备或其他系统定义的实体)。操作系统负责配置MMU以生成未缓存的内存访问。
未缓存内存分为两种不同类型:
- 设备类型用于访问具有副作用的内存(例如内存映射的FIFO外围设备)。硬件确保中断不会取消挂起设备访问。硬件不会对设备访问进行重新排序。外围控制寄存器应标记为设备类型。
- 未缓存类型用于类似内存的内存。没有副作用与通道硬件可以多次从非缓存内存加载。这个硬件可以重新排序未缓存的访问。
对于指令访问,设备类型内存在功能上与未缓存类型相同记忆力对于数据访问,它们是不同的。
代码可以直接从二级缓存执行,绕过一级缓存。
5.10.2 紧耦合存储器
Hexagon处理器支持级别1的紧密耦合指令内存,即定义为具有与指令缓存类似的访问属性的内存。
紧密耦合的内存也支持在级别2,这是定义为备份存储到主缓存。
有关更多信息,请参阅第9章
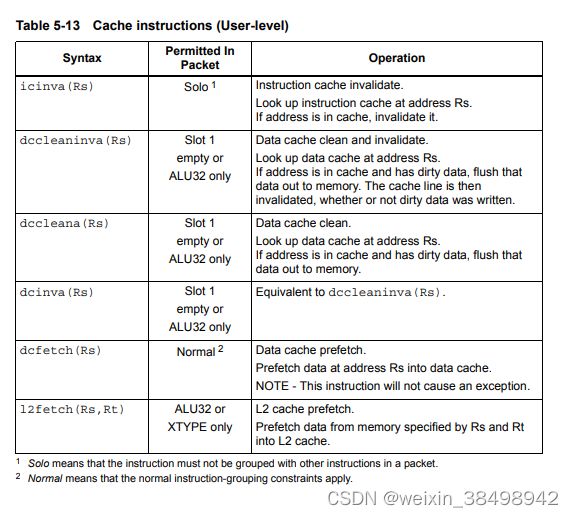
5.10.3缓存维护操作
Hexagon处理器包括专用的缓存维护指令,可以用于使缓存数据无效或将脏数据推送到外部内存。
缓存维护指令在特定内存地址上运行。如果指令导致地址错误(由于权限冲突),处理器引发错误。
注意,此规则的例外是dcfetch,它不会导致处理器错误
每当在指令缓存上执行维护操作时,isync之后必须立即执行指令(第5.11)。本说明确保按照后续说明进行维护操作。
表5-13列出了缓存维护说明
5.10.4 二级缓存操作
缓存维护操作(第5.10.3节)在一级缓存和二级缓存上运行。
数据缓存一致性操作(包括clean、invalidate和clean和失效)影响L1和L2缓存,并确保内存层次结构保持连贯性。
然而,指令缓存无效操作仅影响一级缓存。因此使一级或二级缓存中的指令失效需要两个步骤:
1.使用icinva使一级缓存中的指令无效。
2.单独使用DCINA使二级缓存中的指令失效。
5.10.5 缓存线零
Hexagon处理器包括指令dczeroa。此指令分配一行并将其清除(通过存储所有零)。行为如下:
- Rs寄存器值必须32字节对齐。如果未对齐,处理器将引发未对齐的错误异常。
- 在缓存命中的情况下,指定的缓存线被清除(即,使用所有零)并弄脏。
- 如果缓存未命中,则不会从外部获取指定的缓存线记忆力相反,该行在数据缓存中分配、清除并变脏。
此指令在优化只写数据时非常有用。它允许使用回写页面是最强大、性能最高效的页面,无需最初提取要写入的行。这消除了不必要的读取带宽和延迟。
注意dczeroa与写回存储具有相同的异常行为。具有dczeroa的数据包的插槽1必须为空或包含ALU32指令。
5.10.6 缓存预取
Hexagon处理器支持以下类型的缓存预取:
- 基于硬件的指令缓存预取
- 基于软件的数据缓存预取
- 基于软件的L2FETCH
- 基于硬件的数据缓存预取
基于硬件的指令缓存预取
可以在每个线程的基础上启用或禁用一级和二级指令缓存预取–这是通过在用户状态寄存器中设置HFI字段来实现的(第2.2.3节)。
基于软件的数据缓存预取
Hexagon处理器包括指令dcfetch。此指令查询L1基于指令中指定的地址的数据缓存:
- 如果该地址存在于缓存中,则不采取任何操作。
- 如果地址的缓存线缺失,处理器会尝试填充缓存
来自下一级内存的行。请注意,线程不会暂停,而是在后台进行缓存线填充时继续执行。 - 如果地址无效,则不会生成异常,并且dcfetch指令为被视为NOP。
基于软件的二级拿取
l2fetch提供了更强大的二级预取(数据或指令)指令,指定由Hexagon预取的内存区域处理器的硬件预取引擎。l2fetch将两个寄存器(Rs和Rt)指定为操作数。Rs包含要预取的内存区域的32位虚拟起始地址。Rt包含三个位字段,进一步指定内存区域:
- Rt[15:8]–宽度,指定内存块的宽度(以字节为单位)取来
- Rt[7:0]–高度,指定要获取的宽度大小的块的数量。
- Rt[31:16]–步长,指定用于获取每个宽度大小的块后,增加指针。
l2fetch指令是非阻塞的:它启动一个预取操作当线程继续执行时,由预取引擎在后台执行Hexagon处理器说明。
预取引擎请求指定内存区域中的所有行。如果兴趣已经驻留在二级缓存中,预取引擎不执行任何操作。如果行不在二级缓存中,预取引擎会尝试提取它们。
预取引擎尽最大努力预取请求的数据,并尝试以低于按需回迁的优先级执行预回迁。这可以防止预取当系统处于重载状态时,发动机不会增加公交车流量。
如果程序执行l2fetch指令,而从以前的l2fetch仍处于活动状态,预取引擎停止当前的预取操作。
注:在任何位字段操作数编程为零的情况下执行l2fetch将取消所有预取活动。
当前预取操作的状态保存在用户的PFA字段中状态寄存器(第2.2.3节)。此字段可用于确定预取操作已完成。
关于MMU权限和错误检查,l2fetch指令的行为类似于加载指令。如果虚拟地址导致处理器异常,则例外情况将被接受。(请注意,这与dcfetch指令不同,后者是在存在转换/保护错误的情况下被视为NOP。)
注意:当生成的预取地址位于与起始地址不同的页面。程序员必须充分使用大页面以确保不会发生这种情况。
图5-2显示了使用l2fetch指令的两个示例。第一个显示一个“盒子”预取,即在较大的帧内定义二维内存范围。第二个示例显示了大小为(行*128)的大型线性内存区域的预取。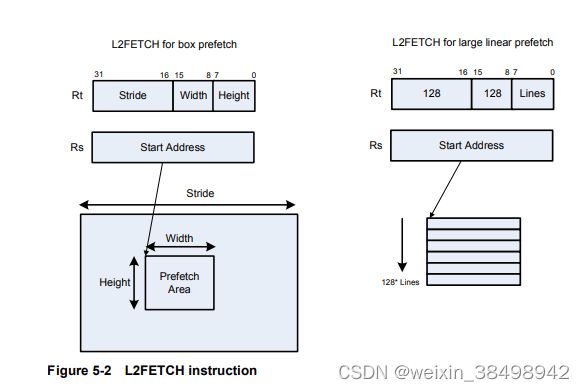
基于硬件的数据缓存预取
一级数据缓存预取可以在每个线程的基础上启用或禁用–这是可以做到的通过在用户状态寄存器中设置HFD字段(第2.2.3节)。
当启用数据缓存预取时,Hexagon处理器观察数据模式缓存未命中,并尝试根据任何循环模式预测未来的未命中未命中,其中地址由恒定步长分隔。如果发现这种模式,处理器尝试自动预取未来的缓存线。
数据缓存预取可以在四个攻击性级别由用户启用:
- HFD=00:无预取
- HFD=01:对于源自负载的未命中,预取多达4行,采用硬件环路内发生的更后寻址模式
- HFD=10:预取多达4条线路,以确定发生的负载引起的未命中在硬件环路内
- HFD=11:预取多达8条线路,用于来自负载的未命中
5.11 内存排序
一些设备在访问时可能需要同步存储和负载。在里面在这种情况下,一组处理器指令使程序员能够控制同步以及内存访问的顺序。
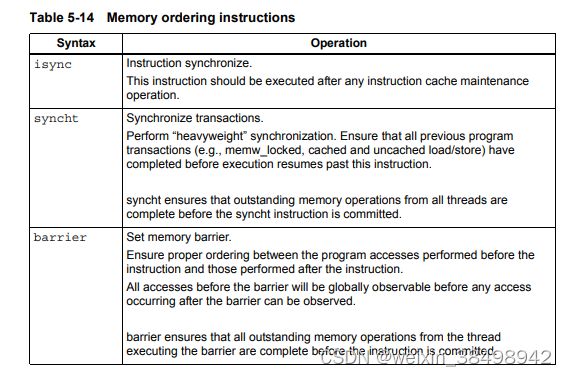
表5-14列出了内存排序说明。
数据内存访问和程序内存访问分别处理并保存在单独的缓存。如果出现以下情况,必需的软件应确保数据和程序代码之间的一致性
例如,对于生成的或自修改的代码,修改后的代码将放置在数据缓存和可能与程序缓存不一致。软件必须明确强制修改数据缓存线到内存(通过使用直写策略或
通过显式缓存清理指令)。然后应使用屏障指令来确保门店完工。最后,相关指令缓存内容应无效,以便重新获取新指令。
下面是建议更改并执行指令的代码序列:
ICINVA(R1) // clear code from instruction cache
ISYNC // ensure that ICINVA is finished
MEMW(R1)=R0 // write the new instruction
DCCLEANINVA(R1) // force data out of data cache
SYNCHT // ensure that it’s in memory
JUMPR R1 // can now execute code at R1
注意:内存排序指令不得与其他指令分组指令,否则行为未定义。
此代码序列不同于以前处理器版本中使用的代码序列
5.12 原子操作
Hexagon处理器包括一个LL/SC(负载锁定/存储条件)机制提供实现所需的原子读修改写操作同步原语,如信号量和互斥量。
这些原语用于同步不同软件程序的执行在Hexagon处理器上并发运行。它们还可以用于提供原子Hexagon处理器和外部块之间的内存支持。
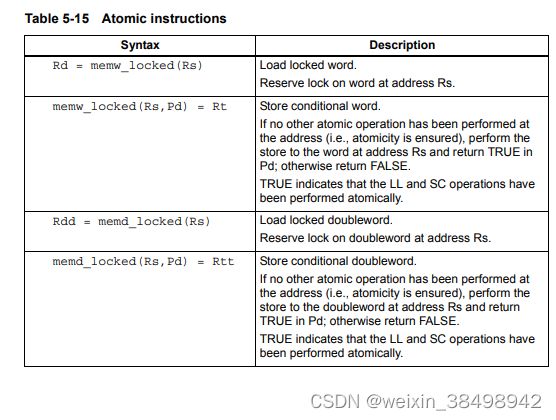
表5-15描述了原子指令
下面是获取互斥锁的推荐代码序列:
// assume R1,R3,P0,P1 are scratch
lockMutex:
R3 = #1
lock_test_spin:
R1 = memw_locked(R0) // do normal test to wait
P1 = cmp.eq(R1,#0) // for lock to be available
if (!P1) jump lock_test_spin
memw_locked(R0,P0) = r3 // do store conditional (SC)
if (!P0) jump lock_test_spin // was LL and SC done atomically?
下面是释放互斥锁的推荐代码序列:
// assume mutex address is held in R0
// assume R1 is scratch
R1 = #0
memw(R0) = R1
使用AXI总线的外部访问支持原子memX_锁定操作并支持原子操作。要使用外部内存执行负载锁定操作,操作系统必须将内存页定义为不可缓存,否则处理器行为未定义。
如果在不支持原子的地址上执行加载锁定操作操作时,行为未定义。对于可缓存内存上的原子操作,页面属性必须设置为可缓存并写回,否则行为未定义。必须使用可缓存内存当线程需要彼此同步时。
注:AHB总线不支持外部memX_锁定操作。如果他们在AHB总线上执行,行为未定义