极智AI | Nvidia Jetson DLA 硬件系统架构
欢迎关注我的公众号 [极智视界],获取我的更多笔记分享
大家好,我是极智视界,本文介绍一下 Nvidia Jetson DLA 硬件系统架构。
NV 的硬件应用广泛,不限于3D图形渲染、AI计算等,而 Jetson 系列是 NV 边缘计算领域的设备主力军。在 Jetson AGX Xavier、Jetson NX 等设备上有 DLA 模块,DLA 全称 Deep Learning Accelerator,是专门用于卷积神经网络前向推理加速的模块,它能够分担一部分边缘端 GPU 的计算压力,以提升系统能力处理能力。所以在这些设备上,你可选择的算法加速方式有 GPU 加速 和 DLA 加速。这里咱们专门来讲讲 NVDLA。
文章目录
-
- 1 总体架构介绍
- 2 功能模块介绍
-
- 2.1 Convolution Core
- 2.2 Single Point Data Processor
- 2.3 Planar Data Processor
- 2.4 Cross Channel Data Processor
- 2.5 RUBIK
- 2.6 BDMA
1 总体架构介绍
DLA 的系统架构分为 Small NVDLA System 和 Large NVDLA System,如下。其中 Small NVDLA System 主要面向成本敏感的物联网设备场景,而当更加强调高性能时,Large NVDLA System 会是更加好的选择。可以看到两者最大的区别在 SRAM 和 Microcontroller,Large NVDLA 的访存接口有 SRAM 和 DRAM,其中 SRAM 接口独立存在,可以进一步提升 DLA 的运算能力,这是由于 DRAM 的访存延时相对较长,且与片上众多处理器共享带宽,这个时候这块独立的 SRAM 可以有效降低系统带宽压力,提高处理效率。

更细的,面向卷积神经网络的加速,NVDLA 可以细化成如下模块:
- Convolution Core:优化的高性能卷积引擎;
- Single Data Processor:用于激活函数单点查找引擎;
- Planar Data Processor:用于池化 pooling 平面平均引擎;
- Channel Data Processor:用于归一化 normalization 多通道平均引擎;
- 专用的 Memory and Data Reshape Engines:用于张量整形、复制操作的内存到内存转换加速引擎;
DLA 内核的一个清晰的硬件架构差不多是这样的:

2 功能模块介绍
2.1 Convolution Core
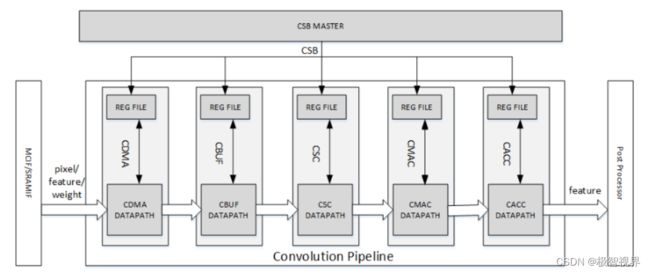
Convolution Pipeline 有五个阶段,分别是:Convolution DMA、Convolution Buffer、Convolution Sequence Controller、Convolution MAC 和 Convolution Accumulator,支持 direct convolution、Winograd 卷积加速、Deconvolution、Multi-Batch Mode 等。其中:
-
Convolution DMA:用于从 SRAM/DRAM 中获取数据进行卷积操作,并按照卷积引擎所需的顺序将其存储到缓冲区 (CBUF) 中;
-
Convolution Buffer:卷积缓冲区(CBUF)它总共包含 512KB 的 SRAM。SRAM 缓存来自 CDMA 模块的
输入像素数据、特征数据、权重数据,并由 CSC 模块读取,CBUF 有两个写端口和三个读端口;
-
Convolution Sequence Controller:卷积序列控制器(CSC)负责从 CBUF 加载输入特征数据、像素数据和权重数据,并将其发送到卷积 MAC 单元;
-
Convolution MAC:用于从卷积序列控制器(CSC)接收输入数据和权重,执行乘法和加法,并将结果输出到卷积累加器,CMAC 有 16 个 MAC 单元,每个 MAC 单元包含 64 个用于 int16/fp16 的 16 位乘法器,另外它还包含 72 个用于 int16/fp16 的加法器;
-
Convolution Accumulator:用于从卷积 MAC 累加部分和,并在发送到 SDP 之前对结果进行四舍五入 (The final result of accumulator in CACC is 48bits for INT16 and 34bits for INT8);
2.2 Single Point Data Processor
支持 Bias addition、non-linear function,如 sigmoid function、relu、hyperbolic tangent、BN、elementwise 等,有几个功能块,每个功能块都有不同的用途:
- 可以从 MEM 或 Conv Core 中选择输入数据;
- Block X1/X2 具有相同的架构;
- Block Y 主要是为 element-wise 设计的,但它也能够支持 Bias add,PReLU 和一个额外的 LUT 操作,可以在输出之前选择以实现任何非线性操作;
- Block C1/C2 用于额外的缩放和偏移以节省位,同时保持高精度;

2.3 Planar Data Processor
PDP 支持最大、最小和平均池化方法。一个平面内的几个相邻输入元素将被发送到一个非线性函数用于计算一个输出元素。
2.4 Cross Channel Data Processor
通道处理旨在解决局部响应归一化 (LRN) 层。局部响应归一化通过沿通道方向对局部输入区域进行归一化来执行一种横向抑制。归一化函数如下所示:

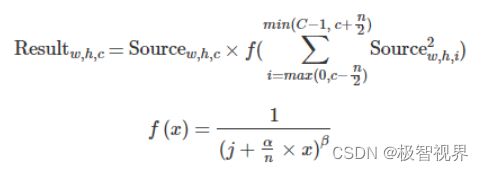
上面两个方程可以通过编程相应的寄存器来绕过,以便将 CDP 视为独立的查找表 (LUT) 。
2.5 RUBIK
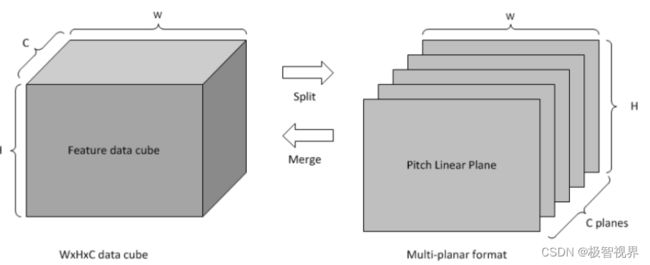
RUBIK 模块类似于 BDMA。它在不进行任何数据计算的情况下转换数据映射格式:
- contract data cube (deconv);
- split feature data cube into multi-planar formats;
- merge multi-planar formats to data cube;
2.6 BDMA
为了利用片上 SRAM,NVDLA 需要在外部 DRAM 和 SRAM 之间移动数据,可以使用 BDMA 来满足这一目的。有两种移动的路径,一种是将数据从外部 DRAM 复制到内部 SRAM,另一种是将数据从内部 SRAM 复制到外部 DRAM,当然这两个方向是不能同时工作的。
BDMA 还可以将数据从外部 DRAM 移动到外部 DRAM,或从内部 SRAM 移动到内部 SRAM。为了移动立方体中的所有数据,BDMA 支持行重复,可以在多行之间进行跳转。
好了,以上分享了 NV Jetson DLA 硬件系统架构,希望我的分享能对你的学习有一点帮助。
【公众号传送】
《极智AI | NVIDIA Jetson DLA 硬件系统架构》

扫描下方二维码即可关注我的微信公众号【极智视界】,获取我的更多经验分享,让我们用极致+极客的心态来迎接AI !
