联邦学习综述:概念与应用
联邦学习:概念与应用
现在的人工智能仍然面临两个挑战:数据孤岛和数据安全。本文介绍一种综合型安全联邦学习框架,包括横向联邦学习、纵向联邦学习和联邦迁移学习。这里介绍定义、结构和应用,提供了相关工作的调研。
一、简介
人工智能发展迅速,但是逐渐显现其缺陷。在很多领域中,数据都是有限的,而且质量不高,因此可以考虑将不同组织的数据进行融合并公用。 由于企业竞争、隐私和复杂的管理过程,信息的聚合很困难,甚至开销很高。
世界政府对数据安全的要求越来越高,制定了很多政策,使得数据公用传输面临挑战。
传统的数据处理模型是一方收集并将数据传输到另一方,另一方对数据进行融合和清洗,之后第三方获取融合后的数据并继续帮助模型的建立,这样的方法面临着约束和挑战。
因此提出了联邦学习,将AI发展的注意力更多放在了数据整合和数据安全与隐私政策。
二、联邦学习概述
联邦学习的基本思想是建立一个基于数据库的机器学习模型,可以在多个设备并部署数据并防止信息泄露。谷歌提出了联邦学习的概念,最近的研究主要是克服统计挑战? 和 提高安全性。需要优化的一些方面有大型分布的通信费用、不平衡的数据分布设备依赖性等。数据通过设备ID或用户ID进行划分,在数据空间是横向的?
2.1 联邦学习定义
定义N个数据持有者 { F 1 , . . . , F N } \{F_1, ..., F_N\} {F1,...,FN},其都想通过各自的数据 { D 1 , . . . , D N } \{D_1, ..., D_N\} {D1,...,DN}训练一个机器学习模型。传统方法是将所有数据放在一起,用 D = D 1 ⋃ . . . ⋃ D N D=D_1{\bigcup}...{\bigcup}D_N D=D1⋃...⋃DN训练一个模型 M S U M M_{SUM} MSUM。联邦学习系统则是将所有持有者的数据进行整合训练一个模型 M F E D M_{FED} MFED的过程,其所处理的持有者数据都不向其它持有者披露。 M F E D M_{FED} MFED的准确率是 V F E D V_{FED} VFED,和 M S U M M_{SUM} MSUM及其准确率 V S U M V_{SUM} VSUM的性能应该很接近。假设 δ \delta δ是非负实数,若:
∣ V F E D − V S U M ∣ < δ |V_{FED}-V_{SUM}|<\delta ∣VFED−VSUM∣<δ
我们认为联邦学习算法拥有 δ \delta δ准确率损失。
2.2 联邦学习的隐私
安全多方计算(Secure Multiparty Computation,SMC):
SMC模型提供完全0知识的框架,也就是说每方只知道自己的输入和输出。0知识很可靠,但是经常需要复杂的计算协议,效率不高。一些情境下,有安全保证的情况下允许部分。最近,[46]采用SMC框架训练机器学习模型,有两个服务器和半诚实假设,MPC协议在[33]中在不揭露用户敏感信息的情况下来训练模型和认证。SMC的一种SOTA框架叫Sharemind[8],[44]的作者提出一个3PC模型[5, 21, 45],兼顾半诚实和恶意假设,这些工作要求参与者的数据在非共谋方之间秘密地共享服务器。
差分隐私(Differential Privacy):
其它工作采用差分隐私(或K匿名)做隐私保护(differential privacy, k-anonymity or diversification)。包括向数据添加噪声,使用泛化方法来模糊敏感属性,直到第三方无法识别身份,从而使得数据不能存储来保护用户隐私。然而,这些方法根本上仍然需要数据传输,需要在准确率和隐私之间做出权衡。差分隐私用来添加到用户方数据,其在训练时隐藏用户信息。
同态加密(Homomorphic Encryption):
同态加密通过在机器学习的过程中采用加密机制进行参数交换来保护用户信息。和差分隐私不同,数据和模型不会被传输,它们也不会被其他方获得的数据猜测到。因此在原始数据层面上不易泄露,近些年多用于在云中聚集和训练数据。实际应用中,可加同态加密是使用最广泛的,多项式估计用来评估机器学习算法中的非线性函数,导致需要在准确性和隐私性之间进行权衡。
2.2.1 非直接信息披露
实际上一些如梯度参数的信息等也可能泄露数据结构,例如图像像素等等。但是会有其它用户恶意攻击在系统中开后门的情况,一种“限制和尺度”毒化攻击方法用来防止数据毒化。研究表明攻击者可以通过训练数据的子集推断成员身份和属性。还有采用区块链作为联邦学习的平台,用区块链来交换和验证移动设备的本地模型更新。
2.3 联邦学习的分类
矩阵 D i D_i Di表示第 i i i个数据拥有者的数据,矩阵的每行代表一个样本,每列代表一种特征,当然有些数据有标签信息。一个数据训练集可以表示为 ( I , X , Y ) (I,X,Y) (I,X,Y)。联邦学习可以根据两方特征和样本空间ID的分布分为横向联邦学习、纵向联邦学习和迁移联邦学习。
2.3.1 横向联邦学习
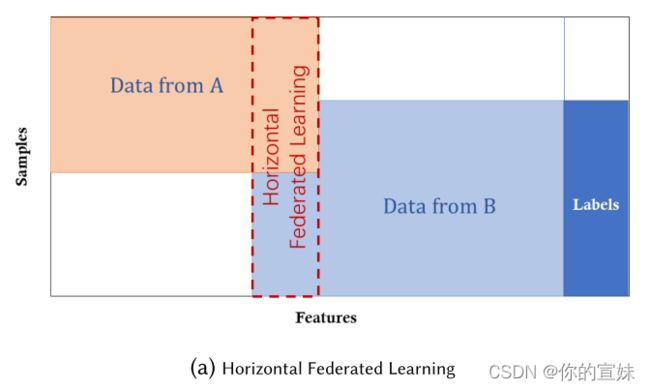
数据集共享相同特征空间,但是不同的样本空间,如下图所示。例如,两个地方的银行在各自的地区有不同的用户群体,它们的交集可能非常小,然而,他们的业务很相似,所以特征空间是相同的。
横向联邦学习中,只有服务器可以保证参与者的数据隐私。其隐私保障还是有挑战的,在训练结束后,全局模型和所有模型的参数会暴露给所有的参与者。
2.3.2 纵向联邦学习
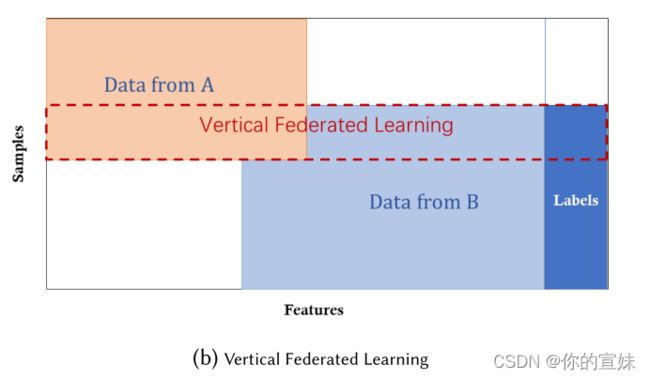
横向联邦学习适用于样本空间相同但特征空间不同的数据,例如在同一城市有两个公司,一个是银行,一个是电子商务,他们的用户都是这个区域大部分居民的数据,用户空间的交集很大,但是银行记录的是存款、开支情况和信用率,电商记录的是用户浏览和购买的记录,特征空间非常不同。假设两方都想建立一个产品购买的预测模型,纵向联邦学习是整合两方不同特征和计算训练损失梯度,并安全计算的过程。
假设两方是不相关的,只有一方受到攻击,攻击方只能获得被攻击用户的信息而不是从其他用户输入输出之外获得信息。为了加强两方的安全计算,会引入半诚实第三方(Semi-Host Third Party, STP),STP和任意一方都没联系。安全多方计算(SMC)为这些原则提供了一般的隐私保护。学习结束后,每方不仅拥有那些和自己特征相关的模型,两方也需要整合产生输出。
2.3.3 联邦迁移学习(FTL)
联邦迁移学习应用在两个数据库不仅样本空间不同,而且特征空间也不同的情境下。假设一个在中国的银行和另一个在美国的电商公司,两者地理条件不同,用户群体交集也很小,另外业务也不同,特征交集也很小。可以采用迁移学习的技术,为整个样本和特征空间提供联邦。采用有限的公共样本集合学习两个特征空间的公共表达和采用单边样本获取预测结果,FTL是联邦学习中的重要拓展,因为其解决的问题是其它联邦学习未解决的。其安全原则和纵向联邦学习很像。

2.4 联邦学习的系统结构
横向联邦学习和纵向联邦学习的结构是非常不同的。
2.4.1 横向联邦学习
横向联邦学习的结构如下图所示,k个有相同数据结构的参与者一起学习一个机器学习模型,有一个参数云服务器。一般假设参与者都是honest的,服务器是honest但curious的。因此,任何参与者和服务器都不会泄露信息,训练过程包含以下四步:
- 参与者在本地训练梯度,采用加密掩盖梯度,差分隐私或者加密共享技术,然后将加密结果传给服务器。
- 服务器在不知道任何参与者信息的情况下整合学习信息。
- 服务器返回给每个参与者整合结果。
- 参与者用解密梯度更新各自的模型。
上面的结构通过SMC或同态加密来防止信息纰漏,但是也可能会遭到采用GAN恶意攻击的参与者。

2.4.2 纵向联邦学习
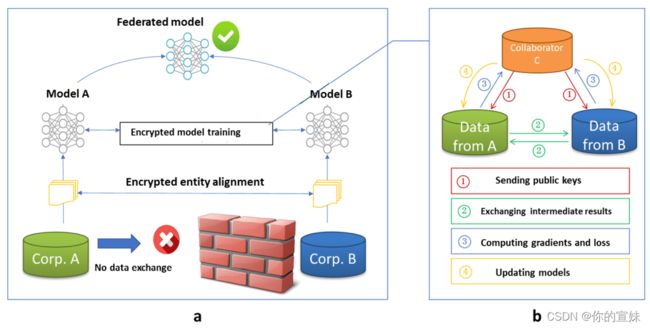
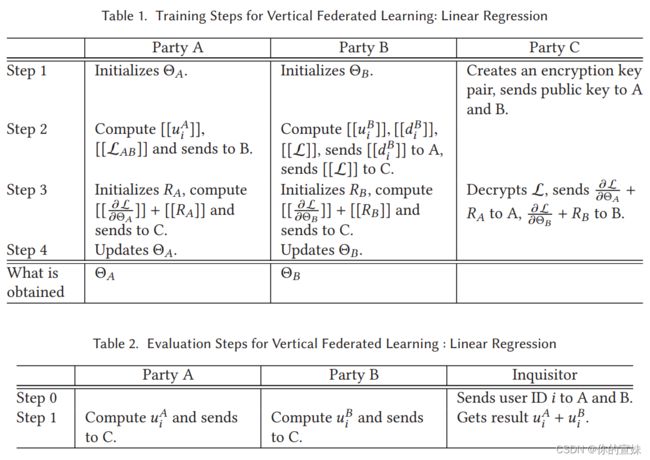
假设A和B联合训练一个机器学习模型,每个企业都有自己的数据,另外企业B有模型预测的标签数据。为了确保安全性,引入一个第三方C,假设C诚实且与A、B没有联系,但A和B诚实但对彼此感兴趣。
第一部分: 加密实体对齐,找到A和B共同的而用户并相互公开其数据,非重叠的数据不公开。
第二部分: 加密模型训练,确定公共数据后,可以用公共数据训练模型,训练过程有以下四个部分:
- C向A和B发送公钥对用于加密
- A和B加密并交换梯度和损失的中间结果
- A和B计算解密后的梯度并各自添加另外一个掩码,B计算loss,A和B将加密结果传给C
- C加密并将梯度和损失传回AB,AB去掉掩码后采用该梯度更新模型。
我们的目标loss如下:
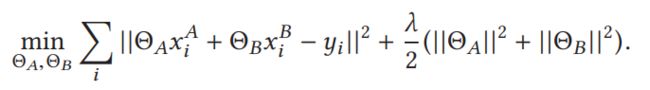

可以看出,A和B在一开始只有loss的一部分,还有一部分需要外部计算。
在此过程中,A不能通过等式8了解任何B的信息,B也是。
2.4.3 联邦迁移学习
例子和上面纵向联邦学习相同,A和B的交集很小,想在A整个数据集上用标签学习。结构和上面的相同,但是这里不是采用重叠部分的数据,而是想利用全局数据,上面的结构中改变的是A和B的交互信息。迁移学习用来学习A和B的共同特征表示,采用B的标签最小化A的标签预测误差。
2.4.4 激励机制
模型建立之后,模型的效果在实际应用非常显著。这些性能可以采用永久数据存储机制记录(如区块链)。系统的性能取决于不同机构的贡献,需要激励更多的机构加入到联邦中。因此联邦学习是一个”闭环“学习机制。
三、相关工作
3.1 隐私保护机器学习
很多机器学习算法都有安全机制,很多都使用SMC进行隐私保护。
3.2 联邦学习和分布式机器学习
分布式学习有很多方面,包含训练数据存储的分布、计算任务操作的分布、模型结果的分布等等。参数服务器是分布式学习的典型元素,其能加快训练过程。横向联邦学习中,工作节点指的是信息持有者,参数服务器负责控制,联邦学习的学习环境更为复杂。研究表明,使用本地非IID数据,联邦学习性能会大大降低,可以采用迁移学习解决此问题。
3.3 联邦学习和边缘计算
联邦学习也可以看作边缘计算的一种操作系统,因为其提供学习安全准则。
3.4 联邦学习和联邦数据库系统
联邦数据库系统连克多个数据库作为一个整体进行管理,可以实现多个独立数据库的操作,采用分布式存储,其和联邦学习的数据存储类型很相似,但是联邦数据库系统没有安全保证机制。联邦数据库的目的是对数据增删改查等操作,而联邦学习则是在保护数据隐私的前提下共同建立联合模型以供使用。
四、应用
联邦学习适用于在涉及知识版权、隐私保护和数据保护等因素时,不能直接集成训练机器学习模型的情景。
以商场零售为例,其想要使用机器学习模型为用户提供个人服务,包含产品推荐和销售服务等。该产业数据特征可能包含用户的购买力、个人喜好和产品特点等。实际应用中,这三个特征都可能分散在公司不同部门,比如用户购买力可能通过银行存款推断,个人喜好可能通过社交网络,产品特点在电子商城中记录。
这样的情景下,我们面临两个问题:第一是用户数据隐私的保护,银行、社交网络和电商网站是由数据阻碍的,不能直接放在一起训练模型;其次三方数据存储形式各异,传统机器学习不能直接学习不同形态的数据。
联邦学习能在不泄露隐私保证安全的情况下学习模型,对各方来说都是有利的。同时还可以采用迁移学习解决数据不统一的问题,在AI学习领域是一大突破。
联邦学习可以用来在不泄露数据的情况下进行多数据库的查询。比如说,金融应用程序中,会有恶意多方借贷,从一家银行借钱支付另外一家银行的贷款。为了找到这样的用户,但不泄露AB银行的用户列表,我们可以采用联邦学习框架,特别是可以采用联邦学习的加密机制,在每一方对用户列表进行加密,在联邦中取加密列表的交集,最终解密结果只有恶意贷款名单,而不会暴露诚信用户的信息。这样的情况是在纵向联邦学习框架中经常出现的。
智能医疗是另外一个应用领域,涉及疾病、基因和报告等数据非常敏感,很难手机,并且在医疗中心和医院中孤立。数据源不足而且缺乏标签使得模型效果并不理想,如果所有医院都把数据用于训练,效果会大大提升,迁移学习能够填补缺失的标签,通过扩展数据规模以进一步提升模型效果。
五、联邦学习和企业联盟
随着数据隐私安全和公司收益与数据关系的增加,云计算模型需求增大。联邦学习为大数据应用提供了新的范式,能让企业以不交换数据的形式联合训练模型,联邦学习还能通过一些公平规则进行利益分配,如区块链的激励机制。