linux awk 命令使用详解
前言
awk是linux的一个强大的命令,具备强大的文本格式化能力,比如对一堆看起来没有什么规律的日志文件,文本文件等,通过awk命令之后,格式化输出为专业的可以做为应用级数据分析的样式;
awk像是一门编程语言,支持条件判断,数组,循环等诸多的功能;
linux三剑客
- grep,擅长单纯的查找或匹配文本内容;
- sed,擅长文本编辑,处理匹配到的文本内容;
- awk,适合格式化文本文件,对文本文件进行更复杂的加工处理、分析;
awk理论基础
1、awk语法
awk [option] 'pattern[action]' file ...
awk 参数 条件动作 文件

action 是指动作,awk擅长文本格式化,且能输出格式化后的结果,因此最常用的动作就是 print 和 printf
2、awk处理文本内容模式
- awk默认以空格为分隔符,且多个空格也识别为一个空格,作为分隔符;
- awk按行处理文件,一行处理完毕之后,再处理下一行;
- awk可以根据用户指定的分隔符去工作,没有指定,则默认为空格;
一、awk内置变量
| 内置变量 | 说明 |
|---|---|
| $n | 指定分隔符后,当前的第n个列所在的字段 |
| $0 | 完整的一行记录 |
| FS | 字段分隔符,默认是空格 |
| NF(Number of fields) | 字段分隔后,当前一共多少个字段 |
| NR(Number of records) | 当前记录数,行数 |
更多的内置变量,可通过 man awk命令进行查看
简单案例展示
提前准备一个文本,内容如下

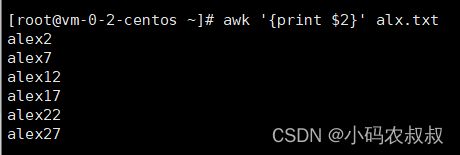
1、输出第二列内容
awk '{print $2}' alx.txt
2、输出多列内容
直接在第一步后面的基础上追加,中间用 “,” 分割
awk '{print $2,$3}' alx.txt

3、查看第三行内容
考察对NR的使用,NR表示第N行记录的模式匹配
awk 'NR==3{print $0}' alx.txt

输出多行
awk 'NR==5,NR==6{print $0}' alx.txt

4、输出从第3到第五行,并显示行号
awk 'NR==3,NR==5 {print NR,$0}' alx.txt

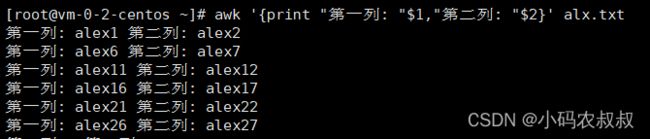
5、自定义输出内容
某些情况下,需要给每一列添加类似于excel的表头信息,就可以考虑使用awk的自定义输出;
awk '{print "第一列: "$1,"第二列: "$2}' alx.txt
需要注意的是大括号外面的使用 ’ 单引号,括号里面的使用双引号
二、awk参数
| 参数 | 说明 |
|---|---|
| -F | 指定分隔字段符 |
| -v | 定义或修改一个awk内部变量 |
| -f | 从脚本文件中读取awk命令 |
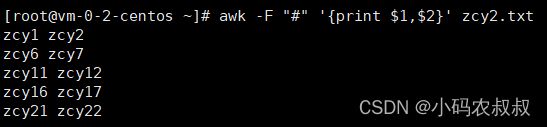
上文谈到,awk默认的字段分隔符为空格,但是像下面这样的文本,以 # 为分隔符,就需要用到自定义分隔符;

1、显示第一列和第二列内容
awk -F "#" '{print $1,$2}' zcy2.txt
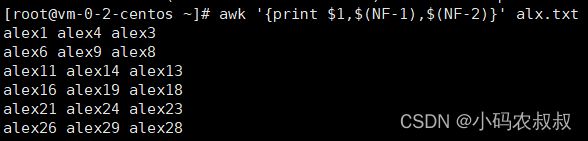
2、显示文件第一列,倒是第一列,和倒数第二列的内容
awk '{print $1,$(NF-1),$(NF-2)}' alx.txt
3、取出本机的IP地址

使用awk的方式获取的话,如果以空格为分隔符,我们发现目标字段在第二行的第二列,使用下面的命令即可,看起来,比起sed和grep命令似乎更简单;
ifconfig eth0 | awk 'NR==2{print $2}'

4、取出密码文件中的第一列和最后一列
考察对自定义输入分隔符的使用,可以看到,下面的文本文件中,可以考虑使用 : 进行分割;
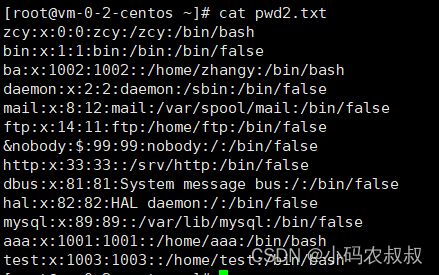
awk -F ':' '{print $1,$NF}' pwd2.txt

三、OFS输出分隔符
通过上文的学习,我们知道awk命令执行后,默认采用空格分割字段,而这个空格就是默认的输出分割符,
单在某些情况下,为了将数据展示的效果更加醒目一些,就可以使用OFS的自定义输出分隔符;
仍然以上面的密码文本为例,输出第一列和最后一列的字段;
awk -F ':' -v OFS=' *** ' '{print $1,$NF}' pwd2.txt
该表默认输出分隔符,直接在awk后面使用: -v OFS=‘自定义输出分隔符’

四、awk变量
awk参数
| 参数 | 说明 |
|---|---|
| -F | 指定分隔字段符 |
| -v | 定义或修改一个awk内部变量 |
| -f | 从脚本文件中读取awk命令 |
对于awk来讲,变量分为:内置变量和自定义变量
awk内置变量
| 参数 | 说明 |
|---|---|
| FS | 输入字段分隔符,默认为空白字符 |
| OFS | 输出字段分隔符,默认为空白字符 |
| RS | 输入记录分隔符,指定输入时的换行符 |
| ORS | 输出记录分隔符,输出时用指定符号替换换行符 |
| NF | 当前行的字段个数,字段数量 |
| NR | 行号,当前处理文本行的行号 |
| FNR | 各文件分别计数的行号 |
| FILENAME | 当前文件名 |
| ARGC | 命令行参数个数 |
| ARGV | 数组,保存的是命令行所给定的各个参数 |
比较常用的内置变量包括: NR,NF,FNR
FILENAME 使用
FILENAME 为awk的内置变量,通过下面这个命令,可以看到在每行记录之前,输出了当前文件名称;
awk 'NR==1,NR==3{print FILENAME,$0}' alx.txt

ARGV使用
先来看下面这条命令的执行结果
awk 'NR==1,NR==3{print ARGV[0],ARGV[1],$0}' alx.txt

可以发现,在输出的每一行记录前面,拼上了 awk 和 alx.txt这两个字段,这两个字段就是这行命令整体解析出来的2个内置参数;
自定义变量
看下面这条命令输出效果,通过-v参数,可以自定义变量进行参数传递;
awk -v myname="zcy" 'BEGIN{print "我的名字是?" ,myname}'
![]()
五、awk格式化输出
在上文,我们接触的是awk的输出功能,主要使用了 print 这个进行输出,它只能对文本进行简单的输出,但是并不能美化或者修改输出格式;
printf 格式化输出
如果对C语言有过了解的同学,对printf 并不陌生,使用这个命令(函数)可以对文本进行格式化输出;
printf与print的几点区别
- printf 需要指定format;
- format 用于指定后面的每个 item输出格式;
- printf 语句不会自动打印换行符; \n ; print 默认添加换行符;
如下,假如我们直接使用 printf 这样操作,看下效果
awk '{printf $0}' alx.txt
![]()
明显来说,把所有内容都输出到同一行了,这时候,就需要使用 printf的格式化输出来控制;
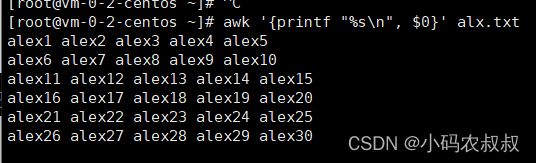
awk '{printf "%s\n", $0}' alx.txt
再看一个案例,使用 printf 将文本中的每一列添加前置输出
awk '{printf "第一列:%s 第二列:%s 第三列:%s\n" ,$1,$2,$3}' alx.txt

六、awk模式pattern
上文了解到,awk的语法如下 :
awk [option] ‘pattern[action]’ file …
而且我们了解到,awk是按行处理文本,以上都是关于 print 相关,接下来,聊聊pattern相关的内容;
在pattern中,有个比较常见的pattern,BEGIN和END;
- BEGIN 模式是处理文本之前需要执行的动作;
- END模式是处理完成所有的行之后执行的操作;
awk 'BEGIN{print "小明在学linux"}'

或者下面这样
awk 'BEGIN{print "小明在学linux"} {print $0}END{print "处理结束"}' alx.txt
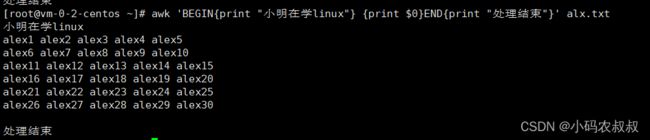
注意:BEGIN 和 END分别放到处理文本内容前后即可
awk如果不指定模式是按行处理,如果指定了模式,只有符合模式的才会被处理
awk常用模式
| 关系运算符 | 说明 |
|---|---|
| < | 小于 |
| <= | 小于等于 |
| == | 等于 |
| != | 不等于 |
| >= | 大于等于 |
| ~ | 匹配正则 |
| !~ | 不匹配正则 |
1、打印前三行的文本内容
awk 'NR<=3{print $0}' alx.txt

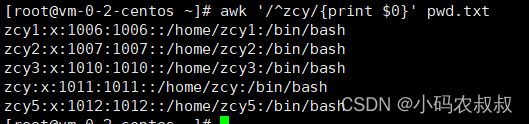
2、匹配密码文本中含有 zcy 的行
awk '/^zcy/{print $0}' pwd.txt
3、格式化输出 /etc/passwd 的部分字段
awk -F ":" 'BEGIN{print"用户名\t\t\t字段1\t\t 字段2\t\t 权限"} {printf "user:%-20s%-20s%-20s%-20s\n", $1,$4,$5,$7}' pwd.txt
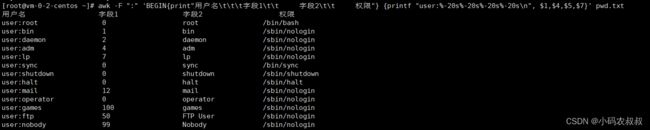
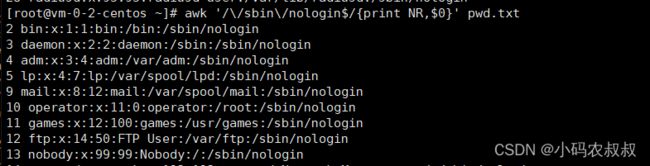
4、找出pwd文件中nologin的用户

awk '/\/sbin\/nologin$/{print NR,$0}' pwd.txt
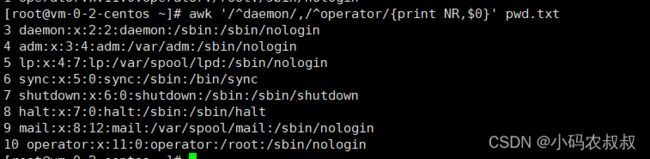
5、找出 下面这个区间的文本行

awk '/^daemon/,/^operator/{print NR,$0}' pwd.txt
七、综合案例:统计nginx的access.log中访问前10的IP

首先来看下该日志文件中的内容格式,简单分析得知,该文件中的内容的每一行,可以看作是由空格分割的,于是可以考虑使用awk来完成需求;

可能用到的额外几个命令
- sort -n ,数字从大到小排序;
- wc -l ,统计行数;
1、访问日志中的访客IP数量
awk '{print $1}' access.log | sort -n | uniq | wc -l

2、查访问最频繁的前10个IP
awk '{print NR,$1}' access.log | sort -n | uniq -c | sort -nr | head -10
