burpsuite字典_从头开发一个BurpSuite数据收集插件
一段时间没写公众号了,最近写了个 burpsuite 数据收集的插件,于是想出一篇从头编写一个 burpsuite 插件的教程。 这个插件的目的收集 burpsuite 请求中的数据,如请求中的子域名、文件名、目录名、参数名等,保存到数据库,然后根据出现的次数进行排序,出现次数多的排在前面,从而强化我们的字典。 插件效果演示 先来看看插件的效果图:
 该插件会在 burp 上面新建一个标签页,用来保存一些配置,如数据库 ip 地址、端口、账号密码等。 还可以从数据库导出数据到文件作为字典,或者从文件中导入数据到数据库中,用于和别人分享及备份数据库。 导出的文件效果如下:
该插件会在 burp 上面新建一个标签页,用来保存一些配置,如数据库 ip 地址、端口、账号密码等。 还可以从数据库导出数据到文件作为字典,或者从文件中导入数据到数据库中,用于和别人分享及备份数据库。 导出的文件效果如下: 
 导出的字典文件是 txt 文件,主要是作为字典来使用,其中的内容是根据出现的次数来排序的, 如 /test/ 目录在 a.baidu.com 出现了一次,然后在 b.baidu.com 出现了一次,那么它的 count 值就是 2 。 目录在不同网站出现的次数越多,那么排名就会越前,证明该目录是最常现出的,因此应该把它放在前面提高命中率。 同理,对于请求中的参数名、文件名、子域名等数据,也是通过出现的次数来排序。 上图中,导出的还有 csv 文件,该文件含有出现的次数,可以通过该文件通过插件导入其它数据库,以实现备份或分享的功能。 插件开发 现在开始插件的开发,开发插件需要些前置的知识。 编写 burpsuite 插件需要对 Java 或 Python 语言有一定的基础,在这里我使用的是 Java,因为 Java 编写的插件在 burpsuite 加载得更快,性能更好。 在这里我使用的开发环境是 IDEA ,因为 IDEA 的智能补全功能就像知道我想打什么代码一样,十分强大。 在 IDEA 新建一个 gradle 项目,点击 Create New Project
导出的字典文件是 txt 文件,主要是作为字典来使用,其中的内容是根据出现的次数来排序的, 如 /test/ 目录在 a.baidu.com 出现了一次,然后在 b.baidu.com 出现了一次,那么它的 count 值就是 2 。 目录在不同网站出现的次数越多,那么排名就会越前,证明该目录是最常现出的,因此应该把它放在前面提高命中率。 同理,对于请求中的参数名、文件名、子域名等数据,也是通过出现的次数来排序。 上图中,导出的还有 csv 文件,该文件含有出现的次数,可以通过该文件通过插件导入其它数据库,以实现备份或分享的功能。 插件开发 现在开始插件的开发,开发插件需要些前置的知识。 编写 burpsuite 插件需要对 Java 或 Python 语言有一定的基础,在这里我使用的是 Java,因为 Java 编写的插件在 burpsuite 加载得更快,性能更好。 在这里我使用的开发环境是 IDEA ,因为 IDEA 的智能补全功能就像知道我想打什么代码一样,十分强大。 在 IDEA 新建一个 gradle 项目,点击 Create New Project  选择 Gradle 项目, Gradle 是一个构建工具,可以方便加载所需的代码仓库。 点击下一步。
选择 Gradle 项目, Gradle 是一个构建工具,可以方便加载所需的代码仓库。 点击下一步。  给项目起个名称
给项目起个名称
 新建完后,在 build.gradle 文件中添加以下依赖,也就是加载 burpsuite 插件API ,如果提示 auto import, 可以点击,从而自动从远程仓库加载 burpsuite API 。
新建完后,在 build.gradle 文件中添加以下依赖,也就是加载 burpsuite 插件API ,如果提示 auto import, 可以点击,从而自动从远程仓库加载 burpsuite API 。
 接着在 /src/main/java 目录处创建一个名为 burp 的包名,在 java 目录处右键 -> New -> Package
接着在 /src/main/java 目录处创建一个名为 burp 的包名,在 java 目录处右键 -> New -> Package 
 接着在该包上右键,新建一个名为 BurpExtender 的类。
接着在该包上右键,新建一个名为 BurpExtender 的类。 
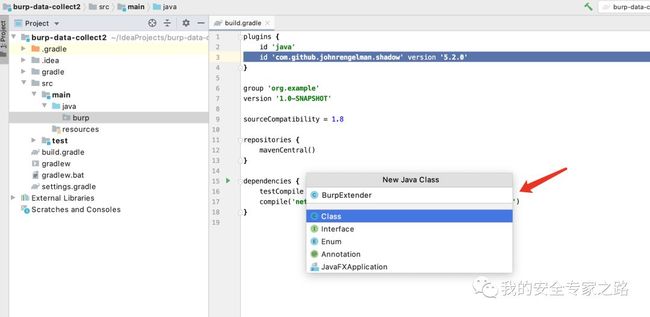 这个包名和类名是固定的,burpsuite 加载插件时就是通过 burp.BurpExtender 来查找的,如果不这样起名,会报 ClassNotFoundException 。 BurpExtender 类需要实现 IBurpExtender 接口,burp 在加载插件时,会调用该接口,并传递 IBurpExtenderCallbacks 接口仅我们使用。 点击错误提示,实现接口中的方法
这个包名和类名是固定的,burpsuite 加载插件时就是通过 burp.BurpExtender 来查找的,如果不这样起名,会报 ClassNotFoundException 。 BurpExtender 类需要实现 IBurpExtender 接口,burp 在加载插件时,会调用该接口,并传递 IBurpExtenderCallbacks 接口仅我们使用。 点击错误提示,实现接口中的方法 
 然后我们添加下面的代码为插件设置名称,并打印一 success 字符串
然后我们添加下面的代码为插件设置名称,并打印一 success 字符串
 接着可以编译该项目成 jar 包,然后让 burp 加载看看效果。 点击右侧的 gradle 菜单,展开菜单,双击 shadowjar ,gradle 会自动编译项目成 jar 包,jar 包位于 build 目录中的 libs 目录中。
接着可以编译该项目成 jar 包,然后让 burp 加载看看效果。 点击右侧的 gradle 菜单,展开菜单,双击 shadowjar ,gradle 会自动编译项目成 jar 包,jar 包位于 build 目录中的 libs 目录中。  接着在 burp 的扩展选项卡添加该 jar 包,点击 add
接着在 burp 的扩展选项卡添加该 jar 包,点击 add 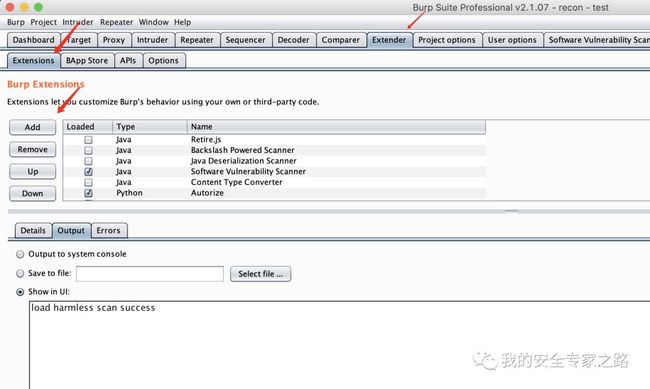 选择 Java 扩展类型,选择我们的 jar 包,点击下一步
选择 Java 扩展类型,选择我们的 jar 包,点击下一步  可以看到加载插件后成功打印了 success 字符串。
可以看到加载插件后成功打印了 success 字符串。  添加标签页 接着我们要为插件创建一个标签页,先在IDEA中创建一个 Form,用于设计UI
添加标签页 接着我们要为插件创建一个标签页,先在IDEA中创建一个 Form,用于设计UI 
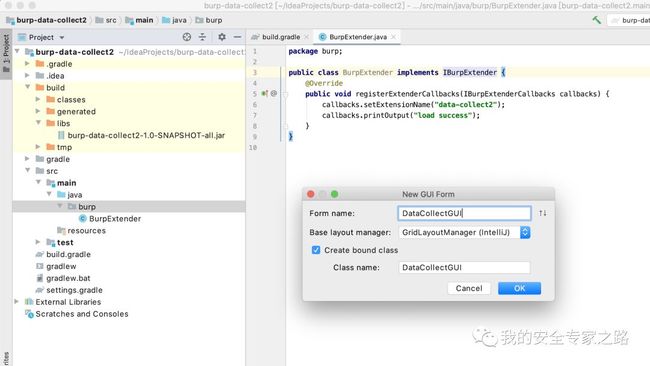 创建的界面如下,左边的窗口中创建了两个文件,一个是 DataCollectGUI.java 文件,该文件与 form 文件绑定,一个是 DataCollectGUI.form 文件,可以在此文件上拖动控件来设计 UI 界面,当界面更新时,会自动生成代码插入 DataCollectGUI.java 文件中。
创建的界面如下,左边的窗口中创建了两个文件,一个是 DataCollectGUI.java 文件,该文件与 form 文件绑定,一个是 DataCollectGUI.form 文件,可以在此文件上拖动控件来设计 UI 界面,当界面更新时,会自动生成代码插入 DataCollectGUI.java 文件中。  接着从右边拖一个 JLabel(标签)、一个 JTextField(输入框)和 JButton(按钮) 到设计面板中,效果如下:
接着从右边拖一个 JLabel(标签)、一个 JTextField(输入框)和 JButton(按钮) 到设计面板中,效果如下:  然后给根面板设置个变量名,用于后面生成代码:
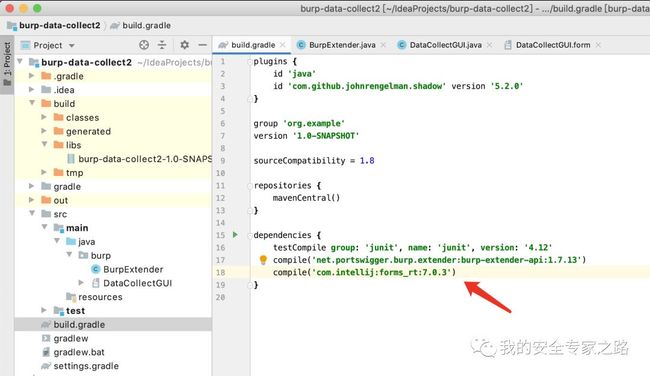
然后给根面板设置个变量名,用于后面生成代码:  为了让 IDEA 打包 GUI 界面的类,需要在 build.gradle 添加以下依赖
为了让 IDEA 打包 GUI 界面的类,需要在 build.gradle 添加以下依赖
 接着在设置中设置根据 Form 界面自动生成 Java 源码:
接着在设置中设置根据 Form 界面自动生成 Java 源码: 
 然后在 Gradle 的编译选项中设置编译器是 IDEA 自带的编译器,这样才能自动更新 form 文件中的控件到代码中:
然后在 Gradle 的编译选项中设置编译器是 IDEA 自带的编译器,这样才能自动更新 form 文件中的控件到代码中:  设置好后,点击构建图标,就会自动生成和 form 文件相关的代码,可以看到在 $$$setupUI$$$() 方法中自动生成了我们拖到界面中的3个控件。 注意,$$$getRootComponent$$$() 方法需要给界面中的JPanel 控件设置变量名才可以生成,参考上面的步骤。
设置好后,点击构建图标,就会自动生成和 form 文件相关的代码,可以看到在 $$$setupUI$$$() 方法中自动生成了我们拖到界面中的3个控件。 注意,$$$getRootComponent$$$() 方法需要给界面中的JPanel 控件设置变量名才可以生成,参考上面的步骤。  接着需要回到 BurpExtender 类中,要为插件添加一个标签页,需要实现 ITab 接口
接着需要回到 BurpExtender 类中,要为插件添加一个标签页,需要实现 ITab 接口  实现 ITab 接口后,会有两个方法需要实现,其中 getTabCaption() 方法返回标签页的名称, getUiComponent() 方法返回我们创建的 UI 面板。 注意,需要在14行下调用 callbacks.addSuiteTab(this) 来注册接口。 接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,就可以看到效果图了:
实现 ITab 接口后,会有两个方法需要实现,其中 getTabCaption() 方法返回标签页的名称, getUiComponent() 方法返回我们创建的 UI 面板。 注意,需要在14行下调用 callbacks.addSuiteTab(this) 来注册接口。 接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,就可以看到效果图了:  获取标签页设置内容 接下来我们需要获取标签页中的配置内容,可以通过添加事件监听器来实现。 回到 IDEA 的 form 文件中,在按钮上右键,点击 Create Listener,选择 ActionListener
获取标签页设置内容 接下来我们需要获取标签页中的配置内容,可以通过添加事件监听器来实现。 回到 IDEA 的 form 文件中,在按钮上右键,点击 Create Listener,选择 ActionListener 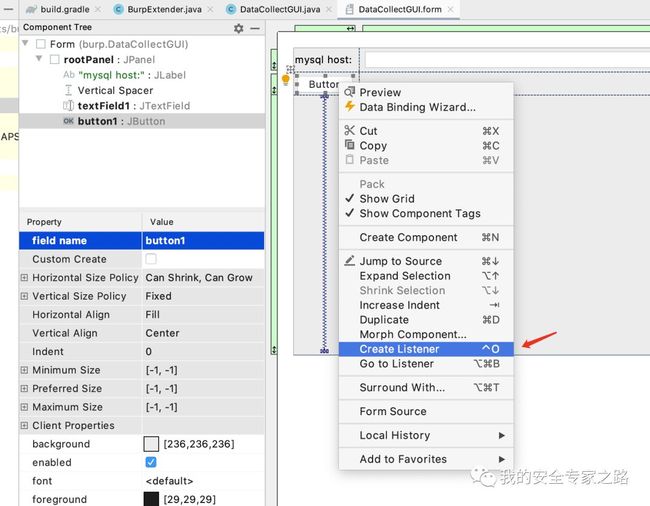
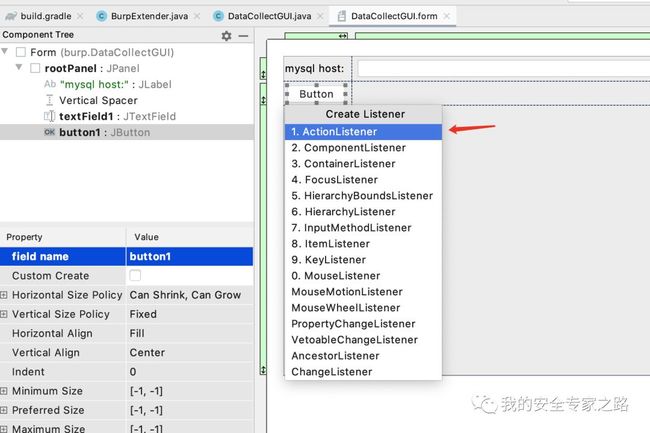 创建好后就可以编写点击按键时的代码逻辑了
创建好后就可以编写点击按键时的代码逻辑了  在这里简单地把输入框中的内容打印在插件日志中,要把内容打印到插件日志中,我们需要获取 IBurpExtenderCallbacks 对象,可以修改构造函数,在初始化时传入:
在这里简单地把输入框中的内容打印在插件日志中,要把内容打印到插件日志中,我们需要获取 IBurpExtenderCallbacks 对象,可以修改构造函数,在初始化时传入:  还需要修改 BurpExtender 中的代码,传入 callbacks 对象
还需要修改 BurpExtender 中的代码,传入 callbacks 对象 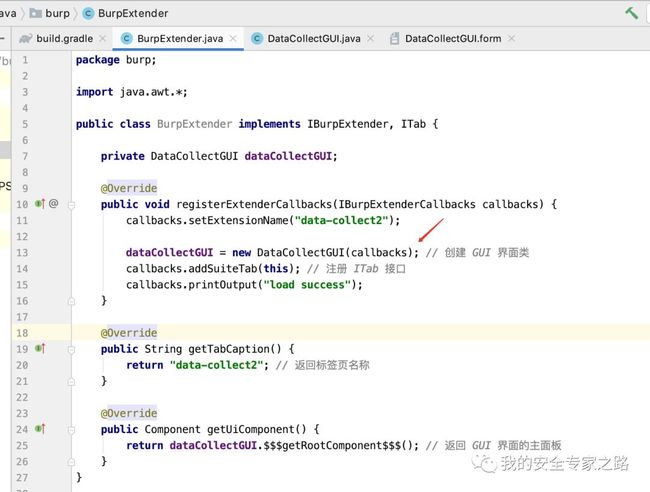 接着在监听器中实现获取标题内容并打印到日志的代码,代码中29行通过 getText()方法获取输入框架的内容,然后在30行处通过 callbacks.printOutput()方法打印内容到日志中。
接着在监听器中实现获取标题内容并打印到日志的代码,代码中29行通过 getText()方法获取输入框架的内容,然后在30行处通过 callbacks.printOutput()方法打印内容到日志中。  接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,在插件输入框中输入 hello world, 点击按钮,就会在插件日志中打印输入框中的内容了。
接着双击 gradle 中的 shadowjar 按钮重新打包 jar 包,然后在 burp 重新加载插件,在插件输入框中输入 hello world, 点击按钮,就会在插件日志中打印输入框中的内容了。 
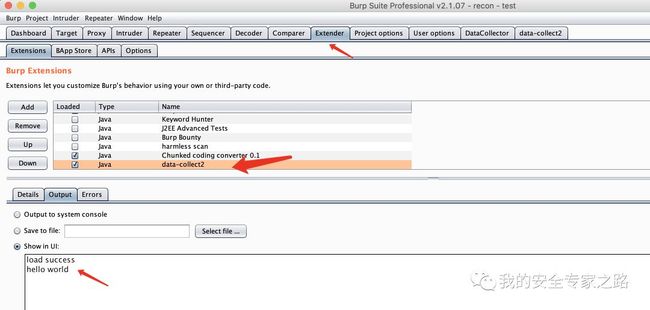 到此,我们可以获取插件输入框中的内容,这样我们就可以开始开发数据收集的插件了。 开发核心功能 由于插件代码比较多,这里就不一一介绍了,先导入开发完成的代码,可以到我的 github 上下载: https://github.com/QdghJ/burp_data_collector 使用 IDEA 导入项目
到此,我们可以获取插件输入框中的内容,这样我们就可以开始开发数据收集的插件了。 开发核心功能 由于插件代码比较多,这里就不一一介绍了,先导入开发完成的代码,可以到我的 github 上下载: https://github.com/QdghJ/burp_data_collector 使用 IDEA 导入项目 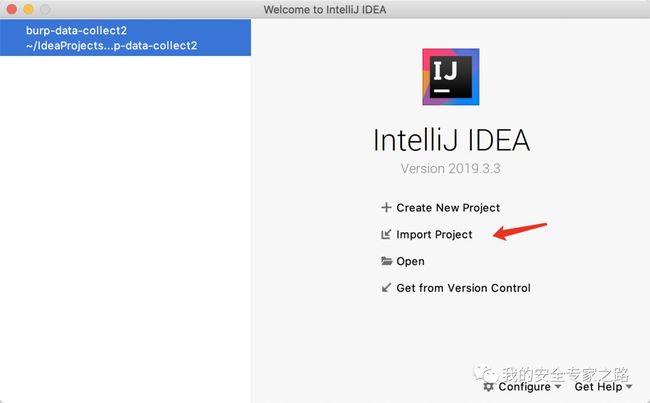 选择 gradle 项目
选择 gradle 项目  导入后,我们来看看开发数据收集插件需要用到哪些库,首先需要 mysql 的 jdbc 驱动,然后是导出 csv 文件时用到的库:
导入后,我们来看看开发数据收集插件需要用到哪些库,首先需要 mysql 的 jdbc 驱动,然后是导出 csv 文件时用到的库:  接着来看看项目的文件结构,在 dao 包中的主要是数据库的操作类,封装了数据库操作的代码,每个表一个类来插入和查询数据。 而 gui 包中的就是界面类。
接着来看看项目的文件结构,在 dao 包中的主要是数据库的操作类,封装了数据库操作的代码,每个表一个类来插入和查询数据。 而 gui 包中的就是界面类。  核心要点 这个插件的核心要点如下:
核心要点 这个插件的核心要点如下:
 接着在 361 行处从 path 中分离出目录,如 /aaa/bbb/ccc/, 那么会收集 /aaa/, /bbb/, /ccc/ 。 接着在 370 行处收集文件名, 如 /js/jquery.js, 那么会收集 jquery.js 。 然后在 376 行处分离主机名,也就是分离域名,只获取子域名,如域名是 aa.bb.cc.dd.ee ,那么会收集先收集分离后的子域名,如 aa, bb, cc, 然后收集 aa.bb.cc, bb.cc, cc 几个子域名。
接着在 361 行处从 path 中分离出目录,如 /aaa/bbb/ccc/, 那么会收集 /aaa/, /bbb/, /ccc/ 。 接着在 370 行处收集文件名, 如 /js/jquery.js, 那么会收集 jquery.js 。 然后在 376 行处分离主机名,也就是分离域名,只获取子域名,如域名是 aa.bb.cc.dd.ee ,那么会收集先收集分离后的子域名,如 aa, bb, cc, 然后收集 aa.bb.cc, bb.cc, cc 几个子域名。  最后在 400 行处获取请求中的所有参数,402 行处的 2 代表 cookie 参数名,暂时不收集 cookie, 然后收集符合条件的参数名。
最后在 400 行处获取请求中的所有参数,402 行处的 2 代表 cookie 参数名,暂时不收集 cookie, 然后收集符合条件的参数名。 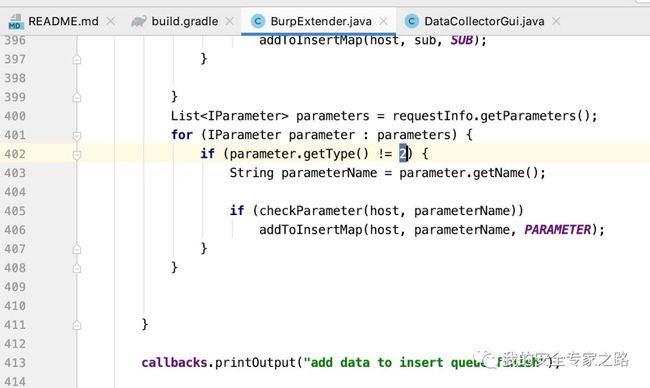 数据库设计 数据库设计主要包括表结构的设计,导出语句的的设计,插入语句的设计。 数据库的设计对性能的影响很大,开始时我写的SQL语句收集一次数据需要20分钟,经过做开发的朋友改进后,只需1秒,所以写数据库代码就是写SQL语句。 首先是表的设计,本次要收集的数据上面已经介绍过,主要的表如下:
数据库设计 数据库设计主要包括表结构的设计,导出语句的的设计,插入语句的设计。 数据库的设计对性能的影响很大,开始时我写的SQL语句收集一次数据需要20分钟,经过做开发的朋友改进后,只需1秒,所以写数据库代码就是写SQL语句。 首先是表的设计,本次要收集的数据上面已经介绍过,主要的表如下: 
 表的类型有两种,一种是 host_xxx_map 表,如 host_dir_map 表用于收集 host 信息及其对应的内容,表的字段有 host 和 dir ,上图可以看出 0.gravatar.com 这个 host 对应的目录有3个。 另一种表如,dir 表,用于导入 csv 文件中的数据,表的字段是 dir , count,分别是目录名和出现的数目,主要用于导入别人导出的 dir_import.csv, 当导出数据时,会合并这种表中的数据,再进行导出。 创建表的代码在 dao/DatabaseUtil 类中
表的类型有两种,一种是 host_xxx_map 表,如 host_dir_map 表用于收集 host 信息及其对应的内容,表的字段有 host 和 dir ,上图可以看出 0.gravatar.com 这个 host 对应的目录有3个。 另一种表如,dir 表,用于导入 csv 文件中的数据,表的字段是 dir , count,分别是目录名和出现的数目,主要用于导入别人导出的 dir_import.csv, 当导出数据时,会合并这种表中的数据,再进行导出。 创建表的代码在 dao/DatabaseUtil 类中  接下来说下插入数据时的语句,插入数据时应该怎么处理呢,我一开始的时候设计的是这样的: 假设要插入一条数据, host 值是 www.baidu.com, dir 值是 /js/ 下面是伪代码
接下来说下插入数据时的语句,插入数据时应该怎么处理呢,我一开始的时候设计的是这样的: 假设要插入一条数据, host 值是 www.baidu.com, dir 值是 /js/ 下面是伪代码
 具体的导出代码如下:
具体的导出代码如下: 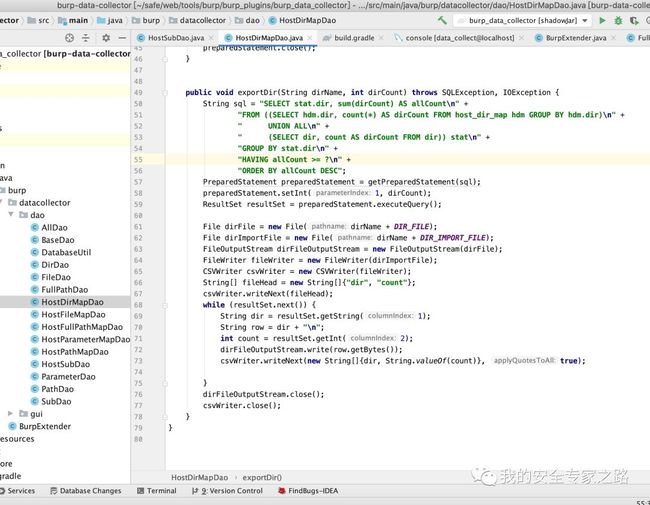 内存去重 插件是可以定时获取请求内容中的数据并插入数据库的,但每次定时操作时,不知道数据是否插入过数据库了,如果每次都插入全部数据到数据库,还是会影响性能。 因此有必要在每插入一个数据的时候,在内存中记录下该数据已经被插入,在第二次定时收集的时候,遇到已经插入过数据库的数据,就可以跳过此数据。 在内存中检查比在数据库中快很多,这样在导出一次全量的数据后,第二次定时收集的时候会快很多,因为只需要收集新出现的请求。 具体怎样实现呢? 我们需要使用 HashMap 和 HashSet 数据结构相结合。 HashMap 是一个键值对数据结构,也就是一个哈希桶,可以把一些键值对保存到该结构中进行快速查找。 HashSet 是一个集合,里面的数据是不重复的元素,也就是说 ,里面只会出现 aa,bb,cc ,而不会出现 aa,aa,bb,cc。 我们可以组合两个数据结构来实现保存 host 对应的 dir 。 具体结构如下图:
内存去重 插件是可以定时获取请求内容中的数据并插入数据库的,但每次定时操作时,不知道数据是否插入过数据库了,如果每次都插入全部数据到数据库,还是会影响性能。 因此有必要在每插入一个数据的时候,在内存中记录下该数据已经被插入,在第二次定时收集的时候,遇到已经插入过数据库的数据,就可以跳过此数据。 在内存中检查比在数据库中快很多,这样在导出一次全量的数据后,第二次定时收集的时候会快很多,因为只需要收集新出现的请求。 具体怎样实现呢? 我们需要使用 HashMap 和 HashSet 数据结构相结合。 HashMap 是一个键值对数据结构,也就是一个哈希桶,可以把一些键值对保存到该结构中进行快速查找。 HashSet 是一个集合,里面的数据是不重复的元素,也就是说 ,里面只会出现 aa,bb,cc ,而不会出现 aa,aa,bb,cc。 我们可以组合两个数据结构来实现保存 host 对应的 dir 。 具体结构如下图: 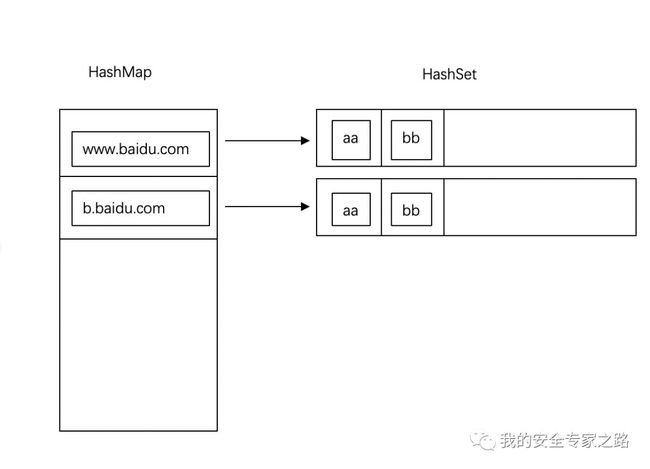 上图中,www.baidu.com 是一个键,对应的值是一个 hashset 结构,hashset里面装有这个 host 所有的目录。 由于有多个表的内容要保存,只要加多一层 HashMap 就可以实现保存所有表了。
上图中,www.baidu.com 是一个键,对应的值是一个 hashset 结构,hashset里面装有这个 host 所有的目录。 由于有多个表的内容要保存,只要加多一层 HashMap 就可以实现保存所有表了。 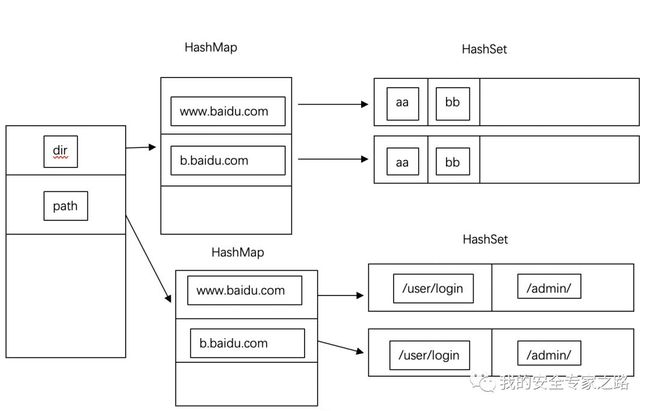 具体实现代码如下:
具体实现代码如下:
 checkDir() 函数调用 addToMemory() 函数判断内存中是否存在该数据了
checkDir() 函数调用 addToMemory() 函数判断内存中是否存在该数据了  回到上面的367行处,接着调用 addToInsertMap() 函数把数据保存到插入队列中,addToInsertMap() 函数和 addToMemory() 相似,区别是只保存新增的数据:
回到上面的367行处,接着调用 addToInsertMap() 函数把数据保存到插入队列中,addToInsertMap() 函数和 addToMemory() 相似,区别是只保存新增的数据:  在 saveData() 函数的最后会取出内存中保存的新增数据,一次性插入数据库中:
在 saveData() 函数的最后会取出内存中保存的新增数据,一次性插入数据库中:  小细节 这个插件比较方便的是会定时保存数据以及在退出 burp 时保存数据。 定时保存数据使用 ScheduledExecutorService 对象定时执行任务:
小细节 这个插件比较方便的是会定时保存数据以及在退出 burp 时保存数据。 定时保存数据使用 ScheduledExecutorService 对象定时执行任务:
 插件的开发到这里就完成了,具体的实现可以下载源码来查看,喜欢我的文章的可以关注下我的公众号,以后可能会继续发些工具开发的文章。 https://github.com/QdghJ/burp_data_collector 这个插件的开发要感谢我的基友,让我的数据库性能得到了极大的提升。
插件的开发到这里就完成了,具体的实现可以下载源码来查看,喜欢我的文章的可以关注下我的公众号,以后可能会继续发些工具开发的文章。 https://github.com/QdghJ/burp_data_collector 这个插件的开发要感谢我的基友,让我的数据库性能得到了极大的提升。
往期文章python协程学习——写个并发获取网站标题的工具一些相见恨晚的BurpSuite插件推荐
该插件会在 burp 上面新建一个标签页,用来保存一些配置,如数据库 ip 地址、端口、账号密码等。 还可以从数据库导出数据到文件作为字典,或者从文件中导入数据到数据库中,用于和别人分享及备份数据库。 导出的文件效果如下: 导出的字典文件是 txt 文件,主要是作为字典来使用,其中的内容是根据出现的次数来排序的, 如 /test/ 目录在 a.baidu.com 出现了一次,然后在 b.baidu.com 出现了一次,那么它的 count 值就是 2 。 目录在不同网站出现的次数越多,那么排名就会越前,证明该目录是最常现出的,因此应该把它放在前面提高命中率。 同理,对于请求中的参数名、文件名、子域名等数据,也是通过出现的次数来排序。 上图中,导出的还有 csv 文件,该文件含有出现的次数,可以通过该文件通过插件导入其它数据库,以实现备份或分享的功能。 插件开发 现在开始插件的开发,开发插件需要些前置的知识。 编写 burpsuite 插件需要对 Java 或 Python 语言有一定的基础,在这里我使用的是 Java,因为 Java 编写的插件在 burpsuite 加载得更快,性能更好。 在这里我使用的开发环境是 IDEA ,因为 IDEA 的智能补全功能就像知道我想打什么代码一样,十分强大。 在 IDEA 新建一个 gradle 项目,点击 Create New Project 选择 Gradle 项目, Gradle 是一个构建工具,可以方便加载所需的代码仓库。 点击下一步。 给项目起个名称
新建完后,在 build.gradle 文件中添加以下依赖,也就是加载 burpsuite 插件API ,如果提示 auto import, 可以点击,从而自动从远程仓库加载 burpsuite API 。
compile('net.portswigger.burp.extender:burp-extender-api:1.7.13')id 'com.github.johnrengelman.shadow' version '5.2.0'callbacks.setExtensionName("data-collect2");callbacks.printOutput("load success");compile('com.intellij:forms_rt:7.0.3')- 解析功能,解析请求中的各种数据,然后插入到数据库中。
- 数据库设计,关键体现在查询和插入数据的性能上,在被我的开发朋友调教后,重新设计SQL语句,从导入一次数据需要十几分钟,优化到了几秒内完成。
- 内存去重,在内存中保存已经插入的数据,如果重复了,就不插入数据库,可以极大地减少数据库的操作。
- 定时收集数据,每10分钟收集一次数据。
- 退出时收集数据,当 burp 退出时会进行最后一次数据收集,不用人工收集。
接着在 361 行处从 path 中分离出目录,如 /aaa/bbb/ccc/, 那么会收集 /aaa/, /bbb/, /ccc/ 。 接着在 370 行处收集文件名, 如 /js/jquery.js, 那么会收集 jquery.js 。 然后在 376 行处分离主机名,也就是分离域名,只获取子域名,如域名是 aa.bb.cc.dd.ee ,那么会收集先收集分离后的子域名,如 aa, bb, cc, 然后收集 aa.bb.cc, bb.cc, cc 几个子域名。 最后在 400 行处获取请求中的所有参数,402 行处的 2 代表 cookie 参数名,暂时不收集 cookie, 然后收集符合条件的参数名。 数据库设计 数据库设计主要包括表结构的设计,导出语句的的设计,插入语句的设计。 数据库的设计对性能的影响很大,开始时我写的SQL语句收集一次数据需要20分钟,经过做开发的朋友改进后,只需1秒,所以写数据库代码就是写SQL语句。 首先是表的设计,本次要收集的数据上面已经介绍过,主要的表如下: 表的类型有两种,一种是 host_xxx_map 表,如 host_dir_map 表用于收集 host 信息及其对应的内容,表的字段有 host 和 dir ,上图可以看出 0.gravatar.com 这个 host 对应的目录有3个。 另一种表如,dir 表,用于导入 csv 文件中的数据,表的字段是 dir , count,分别是目录名和出现的数目,主要用于导入别人导出的 dir_import.csv, 当导出数据时,会合并这种表中的数据,再进行导出。 创建表的代码在 dao/DatabaseUtil 类中 接下来说下插入数据时的语句,插入数据时应该怎么处理呢,我一开始的时候设计的是这样的: 假设要插入一条数据, host 值是 www.baidu.com, dir 值是 /js/ 下面是伪代码
数据库是否存在该记录 // 此处一条查询语句如果存在不插入如果不存在,插入该记录 //此处一条插入语句INSERT IGNORE INTO host_dir_map(host, dir) VALUES("www.baidu.com", "dir1"), ("www.baidu.com", "dir2"), ...("www.baidu.com", "dir1000")SELECT hdm.dir, COUNT(*) AS dirCount FROM host_dir_map hdm GROUP BY hdm.dir ORDER BY `dirCount` DESCprivate boolean addToMemory(String host, String value, String flag) { boolean result = true; HashMap> hostHashMap = memoryHostValueMap.get(host);if (hostHashMap == null) { hostHashMap = new HashMap<>(); HashSet hostHashSet = new HashSet<>(); hostHashSet.add(value); hostHashMap.put(flag, hostHashSet); memoryHostValueMap.put(host, hostHashMap); result = false; } else { HashSet hostHashSet = hostHashMap.get(flag);if (hostHashSet == null) { hostHashSet = new HashSet<>(); hostHashSet.add(value); hostHashMap.put(flag, hostHashSet); result = false; } else {if (!hostHashSet.contains(value)) { hostHashSet.add(value); result = false; } } }return result; }service = Executors.newSingleThreadScheduledExecutor();service.scheduleWithFixedDelay(new Runnable() {@Overridepublic void run() { BurpExtender.this.saveData(); callbacks.printOutput("Scheduled export execution completed"); }}, 0, 10, TimeUnit.MINUTES);往期文章python协程学习——写个并发获取网站标题的工具一些相见恨晚的BurpSuite插件推荐