googlenet网络结构_「动手学计算机视觉」第十八讲:卷积神经网络之GoogLeNet
前言
在前一篇文章介绍VGG时,我提到2014年对于计算机视觉领域是一个丰收的一年,在这一年的ImageNet图像识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge)中出现了两个经典、影响至深的卷积神经网络模型,其中第一名是GoogLeNet、第二名是VGG。
没错,本文的主角就是2014年ILSVRC的第一名--GoogLeNet(Going Deeper with Convolutions),要注意的是,这个网络模型的名称是"GoogLeNet",而不是"GoogleNet",虽然只有一个大小写字母的却别,含义却不同,GoogLeNet之所以叫做这个名字,主要是为了想LeNet致敬。
GoogLeNet与VGG出现在同一年,二者自然有一些相似之处,但是两个模型更多的是差异性。
首先说一下GoogLeNet与VGG的相同之处:
- 都提出了基础块的思想
- 均是为了克服网络逐渐变深带来的问题
首先,说一下第一点--都提出了基础块的思想。
前文已经介绍了,VGG使用块代替层的思想,这使得VGG在迁移性方面表现非常好,也因此得到了广泛的应用。而GoogLeNet也使用了基础块的思想,它引入了Inception块,想必说到这里应该接触过深度计算机视觉的同学应该恍然大悟,也许对GoogLeNet的概念已经变的模糊,但是Inception却如雷贯耳,目前在很多CNN模型中同样作为基础模块使用。
其次,说一下第二点--均是为了克服网络逐渐变深带来的问题。
随着卷积神经网络模型的更新换代,我们发现网络层数逐渐变多,模型变的越来越深,这是因为提升模型效果最为直接有效的方法就是增加网络深度和宽度,但是,随着网络层数的加深、加宽,它也会带来很多负面影响,
- 参数数量增加
- 梯度消失和梯度爆炸
- 计算复杂度增加
因此,从VGG、GoogLeNet开始,包括后面会讲到的ResNet,研究者逐渐把目光聚焦在"如何在增加网络深度和宽度的同时,避免上述这些弊端?"
不同的网络模型所采取的方式不同,这也就引出了VGG与GoogLe的不同之处,
- 输出层不同
- 克服网络加深弊端的方式不同
首先,说一下第一点--输出层不同,
VGG是在LeNet、AlexNet的基础上引入了基础块的思想,但是在网络架构、输出等放并没有进行太多的改变,在输出层方面同样是采用连续三个全连接层,全连接层的输入是前面卷积层的输出经过reshape得到。
虽然GoogLeNet是向LeNet致敬,但是在GoogLeNet的身上却很难看到LeNet和AlexNet的影子,它的输出更是采用NiN的思想(Network in Network),它把全连接层编程了1*1的卷积层。
其次,说一下第二点--克服网络加深弊端的方式不同,
VGG在克服网络加深带来的问题方面采用的是引入基础块的思想,但是整体上还是偏向于"更深",而GoogLeNet更加偏重于"更宽",它引入了并行网络结构的思想,每一层有4个不同的线路对输入进行处理,然后再块的输出部分在沿着通道维进行连接。
GoogLeNet通过对模型的大幅度改进,使得它在参数数量、计算资源方面要明显优于VGG,但是GoogLeNet的模型复杂度相对于VGG也要高一些,因此,在迁移性方面VGG要优于GoogLeNet。
GoogLeNet模型
Inception块是GoogLeNet模型中一个非常重要的组成部分,因此,在介绍完整的GoogLeNet模型之前,我先来讲解一下Inception块的结构。
Inception块
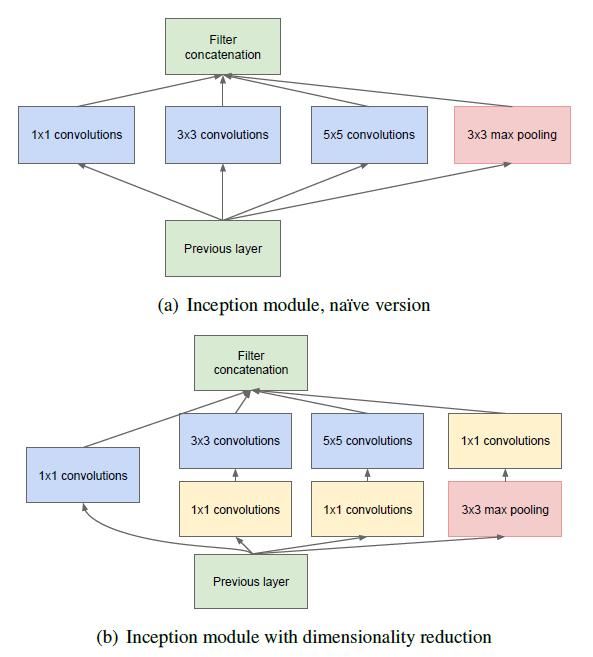
上图就是就是Inception的结构,Inception分为两个版本:
- 简化版
- 降维版
二者主要的区别就在于1*1的卷积层,降维版在第2、3、4条线路添加了1*1的卷积层来减少通道维度,以减小模型复杂度,本文就以降维版为例来讲解GoogLeNet。
现在来看一下Inception的结构,可以很清楚的看出,它包含4条并行线路,其中,第1、2、3条线路分别采用了1*1、3*3、5*5,不同的卷积核大小来对输入图像进行特征提取,使用不同大小卷积核能够充分提取图像特征。其中,第2、3两条线路都加入了1*1的卷积层,这里要明确一点,第2、3两条线路的1*1与第1条线路1*1的卷积层的功能不同,第1条线路是用于特征提取,而第2、3条线路的目的是降低模型复杂度。第4条线路采用的不是卷积层,而是3*3的池化层。最后,4条线路通过适当的填充,使得每一条线路输出的宽和高一致,然后经过Filter Concatenation把4条线路的输出在通道维进行连接。
上述就是Inception块的介绍,在GoogLeNet模型中,Inception块会被多次用到,下面就开始介绍GoogLeNet的完整模型结构。
GoogLeNet
GoogLeNet在网络模型方面与AlexNet、VGG还是有一些相通之处的,它们的主要相通之处就体现在卷积部分,
- AlexNet采用5个卷积层
- VGG把5个卷积层替换成5个卷积块
- GoogLeNet采用5个不同的模块组成主体卷积部分

上述就是GoogLeNet的结构,可以看出,和AlexNet统一使用5个卷积层、VGG统一使用5个卷积块不同,GoogLeNet在主体卷积部分是卷积层与Inception块混合使用。另外,需要注意一下,在输出层GoogleNet采用全局平均池化,得到的是高和宽均为1的卷积层,而不是通过reshape得到的全连接层。
下面就来详细介绍一下GoogLeNet的模型结构。
模块1
第一个模块采用的是一个单纯的卷积层紧跟一个最大池化层。
卷积层:卷积核大小7*7,步长为2,输出通道数64。
池化层:窗口大小3*3,步长为2,输出通道数64。
模块2
第二个模块采用2个卷积层,后面跟一个最大池化层。
卷积层:卷积核大小3*3,步长为1,输出通道数192。
池化层:窗口大小3*3,步长为2,输出通道数192。
模块3
第三个模块采用的是2个串联的Inception块,后面跟一个最大池化层。
第一个Inception的4条线路输出的通道数分别是64、128、32、32,输出的总通道数是4条线路的加和,为256。
第二个Inception的4条线路输出的通道数分别是128、192、96、64,输出的总通道数为480。
池化层:窗口大小3*3,步长为2,输出通道数480。
模块4
第4个模块采用的是5个串联的Inception块,后面跟一个最大池化层。
第一个Inception的4条线路输出的通道数分别是192、208、48、64,输出的总通道数为512。
第二个Inception的4条线路输出的通道数分别是160、224、64、64,输出的总通道数为512。
第三个Inception的4条线路输出的通道数分别是128、256、64、64,输出的总通道数为512。
第四个Inception的4条线路输出的通道数分别是112、288、64、64,输出的总通道数为528。
第五个Inception的4条线路输出的通道数分别是256、320、128、128,输出的总通道数为832。
池化层:窗口大小3*3,步长为2,输出通道数832。
模块5
第五个模块采用的是2个串联的Inception块。
第一个Inception的4条线路输出的通道数分别是256、320、128、128,输出的总通道数为832。
第二个Inception的4条线路输出的通道数分别是384、384、128、128,输出的总通道数为1024。
输出层
前面已经多次提到,在输出层GoogLeNet与AlexNet、VGG采用3个连续的全连接层不同,GoogLeNet采用的是全局平均池化层,得到的是高和宽均为1的卷积层,然后添加丢弃概率为40%的Dropout,输出层激活函数采用的是softmax。
激活函数
GoogLeNet每层使用的激活函数为ReLU激活函数。
编程实践
当我们拿到一个需求的时候,应该先对它进行一下分析、分解,针对GoogLeNet,我们通过分析可以把它分解成如下几个模块,
- Inception块
- 卷积层
- 池化层
- 线性层
通过上述分解,我们逐个来实现上述每个模块。
Inception块
前面讲解过程中已经详细介绍Inception块的结构,它包括4条线路,而对于Inception块最重要的参数就是每个线路输出的通道数,由于其中步长、填充方式、卷积核大小都是固定的,因此不需要我们进行传参。我们把4条线路中每层的输出通道数作为Inception块的入参,具体实现过程如下,
def inception_block(X, c1, c2, c3, c4, name): in_channels = int(X.get_shape()[-1]) # 线路1 with tf.variable_scope('conv1X1_{}'.format(name)) as scope: weight = tf.get_variable("weight", [1, 1, in_channels, c1]) bias = tf.get_variable("bias", [c1]) p1_1 = tf.nn.conv2d(X, weight, strides=[1, 1, 1, 1], padding="SAME") p1_1 = tf.nn.relu(tf.nn.bias_add(p1_1, bias)) # 线路2 with tf.variable_scope('conv2X1_{}'.format(name)) as scope: weight = tf.get_variable("weight", [1, 1, in_channels, c2[0]]) bias = tf.get_variable("bias", [c2[0]]) p2_1 = tf.nn.conv2d(X, weight, strides=[1, 1, 1, 1], padding="SAME") p2_1 = tf.nn.relu(tf.nn.bias_add(p2_1, bias)) p2_shape = int(p2_1.get_shape()[-1]) with tf.variable_scope('conv2X2_{}'.format(name)) as scope: weight = tf.get_variable("weight", [3, 3, p2_shape, c2[1]]) bias = tf.get_variable("bias", [c2[1]]) p2_2 = tf.nn.conv2d(p2_1, weight, strides=[1, 1, 1, 1], padding="SAME") p2_2 = tf.nn.relu(tf.nn.bias_add(p2_2, bias))卷积及池化
在GoogLeNet中多处用到了卷积层和最大池化层,这些结构在AlexNet中都已经实现过,我们直接拿过来使用即可,
def conv_layer(self, X, ksize, out_filters, stride, name): in_filters = int(X.get_shape()[-1]) with tf.variable_scope(name) as scope: weight = tf.get_variable("weight", [ksize, ksize, in_filters, out_filters]) bias = tf.get_variable("bias", [out_filters]) conv = tf.nn.conv2d(X, weight, strides=[1, stride, stride, 1], padding="SAME") activation = tf.nn.relu(tf.nn.bias_add(conv, bias)) return activationdef pool_layer(self, X, ksize, stride): return tf.nn.max_pool(X, ksize=[1, ksize, ksize, 1], strides=[1, stride, stride, 1], padding="SAME")线性层
GoogLeNet与AlexNet、VGG在输出层不同,AlexNet和VGG是通过连续的全连接层处理,然后输入到激活函数即可,而GoogLeNet需要进行全局平均池化后进行一次线性映射,对于这一点实现过程如下,
def linear(self, X, out_filters, name): in_filters = X.get_shape()[-1] with tf.variable_scope(name) as scope: w_fc = tf.get_variable("weight", shape=[in_filters, out_filters]) b_fc = tf.get_variable("bias", shape=[out_filters], trainable=True) fc = tf.nn.xw_plus_b(X, w_fc, b_fc) return tf.nn.relu(fc)搭建模型
上面几步已经把GoogLeNet主要使用的组件已经搭建完成,接下来要做的就是把它们组合到一起即可。这里需要注意一点,全局平均池化层的填充方式和前面卷积层、池化层使用的不同,这里需要使用VALID填充方式,
def create(self, X): # 模块1 module1_1 = self.conv_layer(X, 7, 64, 2, "module1_1") pool_layer1 = self.pool_layer(module1_1, 3, 2) # 模块2 module2_1 = self.conv_layer(pool_layer1, 1, 64, 1, "modul2_1") module2_2 = self.conv_layer(module2_1, 3, 192, 1, "module2_2") pool_layer2 = self.pool_layer(module2_2, 3, 2) # 模块3 module3a = self.inception_block(pool_layer2, 64, (96, 128), (16, 32), 32, "3a") module3b = self.inception_block(module3a, 128, (128, 192), (32, 96), 64, "3b") pool_layer3 = self.pool_layer(module3b, 3, 2) # 模块4 module4a = self.inception_block(pool_layer3, 192, (96, 208), (16, 48), 64, "4a") module4b = self.inception_block(module4a, 160, (112, 224), (24, 64), 64, "4b") module4c = self.inception_block(module4b, 128, (128, 256), (24, 64), 64, "4c") module4d = self.inception_block(module4c, 112, (144, 288), (32, 64), 64, "4d") module4e = self.inception_block(module4d, 256, (160, 320), (32, 128), 128, "4e") pool_layer4 = self.pool_layer(module4e, 3, 2) # 模块5 module5a = self.inception_block(pool_layer4, 256, (160, 320), (32, 128), 128, "5a") module5b = self.inception_block(module5a, 384, (192, 384), (48, 128), 128, "5b") pool_layer5 = tf.nn.avg_pool(module5b, ksize=[1, 7, 7, 1], strides=[1, 1, 1, 1], padding="VALID") flatten = tf.reshape(pool_layer5, [-1, 1024]) dropout = tf.nn.dropout(flatten, keep_prob=self.keep_prob) linear = self.linear(dropout, self.num_classes, 'linear') return tf.nn.softmax(linear)验证
为了验证每一个模块输出的形状和原文中给出的是否一致,我使用numpy,生成了样本数为5的随机样本,看一下每一层的输出结果,
def main(): X = np.random.normal(size=(5, 224, 224, 3)) images = tf.placeholder("float", [5, 224, 224, 3]) googlenet = GoogLeNet(1000, 0.4) writer = tf.summary.FileWriter("logs") with tf.Session() as sess: model = googlenet.create(images) sess.run(tf.global_variables_initializer()) writer.add_graph(sess.graph) prob = sess.run(model, feed_dict={images: X}) print(sess.run(tf.argmax(prob, 1))) # 输出module1_1: (5, 112, 112, 64)pool_layer1: (5, 56, 56, 64)module2_1: (5, 56, 56, 64)module2_2: (5, 56, 56, 192)pool_layer2: (5, 28, 28, 192)module3a: (5, 28, 28, 256)module3b: (5, 28, 28, 480)pool_layer3: (5, 14, 14, 480)module4a: (5, 14, 14, 512)module4b: (5, 14, 14, 512)module4c: (5, 14, 14, 512)module4d: (5, 14, 14, 528)module4e: (5, 14, 14, 832)pool_layer4: (5, 7, 7, 832)module5a: (5, 7, 7, 832)module5b: (5, 7, 7, 1024)pool_layer5: (5, 1, 1, 1024)flatten: (5, 1024)linear: (5, 1000)可以从上述输出可以看出,每一层的输出形状和原文中给出的一致,至于在不同场景、不同数据集下的表现效果,这需要针对性的进行调优。
链接
本文完整代码
https://github.com/Jackpopc/aiLearnNotes/blob/master/computer_vision/GoogLeNet.py
Going Deeper with Convolutions
http://www.arxiv.org/pdf/1409.4842.pdf
Network In Network
http://arxiv.org/pdf/1312.4400
我把本讲文档已经上传到github,如果需要可以搜索github项目aiLearnNotes查看。