Python中的正则表达式
正则表达式
正则表达式就是从字符串中发现规律,并通过“抽象”的符号表达出来。打个比方,对于2,5,10,17,26,37这样的数字序列,如何计算第7个值,肯定要先找该序列的规律,然后用n2+1这个表达式来描述其规律,进而得到第7个值为50。对于需要匹配的字符串来说,同样把发现规律作为第一步,本文主要使用正则表达式完成字符串的查询匹配、替换匹配和分割匹配。
正则表达式为高级的文本模式匹配抽取与/或文本形式的搜家和特换为能提供了基础简单站说,正则表达式(简称为regex)是一些由字符和特殊符号组成的字符串,它们描述了模式的重复或者表述多个字符,于是正则表达式能按照某种模式匹配一系列有相似特征的字符串。换句话说,它们能够匹配多个字符-…种只能匹配个字符串的正则表达式模式是很乏味并且毫无作用的,
Python通过标准库中的re模块来支持正则表达式。本文将做个简短扼要的介绍。 本文主要介绍python中的正则表达式,想要先深入了解正则表达式可以阅读我的上一篇博文——一文详解正则表达式。
正则表达式和Python语言
想要使用python的正则表达式功能就需要调用re模块,re模块为高级字符串处理提供了正则表达式工具。模块中提供了不少有用的函数,比如:compile函数、match函数、search函数、findall函数、finditer函数、split函数、sub函数、subn函数等。接下来本文将会介绍这些函数的使用情况,然后通过分析编译流程对比两种re模块的调用方式,之后会介绍其他一些应用正则表达式需要知道的理论知识,最后通过一些经典的实例将之前学习的理论应用于实际。
在了解了关于正则表达式的全部知识后,开始查看Python当前如何通过使用re模块来支持正则表达式,re模块在古老的Python 1.5版中引入,用于替换那些已过时的regex模块和regsub模块——这两 个模块在Python2.5版中移除,而且此后导入这两个模块中的任意一个都会触发ImportError 异常。
re模块支持更强大而且更通用的Perl风格(Perl 5风格)的正则表达式,该模块允许多个线程共享同一个已编译的正则表达式对象,也支持命名子组。
正则函数
re.match函数
功能:re.match尝试从字符串的起始位置匹配一个模式,如果匹配成功则返回一个匹配的对象,如果不是起始位置匹配成功的话,match()就返回none。
语法:re.match(pattern,string,flags=0)

re.search函数
功能:re.search 扫描整个字符串并返回第一个成功的匹配,如果匹配成功re.search方法返回一个匹配的对象,否则返回None。
语法:re.search(pattern, string, flags=0)
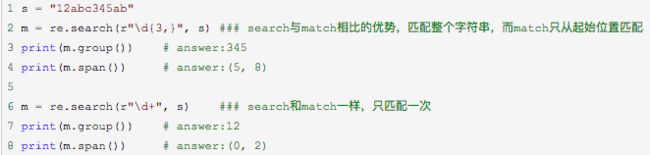
re.sub函数
功能:re.sub用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0, flags=0)
repl参数可以为替换的字符串,也可以为一个函数。
如果repl是字符串,那么就会去替换字符串匹配的子串,返回替换后的字符串;
如果repl是函数,定义的函数只能有一个参数(匹配的对象),并返回替换后的字符串。
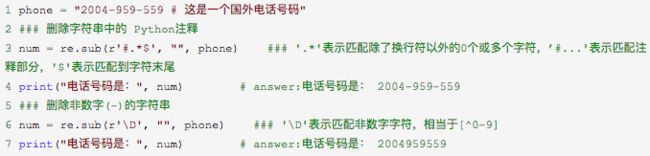
count可指定替换次数,不指定时全部替换。例如:

repl可以为一个函数。例如:

re.subn函数
功能:和sub函数差不多,但是返回结果不同,返回一个元组“(新字符串,替换次数)”
例子:

re.compile函数
功能:compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。如果匹配成功则返回一个Match对象。
语法:re.compile(pattern[, flags])
re.findall函数
功能:在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
语法:findall(string[, pos[, endpos]])

re.finditer函数
功能:在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
语法:re.finditer(pattern, string, flags=0)
例子:

re.split函数
功能:split 方法用pattern做分隔符切分字符串,分割后返回列表。如果用’(pattern)’,那么分隔符也会返回。
语法:re.split(pattern, string[, maxsplit=0, flags=0])
例子:

小结:
- 函数辨析:match和search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
re.search匹配整个字符串,直到找到一个匹配。
- 函数辨析:3个匹配函数match、search、findall
match 和 search 只匹配一次 ,匹配不到返回None,findall 查找所有匹配结果。
- 函数返回值
函数re.finditer 、 re.match和re.search 返回匹配对象,而findall、split返回列表。
re模块的调用
re模块的使用一般有两种方式:
方法1:
直接使用上面介绍的 re.match, re.search 和 re.findall 等函数对文本进行匹配查找。
方法2:
(1)使用compile 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
(2)通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果(一个 Match 对象);
(3)最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
接下来重点介绍一下compile函数。
re.compile函数用于编译正则表达式,生成一个Pattern对象,调用形式如下:
re.compile(pattern[, flag])
其中,pattern是一个字符串形式的正则表达式,flag是一个可选参数(下一节具体讲解)。
例子:
match函数
使用语法:
(1)re.match(pattern, string[, flags])
这个之前讲解过了。
(2)Pattern对象:match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
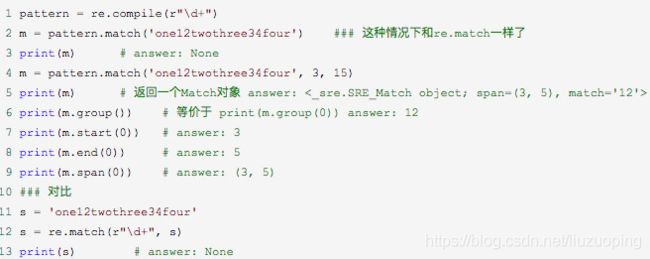
当匹配成功时会返回一个Match对象,其中:
group([0, 1, 2,…]): 可返回一个或多个分组匹配的字符串,若要返回匹配的全部字符串,可以使用group()或group(0)。
start(): 匹配的开始位置。
end(): 匹配的结束位置。
span(): 包含起始、结束位置的元组。等价于(start(), end())。
groups(): 返回分组信息。等价于(m.group(1), m.group(2))。
groupdict(): 返回命名分组信息。

search函数
使用语法:
(1)re.search(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:search(string[, pos[, endpos]])
例子:

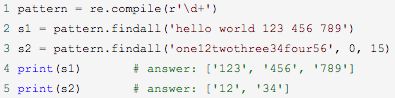
findall函数
使用语法:
(1)findall(string[, pos[, endpos]])
这个函数前面已经讲解过了。
(2)Pattern对象:findall(string[, pos[, endpos]])
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
例子:
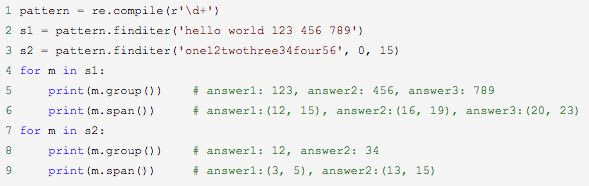
finditer函数
使用语法:
(1)re.finditer(pattern, string, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:finditer(string[, pos[, endpos]])
finditer 函数与 findall 类似,但是它返回每一个匹配结果(Match 对象)的迭代器。
例子:
split函数
使用语法:
(1)re.split(pattern, string[, maxsplit=0, flags=0])
这个函数前面已经讲解过了。
(2)Pattern对象:split(string[, maxsplit]])
maxsplit 可指定分割次数,不指定将对字符串全部分割。
例子:

sub函数
使用语法:
(1)re.sub(pattern, repl, string, count=0, flags=0)
这个函数前面已经讲解过了。
(2)Pattern对象:sub(repl, string[, count])
当repl为字符串时,可以用\id的形式引用分组,但不能使用编号0;当repl为函数时,返回的字符串中不能再引用分组。

subn函数
subn和sub类似,也用于替换操作。使用语法如下:
Pattern对象:subn(repl, string[, count])
返回一个元组,元组第一个元素和sub函数的结果相同,元组第二个元素返回替换次数。
例子:

小结:
-
使用Pattern对象的match、search、findall、finditer等函数可以指定匹配字符串的起始位置。
-
对re模块的两种使用方式进行对比:
使用 re.compile 函数生成一个 Pattern 对象,然后使用 Pattern 对象的一系列方法对文本进行匹配查找;
直接使用 re.match, re.search 和 re.findall 等函数直接对文本匹配查找。
例子:

如果一个正则表达式要用多次,那么出于效率考虑,我们可以预先编译正则表达式,然后调用的一系列函数时复用。如果直接使用re.match、re.search等函数,则需要每一次都对正则表达式进行编译,效率就会降低。因此在这种情况下推荐使用第一种方式。
贪婪匹配
正则表达式匹配时默认的是贪恋匹配,也就是会尽可能多的匹配更多字符。如果想使用非贪恋匹配,可以在正则表达式中加上’?’。
下面,我们来看1个实例:

分组
如果你想要提取子串或是想要重复提取多个字符,那么你可以选择用定义分组的形式。用()就可以表示要提取的分组(group),接下来用几个实例来理解一下分组的使用方式:
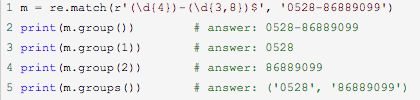
正则表达式’(\d{4})-(\d{3, 8})$‘表示匹配两个分组,第一个分组(\d{4})是一个有4个数字的子串,第二个分组(\d{3,8})表示匹配一个数字子串,子串长度为3到8之间。

正则表达式’(\d{1,3}.){3}\d{1,3}‘的匹配过程分为两个部分,’(\d{1,3}.){3}‘表示匹配一个长度为1到3之间的数字子串加上一个英文句号的字符串,重复匹配 3 次该字符串,’\d{1,3}'表示匹配一个1到3位的数字子串,所以最后得到结果123.456.78.90。

(.)第一个分组,. 代表匹配除换行符之外的所有字符。(.?) 第二个匹配分组,.? 后面加了个问号,代表非贪婪模式,只匹配符合条件的最少字符。后面的一个 .* 没有括号包围,所以不是分组,匹配效果和第一个一样,但是不计入匹配结果中。
group() 等同于group(0),表示匹配到的完整文本字符;
group(1) 得到第一组匹配结果,也就是(.*)匹配到的;
group(2) 得到第二组匹配结果,也就是(.*?)匹配到的;
因为只有匹配结果中只有两组,所以如果填 3 时会报错。
正则表达式修饰符
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。修饰符被指定为一个可选的标志。多个标志可以通过按位 OR(|) 它们来指定。
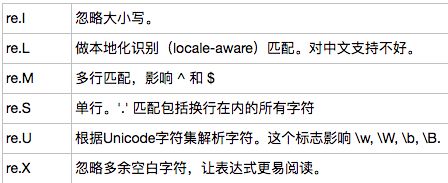

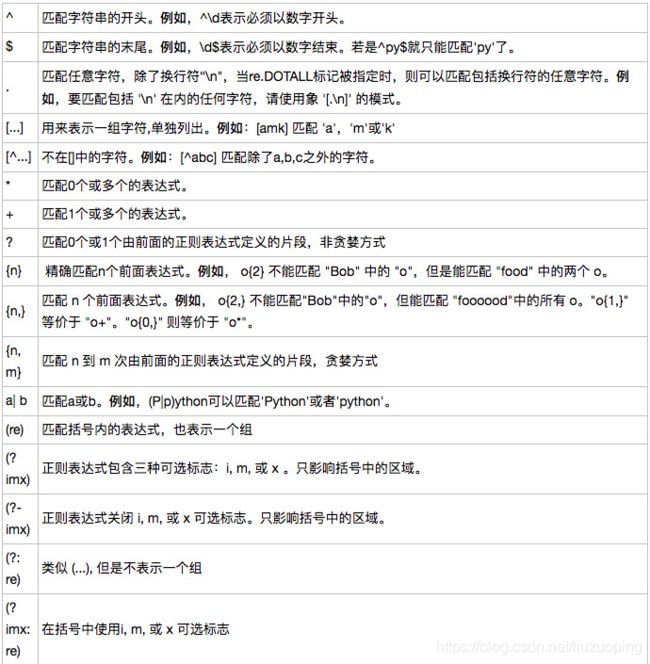
下面列出了正则表达式模式语法中的特殊元素,更多内容在我的上篇博文——一文详解正则表达式中均有涉及。