目录
ceph的网络通信
ceph网络通信模式分类
simple框架
message数据格式
Ceph通信模块代码分析
ceph网络通信模块类说明
1. Async通信模块角色
2. Async通信模式
Ceph日志和调试
现在ceph的网络是async,simple不用,建议只做了解不不必花太多时间在上面。
ceph的网络通信
原文:Ceph Async Messager · 大专栏
ceph 网络层代码分析(1)_shuningzhang的专栏-CSDN博客
Ceph通信框架设计模式
设计模式:订阅发布模式(Subscribe/Publish),又名观察者模式,它意图是“定义对象间的一种一对多的依赖关系,
当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新”。
Ceph通信框架流程图
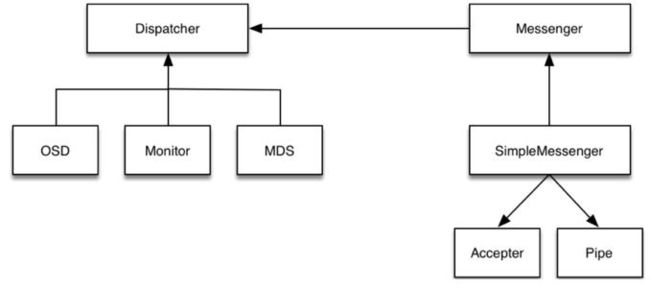
步骤:
- Accepter监听peer的请求, 调用 SimpleMessenger::add_accept_pipe() 创建新的 Pipe 到 SimpleMessenger::pipes 来处理该请求。
- Pipe用于消息的读取和发送。该类主要有两个组件,Pipe::Reader,Pipe::Writer用来处理消息读取和发送。
- Messenger作为消息的发布者, 各个 Dispatcher 子类作为消息的订阅者, Messenger 收到消息之后, 通过 Pipe 读取消息,然后转给 Dispatcher 处理。
- Dispatcher是订阅者的基类,具体的订阅后端继承该类,初始化的时候通过 Messenger::add_dispatcher_tail/head 注册到 Messenger::dispatchers. 收到消息后,通知该类处理。
- DispatchQueue该类用来缓存收到的消息, 然后唤醒 DispatchQueue::dispatch_thread 线程找到后端的 Dispatch 处理消息。
ceph_message_2
Ceph通信框架类图

架构上采用 Publish/subscribe(发布/订阅) 的设计模式.
simple框架
src/common/config_opts.h
OPTION(ms_type, OPT_STR, "simple")
SimpleMessenger 是simple框架具体的实现。
从这个构造函数中可以看到SimpleMessenger 会在构造函数中分别建立结束accepter和发送dispatch_queue 两个线程
| SimpleMessenger::SimpleMessenger(CephContext *cct, entity_name_t name, |
accepter和发送dispatch_queue 线程 建立代码
//这里以accepter为例看看是如何建立接受线程的
class Accepter : public Thread
{
SimpleMessenger *msgr;
bool done;
int listen_sd;
uint64_t nonce;
int shutdown_rd_fd;
int shutdown_wr_fd;
int create_selfpipe(int *pipe_rd, int *pipe_wr);
public:
Accepter(SimpleMessenger *r, uint64_t n)
: msgr(r), done(false), listen_sd(-1), nonce(n),
shutdown_rd_fd(-1), shutdown_wr_fd(-1)
{}
void *entry() override;
void stop();
int bind(const entity_addr_t &bind_addr, const set &avoid_ports);
int rebind(const set &avoid_port);
int start();
};
//可以看到accepter 是thread的子类
//所以我们先看看其start函数
int Accepter::start()
{
ldout(msgr->cct, 1) << __func__ << dendl;
// start thread
create("ms_accepter");
return 0;
}
//在start中通过create来新建一个接收线程,其name是ms_accepter
//其次我们在看看这个线程只要执行的工作,其在entry中实现
void *Accepter::entry()
{
ldout(msgr->cct, 1) << __func__ << " start" << dendl;
int errors = 0;
int ch;
struct pollfd pfd[2];
memset(pfd, 0, sizeof(pfd));
pfd[0].fd = listen_sd;
pfd[0].events = POLLIN | POLLERR | POLLNVAL | POLLHUP;
pfd[1].fd = shutdown_rd_fd;
pfd[1].events = POLLIN | POLLERR | POLLNVAL | POLLHUP;
#开始polling
while (!done)
{
ldout(msgr->cct, 20) << __func__ << " calling poll for sd:" << listen_sd << dendl;
int r = poll(pfd, 2, -1);
if (r < 0)
{
if (errno == EINTR)
{
continue;
}
ldout(msgr->cct, 1) << __func__ << " poll got error"
<< " errno " << errno << " " << cpp_strerror(errno) << dendl;
break;
}
#检查是否polling返回error
if (pfd[0].revents & (POLLERR | POLLNVAL | POLLHUP))
{
ldout(msgr->cct, 1) << __func__ << " poll got errors in revents "
<< pfd[0].revents << dendl;
break;
}
if (pfd[1].revents & (POLLIN | POLLERR | POLLNVAL | POLLHUP))
{
// We got "signaled" to exit the poll
// clean the selfpipe
#检查是否要退出polling
if (::read(shutdown_rd_fd, &ch, 1) == -1)
{
if (errno != EAGAIN)
ldout(msgr->cct, 1) << __func__ << " Cannot read selfpipe: "
<< " errno " << errno << " " << cpp_strerror(errno) << dendl;
}
break;
}
if (done) break;
// accept
#走到这里polling函数就正常返回了,通过accept函数开始接收
sockaddr_storage ss;
socklen_t slen = sizeof(ss);
int sd = ::accept(listen_sd, (sockaddr *)&ss, &slen);
if (sd >= 0)
{
int r = set_close_on_exec(sd);
if (r)
{
ldout(msgr->cct, 1) << __func__ << " set_close_on_exec() failed "
<< cpp_strerror(r) << dendl;
}
errors = 0;
ldout(msgr->cct, 10) << __func__ << " incoming on sd " << sd << dendl;
#实际从pipe中读入msg
msgr->add_accept_pipe(sd);
}
else
{
ldout(msgr->cct, 0) << __func__ << " no incoming connection? sd = " << sd
<< " errno " << errno << " " << cpp_strerror(errno) << dendl;
if (++errors > 4)
break;
}
}
ldout(msgr->cct, 20) << __func__ << " closing" << dendl;
// socket is closed right after the thread has joined.
// closing it here might race
if (shutdown_rd_fd >= 0)
{
::close(shutdown_rd_fd);
shutdown_rd_fd = -1;
}
ldout(msgr->cct, 10) << __func__ << " stopping" << dendl;
return 0;
} message数据格式
通信的双方需要约定数据格式,这是很明显的。否则收到对方发送的数据,不知道如何解析。这应该是通信的首先要解决的问题。
class Message : public RefCountedObject {
protected:
ceph_msg_header header; // headerelope
ceph_msg_footer footer;
bufferlist payload; // "front" unaligned blob
bufferlist middle; // "middle" unaligned blob
bufferlist data; // data payload (page-alignment will be preserved where possible)
...
};在消息内容可以分成3个部分
- header
- user data
- footer。
user data 当中可以分成3个部分
- payload
- middle
- data
payload 一般是ceph操作的元数据 , middle是预留字段目前没有使用。 data是一般为读写的数据。
接下来先介绍header:
struct ceph_msg_header {
__le64 seq; /* message seq# for this session */
__le64 tid; /* transaction id */
__le16 type; /* message type */
__le16 priority; /* priority. higher value == higher priority */
__le16 version; /* version of message encoding */
__le32 front_len; /* bytes in main payload */
__le32 middle_len;/* bytes in middle payload */
__le32 data_len; /* bytes of data payload */
__le16 data_off; /* sender: include full offset;
receiver: mask against ~PAGE_MASK */
struct ceph_entity_name src;
/* oldest code we think can decode this. unknown if zero. */
__le16 compat_version;
__le16 reserved;
__le32 crc; /* header crc32c */
} __attribute__ ((packed));因为payload/middle/data大小一般是变长,因此,为了能正确地解析三者,header中纪录了三者的长度:
- front_len
- middle_len
- data_len
其中data _off含义我尚不明确,后面解决 ⚠️。
接下来看footer的数据结构:
struct ceph_msg_footer {
__le32 front_crc, middle_crc, data_crc;
// sig holds the 64 bits of the digital signature for the message PLR
__le64 sig;
__u8 flags;
} __attribute__ ((packed));在footer中会计算payload/middle/data的crc,填入front_crc middle_crc和data_crc
Ceph通信模块代码分析
(原文:ceph 网络层代码分析(1)_shuningzhang的专栏-CSDN博客)
出现在网络层的数据结构比较多,Messenager,Connection,Dispatcher,DispatchQueue,Pipe,让人眼花缭乱,摸不到重点。
下面我讲述下这些数据结构,如何相互配合完成通信的任务。
Ceph的这一套通信机制,其实和Linux下的Socket通信比较像,每一种数据结构和职责,都能在传统的Socket通信中找到对应点。
Linux下的socket通信模型:
int socket(int domain, int type, int protocol);int socket(int domain, int type, int protocol);创建一个socket,如同买了一步固定电话
int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);将具体的地址绑定到socket上,如同给自己的电话机申请了一个电话号码,和电话机绑定
int listen(int sockfd, int backlog);服务器端会调用listen来监听这个socket,如同给自己的电话接上了线路,别人就可以通过号码打到自己的电话上了。另一个比喻是打开电话的铃声,这样别人来连的时候,就能听到了。
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);服务器端已经准备好了,connect是client端调用的函数,client端主动连server端,如同别人给你拨电话。
int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);服务器端会主动调用accept等待客户来连,如果客户不来连,accept就会阻塞,原地等待。当客户端来连的时候,accept就会返回,同时可以获取到client端的信息,这种情况下线路就通了。
上面是单条线路的通话,如果通话的双方有很多话要讲,同时有其他请求到来时,服务器端并没有停在accept上导致新的通话请求无法接入。在网络通信的早期,一般采用accept之后,创建单独的进程或者线程,或者从线程池中找出一个线程,来应对当前通话,而主线程或者进程,继续调用accept,等待新的通话请求接入。
介绍完了Linux平台下的通用socket通信,接下来介绍ceph的各个数据结构,以及如何和socket通信对应。
ceph中的通信相关的数据结构
服务端:
Messenger 是整个网络模块功能类的抽象。其定义了网络模块的基本功能接口。我们先介绍其手下的成员,当手下的成员介绍清楚了,Messenger就不难理解了。
SimpleMessenger中成员变量如下(部分)
public:
Accepter accepter;
DispatchQueue dispatch_queue;
friend class Accepter;
...
set accepting_pipes;
/// a set of all the Pipes we have which are somehow active
set pipes;
/// a list of Pipes we want to tear down
list pipe_reap_queue; 考虑到SimpleMessenger继承自SimplePolicyMessenger,而SimplePolicyMessenger继承自Messenger
class SimpleMessenger : public SimplePolicyMessenger {
}
class SimplePolicyMessenger : public Messenger
{
}因此SimpleMessenger中还包含如下成员:
list dispatchers;
list fast_dispatchers; 到此,几乎所有的数据结构都已经容纳在SimpleMessenger数据结构之内了,所以说SimpleMessenger是整个网络模块的抽象。
我们从简单到复杂,依次介绍各个模块都是干啥的。
Accepter
Accepter最好理解,它的作用和它的名字一样,用来接受网络连接的。和传统socket通信一样,要想接受网络连接,必须要有电话机(socket),绑定到电话号码(bind),要接上线路,准备接受链接(listen),最后要等待其他地址拨过来的链接请求(accept)。是的,Accepter这个类就是做了这些事情。
以ceph_osd 为例,SimpleMessenger会调用bind,做上面提到的事情,而SimpleMessenger的bind,将这些事情委托给了成员Accepter accepter。
int SimpleMessenger::bind(const entity_addr_t &bind_addr)
{
lock.Lock();
if (started)
{
ldout(cct, 10) << "rank.bind already started" << dendl;
lock.Unlock();
return -1;
}
ldout(cct, 10) << "rank.bind " << bind_addr << dendl;
lock.Unlock();
// bind to a socket
set avoid_ports;
int r = accepter.bind(bind_addr, avoid_ports);
if (r >= 0)
did_bind = true;
return r;
} 而Accepter这个类的bind方法实现,不外乎,socket,bind,listen
| int Accepter::bind(const entity_addr_t &bind_addr, const set int family; default: /*创建socket*/listen_sd = ::socket(family, SOCK_STREAM, 0); if (set_close_on_exec(listen_sd)) // use whatever user specified (if anything) /* bind to port */
if (i > 0) /*默认情况下,并不指定端口,走else*/ // reuse addr+port when possible rc = ::bind(listen_sd, listen_addr.get_sockaddr(), listen_addr.set_port(port); rc = ::bind(listen_sd, listen_addr.get_sockaddr(), if (rc == 0) // It seems that binding completely failed, return with that exit status // what port did we get? if (msgr->cct->_conf->ms_tcp_rcvbuf) ldout(msgr->cct, 10) << "accepter.bind bound to " << listen_addr << dendl; // listen! rc = ::listen(listen_sd, 128); msgr->set_myaddr(bind_addr); if (msgr->get_myaddr().get_port() == 0) msgr->init_local_connection(); ldout(msgr->cct, 1) << "accepter.bind my_inst.addr is " << msgr->get_myaddr() |
不多说了,我们看port的范围,6800到8100
root@node-186:/var/run/ceph# ceph daemon osd.1 config show |grep bind
"ms_bind_ipv6": "false",
"ms_bind_port_min": "6800",
"ms_bind_port_max": "8100",root@node-186:/var/run/ceph# netstat -anp |grep ceph
tcp 0 0 10.10.10.186:6818 0.0.0.0:* LISTEN 4993/ceph-osd
tcp 0 0 10.10.10.186:6819 0.0.0.0:* LISTEN 4993/ceph-osd
tcp 0 0 10.10.10.186:6820 0.0.0.0:* LISTEN 4993/ceph-osd
tcp 0 0 10.10.10.186:6789 0.0.0.0:* LISTEN 4306/ceph-mon
tcp 0 0 0.0.0.0:6800 0.0.0.0:* LISTEN 4446/ceph-mds
tcp 0 0 10.10.10.186:6801 0.0.0.0:* LISTEN 4582/ceph-osd
tcp 0 0 10.10.10.186:6802 0.0.0.0:* LISTEN 4582/ceph-osd
tcp 0 0 10.10.10.186:6803 0.0.0.0:* LISTEN 4582/ceph-osd
tcp 0 0 10.10.10.186:6804 0.0.0.0:* LISTEN 4582/ceph-osd
tcp 0 0 10.10.10.186:6805 0.0.0.0:* LISTEN 4582/ceph-osd
tcp 0 0 10.10.10.186:6806 0.0.0.0:* LISTEN 4702/ceph-osd
tcp 0 0 10.10.10.186:6807 0.0.0.0:* LISTEN 4702/ceph-osd
tcp 0 0 10.10.10.186:6808 0.0.0.0:* LISTEN 4702/ceph-osd
tcp 0 0 10.10.10.186:6809 0.0.0.0:* LISTEN 4702/ceph-osd
tcp 0 0 10.10.10.186:6810 0.0.0.0:* LISTEN 4702/ceph-osd
tcp 0 0 10.10.10.186:6811 0.0.0.0:* LISTEN 4854/ceph-osd
tcp 0 0 10.10.10.186:6812 0.0.0.0:* LISTEN 4854/ceph-osd
tcp 0 0 10.10.10.186:6813 0.0.0.0:* LISTEN 4854/ceph-osd
tcp 0 0 10.10.10.186:6814 0.0.0.0:* LISTEN 4854/ceph-osd
tcp 0 0 10.10.10.186:6815 0.0.0.0:* LISTEN 4854/ceph-osd
tcp 0 0 10.10.10.186:6816 0.0.0.0:* LISTEN 4993/ceph-osd
tcp 0 0 10.10.10.186:6817 0.0.0.0:* LISTEN 4993/ceph-osdsocket,bind,listen,都已经有着落了,但是目前还没有accept的踪影。Accepter类继承自Thread,它本质是个线程:
class Accepter : public Thread
{
SimpleMessenger *msgr;
bool done;
int listen_sd;
uint64_t nonce;
public:
Accepter(SimpleMessenger *r, uint64_t n) : msgr(r), done(false), listen_sd(-1), nonce(n) {}
void *entry();
void stop();
int bind(const entity_addr_t &bind_addr, const set &avoid_ports);
int rebind(const set &avoid_port);
int start();
}; Accepter这个线程的主要任务,就是accept,接受连接到来。前面也讲过,这个线程不能用来处理客户的业务请求(专职处理连接请求),因为两者的通信可能耗时较长,造成阻塞,导致其他所有的连接请求无法响应。这个线程也是这么做的,基本上是接到请求,然后创建Pipe负责该请求,继续accept,等待新的连接。
| int Accepter::start() // start thread return 0; void *Accepter::entry() int errors = 0; struct pollfd pfd; while (!done) if (pfd.revents & (POLLERR | POLLNVAL | POLLHUP)) ldout(msgr->cct, 10) << "pfd.revents=" << pfd.revents << dendl; // accept /*注意这一句,add_accept_pipe,即创建专门的pipe负责此次通信,而线程继续accept,而不是停下来处理通信请求*/ msgr->add_accept_pipe(sd); ldout(msgr->cct, 20) << "accepter closing" << dendl; if (listen_sd >= 0)
|
这个线程是个死循环,不停的等待客户端的连接请求,收到连接请求后,调用msgr->add_accept_pipe,可以理解为创建pipe,由专门的线程负责与客户端通信,而本线程继续accept。
到此处,我们已经终于看到了通信的核心部分Pipe了。我们细细的品以下SimpleMessenger的 add_accept_pipe函数:
Pipe *SimpleMessenger::add_accept_pipe(int sd)
{
lock.Lock();
Pipe *p = new Pipe(this, Pipe::STATE_ACCEPTING, NULL);
p->sd = sd;
p->pipe_lock.Lock();
p->start_reader();
p->pipe_lock.Unlock();
pipes.insert(p);
accepting_pipes.insert(p);
lock.Unlock();
return p;
}即服务器端accept之后,创建了一个新的Pipe数据结构,然后将新的Pipe放入到SimpleMessenger的pipes和accepting_pipes两个集合中去。
服务端:
上面是服务器端,我们看一些client端如何连接服务器的监听端口:
client端的程序一般这样写
- 创建messenger实例
messenger = Messenger::create(g_ceph_context, g_conf->ms_type,
entity_name_t::MON(-1),
"client",
getpid());
messenger->set_magic(MSG_MAGIC_TRACE_CTR);
messenger->set_default_policy(Messenger::Policy::lossy_cli- 创建Dispatcher 类并添加到messenger,用于接收消息 (暂时看不懂也关系,后面会讲到)
dispatcher = new SimpleDispatcher(messenger);
messenger->add_dispatcher_head(dispatcher);
dispatcher->set_active(); // this side is the pinger- 启动messenger
r = messenger->start();- 获得服务器端的连接
conn = messenger->get_connection(dest_server);- 通过connection发送消息
我们可以很清楚地知道,get_connection操作,就如同linux socket通信中的connect系统调用,下面我们看看该函数的实现:
ConnectionRef SimpleMessenger::get_connection(const entity_inst_t &dest)
{
Mutex::Locker l(lock);
if (my_inst.addr == dest.addr){
// local
return local_connection;
}
// remote
while (true)
{
Pipe *pipe = _lookup_pipe(dest.addr);
if (pipe)
{
ldout(cct, 10) << "get_connection " << dest << " existing " << pipe << dendl;
}
else
{
pipe = connect_rank(dest.addr, dest.name.type(), NULL, NULL);
ldout(cct, 10) << "get_connection " << dest << " new " << pipe << dendl;
}
Mutex::Locker l(pipe->pipe_lock);
if (pipe->connection_state)
return pipe->connection_state;
// we failed too quickly! retry. FIXME.
}
}注意,首先是尝试查找已经存在的Pipe(通过_lookup_pipe),如果可以复用,就不再创建,否则就调用connect_rank来创建Pipe,如下所示:
Pipe *SimpleMessenger::connect_rank(const entity_addr_t &addr,
int type,
PipeConnection *con,
Message *first)
{
assert(lock.is_locked());
assert(addr != my_inst.addr);
ldout(cct, 10) << "connect_rank to " << addr << ", creating pipe and registering" << dendl;
// create pipe
Pipe *pipe = new Pipe(this, Pipe::STATE_CONNECTING,
static_cast(con));
pipe->pipe_lock.Lock();
pipe->set_peer_type(type);
pipe->set_peer_addr(addr);
pipe->policy = get_policy(type);
pipe->start_writer();
if (first)
pipe->_send(first);
pipe->pipe_lock.Unlock();
pipe->register_pipe();
pipes.insert(pipe);
return pipe;
} get_connection是client的行为,类似于socket通信中的connect系统调用,它真正通信之前,创建了Pipe数据结构。
而服务器端,accept收到连接请求之后,立刻创建了Pipe,它就返回了,继续accept,等待新的连接。
这其实已经很清楚了,Pipe才是通信的双方。
Pipe
Pipe这个类很容易让人产生困惑,因为Linux编程中,也有Pipe管道的概念,它是进程间通信的一种手段,有亲缘关系的进程之间,一个只有read fd,一个只有 write fd(管道通信是单向的), 一个进程向write fd写入内容,另一个进程就可以从read fd中读取到内容,从而达到进程间通信的目的。
其实Ceph的Pipe类,非常相似。Linux下的Pipe,数据流向是单向的,一个Pipe只能做到单向通信,而Ceph的Pipe同时具有读线程和写线程,通过读线程,可以从socket中读取对方发过来的消息,通过写线程可以向socket写消息,发送给对方。这样Pipe类就做到了双向通信。如下代码,Ceph的Pipe类具有读、写类:
class Pipe : public RefCountedObject
{
class Reader : public Thread
{
Pipe *pipe;
public:
explicit Reader(Pipe *p) : pipe(p) {}
void *entry()
{
pipe->reader();
return 0;
}
} reader_thread;
class Writer : public Thread
{
Pipe *pipe;
public:
explicit Writer(Pipe *p) : pipe(p) {}
void *entry()
{
pipe->writer();
return 0;
}
} writer_thread;回到上一小节,accept之后,线程调用了msgr->add_accept_pipe函数,该函数中有这样一句:
p->sd = sd;
p->pipe_lock.Lock();
p->start_reader();
p->pipe_lock.Unlock();很有意思的是通信的发起者,client端执行的get_connection函数中,如果没有Pipe,需要通过connect_rank创建pipe,该函数中有如下一句:
pipe->start_writer();
其实很明确了,client端是攻,而server端是受,所以client端的Pipe主动地start_writer,而server接受client的请求,因此,它启动了自己的read线程 start_reader。 我们看看两者的实现:
/*启动Pipe的读线程*/
void Pipe::start_reader()
{
assert(pipe_lock.is_locked());
assert(!reader_running);
if (reader_needs_join)
{
reader_thread.join();
reader_needs_join = false;
}
reader_running = true;
reader_thread.create("ms_pipe_read", msgr->cct->_conf->ms_rwthread_stack_bytes);
}
/*启动 Pipe的写线程*/
void Pipe::start_writer()
{
assert(pipe_lock.is_locked());
assert(!writer_running);
writer_running = true;
writer_thread.create("ms_pipe_write", msgr->cct->_conf->ms_rwthread_stack_bytes);
}Pipe的reader_thread的主函数执行的是 pipe->reader(),刚刚创建的时候,Pipe处于Pipe::STATE_ACCEPTING状态,而在Pipe::reader函数中,如果状态处于Pipe::STATE_ACCEPTING,会进行执行Pipe::accept,在该函数中,会调用start_writer,启动Pipe的写线程:
int Pipe::accept()
{
...
pipe_lock.Lock();
discard_requeued_up_to(newly_acked_seq);
if (state != STATE_CLOSED)
{
ldout(msgr->cct, 10) << "accept starting writer, state " << get_state_name() << dendl;
/*启动writer_thread*/
start_writer();
}
ldout(msgr->cct, 20) << "accept done" << dendl;
maybe_start_delay_thread();
return 0; // success.
...
}转到另一面,connect_rank中,新创建的Pipe处于STATE_CONNECTING状态。
ipe *pipe = new Pipe(this, Pipe::STATE_CONNECTING,
static_cast(con)); writer_thread的主函数是Pipe::writer,在该函数中,如果Pipe处于STATE_CONNECTING状态,会调用Pipe::connect函数。
此处和Linux socket通信十分吻合。那么Pipe的accept方法和connect方法到底干了哪些事情呢?我们先不展开,这个深水的内容放到下一篇。 我们先讲讲Connection。
Connection
Connection其实是一个比较上层的概念,关于这一点,YY哥的Ceph源码解析:网络模块 和麦子迈的解析Ceph: 网络层的处理有点不一致。
麦子迈大神认为Connection 就是一个 socket 的 wrapper,它从属于某一个 Pipe,而YY哥认为麦子迈的理解不太对,YY哥认为: Pipe是对socket的封装,Connection更加上层、抽象。
其实我的想法更贴近YY哥,但是麦子迈大神的说法也有一定的道理。从编程应用的角度来看,YY哥正确,因为connection是一上层的概念,暴露在外面.
SimpleMessenger发送消息的流程如下,可以看到Connection是上层的,暴露在外的数据结构,所以YY哥是对的
conn = messenger->get_connection(dest_server);
conn->send_message(m);但是从另一个角度看,麦子迈也是对的,我们先看下Connection类的定义。这个类是一个通用类,抽象层次要高于SimpleMessenger中的Pipe。
struct Connection : public RefCountedObject {
mutable Mutex lock;
Messenger *msgr;
RefCountedObject *priv;
int peer_type;
entity_addr_t peer_addr;
utime_t last_keepalive, last_keepalive_ack;连接总是双方的,所以,他要记录对端的类型和对端的地址,对于连接而言,最重要的是通信,要能通过连接发送消息,因此:virtual int send_message(Message *m) = 0;send_message的能力一定是不可或缺的。OK,目前这都是基类,对于SimpleMessenger实现而言,Connection不过是Pipe的一个名为connection_state的成员变量。
class Pipe : public RefCountedObject {
...
protected:
friend class SimpleMessenger;
PipeConnectionRef connection_state;
...
}
ConnectionRef SimpleMessenger::get_connection(const entity_inst_t& dest)
{
Mutex::Locker l(lock);
if (my_inst.addr == dest.addr) {
// local
return local_connection;
}
// remote
while (true) {
Pipe *pipe = _lookup_pipe(dest.addr);
if (pipe) {
ldout(cct, 10) << "get_connection " << dest << " existing " << pipe << dendl;
} else {
pipe = connect_rank(dest.addr, dest.name.type(), NULL, NULL);
ldout(cct, 10) << "get_connection " << dest << " new " << pipe << dendl;
}
Mutex::Locker l(pipe->pipe_lock);
if (pipe->connection_state)
return pipe->connection_state;
// we failed too quickly! retry. FIXME.
}
}我们看一下PipeConnectionRef connection_state;
class PipeConnection : public Connection
{
Pipe *pipe;
friend class boost::intrusive_ptr;
friend class Pipe;
public:
PipeConnection(CephContext *cct, Messenger *m)
: Connection(cct, m),
pipe(NULL) { }
~PipeConnection();
Pipe *get_pipe();
bool try_get_pipe(Pipe **p);
bool clear_pipe(Pipe *old_p);
void reset_pipe(Pipe *p);
bool is_connected() override;
int send_message(Message *m) override;
void send_keepalive() override;
void mark_down() override;
void mark_disposable() override;
}; /* PipeConnection */ 毫不意外,它提供了send_message的方法,当然还有send_keepalive的方法,这些方法,不过是调用了SimpleMessenger类中的同名方法而已:
int PipeConnection::send_message(Message *m)
{
assert(msgr);
return static_cast(msgr)->send_message(m, this);
}
void PipeConnection::send_keepalive()
{
static_cast(msgr)->send_keepalive(this);
} 通过上面的方法不难看出,Connection其实是一个抽象意义上的类,它有点类似于文件描述符,通过文件描述符可以read和write,但是该类并没有限制实现,各种通信方法,可以实现自己的send_message,send_keepalive,而它本身并没有太多实质的内容。
从这里也可以看出,simple类中的Connection,其实是Pipe中的一个成员变量,因此麦子迈说Connection 就是一个 socket 的 wrapper,它从属于某一个 Pipe,也有一定的道理。
但是很明显,我并不喜欢麦子迈的这种说法,因为很容易产生误解。YY哥的说法我更赞成,也更准确。
Ceph通信模块使用实例-monitor模块为例
Ceph 网络模块(4)——SimpleMessenger数据结构及代码流程分析_Hequan的专栏-CSDN博客
Ceph源码解析:网络模块-simple
由于Ceph的历史很久,最初的网络---simple模式---没有采用现在常用的事件驱动(epoll)的模型,而是采用了与MySQL类似的多线程模型,每个连接(socket)有一个读线程,不断从socket读取,一个写线程,负责将数据写到socket。多线程实现简单,但并发性能就不敢恭维了。
Messenger是网络模块的核心数据结构,负责接收/发送消息。OSD主要有两个Messenger:ms_public处于与客户端的消息,ms_cluster处理与其它OSD的消息。
数据结构
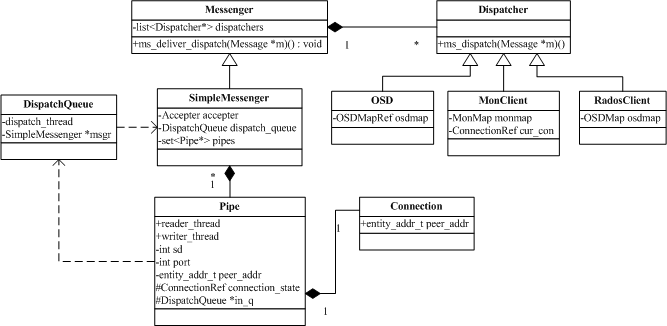
网络模块的核心是SimpleMessager:
(1)它包含一个Accepter对象,它会创建一个单独的线程,用于接收新的连接(Pipe),(socket sd到来,创建Pipe,将连接sd包入其中( p->sd = sd;,Pipe就是SimpleMessager的“连接”)
void *Accepter::entry()
{
...
int sd = ::accept(listen_sd, (sockaddr*)&addr.ss_addr(), &slen);
if (sd >= 0) {
errors = 0;
ldout(msgr->cct,10) << "accepted incoming on sd " << sd << dendl;
msgr->add_accept_pipe(sd);
...
//创建新的Pipe
Pipe *SimpleMessenger::add_accept_pipe(int sd)
{
lock.Lock();
Pipe *p = new Pipe(this, Pipe::STATE_ACCEPTING, NULL);
p->sd = sd;
p->pipe_lock.Lock();
p->start_reader();
p->pipe_lock.Unlock();
pipes.insert(p);
accepting_pipes.insert(p);
lock.Unlock();
return p;
}(2)包含所有的连接对象(Pipe),每个连接Pipe有一个读线程/写线程。读线程负责从socket读取数据,然后放消息放到DispatchQueue分发队列。写线程负责从发送队列取出Message,然后写到socket。
class Pipe : public RefCountedObject {
/**
* The Reader thread handles all reads off the socket -- not just
* Messages, but also acks and other protocol bits (excepting startup,
* when the Writer does a couple of reads).
* All the work is implemented in Pipe itself, of course.
*/
class Reader : public Thread {
Pipe *pipe;
public:
Reader(Pipe *p) : pipe(p) {}
void *entry() { pipe->reader(); return 0; }
} reader_thread; ///读线程
friend class Reader;
/**
* The Writer thread handles all writes to the socket (after startup).
* All the work is implemented in Pipe itself, of course.
*/
class Writer : public Thread {
Pipe *pipe;
public:
Writer(Pipe *p) : pipe(p) {}
void *entry() { pipe->writer(); return 0; }
} writer_thread; ///写线程
friend class Writer;
...
///发送队列
map > out_q; // priority queue for outbound msgs
DispatchQueue *in_q; ///接收队列 (3)包含一个分发队列DispatchQueue,分发队列有一个专门的分发线程(DispatchThread),将消息分发给Dispatcher(OSD)完成具体逻辑处理。
消息的接收
接收流程如下:

Pipe的读线程从socket读取Message,然后放入接收队列,再由分发线程取出Message交给Dispatcher处理。
消息的发送
发送流程如下:

其它资料
这篇文章解析Ceph: 网络层的处理简单介绍了一下Ceph的网络,但对Pipe与Connection的关系描述似乎不太准确,Pipe是对socket的封装,Connection更加上层、抽象。
原文:Ceph源码解析:网络模块